Recognition: no theorem link
Sparsity Hurts: Simple Linear Adapter Can Boost Generalized Category Discovery
Pith reviewed 2026-05-12 01:08 UTC · model grok-4.3
The pith
Embedding a residual linear adapter in each ViT block boosts generalized category discovery by countering the harm from feature sparsity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
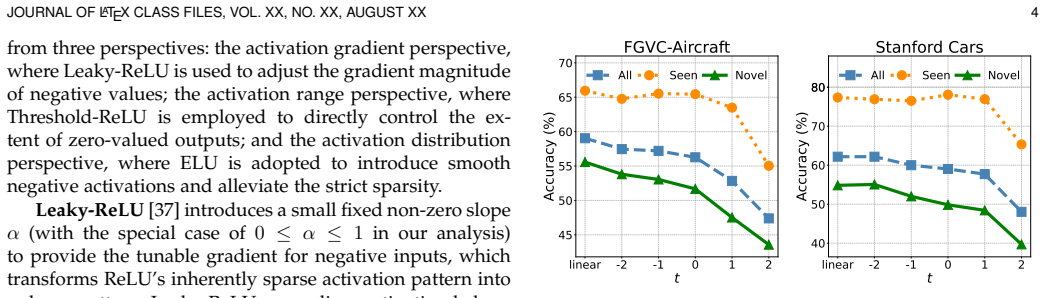
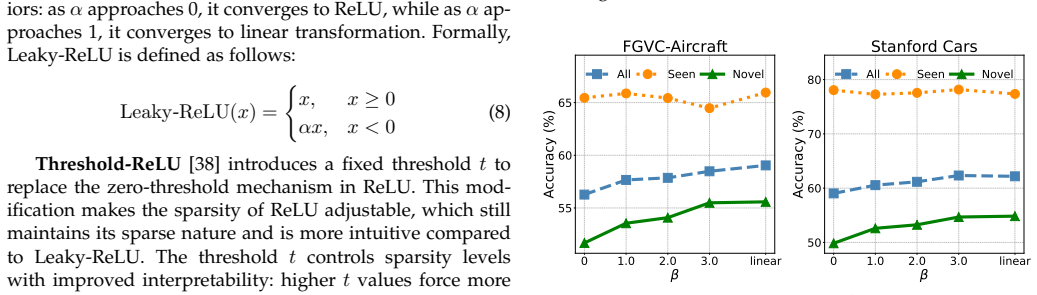
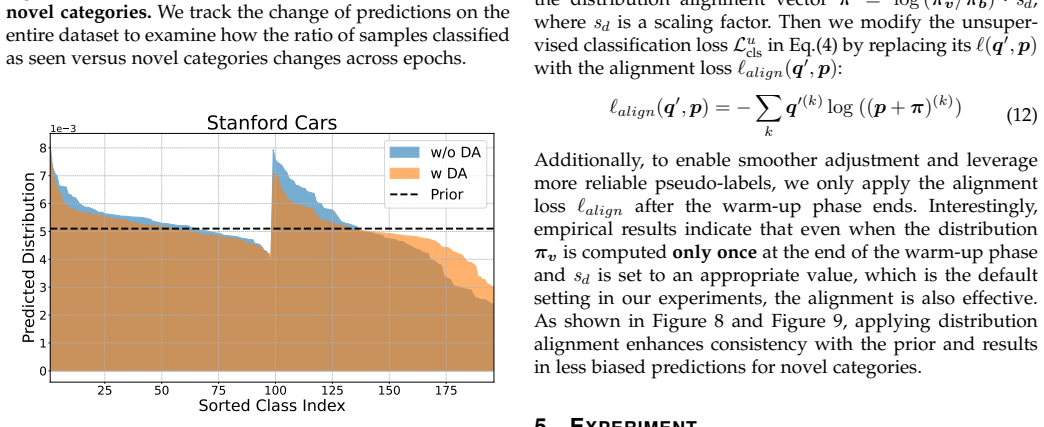
From the perspective of feature sparsity, non-linearity in conventional adapters impairs performance, whereas our linear adapter enhances it by enabling more flexible model capacity. LAGCD embeds a residual linear adapter into each ViT block and introduces an auxiliary distribution alignment loss to mitigate the negative impact of biased predictions between seen and novel categories.
What carries the argument
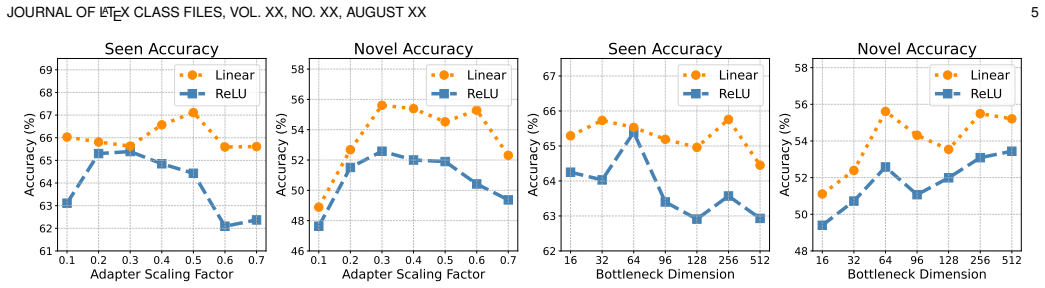
The residual linear adapter inserted into each ViT block, which adapts representations linearly to increase model capacity while avoiding non-linear transformations that degrade sparse features.
If this is right
- The entire pre-trained ViT can be adapted more flexibly than with partial fine-tuning of only the final block.
- Overfitting is reduced compared with visual prompt tuning because the linear adapter has constrained yet sufficient capacity.
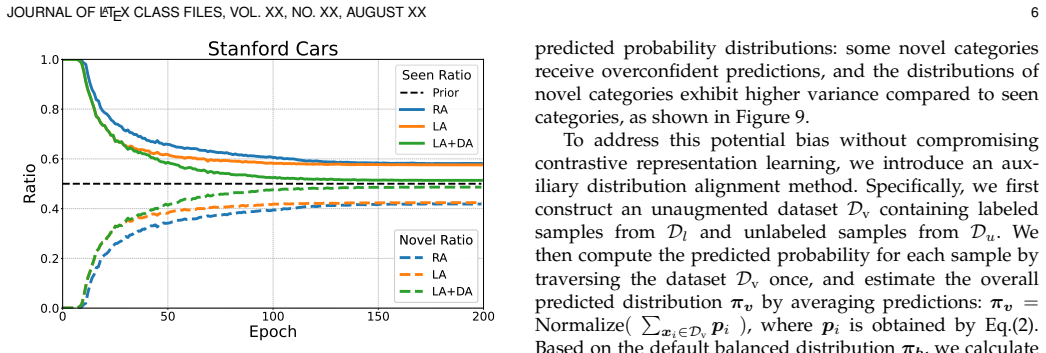
- An auxiliary loss that aligns seen and novel category distributions counters prediction bias without complicating the core architecture.
- Consistent accuracy gains appear on both generic and fine-grained datasets over prior sophisticated GCD baselines.
Where Pith is reading between the lines
- The same sparsity argument could motivate linear adapters in other transfer settings where pre-trained features are known to be sparse.
- Designers of future adapters might test linearity first before adding non-linearities, especially when adapting models for open-set recognition tasks.
- The placement across all blocks suggests that full-model linear adaptation may generalize to other vision problems that require both retention of old knowledge and acquisition of new classes.
Load-bearing premise
The observed gains truly arise from the linear adapter's handling of feature sparsity rather than from the auxiliary loss, specific hyperparameter settings, or other unstated design elements.
What would settle it
An experiment in which the linear adapter is added to the model but the auxiliary distribution alignment loss is removed, and performance either stays flat or drops below the non-linear adapter baselines.
Figures





read the original abstract
Generalized Category Discovery (GCD) seeks to identify novel categories from unlabeled data while retaining the classification ability of seen categories. Prior GCD methods commonly leverage transferable representations from pre-trained models, adapting to downstream datasets via partial fine-tuning (updating only the final ViT block) and visual prompt tuning (appending learnable vectors to inputs). However, conventional partial fine-tuning offers limited flexibility, as it fails to adapt the entire model; meanwhile, visual prompt tuning is prone to overfitting, due to its sensitivity to initialization and inherently constrained capacity. To address these limitations, we propose LAGCD, a simple yet effective GCD approach that embeds a residual linear adapter into each ViT block. From the perspective of feature sparsity, we systematically show that non-linearity in conventional adapters impairs performance, whereas our linear adapter enhances it by enabling more flexible model capacity. We further introduce an auxiliary distribution alignment loss to mitigate the negative impact of biased predictions between seen and novel categories. Extensive experiments on both generic and fine-grained datasets confirm that LAGCD consistently improves performance over many sophisticated baselines. The source code is available at https://github.com/yebo0216best/LAGCD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LAGCD for Generalized Category Discovery, inserting a residual linear adapter into each ViT block. It claims that non-linearity in conventional adapters impairs performance due to increased feature sparsity, while the linear adapter improves results by enabling greater model flexibility. An auxiliary distribution alignment loss is added to mitigate biased predictions between seen and novel classes. Experiments on generic and fine-grained datasets report consistent gains over prior GCD baselines.
Significance. If the sparsity mechanism is causally validated, the work offers a simple alternative to partial fine-tuning and prompt tuning in GCD, potentially simplifying adapter design in transfer learning. Releasing source code aids reproducibility, but the absence of isolated mechanism tests limits the strength of the contribution.
major comments (2)
- [Analysis / Experiments] The central claim that non-linearity impairs performance via feature sparsity (abstract and analysis sections) requires explicit quantification of sparsity differences, such as L0 norms or activation histograms, between linear and non-linear adapters; end-to-end accuracy tables alone do not establish this as the load-bearing mechanism.
- [Experiments] The comparison between linear and non-linear adapters is potentially confounded by the auxiliary distribution alignment loss; a full factorial ablation (adapter type × with/without aux loss) is needed to isolate causality, as noted in the stress-test concern.
minor comments (1)
- [Abstract] The abstract states empirical improvements without referencing specific tables, datasets, or statistical tests; adding these cross-references would improve clarity.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed comments. We address each major comment below and commit to revisions that strengthen the mechanistic evidence and experimental isolation as requested.
read point-by-point responses
-
Referee: [Analysis / Experiments] The central claim that non-linearity impairs performance via feature sparsity (abstract and analysis sections) requires explicit quantification of sparsity differences, such as L0 norms or activation histograms, between linear and non-linear adapters; end-to-end accuracy tables alone do not establish this as the load-bearing mechanism.
Authors: We agree that explicit quantification is required to establish the sparsity mechanism as load-bearing. The manuscript demonstrates the performance advantage of linear adapters and discusses sparsity qualitatively, but we acknowledge that end-to-end tables and existing analysis do not provide direct metrics. In the revised manuscript we will add L0-norm statistics of post-adapter activations together with activation histograms comparing linear versus non-linear adapters across multiple ViT blocks and datasets. These additions will directly quantify the sparsity increase induced by non-linearity. revision: yes
-
Referee: [Experiments] The comparison between linear and non-linear adapters is potentially confounded by the auxiliary distribution alignment loss; a full factorial ablation (adapter type × with/without aux loss) is needed to isolate causality, as noted in the stress-test concern.
Authors: We appreciate the concern about potential confounding. The distribution alignment loss targets prediction bias between seen and novel classes and is intended to be complementary to the adapter choice. To isolate effects rigorously, the revised manuscript will include a complete factorial ablation: linear and non-linear adapters, each evaluated both with and without the auxiliary loss, on the primary generic and fine-grained benchmarks. Results will be presented in a dedicated table to confirm that the linear-adapter benefit holds independently of the loss. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an empirical method (LAGCD) inserting a residual linear adapter per ViT block plus an auxiliary distribution alignment loss, then reports accuracy gains on GCD benchmarks. The 'systematic show' from the feature-sparsity perspective is an interpretive post-experiment explanation rather than a closed mathematical derivation or prediction that reduces to fitted inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises; the auxiliary loss is introduced separately to address bias. Experimental validation on external datasets supplies independent content, so the central claims remain non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained Vision Transformer models yield transferable representations that can be adapted for generalized category discovery.
Reference graph
Works this paper leans on
-
[1]
Parametric classification for gen- eralized category discovery: A baseline study,
X. Wen, B. Zhao, and X. Qi, “Parametric classification for gen- eralized category discovery: A baseline study,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 16 590–16 600
work page 2023
-
[2]
H. Wang, S. Vaze, and K. Han, “Sptnet: An efficient alterna- tive framework for generalized category discovery with spatial prompt tuning,”arXiv preprint arXiv:2403.13684, 2024
-
[3]
Adaptgcd: Multi-expert adapter tuning for generalized category discovery,
Y. Qu, Y. Tang, C. Zhang, and W. Zhang, “Adaptgcd: Multi-expert adapter tuning for generalized category discovery,”arXiv preprint arXiv:2410.21705, 2024
-
[4]
Pseudo-label: The simple and efficient semi- supervised learning method for deep neural networks,
D.-H. Lee, “Pseudo-label: The simple and efficient semi- supervised learning method for deep neural networks,” inWork- shop on challenges in representation learning, ICML, 2013
work page 2013
-
[5]
Regularization with stochastic transformations and perturbations for deep semi- supervised learning,
M. Sajjadi, M. Javanmardi, and T. Tasdizen, “Regularization with stochastic transformations and perturbations for deep semi- supervised learning,” inNeural Information Processing Systems, 2016
work page 2016
-
[6]
Temporal Ensembling for Semi-Supervised Learning,
S. Laine and T. Aila, “Temporal Ensembling for Semi-Supervised Learning,”arXiv: Neural and Evolutionary Computing, 2016
work page 2016
-
[7]
FixMatch: Simplifying semi- supervised learning with consistency and confidence,
K. Sohn, D. Berthelot, C.-L. Li, Z. Zhang, N. Carlini, E. D. Cubuk, A. Kurakin, H. Zhang, and C. Raffel, “FixMatch: Simplifying semi- supervised learning with consistency and confidence,” inNeural Information Processing Systems, 2020
work page 2020
-
[8]
Towards realistic long-tailed semi-supervised learning: Consistency is all you need,
T. Wei and K. Gan, “Towards realistic long-tailed semi-supervised learning: Consistency is all you need,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 3469–3478
work page 2023
-
[9]
Erasing the bias: Fine-tuning foundation models for semi-supervised learning,
K. Gan and T. Wei, “Erasing the bias: Fine-tuning foundation models for semi-supervised learning,” inForty-first International Conference on Machine Learning, 2024
work page 2024
-
[10]
Semi-supervised clip adaptation by enforcing semantic and trapezoidal consistency,
K. Gan, B. Ye, M.-L. Zhang, and T. Wei, “Semi-supervised clip adaptation by enforcing semantic and trapezoidal consistency,” in The Thirteenth International Conference on Learning Representations
-
[11]
Realistic evaluation of deep semi-supervised learning algorithms,
A. Oliver, A. Odena, C. A. Raffel, E. D. Cubuk, and I. Good- fellow, “Realistic evaluation of deep semi-supervised learning algorithms,” inNeural Information Processing Systems, 2018
work page 2018
-
[12]
Open-world semi-supervised learning,
K. Cao, M. Brbic, and J. Leskovec, “Open-world semi-supervised learning,” inInternational Conference on Learning Representations, 2022
work page 2022
-
[13]
Generalized category discovery,
S. Vaze, K. Han, A. Vedaldi, and A. Zisserman, “Generalized category discovery,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 7492–7501
work page 2022
-
[14]
S. Zhang, S. Khan, Z. Shen, M. Naseer, G. Chen, and F. S. Khan, “Promptcal: Contrastive affinity learning via auxiliary prompts for generalized novel category discovery,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3479–3488
work page 2023
-
[15]
A graph-theoretic framework for understanding open-world semi-supervised learning,
Y. Sun, Z. Shi, and Y. Li, “A graph-theoretic framework for understanding open-world semi-supervised learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 23 934–23 967, 2023
work page 2023
-
[16]
No representation rules them all in category discovery,
S. Vaze, A. Vedaldi, and A. Zisserman, “No representation rules them all in category discovery,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[17]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[18]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P . Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international confer- ence on computer vision, 2021, pp. 9650–9660
work page 2021
-
[19]
M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 709–727
work page 2022
-
[20]
Parameter- efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Larous- silhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter- efficient transfer learning for nlp,” inInternational conference on machine learning. PMLR, 2019, pp. 2790–2799
work page 2019
-
[21]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y. Shen, P . Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,”arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Adaptformer: Adapting vision transformers for scalable visual recognition,
S. Chen, C. Ge, Z. Tong, J. Wang, Y. Song, J. Wang, and P . Luo, “Adaptformer: Adapting vision transformers for scalable visual recognition,”Advances in Neural Information Processing Systems, vol. 35, pp. 16 664–16 678, 2022
work page 2022
-
[23]
Rectified linear units improve restricted boltzmann machines,
V . Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” inProceedings of the 27th international confer- ence on machine learning (ICML-10), 2010, pp. 807–814
work page 2010
-
[24]
Xcon: Learning with experts for fine-grained category discovery,
Y. Fei, Z. Zhao, S. Yang, and B. Zhao, “Xcon: Learning with experts for fine-grained category discovery,”arXiv preprint arXiv:2208.01898, 2022
-
[25]
Opencon: Open-world contrastive learning,
Y. Sun and Y. Li, “Opencon: Open-world contrastive learning,” arXiv preprint arXiv:2208.02764, 2022
-
[26]
Contrastive mean-shift learning for generalized category discovery,
S. Choi, D. Kang, and M. Cho, “Contrastive mean-shift learning for generalized category discovery,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 23 094–23 104
work page 2024
-
[27]
Solving the catastrophic forgetting problem in general- ized category discovery,
X. Cao, X. Zheng, G. Wang, W. Yu, Y. Shen, K. Li, Y. Lu, and Y. Tian, “Solving the catastrophic forgetting problem in general- ized category discovery,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 880–16 889
work page 2024
-
[28]
Flipped classroom: Aligning teacher attention with student in generalized category discovery,
H. Lin, W. An, J. Wang, Y. Chen, F. Tian, M. Wang, Q. Wang, G. Dai, and J. Wang, “Flipped classroom: Aligning teacher attention with student in generalized category discovery,”Advances in Neural Information Processing Systems, vol. 37, pp. 60 897–60 935, 2024
work page 2024
-
[29]
Hilo: A learning framework for generalized category discovery robust to domain shifts,
H. Wang, S. Vaze, and K. Han, “Hilo: A learning framework for generalized category discovery robust to domain shifts,”arXiv preprint arXiv:2408.04591, 2024
-
[30]
Bridging the gap: Learning pace synchronization for open-world semi-supervised learning,
B. Ye, K. Gan, T. Wei, and M.-L. Zhang, “Bridging the gap: Learning pace synchronization for open-world semi-supervised learning,” inProceedings of the Thirty-Third International Joint Con- ference on Artificial Intelligence, 2024, pp. 5362–5370
work page 2024
-
[31]
Long- tail learning with foundation model: Heavy fine-tuning hurts,
J.-X. Shi, T. Wei, Z. Zhou, J.-J. Shao, X.-Y. Han, and Y.-F. Li, “Long- tail learning with foundation model: Heavy fine-tuning hurts,” in Proceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[32]
Supervised contrastive learning,
P . Khosla, P . Teterwak, C. Wang, A. Sarna, Y. Tian, P . Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,”Advances in neural information processing systems, vol. 33, pp. 18 661–18 673, 2020
work page 2020
-
[33]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in International conference on machine learning. PMLR, 2020, pp. 1597– 1607
work page 2020
-
[34]
Masked siamese networks for label-efficient learning,
M. Assran, M. Caron, I. Misra, P . Bojanowski, F. Bordes, P . Vincent, A. Joulin, M. Rabbat, and N. Ballas, “Masked siamese networks for label-efficient learning,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 456–473. JOURNAL OF LATEX CLASS FILES, VOL. XX, NO. XX, AUGUST XX 13
work page 2022
-
[35]
Pseudo-labeling and confirmation bias in deep semi-supervised learning,
E. Arazo, D. Ortego, P . Albert, N. E. OConnor, and K. McGuinness, “Pseudo-labeling and confirmation bias in deep semi-supervised learning,” inInternational Joint Conference on Neural Networks, 2020
work page 2020
-
[36]
Empirical evalua- tion of rectified activations in convolutional network
B. Xu, “Empirical evaluation of rectified activations in convolu- tional network,”arXiv preprint arXiv:1505.00853, 2015
-
[37]
Rectifier nonlinearities improve neural network acoustic models,
A. L. Maas, A. Y. Hannun, A. Y. Nget al., “Rectifier nonlinearities improve neural network acoustic models,” inProc. icml, vol. 30, no. 1. Atlanta, GA, 2013, p. 3
work page 2013
-
[38]
Zero-bias autoencoders and the benefits of co-adapting features
K. Konda, R. Memisevic, and D. Krueger, “Zero-bias autoen- coders and the benefits of co-adapting features,”arXiv preprint arXiv:1402.3337, 2014
-
[39]
Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)
D.-A. Clevert, T. Unterthiner, and S. Hochreiter, “Fast and accurate deep network learning by exponential linear units (elus),”arXiv preprint arXiv:1511.07289, vol. 4, no. 5, p. 11, 2015
work page Pith review arXiv 2015
-
[40]
Fine-Grained Visual Classification of Aircraft
S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi, “Fine-grained visual classification of aircraft,”arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[41]
3d object represen- tations for fine-grained categorization,
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3d object represen- tations for fine-grained categorization,” inProceedings of the IEEE international conference on computer vision workshops, 2013, pp. 554– 561
work page 2013
-
[42]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[43]
Y. Tian, D. Krishnan, and P . Isola, “Contrastive multiview coding,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16. Springer, 2020, pp. 776–794
work page 2020
-
[44]
P . Welinder, S. Branson, T. Mita, C. Wah, F. Schroff, S. Belongie, and P . Perona, “Caltech-ucsd birds 200,” 2010
work page 2010
-
[45]
Open-set recogni- tion: A good closed-set classifier is all you need?
S. Vaze, K. Han, A. Vedaldi, and A. Zisserman, “Open-set recogni- tion: A good closed-set classifier is all you need?” 2021
work page 2021
-
[46]
The herbarium challenge 2019 dataset,
K. C. Tan, Y. Liu, B. Ambrose, M. Tulig, and S. Be- longie, “The herbarium challenge 2019 dataset,”arXiv preprint arXiv:1906.05372, 2019
-
[47]
The Hungarian method for the assignment prob- lem,
H. W. Kuhn, “The Hungarian method for the assignment prob- lem,”Naval Research Logistics Quarterly, 1955
work page 1955
-
[48]
k-means++: The advantages of careful seeding,
D. Arthur and S. Vassilvitskii, “k-means++: The advantages of careful seeding,” Stanford, Tech. Rep., 2006
work page 2006
-
[49]
Autonovel: Automatically discovering and learning novel visual categories,
K. Han, S.-A. Rebuffi, S. Ehrhardt, A. Vedaldi, and A. Zisserman, “Autonovel: Automatically discovering and learning novel visual categories,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 6767–6781, 2021
work page 2021
-
[50]
A unified objective for novel class discovery,
E. Fini, E. Sangineto, S. Lathuili `ere, Z. Zhong, M. Nabi, and E. Ricci, “A unified objective for novel class discovery,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9284–9292
work page 2021
-
[51]
Dynamic conceptional contrastive learning for generalized category discovery,
N. Pu, Z. Zhong, and N. Sebe, “Dynamic conceptional contrastive learning for generalized category discovery,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 7579–7588
work page 2023
-
[52]
Learning semi-supervised gaussian mixture models for generalized category discovery,
B. Zhao, X. Wen, and K. Han, “Learning semi-supervised gaussian mixture models for generalized category discovery,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 16 623–16 633
work page 2023
-
[53]
Amend: Adap- tive margin and expanded neighborhood for efficient generalized category discovery,
A. Banerjee, L. S. Kallooriyakath, and S. Biswas, “Amend: Adap- tive margin and expanded neighborhood for efficient generalized category discovery,” inProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision, 2024, pp. 2101–2110
work page 2024
-
[54]
Protogcd: Unified and unbiased prototype learning for generalized category discovery,
S. Ma, F. Zhu, X.-Y. Zhang, and C.-L. Liu, “Protogcd: Unified and unbiased prototype learning for generalized category discovery,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[55]
The perceptron: a probabilistic model for informa- tion storage and organization in the brain
F. Rosenblatt, “The perceptron: a probabilistic model for informa- tion storage and organization in the brain.”Psychological review, vol. 65, no. 6, p. 386, 1958
work page 1958
-
[56]
Y. LeCun, L. Bottou, G. B. Orr, and K.-R. M ¨uller, “Efficient back- prop,” inNeural networks: Tricks of the trade. Springer, 2002, pp. 9–50
work page 2002
-
[57]
Searching for Activation Functions
P . Ramachandran, B. Zoph, and Q. V . Le, “Searching for activation functions,”arXiv preprint arXiv:1710.05941, 2017
work page internal anchor Pith review arXiv 2017
-
[58]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),”arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.