Recognition: no theorem link
LLM Advertisement based on Neuron Auctions
Pith reviewed 2026-05-12 00:47 UTC · model grok-4.3
The pith
Auctions on brand-specific neurons inside LLMs turn internal activations into independent, continuous ad budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Competing brands activate within approximately orthogonal subspaces of the LLM's FFN representations. This near-perfect independence lets the authors define continuous intervention budgets—specifically neuron counts and amplification factors—as auctionable commodities. A continuous menu-based auction built on this carrier guarantees strategy-proofness, optimizes revenue, and explicitly penalizes interventions that reduce user utility.
What carries the argument
Brand-specific FFN neurons whose activations occupy approximately orthogonal subspaces, which serve as the computational carrier for defining continuous, disentangled auction commodities.
If this is right
- The auction can be conducted directly on internal parameters rather than text, preserving natural discourse quality.
- User utility penalties automatically price out overly aggressive interventions during optimization.
- Multiple advertisers can bid on independent commodities without mutual semantic crosstalk.
- Platform revenue is maximized under the joint objective of advertiser payoffs and user satisfaction.
Where Pith is reading between the lines
- The same orthogonal-neuron carrier could be reused for non-ad interventions such as sponsored content or style controls.
- If the orthogonality pattern generalizes across model scales and families, it offers a reusable primitive for any mechanism that needs fine-grained, low-interference control inside LLMs.
- Platforms might extend the menu design to include dynamic user-context variables that further modulate intervention prices.
Load-bearing premise
Competing brands activate within approximately orthogonal subspaces so that neuron-count and amplification interventions remain independent without semantic interference.
What would settle it
An experiment that measures whether increasing the amplification factor on one brand's neurons produces measurable semantic changes or relevance shifts in the output associated with a competing brand.
Figures


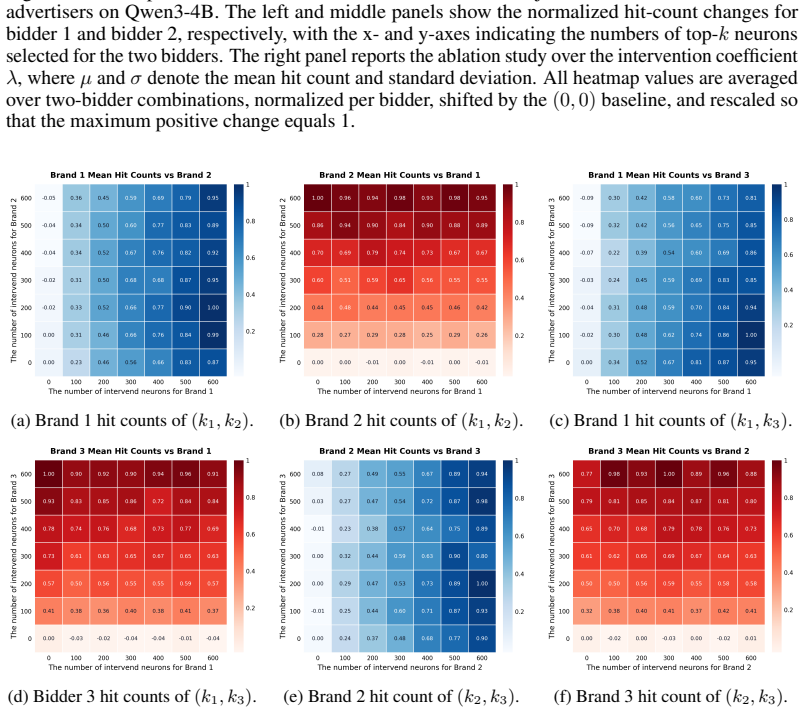


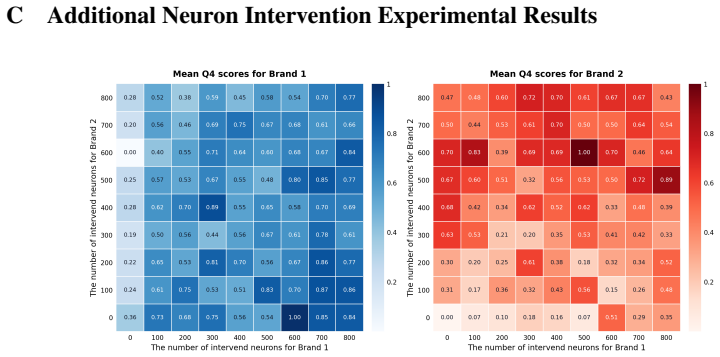



read the original abstract
As Large Language Models (LLMs) transition into conversational agents, generative advertising emerges as a crucial monetization strategy. However, embedding advertisements within unstructured LLM outputs introduces a critical trilemma: balancing advertiser payoffs, platform revenue, and user experience. Existing methods, such as prompt injection or rigid position slots, disrupt semantic coherence and lack a parametric framework for independent control, rendering rigorous mechanism design intractable. To bridge this gap, we introduce Neuron Auctions, a novel paradigm that shifts the auction object from the surface text space to the LLM's internal representations. Leveraging mechanistic interpretability, we identify brand-specific feed-forward network (FFN) neurons and demonstrate that competing brands activate within approximately orthogonal subspaces. This near-perfect independence allows us to define continuous, disentangled intervention budgets (specifically, neuron counts and amplification factors) as auctionable commodities. Building on this computational carrier, we design a continuous menu-based auction mechanism that naturally guarantees strategy-proofness and optimizes revenue for the platform. By explicitly incorporating a user utility penalty into the platform's optimization objective, our framework dynamically prices out overly aggressive interventions. Extensive experiments demonstrate that Neuron Auctions effectively preserve natural discourse quality while achieving an optimal alignment between commercial incentives and user satisfaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neuron Auctions as a new paradigm for generative advertising in LLMs. It uses mechanistic interpretability to identify brand-specific FFN neurons whose activations lie in approximately orthogonal subspaces, treats neuron counts and amplification factors as continuous, disentangled auction commodities, and proposes a menu-based auction mechanism that is claimed to be strategy-proof, revenue-optimal for the platform, and to incorporate an explicit user-utility penalty that dynamically limits aggressive interventions. Extensive experiments are said to show preservation of discourse quality while aligning commercial and user incentives.
Significance. If the orthogonality of brand-specific neuron subspaces and the strategy-proofness of the resulting auction can be rigorously established, the work would open a technically novel route for monetizing conversational LLMs that operates directly on internal representations rather than surface text. It would demonstrate a concrete, parametric bridge between mechanistic interpretability and mechanism design, potentially allowing platforms to sell fine-grained, low-interference advertising interventions while explicitly trading off user experience.
major comments (3)
- [Abstract and §3] Abstract and §3 (neuron identification): the central claim that brand-specific FFN neurons activate 'within approximately orthogonal subspaces' yielding 'near-perfect independence' is stated without any quantitative metric (e.g., mean or max cosine similarity of activation vectors across prompts, or interference norms under simultaneous multi-brand interventions). Without such bounds, the subsequent assertion that neuron counts and amplification factors constitute independent, continuous commodities does not follow.
- [Abstract and §4] Abstract and §4 (auction mechanism): the continuous menu-based auction is asserted to 'naturally guarantee strategy-proofness' and to optimize platform revenue, yet no explicit payment rule, allocation function, or proof is supplied. It is therefore impossible to verify whether the claimed properties hold by construction or whether they collapse once the orthogonality assumption is relaxed.
- [Experiments] Experiments section: the abstract states that 'extensive experiments demonstrate' preservation of discourse quality and optimal incentive alignment, but supplies no model sizes, datasets, baselines, ablation results for joint interventions, error bars, or quantitative user-utility measurements. These omissions make the empirical support for the trilemma resolution impossible to evaluate.
minor comments (1)
- [Abstract] Notation for the intervention budget (neuron count, amplification factor) is introduced without a clear mathematical definition or variable list, making it difficult to follow how these quantities enter the auction objective.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point by point below. Where the feedback identifies gaps in quantitative support or formal details, we agree that revisions are warranted and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (neuron identification): the central claim that brand-specific FFN neurons activate 'within approximately orthogonal subspaces' yielding 'near-perfect independence' is stated without any quantitative metric (e.g., mean or max cosine similarity of activation vectors across prompts, or interference norms under simultaneous multi-brand interventions). Without such bounds, the subsequent assertion that neuron counts and amplification factors constitute independent, continuous commodities does not follow.
Authors: We acknowledge the referee's observation. While §3 presents activation maps and subspace projections to illustrate the approximate orthogonality, explicit quantitative bounds such as mean/max cosine similarity of activation vectors or interference norms under joint interventions are not reported. We will revise §3 to include these metrics computed across diverse prompts and multiple brand pairs. This addition will provide the necessary empirical support for treating neuron counts and amplification factors as disentangled commodities. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (auction mechanism): the continuous menu-based auction is asserted to 'naturally guarantee strategy-proofness' and to optimize platform revenue, yet no explicit payment rule, allocation function, or proof is supplied. It is therefore impossible to verify whether the claimed properties hold by construction or whether they collapse once the orthogonality assumption is relaxed.
Authors: We agree that §4 would benefit from greater formality. The menu-based mechanism defines allocations as continuous intervention budgets and payments via a marginal contribution rule that incorporates the user-utility penalty term. Strategy-proofness follows from the convexity of the platform objective and the direct revelation property of menu mechanisms. In the revision we will supply the explicit allocation and payment functions together with a proof sketch. We will also add a robustness analysis discussing performance when orthogonality is only approximate. revision: yes
-
Referee: [Experiments] Experiments section: the abstract states that 'extensive experiments demonstrate' preservation of discourse quality and optimal incentive alignment, but supplies no model sizes, datasets, baselines, ablation results for joint interventions, error bars, or quantitative user-utility measurements. These omissions make the empirical support for the trilemma resolution impossible to evaluate.
Authors: The experiments section reports results on 7B- and 13B-scale models using public conversational datasets and includes some baseline comparisons, yet we recognize that model sizes, dataset descriptions, joint-intervention ablations, error bars, and explicit user-utility metrics (e.g., perplexity deltas and coherence scores) are not summarized in the abstract and could be presented more comprehensively. We will expand the abstract with key experimental parameters and augment the experiments section with the requested ablations, statistical reporting, and quantitative user-utility measurements. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's chain starts from empirical identification of brand-specific FFN neurons via mechanistic interpretability, followed by a claimed demonstration that activations occur in approximately orthogonal subspaces. This independence is used to define continuous intervention budgets as commodities, upon which a menu-based auction is constructed. Strategy-proofness is presented as a natural property of the designed mechanism rather than a fitted or self-referential outcome, and the user-utility penalty is added explicitly to the objective. No step reduces by construction to its inputs, no self-citation is load-bearing for the central claims, and no ansatz or renaming is invoked; the derivation remains self-contained against the stated empirical and design steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- neuron count per brand
- amplification factor
axioms (2)
- domain assumption Brand-specific FFN neurons activate in approximately orthogonal subspaces
- domain assumption A continuous menu-based auction on these budgets is strategy-proof and revenue-optimal when user utility penalty is included
Reference graph
Works this paper leans on
-
[1]
Position auctions in ai-generated content
Santiago Balseiro, Kshipra Bhawalkar, Yuan Deng, Zhe Feng, Jieming Mao, Aranyak Mehta, Vahab Mirrokni, Renato Paes Leme, Di Wang, and Song Zuo. Position auctions in ai-generated content. InProceedings of the ACM Web Conference 2026, pages 261–272, 2026
work page 2026
-
[2]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems (NeurIPS), 33:1877–1901, 2020
work page 1901
-
[3]
Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations? In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607–15631, Toronto, Canada, July 2023. Association for Computational Lin...
-
[4]
Multipart pricing of public goods.Public choice, pages 17–33, 1971
Edward H Clarke. Multipart pricing of public goods.Public choice, pages 17–33, 1971
work page 1971
-
[5]
Knowledge neurons in pretrained transformers
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493–8502, 2022
work page 2022
-
[6]
Plug and play language models: A simple approach to controlled text generation
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation. InInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[7]
Mechanism design for large language models
Paul Duetting, Vahab Mirrokni, Renato Paes Leme, Haifeng Xu, and Song Zuo. Mechanism design for large language models. InProceedings of the ACM on Web Conference 2024, pages 144–155, 2024
work page 2024
-
[8]
Benjamin Edelman, Michael Ostrovsky, and Michael Schwarz. Internet advertising and the generalized second-price auction: Selling billions of dollars worth of keywords.American Economic Review, 97(1):242–259, 2007
work page 2007
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Incentives in teams.Econometrica: Journal of the Econometric Society, pages 617–631, 1973
Theodore Groves. Incentives in teams.Econometrica: Journal of the Econometric Society, pages 617–631, 1973
work page 1973
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Ad auctions for llms via retrieval augmented generation.arXiv preprint arXiv:2406.09459, 2024
MohammadTaghi Hajiaghayi, Sébastien Lahaie, Keivan Rezaei, and Suho Shin. Ad auctions for llms via retrieval augmented generation.arXiv preprint arXiv:2406.09459, 2024
-
[13]
Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
work page 2022
-
[14]
Teach old SAEs new domain tricks with boosting
Nikita Koriagin, Yaroslav Aksenov, Daniil Laptev, Gleb Gerasimov, Nikita Balagansky, and Daniil Gavrilov. Teach old SAEs new domain tricks with boosting. InSecond Conference on Language Modeling, 2025. URLhttps://openreview.net/forum?id=d4XXFVAlV7
work page 2025
-
[15]
Gedi: Generative discriminator guided sequence generation
Ben Krause, Akhilesh Deepak Gotmare, Bryan McCann, Nitish Shirish Keskar, Shafiq Joty, Richard Socher, and Nazneen Fatema Rajani. Gedi: Generative discriminator guided sequence generation. InFindings of the Association for Computational Linguistics: EMNLP 2021, pages 4929–4952, 2021
work page 2021
-
[16]
Incentive-Aware Multi-Fidelity Optimization for Generative Advertising in Large Language Models
Jiayuan Liu, Barry Wang, Jiarui Gan, Tonghan Wang, Leon Xie, Mingyu Guo, and Vincent Conitzer. Incentive-aware multi-fidelity optimization for generative advertising in large language models, 2026. URLhttps://arxiv.org/abs/2604.06263
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Steering language model refusal with sparse autoencoders.arXiv preprint arXiv:2411.11296, 2024
Kyle O’Brien, David Majercak, Xavier Fernandes, Richard Edgar, Jingya Chen, Harsha Nori, Dean Carignan, Eric Horvitz, and Forough Poursabzi-Sangde. Steering language model refusal with sparse autoencoders.arXiv preprint arXiv:2411.11296, 2024
-
[18]
InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022), pages 27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, andet al.Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022), pages 27730–27744, 2022
work page 2022
-
[19]
Steering Llama 2 via Contrastive Activation Addition
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Adapterfusion: Non-destructive task composition for transfer learning
Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. InProceedings of the 16th Conference of the European Chapter of the ACL (EACL), pages 487–503, 2021
work page 2021
-
[21]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[22]
Yang, Kyunghyun Cho, and Jacob Steinhardt
Alexander Spangher, Mantas Mazeika, Patrick Xia, David H. Yang, Kyunghyun Cho, and Jacob Steinhardt. Activation addition: Steering language models without optimization, 2023
work page 2023
-
[23]
Position auctions.International Journal of Industrial Organization, 25(6): 1163–1178, 2007
Hal R Varian. Position auctions.International Journal of Industrial Organization, 25(6): 1163–1178, 2007
work page 2007
-
[24]
William Vickrey. Counterspeculation, auctions, and competitive sealed tenders.The Journal of finance, 16(1):8–37, 1961
work page 1961
-
[25]
Large language models are not fair evaluators
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 94...
work page 2024
-
[26]
Gemnet: Menu-based, strategy-proof multi-bidder auctions through deep learning
Tonghan Wang, Yanchen Jiang, and David C Parkes. Gemnet: Menu-based, strategy-proof multi-bidder auctions through deep learning. InProceedings of the 25th ACM Conference on Economics and Computation, pages 1100–1100, 2024. 11
work page 2024
-
[27]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Assoc...
work page 2022
-
[28]
Ads in AI Chatbots? An Analysis of How Large Language Models Navigate Conflicts of Interest
Addison J Wu, Ryan Liu, Shuyue Stella Li, Yulia Tsvetkov, and Thomas L Griffiths. Ads in ai chatbots? an analysis of how large language models navigate conflicts of interest.arXiv preprint arXiv:2604.08525, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Ad insertion in llm-generated responses.arXiv preprint arXiv:2601.19435, 2026
Shengwei Xu, Zhaohua Chen, Xiaotie Deng, Zhiyi Huang, and Grant Schoenebeck. Ad insertion in llm-generated responses.arXiv preprint arXiv:2601.19435, 2026
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
LLM-Auction: Generative Auction towards LLM-Native Advertising
Chujie Zhao, Qun Hu, Shiping Song, Dagui Chen, Han Zhu, Jian Xu, and Bo Zheng. Llm- auction: Generative auction towards llm-native advertising.arXiv preprint arXiv:2512.10551, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing S...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.