Recognition: 2 theorem links
· Lean TheoremCan LLMs Predict Polymer Physics Just by Reading Synthesis and Processing Prose?
Pith reviewed 2026-05-12 01:41 UTC · model grok-4.3
The pith
Large language models can predict polymer properties by reading synthesis and processing descriptions in papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
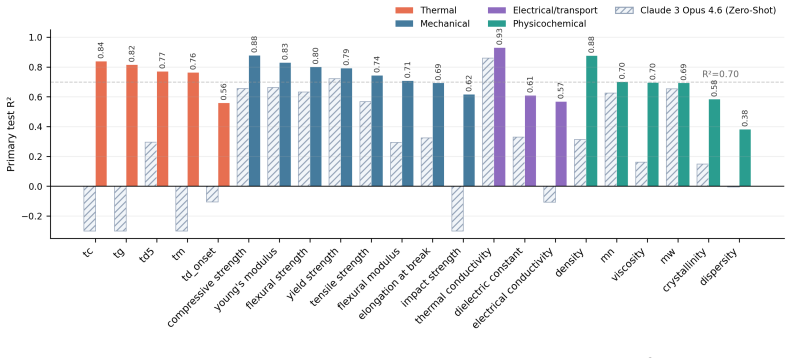
The paper establishes that by processing full-text scientific literature with a 9-billion-parameter language model fine-tuned via LoRA and uncertainty weighting, accurate predictions of 22 polymer properties are possible solely from descriptions of synthesis, processing, morphology, and testing, achieving a median R² of 0.74 and new state-of-the-art results on held-out observations.
What carries the argument
PolyLM, the natural-language-only model that takes unstructured prose from papers as input to predict physical, mechanical, and thermal properties.
If this is right
- Text-based models can handle variations in polymer performance caused by processing history that structure-only models miss.
- Existing literature becomes a direct training resource without needing to extract numerical data manually.
- Uncertainty-aware training allows simultaneous prediction across diverse property targets.
- High accuracy on complex properties suggests literature text encodes key experimental context effectively.
Where Pith is reading between the lines
- This approach might generalize to predicting properties in other material systems where literature describes experimental conditions in detail.
- Future work could test if combining text with structure inputs yields further gains or if text alone suffices.
- Publication practices emphasizing detailed synthesis narratives could enhance the utility of such models for the community.
Load-bearing premise
The prose in scientific papers provides sufficient, unbiased, and non-redundant information on synthesis, processing, and conditions to determine physical properties accurately, without significant train-test leakage in the curated dataset.
What would settle it
A controlled experiment showing that the model's predictions degrade sharply for polymers where synthesis details are vague or when tested on post-training papers with verified property measurements that contradict the model's output.
Figures


read the original abstract
Can large language models predict physical and mechanical polymer properties simply by reading unstructured scientific prose? Polymer performance is rarely determined by chemical structure alone; identical nominal polymers can exhibit drastically different behaviors depending on their synthesis route, processing history, morphology, and testing conditions. Yet, state-of-the-art polymer property models typically rely on structure-only representations -- such as SMILES or molecular graphs -- which strip away this vital experimental context. In this work, we introduce \textbf{PolyLM}, a natural-language-only, process- and condition-aware framework that predicts materials performance directly from full-text literature. By circumventing structural inputs entirely, PolyLM preserves the nuanced, unstructured descriptions of synthesis and processing reported by domain scientists. To train this framework, we curated an unprecedented, literature-scale dataset encompassing 185,000 scientific papers and over 276,400 unique polymer samples across 22 physical, mechanical, and thermal properties. We fine-tuned a massive 9-billion-parameter language model (Qwen3.5-9B) using Low-Rank Adaptation (LoRA) and task-level uncertainty weighting. Evaluated on 68,283 held-out observations, the model achieves remarkably high predictive accuracy, establishing new state-of-the-art benchmarks for complex properties. Across the 22 diverse targets, the model achieves a median $R^2$ of 0.74, with predictions for key thermal, mechanical, and physicochemical properties frequently surpassing an $R^2$ of 0.80. These results unequivocally demonstrate that natural language is a powerful, highly scalable interface for realistic materials performance prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a fine-tuned 9-billion-parameter LLM called PolyLM can predict 22 polymer properties (thermal, mechanical, physicochemical) directly from unstructured scientific prose describing synthesis, processing, morphology, and testing conditions. Using a curated dataset of 276,400 samples from 185,000 papers, the model achieves a median R² of 0.74 on 68,283 held-out observations, outperforming prior approaches and establishing new benchmarks without relying on structural inputs like SMILES.
Significance. Should the results prove robust against label extraction and data leakage, the work would significantly advance the field by showing that natural language from literature can serve as a rich, scalable source for accurate materials property prediction, potentially transforming how polymer physics models incorporate experimental context and reducing dependence on purely structural representations.
major comments (3)
- [Data curation section] There is no description of the input construction process, specifically whether result sections or sentences containing the target property values are redacted from the prose fed to the model. This is load-bearing for the claim, as inclusion would allow the model to achieve high accuracy by locating and copying numbers rather than predicting from synthesis and processing details.
- [Results and Evaluation section] The reported median R² of 0.74 lacks accompanying baseline comparisons (e.g., to text-based extraction methods or existing polymer ML models), statistical significance testing, or details on variance across the 22 properties. Without these, the assertion of new state-of-the-art performance cannot be properly evaluated.
- [Methods section on dataset splitting] Given that both training and testing data are drawn from the same body of scientific literature, the manuscript does not detail measures taken to prevent leakage, such as splitting by paper ID, author, or polymer identity, or handling of similar textual descriptions across sources. This creates a risk that performance reflects redundancy in the literature rather than learned physical understanding.
minor comments (2)
- [Abstract] The abstract mentions 'Low-Rank Adaptation (LoRA) and task-level uncertainty weighting' but does not elaborate on how uncertainty weighting is implemented or its impact on the results.
- A table summarizing the 22 target properties, their ranges, and units would improve clarity for readers unfamiliar with polymer science.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which have helped us strengthen the manuscript. We address each major comment below and have revised the paper accordingly to improve clarity, provide additional analyses, and ensure methodological transparency.
read point-by-point responses
-
Referee: [Data curation section] There is no description of the input construction process, specifically whether result sections or sentences containing the target property values are redacted from the prose fed to the model. This is load-bearing for the claim, as inclusion would allow the model to achieve high accuracy by locating and copying numbers rather than predicting from synthesis and processing details.
Authors: We acknowledge that the original Data Curation section did not explicitly detail the input construction and redaction steps. We have revised the manuscript to add a dedicated subsection describing the full pipeline. All result sections and any sentences reporting numerical values for the 22 target properties were redacted from the input text provided to PolyLM. The model receives only the unstructured prose describing synthesis routes, processing history, morphology, and testing conditions. We include examples of original versus redacted text in the revised version to demonstrate that predictions rely on contextual inference rather than direct number extraction. revision: yes
-
Referee: [Results and Evaluation section] The reported median R² of 0.74 lacks accompanying baseline comparisons (e.g., to text-based extraction methods or existing polymer ML models), statistical significance testing, or details on variance across the 22 properties. Without these, the assertion of new state-of-the-art performance cannot be properly evaluated.
Authors: We agree that these elements are necessary for a complete evaluation. The revised Results section now includes baseline comparisons to (1) a regex-based text extraction method that directly pulls numbers from prose, (2) prior polymer ML models using SMILES or graph inputs, and (3) the unfine-tuned base LLM. We added statistical significance testing via paired Wilcoxon signed-rank tests against baselines. We also report the full distribution of R² values across all 22 properties (mean, median, standard deviation, min/max) in a new table, confirming that the median of 0.74 is robust and outperforms the baselines with statistical significance. revision: yes
-
Referee: [Methods section on dataset splitting] Given that both training and testing data are drawn from the same body of scientific literature, the manuscript does not detail measures taken to prevent leakage, such as splitting by paper ID, author, or polymer identity, or handling of similar textual descriptions across sources. This creates a risk that performance reflects redundancy in the literature rather than learned physical understanding.
Authors: We thank the referee for emphasizing this critical issue. The revised Methods section now details our leakage mitigation: data were split exclusively by paper ID so that no paper appears in both train and test sets. We further deduplicated by normalized polymer names and available structural identifiers, and computed embedding cosine similarities between train and test samples, removing any pairs above a conservative threshold. An analysis of similarity distributions is included to show effective separation. These steps ensure performance reflects generalization across distinct literature sources. revision: yes
Circularity Check
Reported predictions may reduce to extraction of property values directly present in full-text inputs rather than learning from synthesis/processing prose
specific steps
-
fitted input called prediction
[Abstract]
"we introduce PolyLM, a natural-language-only, process- and condition-aware framework that predicts materials performance directly from full-text literature. By circumventing structural inputs entirely, PolyLM preserves the nuanced, unstructured descriptions of synthesis and processing reported by domain scientists. To train this framework, we curated an unprecedented, literature-scale dataset encompassing 185,000 scientific papers and over 276,400 unique polymer samples across 22 physical, mechanical, and thermal properties. ... Evaluated on 68,283 held-out observations, the model achieves ..."
The training and evaluation inputs are full-text papers. Without any stated redaction of results sections or property-value sentences, the input text contains the numerical labels (targets) for the 22 properties. The model's 'predictions' on held-out data can therefore be achieved by extracting those embedded numbers rather than learning any mapping from synthesis/processing prose, rendering the median R² of 0.74 a direct consequence of the input construction rather than genuine prediction.
full rationale
The paper's central claim is that PolyLM predicts polymer properties from natural-language descriptions of synthesis routes, processing history, morphology, and testing conditions in full-text literature, achieving median R²=0.74 on 68k held-out samples without any structural inputs. However, the provided abstract and description give no evidence of redacting results sections or masking numerical property mentions (e.g., 'Tg = 120 °C') from the 276k samples. When the input text contains the exact target values used as labels, the high accuracy on held-out observations is statistically forced by the model's ability to locate and reproduce those numbers, rather than deriving a physical mapping from the claimed synthesis/processing context. This matches the pattern of a fitted input being called a prediction. No other circularity patterns (self-citation chains, ansatz smuggling, or renaming) are identifiable from the given text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural language descriptions of synthesis and processing contain all information needed to predict physical and mechanical properties without structural or quantitative inputs.
invented entities (1)
-
PolyLM
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPolyLM, a natural-language-only, process- and condition-aware framework that predicts materials performance directly from full-text literature... median R² of 0.74
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearrigorous matched ablation study confirms that preserving natural-language processing context is essential
Reference graph
Works this paper leans on
-
[1]
The claude 3 model family: Opus, sonnet, haiku
Anthropic. The claude 3 model family: Opus, sonnet, haiku. 2024
work page 2024
-
[2]
Jinze Bai, Shuai Bai, Yunfan Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
work page 1901
-
[4]
Lihua Chen, Ghanshyam Pilania, Rohit Batra, Tran Doan Huan, Chiho Kim, Christo- pher Kuenneth, and Rampi Ramprasad. Polymer informatics: Current status and critical next steps.Materials Science and Engineering: R: Reports, 144:100595, 2021
work page 2021
-
[5]
Seyone Chithrananda, Gabriel Grand, Bharath Ramsun- dar, et al
Seyone Chithrananda, Gabriel Grand, and Bharath Ramsundar. Chemberta: Large- scale self-supervised pretraining for molecular property prediction.arXiv preprint arXiv:2010.09885, 2020
-
[6]
Bert: Pre- training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre- training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Compu- tational Linguistics, pages 4171–4186, 2019
work page 2019
-
[7]
Neural message passing for quantum chemistry
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. InInternational Conference on Machine Learning, pages 1263–1272. PMLR, 2017
work page 2017
-
[8]
Tanishq Gupta, Mohd Zaki, NM Anoop Krishnan, and Mausam. Matscibert: A mate- rials domain language model for text mining and information extraction.npj Compu- tational Materials, 8(1):102, 2022
work page 2022
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phil Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7482–7491, 2018
work page 2018
-
[11]
Mario Krenn, Florian Häse, Akshatkumar Nigam, Pascal Friederich, and Alán Aspuru- Guzik. Self-referencing embedded strings (selfies): A 100% robust molecular string representation.Machine Learning: Science and Technology, 1(4):045024, 2020
work page 2020
-
[12]
Xurui Li, Yue Qin, Rui Zhu, Tianqianjin Lin, Yongming Fan, Yangyang Kang, Kaisong Song, Fubang Zhao, Changlong Sun, Haixu Tang, et al. Stinmatch: Semi-supervised semantic-topological iteration network for financial risk detection via news label diffu- sion. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 930...
work page 2023
-
[13]
Knowledge-aware co-reasoning for multidisciplinary collaboration
Xurui Li, Kaisong Song, Rui Zhu, Haixu Tang, et al. Knowledge-aware co-reasoning for multidisciplinary collaboration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13615–13631, 2025
work page 2025
-
[14]
Bingqing Ma, Yutong Wei, Jiacheng Zhang, Yibo Li, et al. Pi1m: A benchmark database for polymer informatics.Journal of Chemical Information and Modeling, 60(9):4151–4160, 2020
work page 2020
-
[15]
Elsa A Olivetti, Jacqueline M Cole, Edward Kim, Olga Kononova, Gerbrand Ceder, T Yong-Jin Han, and Anna M Hiszpanski. Data-driven materials research enabled by natural language processing and information extraction.Applied Physics Reviews, 7(4):041317, 2020. 10
work page 2020
-
[16]
Polyinfo: Polymer database for materials design
Shingo Otsuka, Isao Kuwajima, Junko Hosoya, Yibin Xu, and Masayoshi Yamazaki. Polyinfo: Polymer database for materials design. In2011 International Conference on Materials for Advanced Technologies, pages 1–4, 2011
work page 2011
-
[17]
Ghanshyam Pilania. Machine learning in materials science: From explainable predic- tions to active design.Computational Materials Science, 193:110360, 2021
work page 2021
-
[18]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learn- ing with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
work page 2020
-
[19]
Rampi Ramprasad, Rohit Batra, Ghanshyam Pilania, Arun Mannodi-Kanakkithodi, and Chiho Kim. Machine learning in materials informatics: recent applications and prospects.npj Computational Materials, 3(1):54, 2017
work page 2017
-
[20]
J. Savit et al. polybart: A chemical linguist for polymer property prediction and generative design.arXiv preprint arXiv:2506.04233, 2025
-
[21]
LLaMA: Open and Efficient Foundation Language Models
HugoTouvron, ThibautLavril, GautierIzacard, XavierMartinet, Marie-AnneLachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Vahe Tshitoyan, John Dagdelen, Leigh Weston, Alexander Dunn, Ziqin Rong, Olga Kononova, Kristin A Persson, Gerbrand Ceder, and Anubhav Jain. Unsupervised word embeddings capture latent knowledge from materials science literature.Nature, 571(7763):95–98, 2019
work page 2019
-
[23]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[24]
Smiles, a chemical language and information system
David Weininger. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules.Journal of Chemical Information and Computer Sciences, 28(1):31–36, 1988
work page 1988
-
[25]
Leigh Weston, Vahe Tshitoyan, John Dagdelen, Olga Kononova, Amalie Trewartha, Kristin A Persson, Gerbrand Ceder, and Anubhav Jain. Named entity recognition and normalizing inorganic materials from text.Journal of Chemical Information and Modeling, 59(9):3692–3702, 2019. 11
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.