Recognition: 3 theorem links
· Lean TheoremSDG-MoE: Signed Debate Graph Mixture-of-Experts
Pith reviewed 2026-05-13 07:15 UTC · model grok-4.3
The pith
SDG-MoE lets routed experts deliberate through learned support and critique graphs before aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In SDG-MoE, two learned interaction matrices over the active experts—a support graph A+ and a critique graph A—enable a signed message-passing step that updates expert representations before final aggregation. A disagreement-gated Friedkin-Johnsen-style anchoring controls the strength of deliberation and preserves specialization. Theoretical analysis shows stability conditions and low-order overhead, while empirical results demonstrate improved perplexity on validation and external benchmarks.
What carries the argument
Signed debate graph with support matrix A+ and critique matrix A- that performs message-passing among routed experts, regulated by disagreement-gated anchoring.
If this is right
- The architecture improves validation perplexity by 19.8% over the strongest baseline.
- SDG-MoE achieves the best perplexity on WikiText-103, C4, and Paloma compared to vanilla MoE and unsigned graph baselines.
- Deliberation adds only low-order computational overhead over the active expert set.
- Expert states remain stable under the derived conditions during the iterative updates.
Where Pith is reading between the lines
- The learned matrices may reveal patterns in how experts reinforce or correct each other during processing.
- This interaction mechanism could be adapted to other routing-based models to enhance collaboration without full dense computation.
- Further iterations of deliberation might amplify gains if the anchoring continues to prevent instability at scale.
Load-bearing premise
The learned support and critique matrices combined with disagreement-gated anchoring lead to stable expert states and real performance improvements rather than mere fitting artifacts.
What would settle it
Training larger-scale models with SDG-MoE and verifying if the 19.8% perplexity advantage holds, or conducting ablations where the signed graphs are replaced with random fixed values to check if gains vanish.
Figures





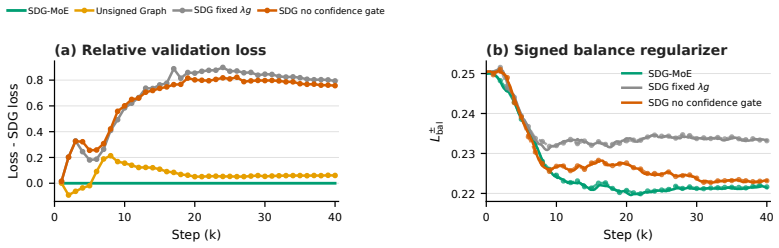

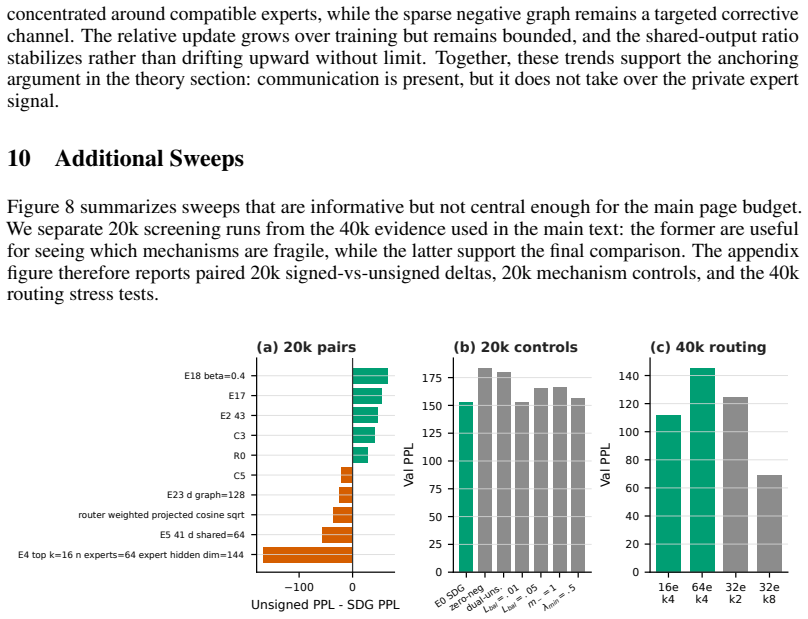
read the original abstract
Sparse MoE models achieve a good balance between capacity and compute by routing each token to a small subset of experts. However, in most MoE architectures, once a token is routed, the selected experts process it independently and their outputs are combined via a weighted sum. This leaves open whether enabling communication among them could improve performance. While prior work has raised this question, direct interaction among the active routed experts remains underexplored. In this paper, we propose SDG-MoE (Signed Debate Graph Mixture-of-Experts), a novel architecture that adds a lightweight, iterative deliberation step before final aggregation. SDG-MoE introduces three components: (i) two learned interaction matrices over the active experts, a support graph $A^+$ and a critique graph $A^-$, capturing reinforcing and corrective influences; (ii) a signed message-passing step that updates expert representations before aggregation; and (iii) a disagreement-gated Friedkin-Johnsen-style anchoring that controls deliberation strength while preventing expert drift. Together, these enable a structured deliberation process where interaction strength scales with disagreement and specialization is preserved. We also provide a theoretical analysis establishing stability conditions on expert states and showing that deliberation adds only low-order overhead over the active set. In controlled three-seed pretraining experiments, SDG-MoE improves validation perplexity over both an unsigned graph communication baseline and vanilla MoE, outperforming the strongest baseline by 19.8%, and gives the best external perplexity on WikiText-103, C4, and Paloma among the compared systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SDG-MoE, a Mixture-of-Experts architecture that augments standard routing with a signed debate graph consisting of learned support matrix A+ and critique matrix A- over the active experts, followed by iterative signed message-passing and a disagreement-gated Friedkin-Johnsen-style anchoring step that modulates deliberation strength. It supplies a theoretical analysis of stability conditions and low-order overhead, and reports that in three-seed pretraining SDG-MoE improves validation perplexity by 19.8% over the strongest baseline while achieving the best external perplexity on WikiText-103, C4, and Paloma.
Significance. If the performance improvements are shown to be robust, the work would provide a concrete mechanism for structured expert communication that preserves specialization while adding only low-order cost, potentially benefiting sparse MoE scaling. The stability analysis and explicit overhead bounds constitute a positive theoretical contribution that goes beyond purely empirical MoE variants.
major comments (2)
- [Experimental results] Experimental results (abstract and §4): the headline 19.8% validation-perplexity gain is reported from three-seed pretraining without variance, standard deviations, or statistical tests; this is load-bearing for the central empirical claim and leaves open whether the improvement is reproducible or an artifact of the narrow experimental regime.
- [Ablation studies] Ablation and component analysis (presumably §4.2–4.3): no ablations are described that remove the signed edges (A+ vs. A-), the disagreement gate, or the anchoring term while keeping other factors fixed; without these controls it is impossible to attribute gains specifically to the deliberation mechanism rather than incidental routing or capacity changes.
minor comments (2)
- [Methods] Notation: the dimensions and initialization of the learned matrices A+ and A- should be stated explicitly (e.g., shape relative to the number of active experts) to aid reproducibility.
- [Figures] Figure clarity: any plots of expert-state trajectories or disagreement evolution should include error bands consistent with the three-seed protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address the two major comments point by point below. We agree that both the statistical reporting of results and the addition of targeted ablations will strengthen the empirical claims, and we will incorporate the suggested changes in the revised version.
read point-by-point responses
-
Referee: [Experimental results] Experimental results (abstract and §4): the headline 19.8% validation-perplexity gain is reported from three-seed pretraining without variance, standard deviations, or statistical tests; this is load-bearing for the central empirical claim and leaves open whether the improvement is reproducible or an artifact of the narrow experimental regime.
Authors: We agree that the current presentation would be strengthened by explicit measures of variability and statistical tests. The three seeds were performed specifically to assess reproducibility under different random initializations, yet we did not report per-seed values, standard deviations, or formal tests in the submitted manuscript. In the revision we will add the individual seed perplexities, compute and report standard deviations across the three runs, and include a paired statistical test (e.g., t-test) against the strongest baseline. These details will appear in §4 with a corresponding update to the abstract. revision: yes
-
Referee: [Ablation studies] Ablation and component analysis (presumably §4.2–4.3): no ablations are described that remove the signed edges (A+ vs. A-), the disagreement gate, or the anchoring term while keeping other factors fixed; without these controls it is impossible to attribute gains specifically to the deliberation mechanism rather than incidental routing or capacity changes.
Authors: We acknowledge that the manuscript does not contain the requested component-wise ablations. While we already compare against an unsigned-graph baseline and vanilla MoE, these controls do not isolate the individual contributions of the signed matrices, disagreement gate, and anchoring term. In the revised version we will add a dedicated ablation subsection that systematically disables each element (A− set to zero, gate removed, anchoring disabled) while holding the routing mechanism and expert capacity fixed. The new results will be reported in §4 to clarify the source of the observed gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines new components (learned support/critique matrices A+ and A-, signed message-passing, disagreement-gated Friedkin-Johnsen anchoring) and trains them end-to-end within the MoE architecture. The central claims are empirical performance gains measured against independent baselines (unsigned graph communication and vanilla MoE) on validation perplexity plus external benchmarks (WikiText-103, C4, Paloma). The provided theoretical analysis derives stability conditions and overhead bounds directly from the model equations without reducing the reported perplexity improvements to a tautology or fitted input. No self-citation load-bearing steps, self-definitional loops, or renamed known results appear in the derivation. The three-seed experiments constitute independent measurements rather than predictions forced by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- support graph A+ and critique graph A-
axioms (1)
- domain assumption Expert states remain stable under the signed message-passing and anchoring rule
invented entities (1)
-
Signed Debate Graph with support and critique matrices
independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel; Jcost_pos_of_ne_one echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
disagreement-gated Friedkin–Johnsen-style anchoring... stability conditions on expert states... signed message-passing step... h(t+1)_i,shr = β h(0)_i,shr + (1−β) h-bar(t+1)_i,shr... q = (1−β)(1 + α g_max C) < 1
-
IndisputableMonolith/Foundation/ArrowOfTime.leanz_monotone_absolute; arrow_from_z echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
signed support graph A+ and criticism graph A−... signed contrast... preventing expert drift... bounded deliberation
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective; LogicNat recovery refines?
refinesRelation between the paper passage and the cited Recognition theorem.
low-order active-set overhead... controlled perturbation of vanilla MoE
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , year =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , year =
-
[2]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =
-
[3]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , journal =
-
[4]
Ben Allal, Loubna and Lozhkov, Anton and Bakouch, Elie , year =
-
[5]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author =. International Conference on Learning Representations , year =. 1701.06538 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Lepikhin, Dmitry and Lee, HyoukJoong and Xu, Yuanzhong and Chen, Dehao and Firat, Orhan and Huang, Yanping and Krikun, Maxim and Shazeer, Noam and Chen, Zhifeng , booktitle =. 2021 , eprint =
work page 2021
-
[7]
Du, Nan and Huang, Yanping and Dai, Andrew M. and Tong, Simon and Lepikhin, Dmitry and Xu, Yuanzhong and Krikun, Maxim and Zhou, Yanqi and Yu, Adams Wei and Firat, Orhan and Zoph, Barret and Fedus, Liam and Bosma, Maarten and Zhou, Zongwei and Wang, Tao and Wang, Yu Emma and Webster, Kellie and Pellat, Marie and Robinson, Kevin and Meier-Hellstern, Kathle...
work page 2022
-
[8]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author =. Journal of Machine Learning Research , year =. 2101.03961 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Zoph, Barret and Bello, Irwan and Kumar, Sameer and Du, Nan and Huang, Yanping and Dean, Jeff and Shazeer, Noam and Fedus, William , year =. 2202.08906 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
Dai, Damai and Deng, Chengqi and Zhao, Chenggang and Xu, R. X. and Gao, Huazuo and Chen, Deli and Li, Jiashi and Zeng, Wangding and Yu, Xingkai and Wu, Y. and Xie, Zhenda and Li, Y. K. and Huang, Panpan and Luo, Fuli and Ruan, Chong and Sui, Zhifang and Liang, Wenfeng , year =. 2401.06066 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Wu, Huijia and Zhao, Hao and Qiu, Zihan and Wang, Zili and He, Zhaofeng and Fu, Jie , year =. 2402.12656 , archivePrefix=
-
[13]
Zhuang, Chenyi and Xie, Zhitian and Zhang, Yinger and Shi, Qitao and Liu, Zhining and Gu, Jinjie and Zhang, Guannan , year =. 2402.00893 , archivePrefix=
-
[14]
Zheng, Zifan and Lv, Bo and Tang, Chen and Yang, Bohao and Zhao, Kun and Liao, Ning and Wang, Xiaoxing and Xiong, Feiyu and Li, Zhiyu and Liu, Nayu and Jiang, Jingchi , year =. 2501.07890 , archivePrefix=
-
[15]
Journal of the American Statistical Association , volume =
Reaching a Consensus , author =. Journal of the American Statistical Association , volume =. 1974 , doi =
work page 1974
-
[16]
Journal of Mathematical Sociology , volume =
Social Influence and Opinions , author =. Journal of Mathematical Sociology , volume =. 1990 , doi =
work page 1990
-
[17]
Yang, An and others , year =. 2505.09388 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
- [18]
-
[19]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author =. 2019 , eprint =
work page 2019
-
[20]
and Richardson, Kyle and Dodge, Jesse , year =
Magnusson, Ian and Bhagia, Akshita and Hofmann, Valentin and Soldaini, Luca and Jha, Ananya Harsh and Tafjord, Oyvind and Schwenk, Dustin and Walsh, Evan Pete and Elazar, Yanai and Lo, Kyle and Groeneveld, Dirk and Beltagy, Iz and Hajishirzi, Hannaneh and Smith, Noah A. and Richardson, Kyle and Dodge, Jesse , year =. 2312.10523 , archivePrefix=
-
[21]
Chain-of-Experts: Unlocking the Communication Power of Mixture-of-Experts Models , author =. 2025 , eprint =
work page 2025
-
[22]
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks , author =. 2018 , eprint =
work page 2018
- [23]
-
[24]
A Survey on Mixture of Experts in Large Language Models , ISSN=
Cai, Weilin and Jiang, Juyong and Wang, Fan and Tang, Jing and Kim, Sunghun and Huang, Jiayi , year=. A Survey on Mixture of Experts in Large Language Models , ISSN=. doi:10.1109/tkde.2025.3554028 , journal=
-
[25]
Modeling Expert Interactions in Sparse Mixture of Experts via Graph Structures , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.