Recognition: 2 theorem links
· Lean TheoremHarmonized Feature Conditioning and Frequency-Prompt Personalization for Multi-Rater Medical Segmentation
Pith reviewed 2026-05-12 01:10 UTC · model grok-4.3
The pith
A harmonized probabilistic framework disentangles scanner artifacts from annotator variability using adaptive feature conditioning and frequency-domain prompts for multi-rater medical segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a harmonized probabilistic framework, incorporating adaptive feature conditioning via a Harmonizer Network and frequency-domain personalization through High-Frequency Prompt Modules, can disentangle acquisition artifacts from genuine annotator variability. This enables the generation of personalized segmentations that remain anatomically consistent while a Generalized Energy Distance regularization aligns the output distribution with empirical rater differences, leading to state-of-the-art performance on datasets like LIDC-IDRI and NPC-170.
What carries the argument
The Harmonizer Network, which implicitly models scanner-specific artifacts and performs dynamic feature modulation to standardize representations, combined with High-Frequency Prompt Modules that encode annotator-dependent boundary precision in the spectral domain.
Load-bearing premise
The Harmonizer Network and High-Frequency Prompt Modules can reliably separate scanner artifacts from true annotator variability without introducing new biases.
What would settle it
A controlled experiment on data with documented scanner artifacts and expert labels where the model's uncertainty maps are checked to see if they align with actual rater disagreement regions rather than artifact locations.
Figures











read the original abstract
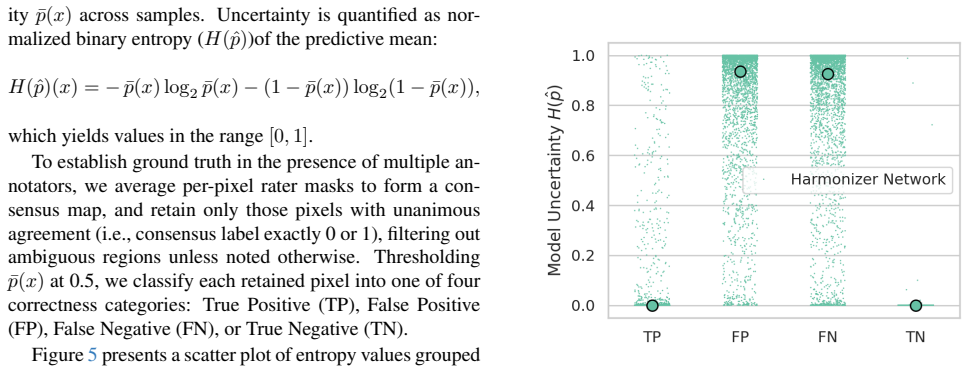
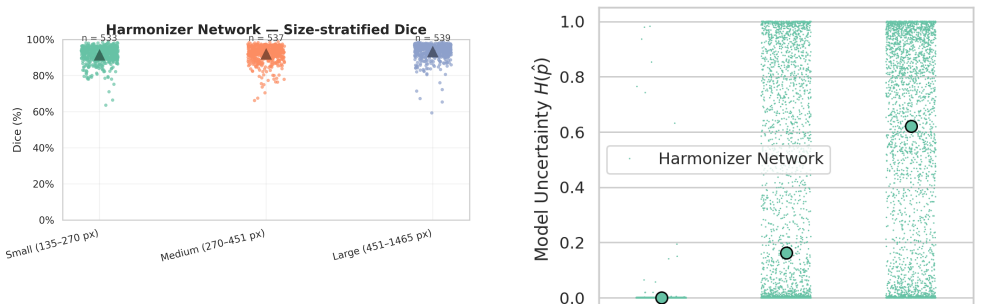
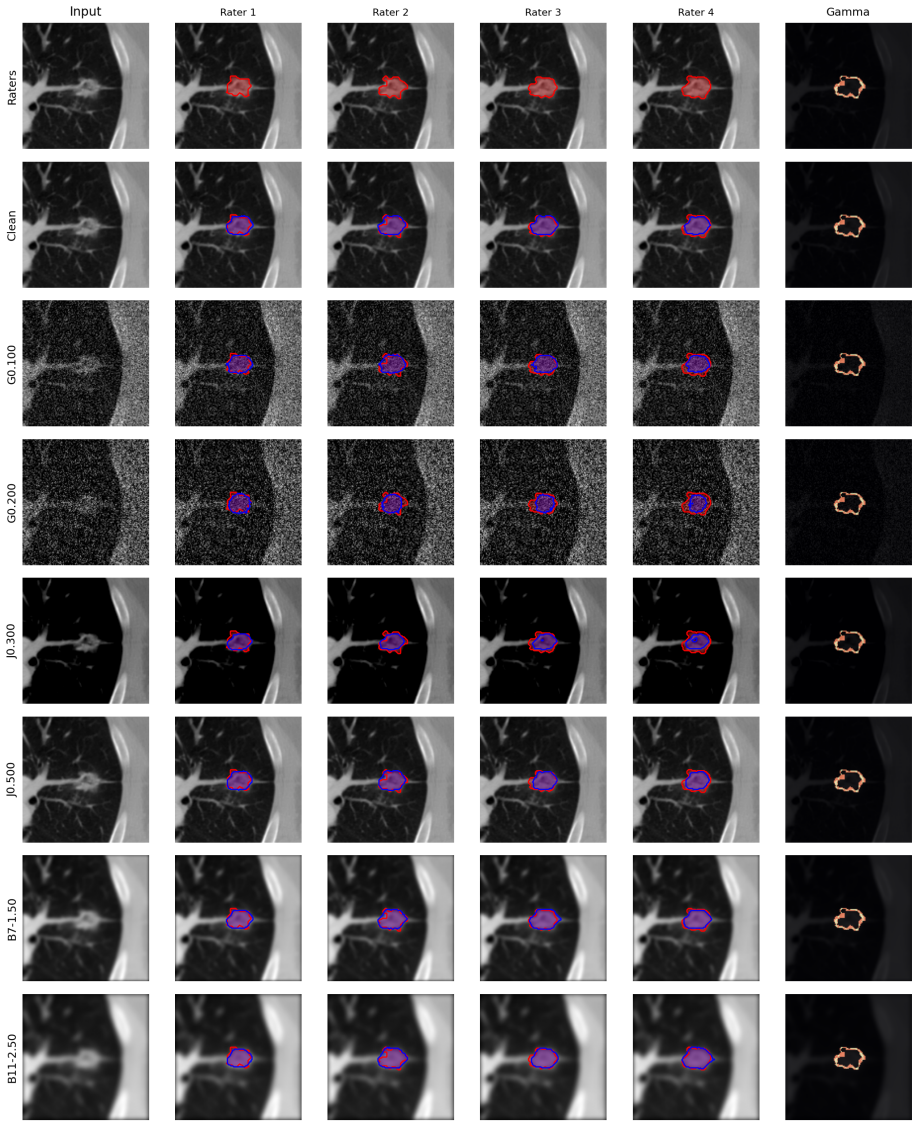
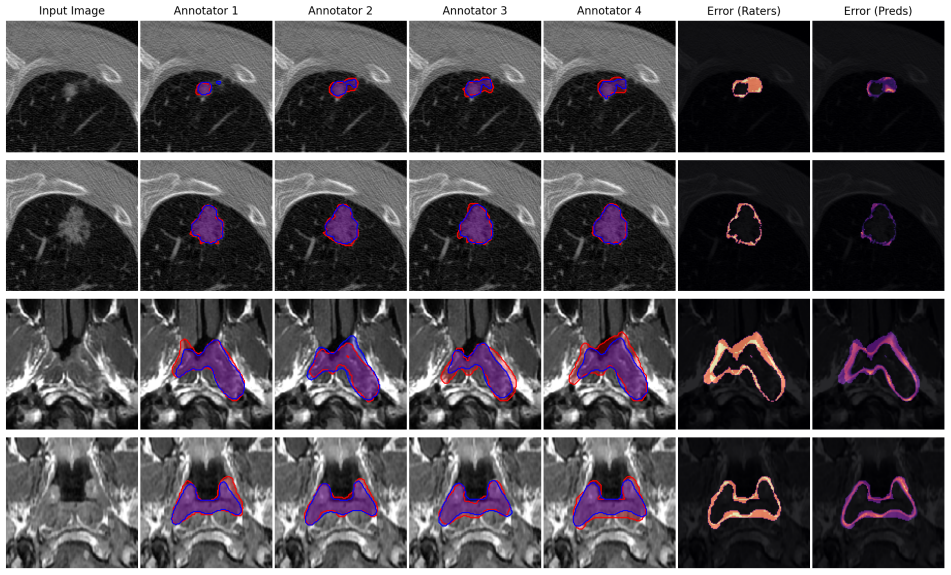
Multi-rater medical image segmentation captures the inherent ambiguity of clinical interpretation, where diagnostic boundaries vary across experts and imaging devices. Existing approaches often reduce this diversity to consensus labels or treat rater differences as noise, resulting in overconfident and poorly calibrated models. We propose a harmonized probabilistic framework that disentangles acquisition artifacts from genuine annotator variability through adaptive feature conditioning and frequency-domain personalization. A lightweight Harmonizer Network implicitly models scanner-specific artifacts and performs dynamic feature modulation to standardize latent representations, ensuring that uncertainty reflects anatomy rather than noise. To represent rater-specific styles, we introduce a novel High-Frequency Prompt Modules that operate in the spectral domain to encode annotator-dependent boundary precision and textural sensitivity. These prompts adaptively modulate harmonized features to produce personalized yet anatomically consistent segmentations. Furthermore, a Generalized Energy Distance based regularization aligns the generative distribution with empirical annotation variability, promoting diversity where experts disagree and consensus where they converge. Experiments on LIDC-IDRI and NPC-170 show SOTA aggregated and individualized segmentation, with notable GED reductions and improved Dice scores, especially on noisy cases. Beyond accuracy, the model exhibits clinically meaningful uncertainty. Confidence rises in agreement regions and declines in ambiguous areas, supporting its use as a reliable and interpretable tool for multi-expert clinical workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a harmonized probabilistic framework for multi-rater medical image segmentation that disentangles acquisition artifacts from annotator variability. It introduces a lightweight Harmonizer Network for adaptive feature conditioning and dynamic modulation to standardize latent representations, novel High-Frequency Prompt Modules operating in the spectral domain to encode rater-specific boundary and textural styles, and Generalized Energy Distance (GED) regularization to align the generative distribution with empirical annotation statistics. The framework is claimed to produce personalized yet anatomically consistent segmentations, with experiments on LIDC-IDRI and NPC-170 datasets showing state-of-the-art aggregated and individualized performance, reduced GED, improved Dice scores (especially on noisy cases), and clinically meaningful uncertainty estimates that rise in agreement regions and decline in ambiguous areas.
Significance. If the empirical claims hold with proper validation, the work would offer a principled way to model both scanner-induced artifacts and genuine rater variability in a single generative model, improving calibration and interpretability of uncertainty in clinical multi-expert workflows. The frequency-domain personalization and GED-based alignment represent potentially useful technical contributions for handling annotation ambiguity beyond simple consensus or noise modeling.
major comments (2)
- [Abstract] Abstract: The central empirical claim of SOTA aggregated and individualized segmentation with notable GED reductions and improved Dice scores on LIDC-IDRI and NPC-170 (especially on noisy cases) is presented without any quantitative tables, baseline comparisons, statistical tests, error bars, or ablation results, rendering the performance assertions impossible to evaluate from the provided manuscript text.
- [Methods] Methods (Harmonizer Network and High-Frequency Prompt Modules description): No controlled experiments (e.g., multi-scanner same-rater protocols), auxiliary reconstruction losses, or explicit validation metrics are described to confirm that the implicit artifact modeling isolates scanner effects without attenuating genuine annotator or biological variability; this separation is load-bearing for the GED regularization to guarantee clinically meaningful diversity rather than artifact-driven or suppressed outputs.
minor comments (2)
- [Abstract] Abstract: The phrase 'especially on noisy cases' is used without defining the criteria for noisy cases or referencing supporting quantitative evidence from the experiments.
- The manuscript would benefit from explicit notation for the frequency-domain modulation operators and prompt scales to clarify how they interact with the harmonized features.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and will revise the manuscript to improve clarity and rigor where possible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of SOTA aggregated and individualized segmentation with notable GED reductions and improved Dice scores on LIDC-IDRI and NPC-170 (especially on noisy cases) is presented without any quantitative tables, baseline comparisons, statistical tests, error bars, or ablation results, rendering the performance assertions impossible to evaluate from the provided manuscript text.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we will add concise statements of the main Dice improvements, GED reductions, and SOTA comparisons (with reference to the full tables, error bars, and statistical tests already present in the Experiments section). This keeps the abstract within length limits while making the claims directly evaluable. revision: yes
-
Referee: [Methods] Methods (Harmonizer Network and High-Frequency Prompt Modules description): No controlled experiments (e.g., multi-scanner same-rater protocols), auxiliary reconstruction losses, or explicit validation metrics are described to confirm that the implicit artifact modeling isolates scanner effects without attenuating genuine annotator or biological variability; this separation is load-bearing for the GED regularization to guarantee clinically meaningful diversity rather than artifact-driven or suppressed outputs.
Authors: The Harmonizer Network is intended to perform implicit standardization via adaptive conditioning, with the GED term and observed uncertainty behavior serving as indirect validation that genuine rater variability is preserved. We acknowledge that explicit controlled experiments would provide stronger evidence. Because neither LIDC-IDRI nor NPC-170 contains multi-scanner same-rater annotations, such protocols cannot be performed. We will add ablation studies (with/without the Harmonizer) and auxiliary reconstruction losses in the revised Methods and Experiments sections, together with expanded discussion of how the current results support separation of acquisition artifacts from annotator variability. revision: partial
- The available datasets (LIDC-IDRI and NPC-170) lack multi-scanner same-rater annotations, preventing the controlled experiments suggested for explicit validation of artifact isolation.
Circularity Check
No circularity: architectural proposal with independent components and standard regularization
full rationale
The paper introduces a harmonized probabilistic framework via novel components (Harmonizer Network for artifact modeling, High-Frequency Prompt Modules for rater styles) motivated directly by the problem of disentangling acquisition artifacts from annotator variability. The GED-based regularization is described as aligning generative outputs to empirical annotation statistics, which is a conventional distribution-matching technique rather than a self-referential derivation. No equations, definitions, or claims in the abstract or described text reduce any prediction or result to its own inputs by construction, nor do they rely on load-bearing self-citations or imported uniqueness theorems. The central claims rest on the proposed architecture and its empirical performance on LIDC-IDRI and NPC-170, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- network hyperparameters and prompt scales
axioms (2)
- domain assumption Multiple rater annotations primarily reflect genuine clinical variability rather than pure noise or systematic bias
- ad hoc to paper Frequency-domain modulation can isolate rater-specific boundary styles without distorting anatomical content
invented entities (2)
-
Harmonizer Network
no independent evidence
-
High-Frequency Prompt Modules
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A lightweight Harmonizer Network implicitly models scanner-specific artifacts and performs dynamic feature modulation... High-Frequency Prompt Modules that operate in the spectral domain... Generalized Energy Distance based regularization
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decompose features via wavelet transforms... high-frequency maps... Rater-Aware Prompt Projection block
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Samuel G Armato, Geoffrey McLennan, Luc Bidaut, Michael F McNitt-Gray, Charles R Meyer, Anthony P Reeves, Binsheng Zhao, Denise R Aberle, Claudia I Hen- schke, Eric A Hoffman, et al. The lung image database con- sortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans. Medical physics, 38(2):...
work page 2011
-
[2]
Laplacian-former: Overcoming the limitations of vision transformers in local texture detection
Reza Azad, Amirhossein Kazerouni, Babak Azad, Ehsan Khodapanah Aghdam, Yury Velichko, Ulas Bagci, and Dorit Merhof. Laplacian-former: Overcoming the limitations of vision transformers in local texture detection. InIn- ternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 736–746. Springer,
-
[3]
Phiseg: Capturing uncertainty in medical image segmentation
Christian F Baumgartner, Kerem C Tezcan, Krishna Chai- tanya, Andreas M H ¨otker, Urs J Muehlematter, Khoschy Schawkat, Anton S Becker, Olivio Donati, and Ender Konukoglu. Phiseg: Capturing uncertainty in medical image segmentation. InInternational Conference on Medical Im- age Computing and Computer-Assisted Intervention, pages 119–127. Springer, 2019. 1, 3
work page 2019
-
[4]
The Cramer Distance as a Solution to Biased Wasserstein Gradients
Marc G Bellemare, Ivo Danihelka, Will Dabney, Shakir Mo- hamed, Balaji Lakshminarayanan, Stephan Hoyer, and R´emi Munos. The cramer distance as a solution to biased wasser- stein gradients.arXiv preprint arXiv:1705.10743, 2017. 5, 6
work page Pith review arXiv 2017
-
[5]
Tax: Tendency-and-assignment ex- plainer for semantic segmentation with multi-annotators
Yuan-Chia Cheng, Zu-Yun Shiau, Fu-En Yang, and Yu- Chiang Frank Wang. Tax: Tendency-and-assignment ex- plainer for semantic segmentation with multi-annotators. arXiv preprint arXiv:2302.09561, 2023. 3
-
[6]
Veronika Cheplygina, Marleen de Bruijne, and Josien PW Pluim. Not-so-supervised: a survey of semi-supervised, multi-instance, and transfer learning in medical image anal- ysis.Medical Image Analysis, 54:280–296, 2019. 1
work page 2019
-
[7]
Steffen Czolbe, Kasra Arnavaz, Oswin Krause, and Aasa Feragen. Is segmentation uncertainty useful? InInforma- tion Processing in Medical Imaging (IPMI), pages 715–726. Springer, 2021. 11
work page 2021
-
[8]
Chaowei Fang, Qian Wang, Lechao Cheng, Zhifan Gao, Chengwei Pan, Zhen Cao, Zhaohui Zheng, and Dingwen Zhang. Reliable mutual distillation for medical image seg- mentation under imperfect annotations.IEEE Transactions on Medical Imaging, 42(6):1720–1734, 2023. 19
work page 2023
-
[9]
Who said what: Modeling individual labelers im- proves classification
Melody Guan, Varun Gulshan, Andrew Dai, and Geoffrey Hinton. Who said what: Modeling individual labelers im- proves classification. InProceedings of the AAAI conference on artificial intelligence, 2018. 3
work page 2018
-
[10]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 1321–1330, 2017. 14
work page 2017
-
[11]
Visual attention network.Compu- tational visual media, 9(4):733–752, 2023
Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, and Shi-Min Hu. Visual attention network.Compu- tational visual media, 9(4):733–752, 2023. 5
work page 2023
-
[12]
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co- teaching: Robust training of deep neural networks with ex- tremely noisy labels.Advances in neural information pro- cessing systems, 31, 2018. 19
work page 2018
-
[13]
Qingqiao Hu, Hao Wang, Jing Luo, Yunhao Luo, Zhi- heng Zhangg, Jan S Kirschke, Benedikt Wiestler, Bjoern Menze, Jianguo Zhang, and Hongwei Bran Li. Inter-rater uncertainty quantification in medical image segmentation via rater-specific bayesian neural networks.arXiv preprint arXiv:2306.16556, 2023. 3
-
[14]
Kvasir-seg: A segmented polyp dataset
Debesh Jha, Pia H Smedsrud, Michael A Riegler, P ˚al Halvorsen, Thomas De Lange, Dag Johansen, and H˚avard D Johansen. Kvasir-seg: A segmented polyp dataset. InIn- ternational conference on multimedia modeling, pages 451–
-
[15]
Learning calibrated medical image segmentation via multi- rater agreement modeling
Wei Ji, Shuang Yu, Junde Wu, Kai Ma, Cheng Bian, Qi Bi, Jingjing Li, Hanruo Liu, Li Cheng, and Yefeng Zheng. Learning calibrated medical image segmentation via multi- rater agreement modeling. InCVPR, pages 12341–12351,
-
[16]
Simon Kohl, Bernardino Romera-Paredes, Clemens Meyer, Jeffrey De Fauw, Joseph R Ledsam, Klaus Maier-Hein, SM Eslami, Danilo Jimenez Rezende, and Olaf Ronneberger. A probabilistic u-net for segmentation of ambiguous im- ages.Advances in neural information processing systems, 31, 2018. 1, 2, 3, 5, 6, 7, 8, 11, 14, 15
work page 2018
-
[17]
Simon AA Kohl, Bernardino Romera-Paredes, Klaus H Maier-Hein, Danilo Jimenez Rezende, SM Eslami, Pushmeet Kohli, Andrew Zisserman, and Olaf Ronneberger. A hierar- chical probabilistic u-net for modeling multi-scale ambigui- ties.arXiv preprint arXiv:1905.13077, 2019. 2
-
[18]
Annotation ambigu- ity aware semi-supervised medical image segmentation
Suruchi Kumari and Pravendra Singh. Annotation ambigu- ity aware semi-supervised medical image segmentation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10404–10413, 2025. 1, 6
work page 2025
-
[19]
Hongwei Bran Li, Fernando Navarro, Ivan Ezhov, Amirhos- sein Bayat, Dhritiman Das, Florian Kofler, Suprosanna Shit, Diana Waldmannstetter, Johannes C Paetzold, Xi- aobin Hu, et al. Qubiq: Uncertainty quantification for biomedical image segmentation challenge.arXiv preprint arXiv:2405.18435, 2024. 1
-
[20]
Superpixel- guided iterative learning from noisy labels for medical image segmentation
Shuailin Li, Zhitong Gao, and Xuming He. Superpixel- guided iterative learning from noisy labels for medical image segmentation. InInternational Conference on Medical Im- age Computing and Computer-Assisted Intervention, pages 525–535. Springer, 2021. 19
work page 2021
-
[21]
Transformer-based annotation bias-aware medical image segmentation
Zehui Liao, Shishuai Hu, Yutong Xie, and Yong Xia. Transformer-based annotation bias-aware medical image segmentation. InInternational conference on medical image computing and computer-assisted intervention, pages 24–34,
-
[22]
Adaptive early-learning correc- tion for segmentation from noisy annotations
Sheng Liu, Kangning Liu, Weicheng Zhu, Yiqiu Shen, and Carlos Fernandez-Granda. Adaptive early-learning correc- tion for segmentation from noisy annotations. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2606–2616, 2022. 19
work page 2022
-
[23]
Using soft la- bels to model uncertainty in medical image segmentation
Jo ˜ao Lourenc ¸o-Silva and Arlindo L Oliveira. Using soft la- bels to model uncertainty in medical image segmentation. InInternational MICCAI brainlesion workshop, pages 585–
-
[24]
D-lema: Deep learning ensembles from mul- tiple annotations-application to skin lesion segmentation
Zahra Mirikharaji, Kumar Abhishek, Saeed Izadi, and Ghas- san Hamarneh. D-lema: Deep learning ensembles from mul- tiple annotations-application to skin lesion segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 1837–1846, 2021. 2
work page 2021
-
[25]
Miguel Monteiro, Lo ¨ıc Le Folgoc, Daniel Coelho de Castro, Nick Pawlowski, Bernardo Marques, Konstantinos Kamnit- sas, Mark Van der Wilk, and Ben Glocker. Stochastic seg- mentation networks: Modelling spatially correlated aleatoric uncertainty.Advances in neural information processing sys- tems, 33:12756–12767, 2020. 3
work page 2020
-
[26]
Ambiguous medical image segmentation using diffusion models
Aimon Rahman, Jeya Maria Jose Valanarasu, Ilker Haci- haliloglu, and Vishal M Patel. Ambiguous medical image segmentation using diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11536–11546, 2023. 3
work page 2023
-
[27]
Probabilistic modeling of inter-and intra-observer variabil- ity in medical image segmentation
Arne Schmidt, Pablo Morales- ´Alvarez, and Rafael Molina. Probabilistic modeling of inter-and intra-observer variabil- ity in medical image segmentation. InICCV, pages 21097– 21106, 2023. 7, 8
work page 2023
-
[28]
Ewout W. Steyerberg, Andrew J. Vickers, Nancy R. Cook, Thomas Gerds, Mithat Gonen, Nancy Obuchowski, Michael J. Pencina, and Michael W. Kattan. Assessing the performance of prediction models: a framework for some traditional and novel measures.Epidemiology, 21(1):128– 138, 2010. 14
work page 2010
-
[29]
Learning from noisy labels by regularized estimation of annotator confu- sion
Ryutaro Tanno, Ardavan Saeedi, Swami Sankaranarayanan, Daniel C Alexander, and Nathan Silberman. Learning from noisy labels by regularized estimation of annotator confu- sion. InCVPR, pages 11244–11253, 2019. 8
work page 2019
-
[30]
MM Amaan Valiuddin, Christiaan GA Viviers, Ruud JG Van Sloun, Peter HN De With, and Fons van der Som- men. Investigating and improving latent density segmenta- tion models for aleatoric uncertainty quantification in medi- cal imaging.IEEE Transactions on Medical Imaging, 2024. 2
work page 2024
-
[31]
Multi-rater prompting for ambiguous medical image segmentation
Jinhong Wang, Yi Cheng, Jintai Chen, Hongxia Xu, Danny Chen, and Jian Wu. Multi-rater prompting for ambiguous medical image segmentation. InIEEE International Con- ference on Bioinformatics and Biomedicine (BIBM) 2024,
work page 2024
-
[32]
Lin Wang, Xiufen Ye, Lie Ju, Wanji He, Donghao Zhang, Xin Wang, Yelin Huang, Wei Feng, Kaimin Song, and Zongyuan Ge. Medical matting: Medical image segmen- tation with uncertainty from the matting perspective.Com- puters in Biology and Medicine, 158:106714, 2023. 6
work page 2023
-
[33]
Tao Wang, Zhenxuan Zhang, Yuanbo Zhou, Xinlin Zhang, Yuanbin Chen, Tao Tan, Guang Yang, and Tong Tong. From noisy labels to intrinsic structure: A geometric-structural dual-guided framework for noise-robust medical image seg- mentation.arXiv preprint arXiv:2509.02419, 2025. 6, 8, 17, 19
-
[34]
Symmetric cross entropy for robust learning with noisy labels
Yisen Wang, Xingjun Ma, Zaiyi Chen, Yuan Luo, Jinfeng Yi, and James Bailey. Symmetric cross entropy for robust learning with noisy labels. InICCV, pages 322–330, 2019. 19
work page 2019
-
[35]
Yifeng Wang, Luyang Luo, Mingxiang Wu, Qiong Wang, and Hao Chen. Learning robust medical image segmenta- tion from multi-source annotations.Medical Image Analysis, 101:103489, 2025. 1
work page 2025
-
[36]
Simon K Warfield, Kelly H Zou, and William M Wells. Si- multaneous truth and performance level estimation (staple): an algorithm for the validation of image segmentation.IEEE transactions on medical imaging, 23(7):903–921, 2004. 1, 2
work page 2004
-
[37]
Com- bating noisy labels by agreement: A joint training method with co-regularization
Hongxin Wei, Lei Feng, Xiangyu Chen, and Bo An. Com- bating noisy labels by agreement: A joint training method with co-regularization. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 13726–13735, 2020. 19
work page 2020
-
[38]
Junde Wu, Yu Zhang, Huihui Fang, Lixin Duan, Mingkui Tan, Weihua Yang, Chunhui Wang, Huiying Liu, Yueming Jin, and Yanwu Xu. Calibrate the inter-observer segmenta- tion uncertainty via diagnosis-first principle.IEEE Transac- tions on Medical Imaging, 43(9):3331–3342, 2024. 2
work page 2024
-
[39]
Diversified and personalized multi-rater medical image segmentation
Yicheng Wu, Xiangde Luo, Zhe Xu, Xiaoqing Guo, Lie Ju, Zongyuan Ge, Wenjun Liao, and Jianfei Cai. Diversified and personalized multi-rater medical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 11470–11479, 2024. 2, 3, 6, 7, 8, 11, 14, 15, 19, 22
work page 2024
-
[40]
Robust early-learning: Hindering the memorization of noisy labels
Xiaobo Xia, Tongliang Liu, Bo Han, Chen Gong, Nannan Wang, Zongyuan Ge, and Yi Chang. Robust early-learning: Hindering the memorization of noisy labels. InInternational conference on learning representations, 2020. 19
work page 2020
-
[41]
Confidence con- tours: Uncertainty-aware annotation for medical semantic segmentation
Andre Ye, Quan Ze Chen, and Amy Zhang. Confidence con- tours: Uncertainty-aware annotation for medical semantic segmentation. InProceedings of the AAAI Conference on Human Computation and Crowdsourcing, pages 186–197,
-
[42]
That label’s got style: Handling label style bias for uncertain image segmentation
Kilian Zepf, Eike Petersen, Jes Frellsen, and Aasa Feragen. That label’s got style: Handling label style bias for uncertain image segmentation. InProc. International Conference on Learning Representations (ICLR), 2023. 3
work page 2023
-
[43]
Han Zhang, Xiangde Luo, Yong Chen, and Kang Li. Diffoseg: Omni medical image segmentation via multi- expert collaboration diffusion model.arXiv preprint arXiv:2507.13087, 2025. 2, 3
-
[44]
Le Zhang, Ryutaro Tanno, Mou-Cheng Xu, Chen Jin, Joseph Jacob, Olga Cicarrelli, Frederik Barkhof, and Daniel Alexan- der. Disentangling human error from ground truth in segmen- tation of medical images.Advances in Neural Information Processing Systems, 33:15750–15762, 2020. 3, 6, 8
work page 2020
-
[45]
Xingyue Zhao, Zhongyu Li, Xiangde Luo, Peiqi Li, Peng Huang, Jianwei Zhu, Yang Liu, Jihua Zhu, Meng Yang, Shi Chang, et al. Ultrasound nodule segmentation using asym- metric learning with simple clinical annotation.IEEE Trans- actions on Circuits and Systems for Video Technology, 34 (10):9010–9023, 2024. 19 Supplementary Material To further support our ex...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.