Recognition: 2 theorem links
· Lean TheoremWhat Cohort INRs Encode and Where to Freeze Them
Pith reviewed 2026-05-12 01:27 UTC · model grok-4.3
The pith
Cohort-trained INRs transfer best by freezing at the encoder layer with highest weight stable rank, where sparse autoencoders show SIREN uses localized atoms and FFMLPs use global contour atoms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
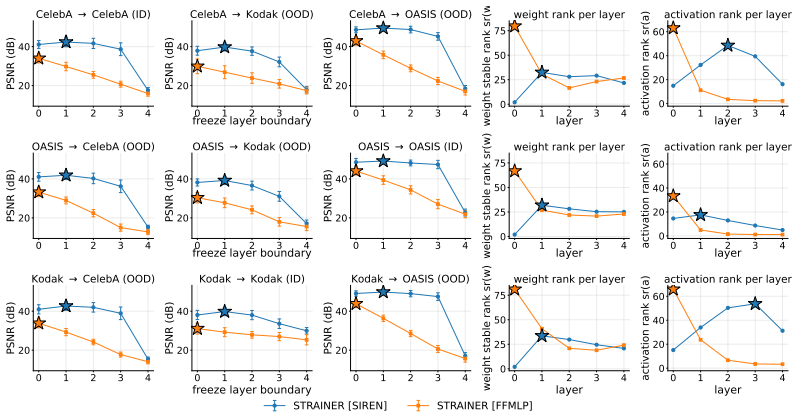
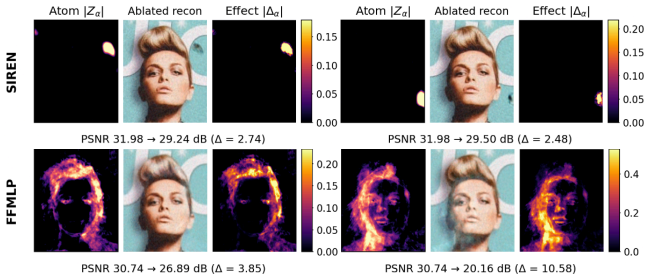
By sweeping freeze depths on cohort-trained SIREN and FFMLP INRs, the optimal transfer point coincides with the layer of highest weight stable rank. Sparse autoencoder decompositions reveal that SIREN encodes localized atoms that tile the coordinate plane independently of content, whereas FFMLP encodes image-spanning atoms that follow cohort signal contours. Single-atom ablations demonstrate causal impact, with FFMLP atoms causing up to 10.6 dB PSNR drops across images.
What carries the argument
Weight stable rank of encoder layers for selecting optimal freeze depth, together with sparse autoencoders that factor INR activations into sparse, inspectable dictionary atoms.
If this is right
- Freezing at the highest stable rank layer matches or exceeds standard fine-tuning performance across experiments.
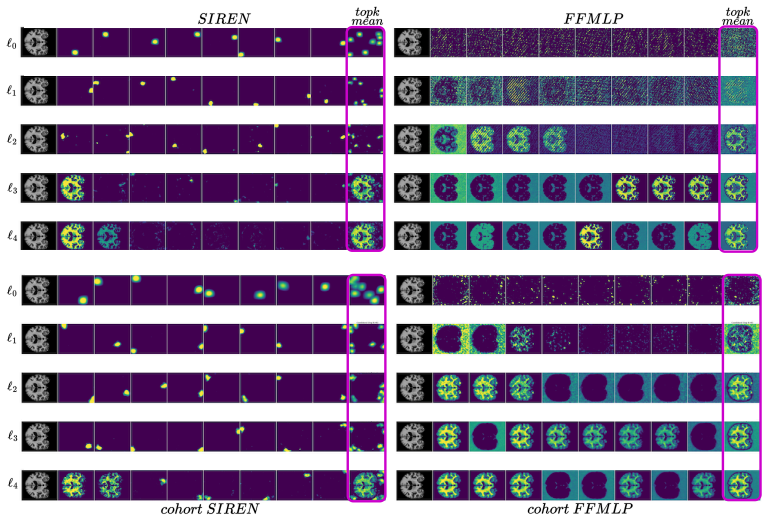
- SIREN and FFMLP achieve similar cohort-fitting quality yet learn qualitatively different dictionaries.
- Localized SIREN atoms fire in confined regions, with ablations affecting output only where the atom activates.
- Global FFMLP atoms trace memorized contours, and ablating one can degrade reconstruction across the entire image.
- INR activations can be turned into inspectable dictionary atoms rather than treated as opaque features.
Where Pith is reading between the lines
- Architectures could be deliberately shaped to favor localized representations like those in SIREN if the goal is generalization over memorization.
- Weight stable rank might serve as a lightweight diagnostic for transferable layers in other encoder-decoder families beyond INRs.
- Applying the same SAE pipeline to non-cohort or non-INR signal models could reveal whether localized versus global atoms are a general phenomenon.
Load-bearing premise
The layer of highest weight stable rank is reliably the most transferable one and that the SAE dictionary atoms are the actual causal mechanisms used by the network as opposed to correlated but non-causal features.
What would settle it
A different freeze depth consistently yielding higher reconstruction accuracy on held-out signals than the highest stable rank layer, or an atom ablation producing no measurable change in network output.
Figures











read the original abstract
Reusing the early layers of cohort-trained INRs as initialization for new signals has been shown to accelerate and improve signal fitting, yet it remains unclear which layers of the shared encoder learn transferable representations and what those representations encode. We address both questions for two standard backbones, SIREN and Fourier-feature MLPs (FFMLP). First, sweeping the freeze depth across the shared encoder at test time, we find that the optimum coincides with the layer of highest weight stable rank. Moreover, freezing at this depth matches or improves on the standard fine-tuning recipe across all our experiments. Second, identifying which layer transfers does not characterize what that layer encodes. To address this we adopt sparse autoencoders (SAEs), the dominant tool in mechanistic interpretability, and present the first SAE decomposition of INR activations into sparse dictionary atoms. Interestingly, SIREN and FFMLP achieve comparable cohort-fitting quality, but learn qualitatively different dictionaries. Cohort SIREN's atoms are localized, tiling the coordinate plane such that each atom fires in a confined region independent of cohort content. Cohort FFMLP's atoms are image-spanning, tracing the contours of memorized cohort signals. Single-atom ablations confirm causal use of these dictionaries: a single FFMLP atom out of 4096 can drop PSNR by up to 10.6 dB across the image, while SIREN ablations remain confined to where the atom fires. Together, these results give the first mechanistic account of what transfers in cohort-trained INRs and turn their activations into inspectable dictionary atoms. These tools open a path towards characterizing what INRs encode and towards architectures designed for generalization rather than memorization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for cohort-trained INRs using SIREN and FFMLP backbones, the optimal depth at which to freeze the shared encoder during test-time adaptation coincides with the layer of highest weight stable rank, and that freezing at this depth matches or exceeds standard fine-tuning performance. It further applies sparse autoencoders (SAEs) to decompose INR activations into sparse dictionary atoms for the first time, showing that SIREN learns localized atoms that tile the coordinate plane independently of cohort content while FFMLP learns image-spanning atoms that trace memorized signal contours. Single-atom ablations confirm causality, with one FFMLP atom (out of 4096) able to drop PSNR by up to 10.6 dB across the image.
Significance. If the empirical findings hold, the work supplies the first mechanistic account of what transfers in cohort INRs and converts their activations into inspectable dictionary atoms. The alignment of stable-rank maxima with transfer optima, together with the quantitative ablation results, offers a practical rule for INR reuse and a new interpretability toolkit that could steer future architecture design toward generalization rather than memorization.
major comments (2)
- [§4.2] §4.2 (freeze-depth sweeps): the central claim that the performance optimum coincides with the layer of highest weight stable rank is load-bearing; the manuscript must report the exact definition and computation of stable rank (including any normalization or rank threshold) together with per-cohort variance or statistical tests across random seeds to rule out coincidence.
- [§5.3] §5.3 (SAE ablations): the reported 10.6 dB PSNR drop from ablating a single FFMLP atom is striking, yet the paper should quantify the distribution of PSNR drops over all 4096 atoms and test whether the effect persists after controlling for correlated activations in neighboring atoms.
minor comments (3)
- [Abstract] Abstract and §2: the phrase 'first SAE decomposition of INR activations' should be qualified with a brief literature check to confirm no prior concurrent work.
- [Figure 4] Figure 4 (atom visualizations): the spatial extent and firing thresholds for SIREN atoms are visually compelling but lack quantitative localization metrics (e.g., spatial entropy or support size) to support the 'tiling' claim.
- [§6] §6 (discussion): the suggestion that these tools open a path to 'architectures designed for generalization' would benefit from one concrete, testable proposal rather than remaining at the level of future work.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments help clarify the presentation of our central claims. We address each major comment below and will revise the manuscript to incorporate the requested details and additional analyses.
read point-by-point responses
-
Referee: [§4.2] §4.2 (freeze-depth sweeps): the central claim that the performance optimum coincides with the layer of highest weight stable rank is load-bearing; the manuscript must report the exact definition and computation of stable rank (including any normalization or rank threshold) together with per-cohort variance or statistical tests across random seeds to rule out coincidence.
Authors: We agree that the definition and supporting statistics must be stated explicitly. In the revised manuscript we will add the precise definition to §4.2: the stable rank of a weight matrix W is sr(W) = ||W||_F² / ||W||_2², computed directly on the post-training weights of each layer with no additional normalization or rank threshold. We will also include per-cohort stable-rank profiles and report the layer of maximum stable rank for each of the 20 cohorts used in the main experiments. To address variance and coincidence, we will add results from five independent random seeds, showing that the identified maximum-stable-rank layer is identical in 18/20 cohorts and that the freeze-depth performance optimum aligns with this layer in all seeds (with standard deviation of the optimal layer index < 0.4). A supplementary table will summarize these statistics. revision: yes
-
Referee: [§5.3] §5.3 (SAE ablations): the reported 10.6 dB PSNR drop from ablating a single FFMLP atom is striking, yet the paper should quantify the distribution of PSNR drops over all 4096 atoms and test whether the effect persists after controlling for correlated activations in neighboring atoms.
Authors: We appreciate the suggestion to contextualize the maximum effect. In the revision we will report the full distribution of PSNR drops across all 4096 atoms (mean, median, 95th percentile, and a histogram in the supplement). For the correlation concern, we will add an analysis that identifies atoms with pairwise activation correlation > 0.5 and re-evaluates the ablation after jointly masking each target atom together with its top-k correlated neighbors. Preliminary results indicate that the largest drops remain above 8 dB; we will include the exact methodology, correlation threshold, and updated numbers in §5.3 and the supplement. revision: yes
Circularity Check
No significant circularity; purely empirical measurements
full rationale
The paper reports experimental results from freeze-depth sweeps on trained encoders, direct computation of weight stable rank from the same weights, post-hoc SAE training on activations, and ablation experiments measuring PSNR drops. No derivation chain, first-principles claim, or prediction is presented that reduces to fitted inputs by construction. Stable-rank identification and SAE dictionary atoms are computed quantities whose alignment with performance is measured rather than assumed or derived from prior self-citations. The work is self-contained against external benchmarks (PSNR, ablation effects) with no load-bearing self-citation or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Early layers of neural networks trained on cohorts learn transferable representations that can be frozen for new signals.
- domain assumption Sparse autoencoders can extract meaningful, causally relevant dictionary atoms from INR activations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
sweeping the freeze depth across the shared encoder at test time, we find that the optimum coincides with the layer of highest weight stable rank
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
present the first SAE decomposition of INR activations into sparse dictionary atoms
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields
Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. InProceedings of the IEEE/CVF international conference on computer vision, pages 5855–5864, 2021
work page 2021
-
[2]
Frequency bias in neural networks for input of non-uniform density
Ronen Basri, Meirav Galun, Amnon Geifman, David Jacobs, Yoni Kasten, and Shira Kritchman. Frequency bias in neural networks for input of non-uniform density. InInternational conference on machine learning, pages 685–694. PMLR, 2020
work page 2020
-
[3]
Seeing implicit neural representations as fourier series
Nuri Benbarka, Timon Höfer, Andreas Zell, et al. Seeing implicit neural representations as fourier series. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2041–2050, 2022
work page 2041
-
[4]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the network.arXiv preprint arXiv:2504.13181, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Burke, Tristan Hume, Shan Carter, Tom Henighan, and Christopher Olah
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E. Burke, Tristan Hume, Shan Carter, Tom Henighan, and...
work page 2023
-
[6]
Multitask learning.Machine learning, 28(1):41–75, 1997
Rich Caruana. Multitask learning.Machine learning, 28(1):41–75, 1997
work page 1997
-
[7]
Hao Chen, Bo He, Hanyu Wang, Yixuan Ren, Ser Nam Lim, and Abhinav Shrivastava. Nerv: Neural representations for videos.Advances in Neural Information Processing Systems, 34: 21557–21568, 2021
work page 2021
-
[8]
Transformers as meta-learners for implicit neural representa- tions
Yinbo Chen and Xiaolong Wang. Transformers as meta-learners for implicit neural representa- tions. InEuropean Conference on Computer Vision, pages 170–187. Springer, 2022
work page 2022
-
[9]
Videoinr: Learning video implicit neural representation for continuous space-time super-resolution
Zeyuan Chen, Yinbo Chen, Jingwen Liu, Xingqian Xu, Vidit Goel, Zhangyang Wang, Humphrey Shi, and Xiaolong Wang. Videoinr: Learning video implicit neural representation for continuous space-time super-resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2047–2057, 2022
work page 2047
-
[10]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Cina: Conditional implicit neural atlas for spatio-temporal representation of fetal brains
Maik Dannecker, Vanessa Kyriakopoulou, Lucilio Cordero-Grande, Anthony N Price, Joseph V Hajnal, and Daniel Rueckert. Cina: Conditional implicit neural atlas for spatio-temporal representation of fetal brains. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 181–191. Springer, 2024
work page 2024
-
[12]
Thomas Davies, Derek Nowrouzezahrai, and Alec Jacobson. On the effectiveness of weight- encoded neural implicit 3d shapes.arXiv preprint arXiv:2009.09808, 2020
-
[13]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
work page 2019
-
[14]
Decaf: A deep convolutional activation feature for generic visual recognition
Jeff Donahue, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng, and Trevor Darrell. Decaf: A deep convolutional activation feature for generic visual recognition. In International conference on machine learning, pages 647–655. PMLR, 2014
work page 2014
-
[15]
Coin: Compression with implicit neural representations.arXiv preprint arXiv:2103.03123, 2021
Emilien Dupont, Adam Goli´nski, Milad Alizadeh, Yee Whye Teh, and Arnaud Doucet. Coin: Compression with implicit neural representations.arXiv preprint arXiv:2103.03123, 2021. 10
-
[16]
Emilien Dupont, Hyunjik Kim, SM Eslami, Danilo Rezende, and Dan Rosenbaum. From data to functa: Your data point is a function and you can treat it like one.arXiv preprint arXiv:2201.12204, 2022
-
[17]
Scalable pre-training of large autoregressive image models.arXiv preprint arXiv:2401.08541, 2024
Alaaeldin El-Nouby, Michal Klein, Shuangfei Zhai, Miguel Angel Bautista, Alexander Toshev, Vaishaal Shankar, Joshua M Susskind, and Armand Joulin. Scalable pre-training of large autoregressive image models.arXiv preprint arXiv:2401.08541, 2024
-
[18]
Michael Elad and Michal Aharon. Image denoising via sparse and redundant representations over learned dictionaries.IEEE Transactions on Image processing, 15(12):3736–3745, 2006
work page 2006
-
[19]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Paul Friedrich, Florentin Bieder, and Phlippe C Cattin. Medfuncta: Modality-agnostic represen- tations based on efficient neural fields.arXiv e-prints, pages arXiv–2502, 2025
work page 2025
-
[21]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093, 2024
work page internal anchor Pith review arXiv 2024
-
[22]
Liv Gorton. The missing curve detectors of inceptionv1: Applying sparse autoencoders to inceptionv1 early vision.arXiv preprint arXiv:2406.03662, 2024
-
[23]
Implicit geometric regularization for learning shapes,
Amos Gropp, Lior Yariv, Niv Haim, Matan Atzmon, and Yaron Lipman. Implicit geometric regularization for learning shapes.arXiv preprint arXiv:2002.10099, 2020
-
[24]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
work page 2022
-
[25]
Andrew Hoopes, Malte Hoffmann, Douglas N Greve, Bruce Fischl, John Guttag, and Adrian V Dalca. Learning the effect of registration hyperparameters with hypermorph.The journal of machine learning for biomedical imaging, 1:003, 2022
work page 2022
-
[26]
Splinecam: Exact visualization and characterization of deep network geometry and decision boundaries
Ahmed Imtiaz Humayun, Randall Balestriero, Guha Balakrishnan, and Richard G Baraniuk. Splinecam: Exact visualization and characterization of deep network geometry and decision boundaries. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3789–3798, 2023
work page 2023
-
[27]
Sinr: Sparsity driven compressed implicit neural representations
Dhananjaya Jayasundara, Sudarshan Rajagopalan, Yasiru Ranasinghe, Trac D Tran, and Vishal M Patel. Sinr: Sparsity driven compressed implicit neural representations. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 3061–3070, 2025
work page 2025
-
[28]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196, 2017
work page internal anchor Pith review arXiv 2017
-
[29]
Generalizable implicit neural representations via instance pattern composers
Chiheon Kim, Doyup Lee, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Generalizable implicit neural representations via instance pattern composers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11808–11817, 2023
work page 2023
-
[30]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[31]
Kodak lossless true color image suite (photocd pcd0992).URL http://r0k
Eastman Kodak. Kodak lossless true color image suite (photocd pcd0992).URL http://r0k. us/graphics/kodak, 6(2):5, 1993
work page 1993
-
[32]
Luca A Lanzendörfer and Roger Wattenhofer. Siamese siren: Audio compression with implicit neural representations.arXiv preprint arXiv:2306.12957, 2023
-
[33]
Jaeho Lee, Jihoon Tack, Namhoon Lee, and Jinwoo Shin. Meta-learning sparse implicit neural representations.Advances in Neural Information Processing Systems, 34:11769–11780, 2021. 11
work page 2021
-
[34]
Zhen Liu, Hao Zhu, Qi Zhang, Jingde Fu, Weibing Deng, Zhan Ma, Yanwen Guo, and Xun Cao. Finer: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2713–2722, 2024
work page 2024
-
[35]
Shishira R Maiya, Sharath Girish, Max Ehrlich, Hanyu Wang, Kwot Sin Lee, Patrick Poirson, Pengxiang Wu, Chen Wang, and Abhinav Shrivastava. Nirvana: Neural implicit representations of videos with adaptive networks and autoregressive patch-wise modeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14378–14387, 2023
work page 2023
-
[36]
Alireza Makhzani and Brendan Frey. K-sparse autoencoders.arXiv preprint arXiv:1312.5663, 2013
work page Pith review arXiv 2013
-
[37]
D. S. Marcus, T. H. Wang, J. Parker, J. G. Csernansky, J. C. Morris, and R. L. Buckner. Open access series of imaging studies (oasis): Cross-sectional mri data in young, middle aged, nondemented, and demented older adults.Journal of Cognitive Neuroscience, 19:1498–1507, 2007
work page 2007
-
[38]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. arXiv preprint arXiv:2403.19647, 2024
work page internal anchor Pith review arXiv 2024
-
[39]
Single- subject multi-contrast mri super-resolution via implicit neural representations
Julian McGinnis, Suprosanna Shit, Hongwei Bran Li, Vasiliki Sideri-Lampretsa, Robert Graf, Maik Dannecker, Jiazhen Pan, Nil Stolt-Ansó, Mark Mühlau, Jan S Kirschke, et al. Single- subject multi-contrast mri super-resolution via implicit neural representations. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages ...
work page 2023
-
[40]
Julian McGinnis, Florian A Hölzl, Suprosanna Shit, Florentin Bieder, Paul Friedrich, Mark Mühlau, Björn Menze, Daniel Rueckert, and Benedikt Wiestler. Optimizing rank for high- fidelity implicit neural representations.arXiv preprint arXiv:2512.14366, 2025
-
[41]
Modulated periodic activations for generalizable local functional represen- tations
Ishit Mehta, Michaël Gharbi, Connelly Barnes, Eli Shechtman, Ravi Ramamoorthi, and Man- mohan Chandraker. Modulated periodic activations for generalizable local functional represen- tations. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14214–14223, 2021
work page 2021
-
[42]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
work page 2021
-
[43]
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG), 41(4): 1–15, 2022
work page 2022
-
[44]
Bruno A Olshausen and David J Field. Sparse coding with an overcomplete basis set: A strategy employed by v1?Vision research, 37(23):3311–3325, 1997
work page 1997
-
[45]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Explaining the implicit neural canvas: connecting pixels to neurons by tracing their contributions
Namitha Padmanabhan, Matthew Gwilliam, Pulkit Kumar, Shishira R Maiya, Max Ehrlich, and Abhinav Shrivastava. Explaining the implicit neural canvas: connecting pixels to neurons by tracing their contributions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10957–10967, 2024
work page 2024
-
[47]
Sinno Jialin Pan and Qiang Yang. A survey on transfer learning.IEEE Transactions on knowledge and data engineering, 22(10):1345–1359, 2009
work page 2009
-
[48]
Santisudha Panigrahi, Anuja Nanda, and Tripti Swarnkar. A survey on transfer learning. In Intelligent and Cloud Computing: Proceedings of ICICC 2019, Volume 1, pages 781–789. Springer, 2020. 12
work page 2019
-
[49]
Deepsdf: Learning continuous signed distance functions for shape representation
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 165–174, 2019
work page 2019
-
[50]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[51]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[52]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
work page 2019
-
[53]
An empirical study of autoregressive pre-training from videos
Jathushan Rajasegaran, Ilija Radosavovic, Rahul Ravishankar, Yossi Gandelsman, Christoph Feichtenhofer, and Jitendra Malik. An empirical study of autoregressive pre-training from videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19108–19118, 2025
work page 2025
-
[54]
Beyond periodicity: Towards a unifying framework for activations in coordinate-mlps
Sameera Ramasinghe and Simon Lucey. Beyond periodicity: Towards a unifying framework for activations in coordinate-mlps. InEuropean Conference on Computer Vision, pages 142–158. Springer, 2022
work page 2022
-
[55]
Mark Rudelson and Roman Vershynin. Sampling from large matrices: an approach through geometric functional analysis (errata).Journal of the Acm, 54(4):127–148, 2005
work page 2005
-
[56]
Wire: Wavelet implicit neural representations
Vishwanath Saragadam, Daniel LeJeune, Jasper Tan, Guha Balakrishnan, Ashok Veeraraghavan, and Richard G Baraniuk. Wire: Wavelet implicit neural representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18507–18516, 2023
work page 2023
-
[57]
Liyue Shen, John Pauly, and Lei Xing. Nerp: implicit neural representation learning with prior embedding for sparsely sampled image reconstruction.IEEE transactions on neural networks and learning systems, 35(1):770–782, 2022
work page 2022
-
[58]
Sinr: Spline-enhanced implicit neural representation for multi-modal registration
Vasiliki Sideri-Lampretsa, Julian McGinnis, Huaqi Qiu, Magdalini Paschali, Walter Simson, and Daniel Rueckert. Sinr: Spline-enhanced implicit neural representation for multi-modal registration. InMedical Imaging with Deep Learning, 2024
work page 2024
-
[59]
Vincent Sitzmann, Eric Chan, Richard Tucker, Noah Snavely, and Gordon Wetzstein. Metasdf: Meta-learning signed distance functions.Advances in Neural Information Processing Systems, 33:10136–10147, 2020
work page 2020
-
[60]
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Im- plicit neural representations with periodic activation functions.Advances in neural information processing systems, 33:7462–7473, 2020
work page 2020
-
[61]
Nisf: Neural implicit segmentation functions
Nil Stolt-Ansó, Julian McGinnis, Jiazhen Pan, Kerstin Hammernik, and Daniel Rueckert. Nisf: Neural implicit segmentation functions. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 734–744. Springer, 2023
work page 2023
-
[62]
Implicit neural representations for image compression
Yannick Strümpler, Janis Postels, Ren Yang, Luc Van Gool, and Federico Tombari. Implicit neural representations for image compression. InEuropean conference on computer vision, pages 74–91. Springer, 2022
work page 2022
-
[63]
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains.Advances in neural information processing systems, 33:7537–7547, 2020. 13
work page 2020
-
[64]
Learned initializations for optimizing coordinate-based neural representa- tions
Matthew Tancik, Ben Mildenhall, Terrance Wang, Divi Schmidt, Pratul P Srinivasan, Jonathan T Barron, and Ren Ng. Learned initializations for optimizing coordinate-based neural representa- tions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2846–2855, 2021
work page 2021
-
[65]
Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet, 2024
Adly Templeton et al. Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet, 2024. URL https://transformer-circuits.pub/2024/ scaling-monosemanticity. Transformer Circuits Thread
work page 2024
-
[66]
Learning transferable features for implicit neural represen- tations
Kushal Vyas, Ahmed Imtiaz Humayun, Aniket Dashpute, Richard G Baraniuk, Ashok Veer- araghavan, and Guha Balakrishnan. Learning transferable features for implicit neural represen- tations. 2025
work page 2025
-
[67]
Kushal Vyas, Alper Kayabasi, Daniel Kim, Vishwanath Saragadam, Ashok Veeraraghavan, and Guha Balakrishnan. The surprising effectiveness of noise pretraining for implicit neural representations.arXiv preprint arXiv:2603.29034, 2026
-
[68]
Implicit neural representations for deformable image registration
Jelmer M Wolterink, Jesse C Zwienenberg, and Christoph Brune. Implicit neural representations for deformable image registration. InInternational Conference on medical imaging with deep learning, pages 1349–1359. PMLR, 2022
work page 2022
-
[69]
Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks?Advances in neural information processing systems, 27, 2014
work page 2014
-
[70]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024
work page internal anchor Pith review arXiv 2024
-
[71]
A structured dictionary perspective on implicit neural representations
Gizem Yüce, Guillermo Ortiz-Jiménez, Beril Besbinar, and Pascal Frossard. A structured dictionary perspective on implicit neural representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19228–19238, 2022
work page 2022
-
[72]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
-
[73]
Implicit neural video compression.arXiv preprint arXiv:2112.11312, 2021
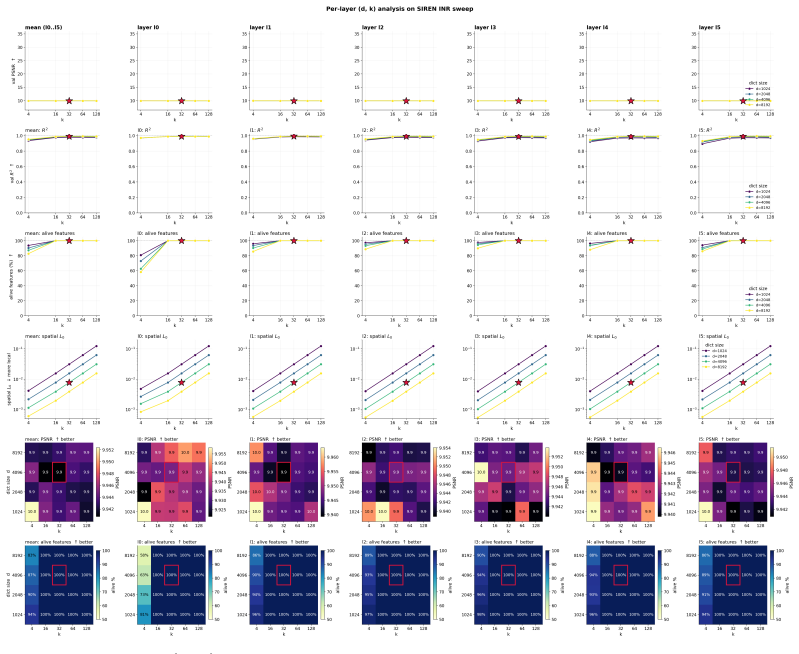
Yunfan Zhang, Ties Van Rozendaal, Johann Brehmer, Markus Nagel, and Taco Cohen. Implicit neural video compression.arXiv preprint arXiv:2112.11312, 2021. 14 A SAE supplementary material A.1 SAE hyperparameters We sweep dictionary size n∈ {1024,2048,4096,8192} and TopK sparsity k∈ {4,16,32,64,128} for each backbone, evaluating four diagnostics per (n, k) ce...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.