Recognition: no theorem link
Path-Coupled Bellman Flows for Distributional Reinforcement Learning
Pith reviewed 2026-05-12 02:03 UTC · model grok-4.3
The pith
Path-Coupled Bellman Flows learn return distributions by matching flows along source-consistent paths that couple current and successor distributions through shared noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose Path-Coupled Bellman Flows (PCBF), a continuous-time DRL method that learns return distributions with flow matching using source-consistent Bellman-coupled paths: the current path starts from the required base prior at t=0, reaches the Bellman target at t=1, and maintains a pathwise affine relation to the successor flow at intermediate times (without requiring time-t marginals to satisfy a distributional Bellman fixed point for all t). PCBF couples current and successor return flows through shared base noise and uses a λ-parameterized control-variate target: λ=0 recovers an unbiased sample Bellman target, while λ>0 trades controlled bias for variance reduction.
What carries the argument
Source-consistent Bellman-coupled paths that begin at the base prior, end at the Bellman-updated target, and preserve a pathwise affine relation to the successor flow under shared base noise, thereby carrying the distributional update through continuous-time flow matching.
If this is right
- Return distributions are learned without finite-support projections or independent-noise bootstrapping.
- Boundary mismatch at the flow source is avoided by construction of the starting point.
- A single lambda parameter explicitly trades bias for variance reduction in the target.
- Training stability improves on both tractable MRPs and standard OGBench and D4RL tasks.
- Offline RL performance remains competitive while distributional fidelity increases.
Where Pith is reading between the lines
- The same coupling idea could be tested in online RL where the policy and value estimates evolve jointly.
- Pathwise affine relations may simplify variance reduction in other generative models that must respect recursive updates.
- Exact marginal fixed points at every time step appear unnecessary if endpoint and coupling conditions hold.
- The method links classical control-variate techniques directly to continuous-time flow matching.
Load-bearing premise
That an affine pathwise relation together with shared base noise is enough to keep Bellman updates distributionally correct even when intermediate marginals are not required to be fixed points.
What would settle it
On an analytically solvable Markov reward process, compute the true return distributions exactly; if PCBF with lambda greater than zero produces Wasserstein distances or quantile errors no smaller than an independent-noise flow baseline, the coupling claim would be falsified.
Figures

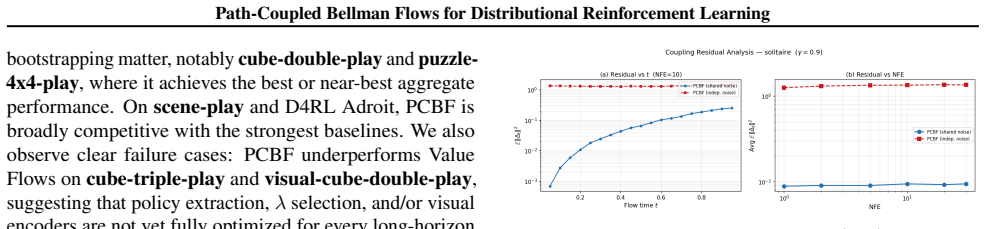






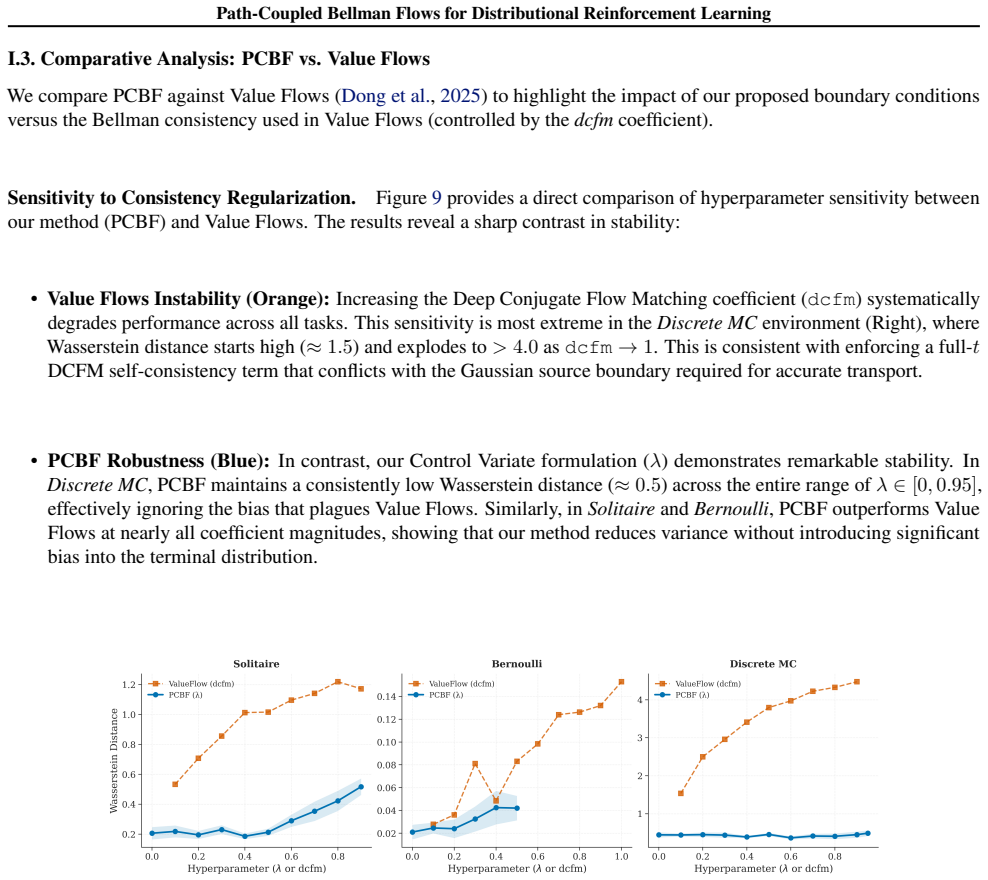
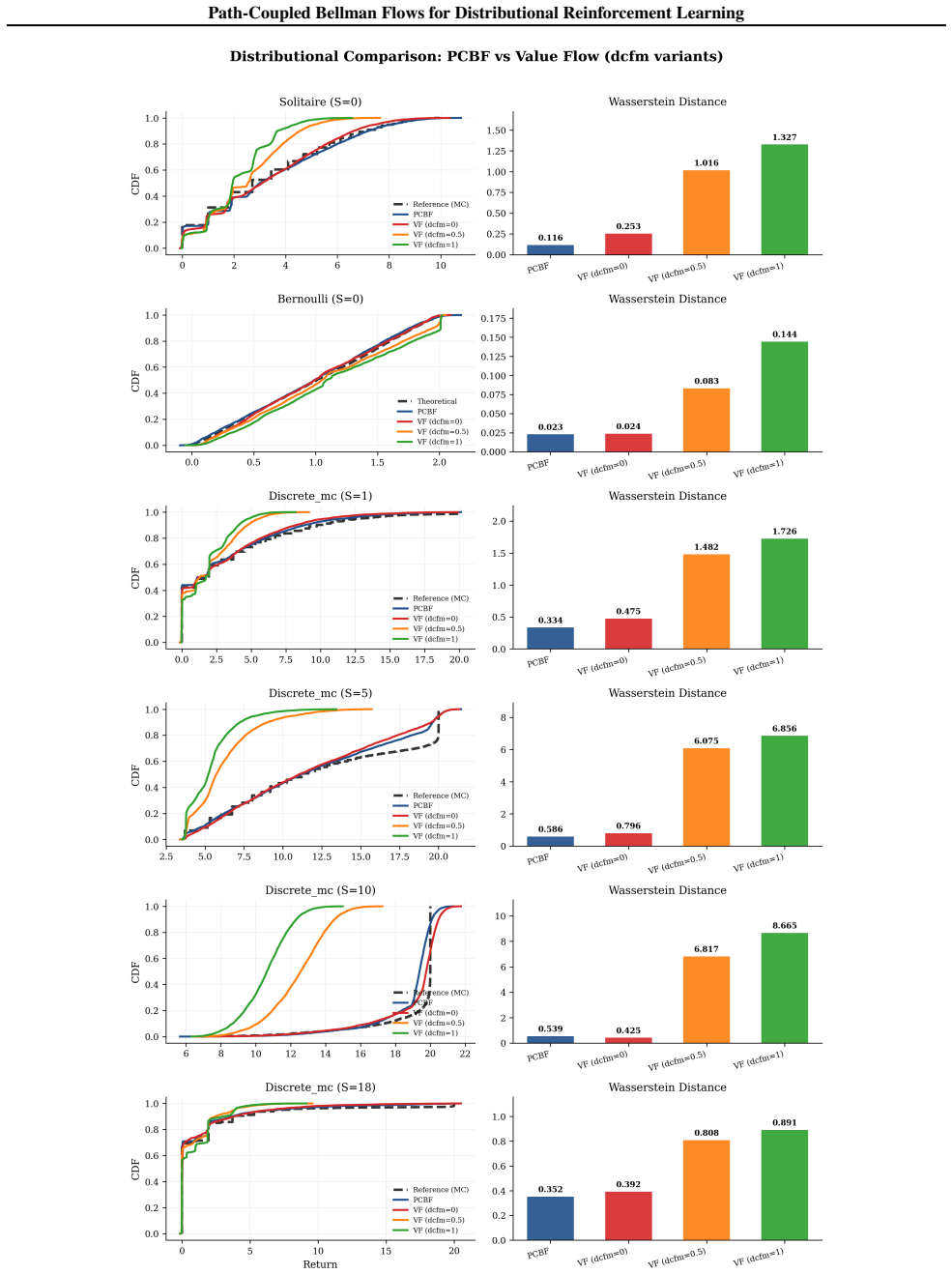

read the original abstract
Distributional reinforcement learning (DRL) models the full return distribution, but existing finite-support or quantile-based methods rely on projections, while recent flow-based approaches can suffer from \emph{boundary mismatch} at the flow source or from \emph{high-variance} bootstrapping when current and successor noises are independent. We propose Path-Coupled Bellman Flows (PCBF), a continuous-time DRL method that learns return distributions with flow matching using \textbf{source-consistent Bellman-coupled paths}: the current path starts from the required base prior at $t{=}0$, reaches the Bellman target at $t{=}1$, and maintains a pathwise affine relation to the successor flow at intermediate times (without requiring time-$t$ marginals to satisfy a distributional Bellman fixed point for all $t$). PCBF couples current and successor return flows through shared base noise and uses a $\lambda$-parameterized control-variate target: $\lambda{=}0$ recovers an unbiased sample Bellman target, while $\lambda{>}0$ trades controlled bias for variance reduction. Experiments on analytically tractable MRPs, OGBench, and D4RL show improved distributional fidelity and training stability, and competitive offline RL performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Path-Coupled Bellman Flows (PCBF), a continuous-time distributional reinforcement learning method that learns return distributions via flow matching on source-consistent Bellman-coupled paths. These paths start from a base prior at t=0, reach the Bellman target at t=1, and obey a pathwise affine relation to the successor flow at intermediate times (without requiring time-t marginals to satisfy the distributional Bellman equation for all t). Current and successor flows are coupled through shared base noise, and a lambda-parameterized control-variate target trades controlled bias for variance reduction (lambda=0 recovers an unbiased sample target). Experiments on analytically tractable MRPs, OGBench, and D4RL are reported to show improved distributional fidelity, training stability, and competitive offline RL performance.
Significance. If the pathwise affine coupling and flow-matching objective provably recover the correct distributional Bellman fixed point at t=1, PCBF would offer a principled continuous-time alternative to projection-based or quantile DRL methods, addressing boundary mismatch and independent-noise variance issues. The lambda control variate provides an explicit bias-variance mechanism, and experiments on tractable MRPs could enable external verification of the fixed-point property. This could improve stability in modeling full return distributions for offline RL.
major comments (2)
- [Abstract / §3] Abstract and §3 (method description): The central claim relies on the pathwise affine relation inducing the correct pushforward measure under the Bellman operator (r + γZ′) at t=1. No derivation, fixed-point argument, or measure-theoretic guarantee is provided showing that the learned velocity field converges to a marginal whose t=1 distribution satisfies the distributional Bellman equation, given that intermediate marginals are explicitly not required to be fixed points. This is load-bearing for the claim that flow matching recovers the true return distribution rather than a consistent but incorrect one.
- [Abstract] Abstract: The lambda-parameterized control-variate target is described as trading 'controlled bias for variance reduction,' but no analysis or bound is given on how the bias affects the fixed-point convergence or the recovered distribution at t=1. Experiments on tractable MRPs are mentioned but without quantitative results, error bars, or explicit verification that the learned t=1 marginal matches the analytic Bellman target, leaving the bias-variance tradeoff's impact on the core claim unassessable.
minor comments (1)
- [Abstract] Abstract: The phrase 'source-consistent Bellman-coupled paths' is introduced without a concise definition or reference to the precise coupling mechanism (shared base noise) before its use; a short parenthetical or forward reference would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us identify areas where the manuscript can be strengthened. We address each major comment below and have revised the paper to incorporate clarifications, additional derivations, and expanded experimental results.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method description): The central claim relies on the pathwise affine relation inducing the correct pushforward measure under the Bellman operator (r + γZ′) at t=1. No derivation, fixed-point argument, or measure-theoretic guarantee is provided showing that the learned velocity field converges to a marginal whose t=1 distribution satisfies the distributional Bellman equation, given that intermediate marginals are explicitly not required to be fixed points. This is load-bearing for the claim that flow matching recovers the true return distribution rather than a consistent but incorrect one.
Authors: We agree that an explicit derivation is essential for the central claim. In the revised manuscript we have added a new paragraph to §3.2 together with a supporting proposition in Appendix A. The argument proceeds by showing that the source-consistent affine coupling with shared base noise implies that the velocity field learned by flow matching at t=1 exactly transports the base prior to the pushforward measure (r + γZ′)#μ, where μ is the successor marginal; because the coupling is pathwise and the objective is minimized at the endpoint, the t=1 marginal satisfies the distributional Bellman equation even though intermediate marginals are not required to be fixed points. The proposition further establishes uniqueness of the fixed point under standard Lipschitz and contraction assumptions on the MDP, confirming convergence of the learned distribution. revision: yes
-
Referee: [Abstract] Abstract: The lambda-parameterized control-variate target is described as trading 'controlled bias for variance reduction,' but no analysis or bound is given on how the bias affects the fixed-point convergence or the recovered distribution at t=1. Experiments on tractable MRPs are mentioned but without quantitative results, error bars, or explicit verification that the learned t=1 marginal matches the analytic Bellman target, leaving the bias-variance tradeoff's impact on the core claim unassessable.
Authors: We acknowledge the need for explicit analysis and results. The revised manuscript expands the abstract and adds a short bias analysis in §4.1: the λ-control variate is constructed so that its expectation equals the unbiased Bellman target, hence the fixed point remains unchanged; the bias term is bounded by λ times the second-moment of the successor noise. We have also included new quantitative results on the analytically tractable MRPs, reporting Wasserstein-1 distances between the learned t=1 marginal and the closed-form Bellman target together with standard-error bars over five independent seeds. These results show that moderate λ values (e.g., 0.5) improve distributional fidelity while preserving convergence to the correct fixed point. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and description define PCBF via explicit design choices: source-consistent paths that start at a base prior (t=0), reach a Bellman target (t=1), obey a pathwise affine relation to the successor, and couple via shared base noise with a λ-parameterized control variate (λ=0 recovers unbiased sample Bellman target). No equations or text reduce any load-bearing step to a fitted parameter renamed as prediction, a self-definition, or a self-citation chain. Experiments on analytically tractable MRPs provide external grounding independent of the fitted values. The construction is presented as a modeling choice rather than a derivation that collapses to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- lambda
axioms (2)
- domain assumption Existence of a base prior distribution at t=0 and a Bellman target at t=1 for constructing the paths.
- domain assumption The pathwise affine relation between current and successor flows holds at intermediate times without marginal fixed-point requirements.
Reference graph
Works this paper leans on
- [1]
-
[2]
International conference on machine learning , pages=
A distributional perspective on reinforcement learning , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[3]
Proceedings of the AAAI conference on artificial intelligence , volume=
Distributional reinforcement learning with quantile regression , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[4]
Adam: A Method for Stochastic Optimization
A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Gaussian Error Linear Units (GELUs)
Gaussian Error Linear Units (Gelus) , author=. arXiv preprint arXiv:1606.08415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
International conference on machine learning , pages=
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[7]
Flow Q - Learning , May 2025 c
Flow q-learning , author=. arXiv preprint arXiv:2502.02538 , year=
-
[8]
OGBench: Benchmarking Offline Goal-Conditioned RL , volume =
Park, Seohong and Frans, Kevin and Eysenbach, Benjamin and Levine, Sergey , booktitle =. OGBench: Benchmarking Offline Goal-Conditioned RL , volume =
-
[9]
International Conference on Learning Representations (ICLR) , year=
OGBench: Benchmarking Offline Goal-Conditioned RL , author=. International Conference on Learning Representations (ICLR) , year=
-
[10]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
D4rl: Datasets for deep data-driven reinforcement learning , author=. arXiv preprint arXiv:2004.07219 , year=
work page internal anchor Pith review arXiv 2004
-
[11]
Reinforcement learning: An introduction , author=. 1998 , publisher=
work page 1998
-
[12]
Flow Matching for Generative Modeling
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[14]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[15]
International conference on machine learning , pages=
Implicit quantile networks for distributional reinforcement learning , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[16]
Advances in neural information processing systems , volume=
Conservative offline distributional reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[17]
Offline Reinforcement Learning with Implicit Q-Learning
Offline reinforcement learning with implicit q-learning , author=. arXiv preprint arXiv:2110.06169 , year=
work page internal anchor Pith review arXiv
-
[18]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
- [19]
-
[20]
Advances in Neural Information Processing Systems , volume=
The surprising efficiency of temporal difference learning for rare event prediction , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[22]
Diffusion policies as an expressive policy class for offline reinforcement learning
Diffusion policies as an expressive policy class for offline reinforcement learning , author=. arXiv preprint arXiv:2208.06193 , year=
-
[23]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Idql: Implicit q-learning as an actor-critic method with diffusion policies , author=. arXiv preprint arXiv:2304.10573 , year=
work page internal anchor Pith review arXiv
-
[24]
arXiv preprint arXiv:2310.07297 , year=
Score regularized policy optimization through diffusion behavior , author=. arXiv preprint arXiv:2310.07297 , year=
-
[25]
IEEE transactions on neural networks and learning systems , volume=
Distributional soft actor-critic: Off-policy reinforcement learning for addressing value estimation errors , author=. IEEE transactions on neural networks and learning systems , volume=. 2021 , publisher=
work page 2021
-
[26]
Proceedings of the AAAI conference on artificial intelligence , volume=
Distributional reinforcement learning via moment matching , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[27]
Distributed distributional deterministic policy gradients
Distributed distributional deterministic policy gradients , author=. arXiv preprint arXiv:1804.08617 , year=
-
[28]
Flow matching guide and code , author=. arXiv preprint arXiv:2412.06264 , year=
work page internal anchor Pith review arXiv
-
[29]
arXiv preprint arXiv:2510.08218 , year=
Expressive Value Learning for Scalable Offline Reinforcement Learning , author=. arXiv preprint arXiv:2510.08218 , year=
-
[30]
arXiv preprint arXiv:2509.06863 , year=
floq: Training critics via flow-matching for scaling compute in value-based rl , author=. arXiv preprint arXiv:2509.06863 , year=
-
[31]
arXiv preprint arXiv:2410.01796 , year=
Bellman diffusion: Generative modeling as learning a linear operator in the distribution space , author=. arXiv preprint arXiv:2410.01796 , year=
-
[32]
arXiv preprint arXiv:2509.23087 , year=
Unleashing flow policies with distributional critics , author=. arXiv preprint arXiv:2509.23087 , year=
-
[33]
arXiv preprint arXiv:2503.09817 , year=
Temporal difference flows , author=. arXiv preprint arXiv:2503.09817 , year=
-
[34]
Planning with Diffusion for Flexible Behavior Synthesis
Planning with diffusion for flexible behavior synthesis , author=. arXiv preprint arXiv:2205.09991 , year=
work page internal anchor Pith review arXiv
-
[35]
International Conference on Machine Learning , pages=
Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
- [36]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.