Recognition: no theorem link
Is Class Signal Clustered or Routed in Task-Induced Implicit Neural Representation Weight Spaces?
Pith reviewed 2026-05-12 01:34 UTC · model grok-4.3
The pith
Task-induced INR weights classify by class because the reader routes their signal through specific pathways rather than because the weights form geometric clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
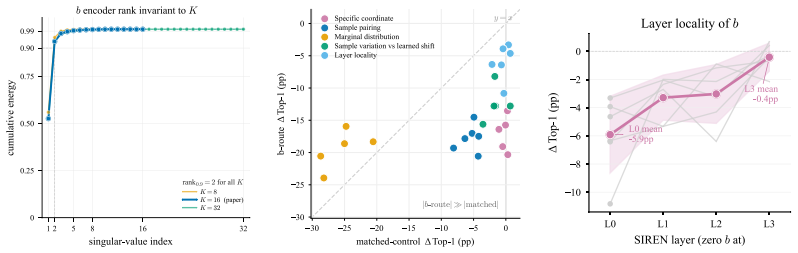
In the SIREN-based Meta Weight Transformer regime, end-to-end meta-training does not produce weight-space geometry whose clustering reliably predicts trained-reader accuracy; local class consistency can increase while reader performance decreases. Token-flow diagnostics demonstrate that class-aligned neighborhoods become predictive only after late reader interactions, not in the input coordinate. The native SIREN bias column in the augmented weight token functions as a sample-dependent causal readout route, and controls rule out generic scalar or marginal artifacts. Route-directed interventions often outperform the baseline under the lane-specific training conventions tested.
What carries the argument
Token-flow diagnostics that track when class alignment emerges in the reader, together with the native SIREN bias column as a low-dimensional causal readout route for the trained reader.
Load-bearing premise
That the token-flow diagnostics and targeted controls on the bias column isolate the routing mechanism without being confounded by the SIREN architecture or the specific training conventions used.
What would settle it
Randomizing or masking only the bias column during reader training while leaving all other weight tokens intact, then measuring whether reader accuracy falls sharply compared with an unmasked control; if accuracy stays high, the routing claim is falsified.
Figures




read the original abstract
Implicit neural representations (INRs) encode images as neural-network weights, making image classification a problem of weight-space classifiability. A natural geometric hypothesis is that classifier feedback should make image-specific weights cluster by class in the shared-anchor coordinate. We test this hypothesis in the SIREN-based Meta Weight Transformer (MWT) regime, where end-to-end training meta-learns a shared initialization and inner-loop update schedule for fitting image-specific SIRENs. We find that this prediction fails. Exposed weight-space geometry and supervised clustering pressure do not reliably track trained-reader accuracy; clustering can even make local neighborhoods more class-consistent while making the trained reader worse. Crucially, the reader constructs rather than inherits class-aligned geometry: token-flow diagnostics show that class-aligned neighborhoods become strongly predictive of trained-reader accuracy only after late reader interactions, not in the input coordinate. We further identify the native SIREN bias column in the augmented weight token as a low-dimensional, sample-dependent causal readout route for the trained reader; targeted controls rule out generic scalar-column and marginal-distribution artifacts. The diagnosis motivates interventions that strengthen reader routing, add an explicit bias route, or use denser inner-loop fitting; under the lane-specific training conventions used here, route-directed variants often outperform the shared-anchor baseline but interact non-additively. Task-induced INR weights are classifiable not because they form raw geometric clusters, but because their class signal is routed through the reader.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper tests the hypothesis that task-induced INR weights (in the SIREN-based Meta Weight Transformer regime) form class-aligned geometric clusters in the shared-anchor coordinate. Using token-flow diagnostics and targeted bias-column ablations, it reports a negative result: raw weight-space geometry and clustering pressure do not track reader accuracy, and class alignment emerges only after late reader interactions. The class signal is instead routed through the reader, with the native SIREN bias column identified as a low-dimensional causal route; interventions that strengthen routing or add explicit bias paths can outperform the baseline under the reported training conventions.
Significance. If the empirical diagnostics hold, the work supplies a concrete negative result against the clustering hypothesis for meta-learned INR weight spaces and shifts attention to reader routing mechanisms. The token-flow analysis and bias-column controls constitute reusable tools for probing weight-space classifiability. The finding that clustering can improve local consistency while harming reader performance is a useful cautionary observation for future meta-learning designs.
major comments (2)
- [§4 and §5.1] §4 (Token-flow diagnostics) and §5.1 (bias ablation): both sets of results are obtained exclusively inside the SIREN + augmented-token MWT regime with its specific inner-loop schedule and shared-anchor initialization. No cross-architecture controls (ReLU MLPs, Fourier-feature INRs, or alternative bases) are reported, so the observed decoupling of raw clustering from reader accuracy could be produced by SIREN sinusoidal bias dynamics or the particular tokenization rather than by task-induced fitting in general.
- [§5.2] §5.2 (intervention experiments): the reported gains from route-directed variants are described as non-additive and dependent on lane-specific conventions. Without an explicit statement of how many random seeds, data splits, or hyperparameter sweeps were used to establish these interactions, it is difficult to assess whether the routing advantage is robust or sensitive to the exact MWT training protocol.
minor comments (2)
- [Abstract] Abstract: the phrase 'lane-specific training conventions' is used without a one-sentence gloss or pointer to the methods section; a brief clarification would improve accessibility.
- [Figure 3, Table 1] Figure 3 and Table 1: axis labels and legend entries for the token-flow plots and clustering metrics should be enlarged or clarified to ensure they remain legible when the paper is viewed at standard column width.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope and robustness of our findings. We address each major comment below.
read point-by-point responses
-
Referee: [§4 and §5.1] §4 (Token-flow diagnostics) and §5.1 (bias ablation): both sets of results are obtained exclusively inside the SIREN + augmented-token MWT regime with its specific inner-loop schedule and shared-anchor initialization. No cross-architecture controls (ReLU MLPs, Fourier-feature INRs, or alternative bases) are reported, so the observed decoupling of raw clustering from reader accuracy could be produced by SIREN sinusoidal bias dynamics or the particular tokenization rather than by task-induced fitting in general.
Authors: We agree that our empirical results are specific to the SIREN-based MWT regime, which is the focus of the study as it represents a standard approach for meta-learning task-induced INRs. The token-flow diagnostics and bias ablations are tailored to this architecture to isolate the routing mechanism. While we acknowledge that cross-architecture validation would strengthen the generality claim, the negative result against the clustering hypothesis holds within this widely-used setup. We will add a dedicated limitations paragraph discussing the potential influence of SIREN-specific dynamics and outlining future work on other INR bases. revision: yes
-
Referee: [§5.2] §5.2 (intervention experiments): the reported gains from route-directed variants are described as non-additive and dependent on lane-specific conventions. Without an explicit statement of how many random seeds, data splits, or hyperparameter sweeps were used to establish these interactions, it is difficult to assess whether the routing advantage is robust or sensitive to the exact MWT training protocol.
Authors: We appreciate this point on reporting standards. The intervention experiments were conducted over 3 independent random seeds with fixed data splits corresponding to the standard train/validation/test partitions of the datasets used. Hyperparameters were selected based on a limited grid search around the baseline configuration, and we observed consistent trends across seeds. To address the concern, we will expand the experimental details section to explicitly state the number of seeds, the variance in performance metrics, and the hyperparameter ranges explored, thereby demonstrating the robustness under the reported conventions. revision: yes
Circularity Check
No circularity: purely empirical hypothesis test with no self-referential derivations
full rationale
The paper tests a geometric clustering hypothesis for task-induced INR weights via token-flow diagnostics, bias-column ablations, and reader accuracy correlations inside the SIREN+MWT regime. No equations, first-principles derivations, or predictions are claimed; all load-bearing steps are experimental observations (e.g., class alignment becomes predictive only after late reader layers). No self-citations, fitted parameters renamed as predictions, or ansatzes appear in the provided text. The result is self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The SIREN-based Meta Weight Transformer regime with its shared initialization and inner-loop schedule produces task-induced weights whose geometry can be meaningfully diagnosed by token-flow and clustering metrics.
Reference graph
Works this paper leans on
-
[1]
Ainsworth, Jonathan Hayase, and Siddhartha S
Samuel K. Ainsworth, Jonathan Hayase, and Siddhartha S. Srinivasa. Git re-basin: Merging models modulo permutation symmetries. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[2]
NeRN: Learning neural representations for neural networks
Maor Ashkenazi, Zohar Rimon, Ron Vainshtein, Shir Levi, Elad Richardson, Pinchas Mintz, and Eran Treister. NeRN: Learning neural representations for neural networks. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[3]
Spatial functa: Scaling functa to ImageNet classification and generation, 2023
Matthias Bauer, Emilien Dupont, Andy Brock, Dan Rosenbaum, Jonathan Richard Schwarz, and Hyunjik Kim. Spatial functa: Scaling functa to ImageNet classification and generation, 2023
work page 2023
-
[4]
Encoding semantic priors into the weights of implicit neural representation
Zhicheng Cai and Qiu Shen. Encoding semantic priors into the weights of implicit neural representation. In2024 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2024. doi: 10.1109/ICME57554.2024.10688197
-
[5]
Emilien Dupont, Hyunjik Kim, S M Ali Eslami, Danilo Rezende, and Dan Rosenbaum. From data to functa: Your data point is a function and you can treat it like one.Proceedings of the 39th International Conference on Machine Learning, (162):5694–5725, 2022
work page 2022
-
[6]
Classifying the classifier: Dissecting the weight space of neural networks
Eilertsen Gabriel, Jönsson Daniel, Ropinski Timo, Unger Jonas, and Ynnerman Anders. Classifying the classifier: Dissecting the weight space of neural networks. InFrontiers in Artificial Intelligence and Applications. IOS Press, 2020. doi: 10.3233/FAIA200209
-
[7]
The role of permutation invariance in linear mode connectivity of neural networks
Rahim Entezari, Hanie Sedghi, Olga Saukh, and Behnam Neyshabur. The role of permutation invariance in linear mode connectivity of neural networks. InThe Tenth International Conference on Learning Representations, 2022
work page 2022
-
[8]
Ziya Erkoç, Fangchang Ma, Qi Shan, Matthias Nießner, and Angela Dai. HyperDiffusion: Generating implicit neural fields with weight-space diffusion. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 14254–14264. IEEE, 2023. doi: 10.1109/ICCV51070.2023.01315
-
[9]
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks.Proceedings of the 34th International Conference on Machine Learning, (70):1126–1135, 2017
work page 2017
-
[10]
What’s in the image? a deep-dive into the vision of vision language models
Alexander Gielisse and Jan Van Gemert. End-to-end implicit neural representations for classification. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18728–18737. IEEE, 2025. doi: 10.1109/CVPR52734.2025.01745
-
[11]
A survey of weight space learning: Understanding, representation, and generation, 2026
Xiaolong Han, Zehong Wang, Bo Zhao, Binchi Zhang, Jundong Li, Damian Borth, Rose Yu, Haggai Maron, Yanfang Ye, Lu Yin, and Ferrante Neri. A survey of weight space learning: Understanding, representation, and generation, 2026
work page 2026
-
[12]
What’s in the image? a deep-dive into the vision of vision language models
Eliahu Horwitz, Bar Cavia, Jonathan Kahana, and Yedid Hoshen. Learning on model weights using tree experts. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20468–20478. IEEE, 2025. doi: 10.1109/CVPR52734.2025.01906
-
[13]
Neil Houlsby, Andrei Giurgiu, Stanisław Jastrzebski, and Bruna Morrone. Parameter-efficient transfer learning for NLP.Proceedings of the 36th International Conference on Machine Learning, (97):2790–2799, 2019
work page 2019
-
[14]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, 2022
work page 2022
-
[15]
Editing models with task arithmetic
Gabriel Ilharco, Marco Túlio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[16]
Deep linear probe generators for weight space learning
Jonathan Kahana, Eliahu Horwitz, Imri Shuval, and Yedid Hoshen. Deep linear probe generators for weight space learning. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[17]
Scale equivariant graph metanetworks
Ioannis Kalogeropoulos, Giorgos Bouritsas, and Yannis Panagakis. Scale equivariant graph metanetworks. InAdvances in Neural Information Processing Systems 37, pages 106800–106840. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2024. doi: 10.52202/079017-3391. 10
-
[18]
Lifting the veil on visual information flow in mllms: Unlocking pathways to faster inference
Alper Kayabasi, Anil Kumar Vadathya, Guha Balakrishnan, and Vishwanath Saragadam. Bias for action: Video implicit neural representations with bias modulation. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27999–28008. IEEE, 2025. doi: 10.1109/CVPR52734. 2025.02607
-
[19]
Supervised contrastive learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. InAdvances in Neural Information Processing Systems, volume 33, pages 18661–18673. Curran Associates, Inc., 2020
work page 2020
-
[20]
Burghouts, Efstratios Gavves, Cees G
Miltiadis Kofinas, Boris Knyazev, Yan Zhang, Yunlu Chen, Gertjan J. Burghouts, Efstratios Gavves, Cees G. M. Snoek, and David W. Zhang. Graph neural networks for learning equivariant representations of neural networks. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[21]
Meta-SGD: Learning to learn quickly for few-shot learning, 2017
Zhenguo Li, Fengwei Zhou, Fei Chen, and Hang Li. Meta-SGD: Learning to learn quickly for few-shot learning, 2017
work page 2017
-
[22]
Law, Jonathan Lorraine, and James Lucas
Derek Lim, Haggai Maron, Marc T. Law, Jonathan Lorraine, and James Lucas. Graph metanetworks for pro- cessing diverse neural architectures. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[23]
Zhen Liu, Hao Zhu, Qi Zhang, Jingde Fu, Weibing Deng, Zhan Ma, Yanwen Guo, and Xun Cao. FINER: Flexible spectral-bias tuning in implicit NEural representation by variableperiodic activation functions. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2713–2722. IEEE, 2024. doi: 10.1109/CVPR52733.2024.00262
-
[24]
ARC: Anchored representa- tion clouds for high-resolution INR classification, 2025
Joost Luijmes, Alexander Gielisse, Roman Knyazhitskiy, and Jan van Gemert. ARC: Anchored representa- tion clouds for high-resolution INR classification, 2025
work page 2025
-
[25]
Paudel, Ender Konukoglu, and Luc Van Gool
Qi Ma, Danda P. Paudel, Ender Konukoglu, and Luc Van Gool. Implicit zoo: A large-scale dataset of neural implicit functions for 2d images and 3d scenes.Advances in Neural Information Processing Systems, 37:88684–88704, 2024. doi: 10.52202/079017-2814
-
[26]
Equivariant architectures for learning in deep weight spaces
Aviv Navon, Aviv Shamsian, Idan Achituve, Ethan Fetaya, Gal Chechik, and Haggai Maron. Equivariant architectures for learning in deep weight spaces. InInternational Conference on Machine Learning, volume 202, pages 25790–25816. PMLR, 2023
work page 2023
-
[27]
Equivariant deep weight space alignment
Aviv Navon, Aviv Shamsian, Ethan Fetaya, Gal Chechik, Nadav Dym, and Haggai Maron. Equivariant deep weight space alignment. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[28]
Samuele Papa, Riccardo Valperga, David Knigge, Miltiadis Kofinas, Phillip Lippe, Jan-Jakob Sonke, and Efstratios Gavves. How to train neural field representations: A comprehensive study and benchmark. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22616–22625. IEEE, 2024. doi: 10.1109/CVPR52733.2024.02134
-
[29]
Vardan Papyan, X. Y . Han, and David L. Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020. doi: 10.1073/pnas.2015509117
-
[30]
William Peebles, Ilija Radosavovic, Tim Brooks, Alexei A. Efros, and Jitendra Malik. Learning to learn with generative models of neural network checkpoints, 2022
work page 2022
-
[31]
Tianming Qiu, Christos Sonis, and Hao Shen. Ensuring semantics in weights of implicit neural representa- tions through the implicit function theorem, 2026
work page 2026
-
[32]
Konstantin Schürholt, Dimche Kostadinov, and Damian Borth. Self-supervised representation learning on neural network weights for model characteristic prediction. InAdvances in Neural Information Processing Systems, volume 34, pages 16481–16493, 2021
work page 2021
-
[33]
Konstantin Schürholt, Boris Knyazev, Xavier Giró-i Nieto, and Damian Borth. Hyper-representations as generative models: Sampling unseen neural network weights.Advances in Neural Information Processing Systems, 35:27906–27920, 2022
work page 2022
-
[34]
Konstantin Schürholt, Diyar Taskiran, Boris Knyazev, Xavier Giró-i Nieto, and Damian Borth. Model zoos: A dataset of diverse populations of neural network models.Advances in Neural Information Processing Systems, 35:38134–38148, 2022
work page 2022
-
[35]
Zhang, Yan Zhang, Ethan Fetaya, Gal Chechik, and Haggai Maron
Aviv Shamsian, Aviv Navon, David W. Zhang, Yan Zhang, Ethan Fetaya, Gal Chechik, and Haggai Maron. Improved generalization of weight space networks via augmentations. InProceedings of the 41st International Conference on Machine Learning, volume 235, pages 44378–44393. PMLR, 2024. 11
work page 2024
-
[36]
Implicit neural representations with periodic activation functions
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. InAdvances in Neural Information Processing Systems, volume 33, pages 7462–7473. Curran Associates, Inc., 2020
work page 2020
-
[37]
Hoang V . Tran, Thieu N. V o, Tho Huu, An Nguyen The, and Tan Minh Nguyen. Monomial matrix group equivariant neural functional networks. InAdvances in Neural Information Processing Systems 37, pages 48628–48665. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2024. doi: 10.52202/079017-1541
-
[38]
Predicting neural network accuracy from weights, 2020
Thomas Unterthiner, Daniel Keysers, Sylvain Gelly, Olivier Bousquet, and Ilya Tolstikhin. Predicting neural network accuracy from weights, 2020
work page 2020
-
[39]
A discriminative feature learning approach for deep face recognition
Yandong Wen, Kaipeng Zhang, Zhifeng Li, and Yu Qiao. A discriminative feature learning approach for deep face recognition. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors,Computer Vision – ECCV 2016, volume 9911, pages 499–515. Springer International Publishing, 2016. doi: 10.1007/ 978-3-319-46478-7_31
work page 2016
-
[40]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
Gizem Yuce, Guillermo Ortiz-Jimenez, Beril Besbinar, and Pascal Frossard. A structured dictionary perspective on implicit neural representations. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19206–19216. IEEE, 2022. doi: 10.1109/CVPR52688.2022.01863
-
[41]
Understanding bias terms in neural representations
Weixiang Zhang, Boxi Li, Shuzhao Xie, Chengwei Ren, Yuan Xue, and Zhi Wang. Understanding bias terms in neural representations. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[42]
Allan Zhou, Kaien Yang, Kaylee Burns, Adriano Cardace, Yiding Jiang, Samuel Sokota, J. Zico Kolter, and Chelsea Finn. Permutation equivariant neural functionals.Advances in Neural Information Processing Systems, 36:24966–24992, 2023
work page 2023
-
[43]
Allan Zhou, Kaien Yang, Yiding Jiang, Kaylee Burns, Winnie Xu, Samuel Sokota, J. Zico Kolter, and Chelsea Finn. Neural functional transformers.Advances in Neural Information Processing Systems, 36: 77485–77502, 2023
work page 2023
-
[44]
Allan Zhou, Chelsea Finn, and James Harrison. Universal neural functionals. InAdvances in Neural Information Processing Systems 37, pages 104754–104775. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2024. doi: 10.52202/079017-3326. 12 A Model definitions and training conventions This appendix records the model definitions and training ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.