Recognition: 2 theorem links
· Lean TheoremPractical Wi-Fi-based Motion Recognition Under Variable Traffic Patterns
Pith reviewed 2026-05-12 00:57 UTC · model grok-4.3
The pith
A transformer-based network with sampling rate augmentation enables reliable Wi-Fi motion recognition despite variable traffic patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
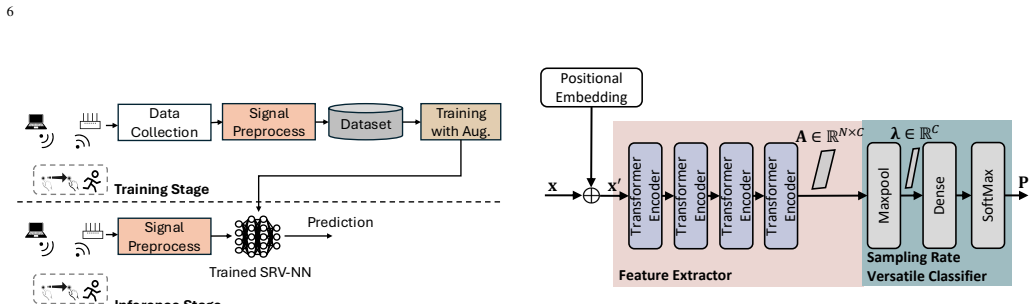
The central discovery is that a sampling rate versatile neural network (SRV-NN) built on transformer architecture, paired with dynamic sampling rate augmentation, can maintain high performance in motion recognition tasks using Wi-Fi CSI even when the sampling rate varies due to traffic. This is validated through extensive experiments demonstrating substantial accuracy gains and reduced variance compared to baselines without such augmentation.
What carries the argument
SRV-NN, a transformer-based neural network that accommodates variable input sizes through its architecture and is trained with dynamic sampling rate augmentation to handle different rates and intervals in CSI data.
If this is right
- The approach allows Wi-Fi sensing to operate without assuming constant sampling rates.
- Models become more stable, with greatly reduced accuracy fluctuations across sampling conditions.
- It supports both gesture and activity recognition applications in variable environments.
- Extensive evaluation confirms improvements over baseline models without augmentation.
Where Pith is reading between the lines
- This could extend to other sensing modalities where sampling is irregular due to external factors.
- Integration with real-time traffic monitoring might further optimize the augmentation strategy.
- Testing on live networks with unpredictable traffic would provide further validation.
Load-bearing premise
The dynamic sampling-rate augmentation and transformer will generalize beyond the sampling rates and traffic patterns in the four evaluated datasets.
What would settle it
Collecting CSI data at sampling rates significantly different from those in the training augmentations and observing if accuracy and stability match the reported improvements or revert to baseline levels.
Figures











read the original abstract
Wi-Fi sensing detects human motions and activities by analysing the channel state information (CSI) derived from Wi-Fi transmissions. However, the impact of variable transmission traffic, which dictates the effective sampling rate and interval, is often overlooked. Existing Wi-Fi sensing systems are trained with fixed input size and sampling rate, which suffer from poor sampling rate generalisation. This paper proposes a novel Wi-Fi sensing approach for motion recognition applications, e.g., gesture and activity recognition, under variable traffic patterns. A sampling rate versatile neural network (SRV-NN) based on the transformer is proposed to efficiently handle variable input-sized sensing signals. A dynamic sampling rate augmentation is employed for variable sampling rates and intervals. To validate our approach, we have carried out extensive experimental evaluation, using two self-collected datasets, namely SRV activity and SRV gesture, as well as two publicly available datasets. Our method demonstrated exceptional performance and stability under variable sampling rates, with substantial improvements in average accuracy compared to baseline models without augmentation. The proposed approach significantly enhances stability by greatly reducing accuracy variance across different sampling rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a transformer-based Sampling Rate Versatile Neural Network (SRV-NN) for Wi-Fi CSI motion recognition (gesture and activity) that accommodates variable input lengths induced by differing transmission traffic patterns. It introduces a dynamic sampling-rate augmentation strategy during training and reports evaluation on two self-collected datasets (SRV activity, SRV gesture) plus two public datasets, claiming substantially higher average accuracy and markedly lower accuracy variance across sampling rates relative to unaugmented baselines.
Significance. If the reported gains and stability improvements prove robust, the work would address a practically important gap in Wi-Fi sensing: existing systems assume fixed sampling rates and degrade under real traffic variability. The transformer architecture for variable-length inputs and the augmentation approach are conceptually well-motivated for this setting, and the use of both self-collected and public datasets is a positive step toward reproducibility.
major comments (4)
- [Abstract, §4] Abstract and §4 (experimental evaluation): the central claims of 'substantial improvements in average accuracy' and 'greatly reducing accuracy variance' are presented without any numerical values, standard deviations, confidence intervals, or statistical significance tests. This absence prevents assessment of effect size and leaves the performance advantage unquantified.
- [§3.2, §4.2] §3.2 (dynamic sampling rate augmentation) and §4.2 (dataset description): no explicit ranges for the simulated sampling rates or traffic intervals are stated, nor is the precise resampling procedure (e.g., interpolation method, rate distribution) described. Without these details the augmentation cannot be reproduced or verified to cover the variable-traffic regime claimed.
- [§4.3] §4.3 (baseline comparison): the manuscript does not specify how the baseline models were adapted (or not) to variable-length inputs, nor whether they received equivalent augmentation. This omission makes it impossible to isolate the contribution of SRV-NN versus the augmentation itself.
- [§4.4] §4.4 (generalization): no out-of-distribution or cross-rate extrapolation experiments are reported (e.g., testing on sampling rates outside the training augmentation range or on traffic patterns absent from the four datasets). The stability claim therefore rests entirely on in-distribution results.
minor comments (2)
- [§3.1] The notation for SRV-NN and the precise transformer modifications (e.g., positional encoding for variable lengths) should be formalized with equations or a clear diagram in §3.1.
- [Figures in §4] Figure captions and axis labels in the results section should explicitly state the sampling-rate values or ranges used in each experiment.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight important areas for improving the clarity and rigor of our manuscript. We address each major comment below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (experimental evaluation): the central claims of 'substantial improvements in average accuracy' and 'greatly reducing accuracy variance' are presented without any numerical values, standard deviations, confidence intervals, or statistical significance tests. This absence prevents assessment of effect size and leaves the performance advantage unquantified.
Authors: We agree that the abstract and experimental summary would benefit from explicit quantitative support. In the revised manuscript, we will update the abstract to include key numerical results (e.g., average accuracy gains of X% with standard deviations) and expand §4 to report per-rate accuracies, variance reductions, standard deviations across trials, and any statistical significance tests (such as paired t-tests) that were performed on the results. revision: yes
-
Referee: [§3.2, §4.2] §3.2 (dynamic sampling rate augmentation) and §4.2 (dataset description): no explicit ranges for the simulated sampling rates or traffic intervals are stated, nor is the precise resampling procedure (e.g., interpolation method, rate distribution) described. Without these details the augmentation cannot be reproduced or verified to cover the variable-traffic regime claimed.
Authors: We acknowledge that additional implementation details are necessary for reproducibility. The revised §3.2 and §4.2 will explicitly state the simulated sampling rate range (e.g., 5–200 Hz corresponding to typical traffic intervals), the traffic interval distributions used, and the precise resampling procedure, including the interpolation method (linear interpolation with anti-aliasing) and the uniform or empirical rate sampling distribution applied during augmentation. revision: yes
-
Referee: [§4.3] §4.3 (baseline comparison): the manuscript does not specify how the baseline models were adapted (or not) to variable-length inputs, nor whether they received equivalent augmentation. This omission makes it impossible to isolate the contribution of SRV-NN versus the augmentation itself.
Authors: We will revise §4.3 to provide a clear description of the baseline adaptations. Each baseline was modified to accept variable-length inputs via zero-padding to the maximum sequence length observed in the batch (or by using their native variable-length support where available), and all baselines were trained both with and without the dynamic sampling-rate augmentation under identical hyperparameter settings. This allows direct isolation of the SRV-NN architecture's contribution. revision: yes
-
Referee: [§4.4] §4.4 (generalization): no out-of-distribution or cross-rate extrapolation experiments are reported (e.g., testing on sampling rates outside the training augmentation range or on traffic patterns absent from the four datasets). The stability claim therefore rests entirely on in-distribution results.
Authors: We agree that explicit OOD evaluation would further validate the stability claims. In the revised manuscript, we will add cross-rate extrapolation experiments in §4.4: models will be trained on a restricted subset of sampling rates within the augmentation range and evaluated on held-out rates (both inside and at the boundaries of the range) using the existing datasets. We will also discuss the limitations of fully novel traffic patterns not represented in the four datasets. revision: yes
Circularity Check
No circularity: empirical ML evaluation with no derivations or self-referential reductions
full rationale
The paper is an empirical machine learning study proposing a transformer-based SRV-NN architecture and dynamic sampling-rate augmentation for Wi-Fi CSI motion recognition. No equations, derivations, or first-principles claims are presented that could reduce outputs to inputs by construction. Performance results are obtained via direct experimental evaluation on two self-collected datasets and two public datasets, with comparisons to baseline models. No self-citation chains, fitted parameters renamed as predictions, or ansatzes smuggled via prior work are evident in the load-bearing steps. The work is self-contained against external benchmarks through dataset-based validation, yielding no significant circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CSI amplitude and phase patterns contain sufficient information to distinguish gestures and activities even after rate variation
- domain assumption Transformer self-attention can learn rate-invariant features when trained with rate-augmented data
Reference graph
Works this paper leans on
-
[1]
Detecting and recog- nizing human-object interactions,
G. Gkioxari, R. Girshick, P. Doll ´ar, and K. He, “Detecting and recog- nizing human-object interactions,” inProc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. (CVPR), June 2018, pp. 8359–8367
work page 2018
-
[2]
Bodyscope: A wearable acoustic sensor for activity recognition,
K. Yatani and K. N. Truong, “Bodyscope: A wearable acoustic sensor for activity recognition,” inProc. ACM Conf. Ubiquitous Comput. (UBICOMP), New York, NY , USA, Sep. 2012, p. 341–350
work page 2012
-
[3]
Wi-Fi sensing on the edge: Signal processing techniques and challenges for real-world systems,
S. M. Hernandez and E. Bulut, “Wi-Fi sensing on the edge: Signal processing techniques and challenges for real-world systems,”IEEE Commun. Surveys Tuts., vol. 25, no. 1, pp. 46–76, 2023
work page 2023
-
[4]
Two-Stream convolution augmented transformer for human activity recognition,
B. Li, W. Cui, W. Wang, L. Zhang, Z. Chen, and M. Wu, “Two-Stream convolution augmented transformer for human activity recognition,” in Proc. Assoc. Advancement Artif. Intell. (AAAI), held virtually, May 2021, pp. 286–293
work page 2021
-
[5]
On spatial diversity in Wi-Fi-based human activity recognition: A deep learning-based approach,
F. Wang, W. Gong, and J. Liu, “On spatial diversity in Wi-Fi-based human activity recognition: A deep learning-based approach,”IEEE Internet Things J., vol. 6, no. 2, pp. 2035–2047, Sep. 2018
work page 2035
-
[6]
F. Meneghello, D. Garlisi, N. Dal Fabbro, I. Tinnirello, and M. Rossi, “SHARP: Environment and person independent activity recognition with commodity IEEE 802.11 access points,”IEEE Trans. Mobile Comput., 2022
work page 2022
-
[7]
WiHF: Gesture and user recognition with Wi-Fi,
C. L. Li, M. Liu, and Z. Cao, “WiHF: Gesture and user recognition with Wi-Fi,”IEEE Trans. Mobile Comput., vol. 21, pp. 1–1, Jul. 2020
work page 2020
-
[8]
Towards position-independent sensing for gesture recognition with Wi-Fi,
R. Gao, M. Zhang, J. Zhang, Y . Li, E. Yi, D. Wu, L. Wang, and D. Zhang, “Towards position-independent sensing for gesture recognition with Wi-Fi,”Proc. ACM Interact. Mobile Wearable Ubiquitous Technol. (IMWUT), vol. 5, no. 2, pp. 1–28, Jun. 2021
work page 2021
-
[9]
SignFi: Sign lan- guage recognition using Wi-Fi,
Y . Ma, G. Zhou, S. Wang, H. Zhao, and W. Jung, “SignFi: Sign lan- guage recognition using Wi-Fi,”Proc. ACM Interact. Mobile Wearable Ubiquitous Technol. (IMWUT), vol. 2, no. 1, pp. 1–21, Mar. 2018
work page 2018
-
[10]
Widar3.0: Zero-effort cross-domain gesture recognition with Wi-Fi,
Y . Zhang, Y . Zheng, K. Qian, G. Zhang, Y . Liu, C. Wu, and Z. Yang, “Widar3.0: Zero-effort cross-domain gesture recognition with Wi-Fi,” IEEE Trans. Pattern Anal. Mach. Intell., pp. 1–1, Aug. 2021
work page 2021
-
[11]
An overview on IEEE 802.11 bf: WLAN sensing,
R. Du, H. Hua, H. Xie, X. Song, Z. Lyu, M. Hu, Y . Xin, S. McCann, M. Montemurro, T. X. Hanet al., “An overview on IEEE 802.11 bf: WLAN sensing,”arXiv preprint arXiv:2310.17661, 2023
-
[12]
Understanding and modeling of Wi-Fi signal based human activity recognition,
W. Wang, A. X. Liu, M. Shahzad, K. Ling, and S. Lu, “Understanding and modeling of Wi-Fi signal based human activity recognition,” in Proc. Annu. Int. Conf. Mobile Comput. Netw. (MobiCom), Sep. 2015, pp. 65–76
work page 2015
-
[13]
A survey on behavior recognition using Wi-Fi channel state information,
S. Yousefi, H. Narui, S. Dayal, S. Ermon, and S. Valaee, “A survey on behavior recognition using Wi-Fi channel state information,”IEEE Commun. Mag., vol. 55, no. 10, pp. 98–104, 2017
work page 2017
-
[14]
CrossSense: Towards cross-site and large-scale Wi-Fi sensing,
J. Zhang, Z. Tang, M. Li, D. Fang, P. Nurmi, and Z. Wang, “CrossSense: Towards cross-site and large-scale Wi-Fi sensing,” inProc. Annu. Int. Conf. Mobile Comput. Netw. (MobiCom), Oct. 2018, pp. 305–320
work page 2018
-
[15]
Pushing the limits of Wi-Fi sensing with low transmission rates,
X. Zheng, K. Yang, J. Xiong, L. Liu, and H. Ma, “Pushing the limits of Wi-Fi sensing with low transmission rates,”IEEE Trans. Mobile Comput., 2024
work page 2024
-
[16]
SenCom: Integrated sensing and communication with practical Wi-Fi,
Y . He, J. Liu, M. Li, G. Yu, J. Han, and K. Ren, “SenCom: Integrated sensing and communication with practical Wi-Fi,” inProc. Annu. Int. Conf. Mobile Comput. Netw. (MobiCom), 2023, pp. 1–16
work page 2023
-
[17]
FallDeFi: Ubiquitous fall detection using commodity Wi-Fi devices,
S. Palipana, D. Rojas, P. Agrawal, and D. Pesch, “FallDeFi: Ubiquitous fall detection using commodity Wi-Fi devices,”Proc. ACM Interact. Mobile Wearable Ubiquitous Technol. (IMWUT), vol. 1, no. 4, 2018
work page 2018
-
[18]
Smokey: Ubiquitous smoking detection with commercial Wi-Fi infrastructures,
X. Zheng, J. Wang, L. Shangguan, Z. Zhou, and Y . Liu, “Smokey: Ubiquitous smoking detection with commercial Wi-Fi infrastructures,” inProc. IEEE Int. Conf. Comput. Commun. (INFOCOM), 2016, pp. 1–9
work page 2016
-
[19]
WiDFF-ID: Device- free fast person identification using commodity Wi-Fi,
Z. Wu, X. Xiao, C. Lin, S. Gong, and L. Fang, “WiDFF-ID: Device- free fast person identification using commodity Wi-Fi,”IEEE Trans. on Cogn. Commun. Netw., vol. 9, no. 1, pp. 198–210, 2023
work page 2023
-
[20]
AutoFi: Toward automatic Wi-Fi human sensing via geometric self-supervised learning,
J. Yang, X. Chen, H. Zou, D. Wang, and L. Xie, “AutoFi: Toward automatic Wi-Fi human sensing via geometric self-supervised learning,” IEEE Internet Things J., vol. 10, no. 8, pp. 7416–7425, 2022
work page 2022
-
[21]
E-eyes: device-free location-oriented activity identification using fine-grained Wi-Fi signatures,
Y . Wang, J. Liu, Y . Chen, M. Gruteser, J. Yang, and H. Liu, “E-eyes: device-free location-oriented activity identification using fine-grained Wi-Fi signatures,” inProc. Annual Int. Conf. Mobile Computing and Networking, Maui, Hawaii, Sep. 2014, pp. 617–628
work page 2014
-
[22]
Commercial Wi-Fi based fall detection with environment influence mitigation,
L. Zhang, Z. Wang, and L. Yang, “Commercial Wi-Fi based fall detection with environment influence mitigation,” inProc. Annu. IEEE Int. Conf. Sens. Commun. Netw. (SECON), Massachusetts, USA, Jun. 2019, pp. 1–9
work page 2019
-
[23]
Widff-id: Device-free fast person identification using commodity wifi,
Z. Wu, X. Xiao, C. Lin, S. Gong, and L. Fang, “Widff-id: Device-free fast person identification using commodity wifi,”IEEE Trans. on Cogn. Commun. Netw., Nov. 2022
work page 2022
-
[24]
Gait recognition using Wi- Fi signals,
W. Wang, A. X. Liu, and M. Shahzad, “Gait recognition using Wi- Fi signals,” inProc. ACM Int. Jt. Conf. Pervasive Ubiquitous Com- put.(UBICOMP), New York, NY , USA, Sep. 2016, p. 363–373
work page 2016
-
[25]
FewSense, towards a scalable and cross-domain Wi-Fi sensing system using few-shot learning,
G. Yin, J. Zhang, G. Shen, and Y . Chen, “FewSense, towards a scalable and cross-domain Wi-Fi sensing system using few-shot learning,”IEEE Trans. Mobile Comput., 2022
work page 2022
-
[26]
Wi-Fi sensing with channel state information: A survey,
Y . Ma, G. Zhou, and S. Wang, “Wi-Fi sensing with channel state information: A survey,”ACM Comput. Surv., vol. 52, no. 3, pp. 1–36, 2019
work page 2019
-
[27]
Wi-Fi CSI based passive human activity recognition using attention based BLSTM,
Z. Chen, L. Zhang, C. Jiang, Z. Cao, and W. Cui, “Wi-Fi CSI based passive human activity recognition using attention based BLSTM,”IEEE Trans. Mobile Comput., vol. 18, no. 11, pp. 2714–2724, 2018
work page 2018
-
[28]
SenseFi: A library and benchmark on deep-learning-empowered Wi-Fi human sensing,
J. Yang, X. Chen, H. Zou, C. X. Lu, D. Wang, S. Sun, and L. Xie, “SenseFi: A library and benchmark on deep-learning-empowered Wi-Fi human sensing,”Patterns, vol. 4, no. 3, 2023
work page 2023
-
[29]
Deepseg: Deep-learning- based activity segmentation framework for activity recognition using Wi-Fi,
C. Xiao, Y . Lei, Y . Ma, F. Zhou, and Z. Qin, “Deepseg: Deep-learning- based activity segmentation framework for activity recognition using Wi-Fi,”IEEE Internet Things J., vol. 8, no. 7, pp. 5669–5681, 2021
work page 2021
-
[30]
Caring: Towards collaborative and cross-domain Wi-Fi sensing,
X. Li, F. Song, M. Luo, K. Li, L. Chang, X. Chen, and Z. Wang, “Caring: Towards collaborative and cross-domain Wi-Fi sensing,”IEEE Trans. Mobile Comput., 2023
work page 2023
-
[31]
Segall: A unified active learning framework for wireless sensing data segmen- tation,
N. Zheng, R. Liu, X. Fan, C. Zhang, L. Zhang, and Z. Yin, “Segall: A unified active learning framework for wireless sensing data segmen- tation,”Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 9, no. 3, pp. 1–27, 2025
work page 2025
-
[32]
An imperceptible eavesdropping attack on wifi sensing systems,
L. Lu, M. Chen, J. Yu, Z. Ba, F. Lin, J. Han, Y . Zhu, and K. Ren, “An imperceptible eavesdropping attack on wifi sensing systems,”IEEE/ACM Transactions on Networking, vol. 32, no. 5, pp. 4009–4024, 2024
work page 2024
-
[33]
Evasion attacks and coun- termeasures in deep learning-based wi-fi gesture recognition,
G. Yin, J. Zhang, X. Yi, and X. Wang, “Evasion attacks and coun- termeasures in deep learning-based wi-fi gesture recognition,”IEEE Transactions on Mobile Computing, 2025
work page 2025
-
[34]
MUSE-Fi: Contactless muti-person sensing exploiting near-field Wi-Fi channel variation,
J. Hu, T. Zheng, Z. Chen, H. Wang, and J. Luo, “MUSE-Fi: Contactless muti-person sensing exploiting near-field Wi-Fi channel variation,” in Proc. Annu. Int. Conf. Mobile Comput. Netw. (MobiCom), Oct. 2023, pp. 1–15
work page 2023
-
[35]
CrossSense: Towards cross-site and large-scale Wi-Fi sensing,
J. Zhang, Z. Tang, M. Li, D. Fang, P. Nurmi, and Z. Wang, “CrossSense: Towards cross-site and large-scale Wi-Fi sensing,” inProc. Annu. Int. Conf. Mobile Comput. Netw. (MobiCom), New York, NY , USA, Oct. 2018, pp. 305–320
work page 2018
-
[36]
Context-aware wireless based cross domain gesture recognition,
H. Kang, Q. Zhang, and Q. Huang, “Context-aware wireless based cross domain gesture recognition,”IEEE Internet Things J., vol. 8, no. 17, Mar. 2021
work page 2021
-
[37]
Y . Zhang, A. Cheng, B. Chen, Y . Wang, and L. Jia, “A Location- independent Human Activity Recognition Method Based on CSI: Sys- tem, Architecture, Implementation,”IEEE Trans. Mobile Comput., pp. 1–14, 2023
work page 2023
-
[38]
Adawifi, collaborative wifi sensing for cross- environment adaptation,
N. Zheng, Y . Li, S. Jiang, Y . Li, R. Yao, C. Dong, T. Chen, Y . Yang, Z. Yin, and Y . Liu, “Adawifi, collaborative wifi sensing for cross- environment adaptation,”IEEE Trans. Mobile Comput., 2024. 17
work page 2024
-
[39]
Towards environment independent device free human activity recognition,
W. Jiang, C. Miao, F. Ma, S. Yao, Y . Wang, Y . Yuan, H. Xue, C. Song, X. Ma, D. Koutsonikolaset al., “Towards environment independent device free human activity recognition,” inProc. Annu. Int. Conf. Mobile Comput. Netw. (MobiCom), New Delhi, India, Oct. 2018, pp. 289–304
work page 2018
-
[40]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Adv. Neural Inf. Process. Syst., vol. 30, 2017
work page 2017
-
[41]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 770–778
work page 2016
-
[42]
Tool release: Gath- ering 802.11n traces with channel state information,
D. Halperin, W. Hu, A. Sheth, and D. Wetherall, “Tool release: Gath- ering 802.11n traces with channel state information,”ACM SIGCOMM Comput. Commun. Rev., vol. 41, no. 1, p. 53, Jan. 2011
work page 2011
-
[43]
Free your CSI: A channel state information extraction platform for modern Wi-Fi chipsets,
F. Gringoli, M. Schulz, J. Link, and M. Hollick, “Free your CSI: A channel state information extraction platform for modern Wi-Fi chipsets,” inProc. ACM Inter. Workshop Wireless Netw. Testbeds, Exp. eval. Characterization (WiNTECH), 2019, p. 21–28
work page 2019
-
[44]
Linformer: Self-Attention with Linear Complexity
S. Wang, B. Z. Li, M. Khabsa, H. Fang, and H. Ma, “Linformer: Self-attention with linear complexity,”arXiv preprint arXiv:2006.04768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[45]
Rethinking Attention with Performers
K. Choromanski, V . Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sar- los, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiseret al., “Rethinking attention with performers,”arXiv preprint arXiv:2009.14794, 2020
work page internal anchor Pith review arXiv 2009
-
[46]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.