Recognition: no theorem link
Maintaining Queries under Updates Using Heavy-Light Partitioning of the Input Relations
Pith reviewed 2026-05-12 01:22 UTC · model grok-4.3
The pith
Heavy-light partitioning of relations yields a uniform maintenance scheme for arbitrary join queries under single-tuple updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining delta queries, trees of materialized views, and heavy-light data partitioning of the input relations, the output of an arbitrary join query can be maintained under single-tuple updates so that it remains enumerable with constant delay; the per-update time is characterized by the maintenance width of the query, a new measure parameterized by the heavy-light threshold, and the threshold can be chosen to minimize that width.
What carries the argument
Heavy-light data partitioning of input relations together with delta queries and materialized-view trees; the maintenance width is the resulting bound on update time, obtained by classifying tuples as heavy or light relative to a tunable threshold.
If this is right
- Any join query admits a maintenance plan whose update time is at most its maintenance width.
- The optimal heavy-light threshold for a query can be found algorithmically.
- The resulting update times match or improve the best previously reported figures for the queries those figures covered.
- Constant-delay enumeration of the query output is preserved after every update.
Where Pith is reading between the lines
- The same partitioning idea could be tested on maintenance problems for queries that contain aggregates or negation.
- In a database system the maintenance width might serve as a static cost model for choosing among candidate indexes or materialized views.
- Dynamic repartitioning at runtime could further reduce the worst-case width when data distributions change.
Load-bearing premise
That the three techniques together produce update costs bounded by the maintenance width for every join query and every update sequence, without extra overheads from repartitioning or view maintenance.
What would settle it
An explicit join query, a concrete heavy-light threshold, and a sequence of single-tuple updates whose measured total processing time exceeds the maintenance width computed for that threshold.
Figures









read the original abstract
We study the classical incremental view maintenance problem: Given a query and a database, maintain the query output under single-tuple updates (inserts or deletes) to the database such that the tuples in the query output can be enumerated with constant delay after any update. We introduce a maintenance approach whose update time matches or improves the best update time reported in prior work. Whereas prior approaches are manually tailored to each of a handful of queries, our approach generalizes to arbitrary join queries. It combines three techniques: delta queries, trees of materialized views, and heavy-light data partitioning. The overall update time incurred by our approach for a given join query is characterized by the maintenance width, a new measure that is parameterized by the heavy-light threshold for data partitioning. We show how to find the threshold that minimizes the maintenance width.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies incremental view maintenance for join queries under single-tuple updates, with the goal of supporting constant-delay enumeration of the query output after each update. It proposes a general approach that combines delta queries, trees of materialized views, and heavy-light partitioning of input relations. The update time is characterized by a new measure called the maintenance width, which is parameterized by the heavy-light threshold; the paper shows how to select the threshold minimizing this width and claims that the resulting update time matches or improves upon the best prior results while applying to arbitrary join queries rather than hand-crafted solutions for a few queries.
Significance. If the maintenance width correctly upper-bounds the total update cost (including partition maintenance and view-tree updates) for arbitrary joins, the work would supply a systematic, optimizable framework that generalizes beyond the handful of queries addressed by prior specialized techniques. The introduction of a computable width measure and an explicit minimization procedure over the threshold are positive contributions that could enable broader applicability in dynamic query processing.
major comments (2)
- [Definition of maintenance width and update-time analysis] The central claim that the minimized maintenance width bounds the end-to-end update time requires an explicit accounting of the cost of maintaining the heavy-light partitions themselves after each single-tuple update. It is unclear whether re-partitioning or data-structure adjustments for heavy and light tuples are absorbed into the width or introduce additional factors (e.g., scans or logarithmic overheads) not captured by the definition.
- [View-tree construction and delta propagation] For arbitrary join queries, the view-tree construction and delta-query propagation must ensure that materialized sub-results remain size-bounded by the width even when the optimal threshold leaves many light tuples or when the join hypergraph has high treewidth. The manuscript should provide a concrete argument or lemma showing that no query-specific blow-up occurs in these cases.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from a brief comparison table listing the maintenance width (or equivalent) for a few standard queries (e.g., triangle, 4-cycle) against the best prior bounds, to make the improvement claim immediately verifiable.
- [Preliminaries] Notation for the heavy-light threshold and the resulting partition sizes should be introduced earlier and used consistently when defining the maintenance width.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions made to strengthen the manuscript.
read point-by-point responses
-
Referee: The central claim that the minimized maintenance width bounds the end-to-end update time requires an explicit accounting of the cost of maintaining the heavy-light partitions themselves after each single-tuple update. It is unclear whether re-partitioning or data-structure adjustments for heavy and light tuples are absorbed into the width or introduce additional factors (e.g., scans or logarithmic overheads) not captured by the definition.
Authors: We agree that explicit accounting improves clarity. The maintenance width is defined (Definition 3.2) to include partition maintenance: each update triggers a constant-time degree check against the threshold using the existing index structures, with reclassification of a tuple (if needed) charged to the width via an amortized argument over a sequence of updates. No full scans or extra logarithmic factors arise beyond the data-structure costs already present in the view maintenance. To address the concern directly we have added a dedicated paragraph and a supporting claim in Section 4.2 that isolates the partition cost and shows it is subsumed by the width; the revision is therefore partial and consists of clarification rather than alteration of the core bound. revision: partial
-
Referee: For arbitrary join queries, the view-tree construction and delta-query propagation must ensure that materialized sub-results remain size-bounded by the width even when the optimal threshold leaves many light tuples or when the join hypergraph has high treewidth. The manuscript should provide a concrete argument or lemma showing that no query-specific blow-up occurs in these cases.
Authors: The maintenance width is constructed precisely to guarantee the bound for any join query. When many tuples remain light, each delta query is limited to combinations involving at most one light tuple from each relation in the relevant subtree; the resulting size is therefore at most the width by construction of the threshold minimization. For high-treewidth hypergraphs the view tree is obtained from a width-minimizing tree decomposition, and delta propagation traverses only the edges of this decomposition, preventing blow-up. We have added Lemma 5.1 that formally states and proves the size invariant for every materialized view under single-tuple updates, covering both the light-tuple and high-treewidth regimes. The revision therefore consists of inserting this lemma and its proof. revision: yes
Circularity Check
No circularity: maintenance width is a new independent measure with algorithmic optimization
full rationale
The paper defines maintenance width as a novel parameterized measure for update cost under the combined delta-query, view-tree, and heavy-light partitioning scheme, then gives an algorithm to select the minimizing threshold. This is a definitional and computational step rather than any reduction of a claimed prediction back to fitted inputs or self-citations by construction. The bounding argument for arbitrary joins is presented as following from the three techniques once the threshold is chosen; no equation equates the final bound to the definition itself, and no load-bearing self-citation or ansatz is invoked to force the result. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- heavy-light threshold
axioms (2)
- domain assumption Single-tuple updates to the database
- domain assumption Constant delay enumeration is achievable
invented entities (1)
-
maintenance width
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Insert-only versus insert-delete in dynamic query evaluation.Proc
Mahmoud Abo Khamis, Ahmet Kara, Dan Olteanu, and Dan Suciu. Insert-only versus insert-delete in dynamic query evaluation.Proc. ACM Manag. Data, 2(5), November 2024.doi:10.1145/3695837
-
[2]
Mahmoud Abo Khamis, Hung Q. Ngo, and Dan Suciu. Panda: Query evaluation in submodu- lar width.TheoretiCS, Volume 4, Apr 2025. URL:https://theoretics.episciences.org/13722, doi:10.46298/theoretics.25.12
-
[3]
Sepehr Assadi and Vihan Shah. An improved fully dynamic algorithm for counting 4-cycles in general graphs using fast matrix multiplication.Proc. ACM Manag. Data, 3(2):91:1–91:24, 2025.doi:10.1145/ 3725228. 18
work page 2025
-
[4]
Size bounds and query plans for relational joins
Albert Atserias, Martin Grohe, and D´ aniel Marx. Size bounds and query plans for relational joins. In FOCS, pages 739–748, 2008.doi:10.1109/FOCS.2008.43
-
[5]
Answering Conjunctive Queries Under Updates
Christoph Berkholz, Jens Keppeler, and Nicole Schweikardt. Answering Conjunctive Queries Under Updates. InPODS, pages 303–318, 2017.doi:10.1145/3034786.3034789
-
[6]
Mihai Budiu, Leonid Ryzhyk, Gerd Zellweger, Ben Pfaff, Lalith Suresh, Simon Kassing, Abhinav Gyawali, Matei Budiu, Tej Chajed, Frank McSherry, and Val Tannen. DBSP: automatic incremental view maintenance for rich query languages.VLDB J., 34(4), 2025.doi:10.1007/S00778-025-00922-Y
-
[7]
Rada Chirkova and Jun Yang. Materialized views.Found. Trends Databases, 4(4):295–405, 2012. doi:10.1561/1900000020
-
[8]
First-order queries on structures of bounded degree are com- putable with constant delay.ACM Trans
Arnaud Durand and Etienne Grandjean. First-order queries on structures of bounded degree are com- putable with constant delay.ACM Trans. Comput. Logic, 8(4), August 2007.doi:10.1145/1276920. 1276923
-
[9]
On lattices, learning with errors, random linear codes, and cryptography,
Georg Gottlob, Zolt´ an Mikl´ os, and Thomas Schwentick. Generalized hypertree decompositions: Np- hardness and tractable variants.J. ACM, 56(6):30:1–30:32, 2009.doi:10.1145/1568318.1568320
-
[10]
Fully dynamic four-vertex subgraph counting
Kathrin Hanauer, Monika Henzinger, and Qi Cheng Hua. Fully dynamic four-vertex subgraph counting. InSAND, pages 18:1–18:17, 2022.doi:10.4230/LIPICS.SAND.2022.18
-
[11]
Monika Henzinger, Sebastian Krinninger, Danupon Nanongkai, and Thatchaphol Saranurak. Unifying and strengthening hardness for dynamic problems via the online matrix-vector multiplication conjecture. InSTOC, pages 21–30, 2015.doi:10.1145/2746539.2746609
-
[12]
In: Salihoglu, S., Zhou, W., Chirkova, R., Yang, J., Suciu, D
Muhammad Idris, Mart´ ın Ugarte, and Stijn Vansummeren. The dynamic yannakakis algorithm: Compact and efficient query processing under updates. InSIGMOD, pages 1259–1274, 2017.doi: 10.1145/3035918.3064027
-
[13]
URL: https://drops.dagstuhl.de/entities/document/10.4230/LIPIcs
Ahmet Kara, Zheng Luo, Milos Nikolic, Dan Olteanu, and Haozhe Zhang. Tractable Conjunctive Queries over Static and Dynamic Relations. InICDT, pages 12:1–12:21, 2025.doi:10.4230/LIPIcs. ICDT.2025.12
-
[14]
Ngo, Milos Nikolic, Dan Olteanu, and Haozhe Zhang
Ahmet Kara, Hung Q. Ngo, Milos Nikolic, Dan Olteanu, and Haozhe Zhang. Counting triangles under updates in worst-case optimal time. InICDT, pages 4:1–4:18, 2019.doi:10.4230/LIPICS.ICDT.2019. 4
-
[15]
Ngo, Milos Nikolic, Dan Olteanu, and Haozhe Zhang
Ahmet Kara, Hung Q. Ngo, Milos Nikolic, Dan Olteanu, and Haozhe Zhang. Maintaining triangle queries under updates.ACM Trans. Database Syst., 45(3):11:1–11:46, 2020.doi:10.1145/3396375
-
[16]
Trade-offs in static and dynamic evalu- ation of hierarchical queries
Ahmet Kara, Milos Nikolic, Dan Olteanu, and Haozhe Zhang. Trade-offs in static and dynamic evalu- ation of hierarchical queries. InPODS, pages 375–392, 2020.doi:10.1145/3375395.3387646
-
[17]
Ahmet Kara, Milos Nikolic, Dan Olteanu, and Haozhe Zhang. F-IVM: analytics over relational databases under updates.VLDB J., 33(4):903–929, 2024.doi:10.1007/S00778-023-00817-W
-
[18]
Conjunctive queries with free access patterns under updates.LMCS, Volume 21, Issue 2, Jun 2025
Ahmet Kara, Milos Nikolic, Dan Olteanu, and Haozhe Zhang. Conjunctive queries with free access patterns under updates.LMCS, Volume 21, Issue 2, Jun 2025. URL:https://lmcs.episciences. org/13059,doi:10.46298/lmcs-21(2:23)2025
-
[19]
Join size bounds using l p-norms on degree sequences.Proc
Mahmoud Abo Khamis, Vasileios Nakos, Dan Olteanu, and Dan Suciu. Join size bounds using l p-norms on degree sequences.Proc. ACM Manag. Data, 2(2):96, 2024.doi:10.1145/3651597
-
[20]
Mahmoud Abo Khamis, Vasileios Nakos, Dan Olteanu, and Dan Suciu. Information theory strikes back: New development in the theory of cardinality estimation.SIGMOD Rec., 54(1):7–15, 2025. doi:10.1145/3733620.3733623. 19
-
[21]
Mahmoud Abo Khamis, Hung Q. Ngo, and Atri Rudra. FAQ: questions asked frequently. InPODS, pages 13–28, 2016.doi:10.1145/2902251.2902280
-
[22]
Mahmoud Abo Khamis, Hung Q. Ngo, and Dan Suciu. Computing join queries with functional depen- dencies. InPODS, pages 327–342, 2016.doi:10.1145/2902251.2902289
-
[23]
Christoph Koch, Yanif Ahmad, Oliver Kennedy, Milos Nikolic, Andres N¨ otzli, Daniel Lupei, and Amir Shaikhha. DBToaster: Higher-order Delta Processing for Dynamic, Frequently Fresh Views.VLDB J., 23(2):253–278, 2014.doi:10.14778/2336664.2336670
-
[24]
Lynn Harold Loomis and Hassler Whitney. An inequality related to the isoperimetric inequality.Bulletin of the American Mathematical Society, 55:961–962, 1949. URL:https://api.semanticscholar.org/ CorpusID:123450423
work page 1949
-
[25]
Approximating fractional hypertree width.ACM Trans
D´ aniel Marx. Approximating fractional hypertree width.ACM Trans. Algorithms, 6(2):29:1–29:17, 2010.doi:10.1145/1721837.1721845
-
[26]
Incremental, iterative data processing with timely dataflow.Commun
Derek Gordon Murray, Frank McSherry, Michael Isard, Rebecca Isaacs, Paul Barham, and Mart´ ın Abadi. Incremental, iterative data processing with timely dataflow.Commun. ACM, 59(10):75–83, 2016.doi:10.1145/2983551
-
[27]
Hung Q. Ngo. Worst-case optimal join algorithms: Techniques, results, and open problems. InPODS, page 111–124, 2018.doi:10.1145/3196959.3196990
-
[28]
Recent increments in incremental view maintenance
Dan Olteanu. Recent increments in incremental view maintenance. InPODS, pages 8–17, 2024.doi: 10.1145/3635138.3654763
-
[29]
John Wiley & Sons, Inc., USA, 1986
Alexander Schrijver.Theory of linear and integer programming. John Wiley & Sons, Inc., USA, 1986
work page 1986
-
[30]
Daniel Sotolongo, Daniel Mills, Tyler Akidau, Anirudh Santhiar, Attila-P´ eter T´ oth, Botong Huang, Boyuan Zhang, Igor Belianski, Ling Geng, Matt Uhlar, Nikhil Shah, Olivia Zhou, Saras Nowak, Sasha Lionheart, Vlad Lifliand, Wendy Grus, Yiwen Zhu, Ankur Sharma, Dzmitry Pauliukevich, Enrico Sar- torello, Ilaria Battiston, Ivan Kalev, Lawrence Benson, Leon ...
-
[31]
Christopher, and Christoph Koch.Probabilistic Databases
Dan Suciu, Dan Olteanu, R. Christopher, and Christoph Koch.Probabilistic Databases. Morgan & Claypool Publishers, 1st edition, 2011
work page 2011
-
[32]
Change propagation without joins.Proc
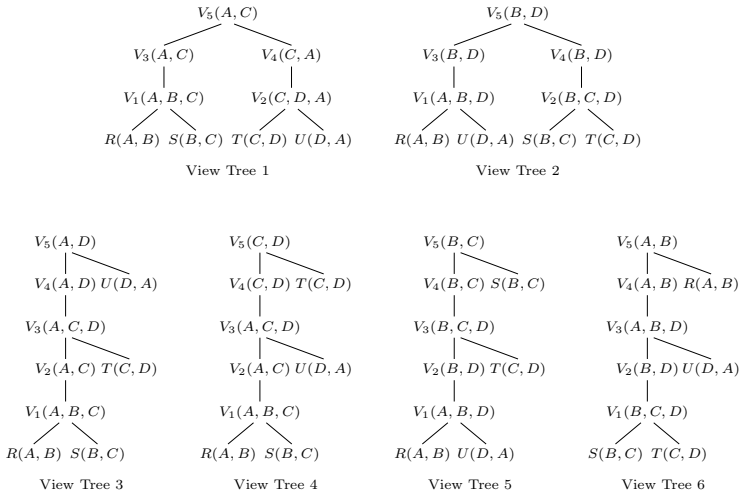
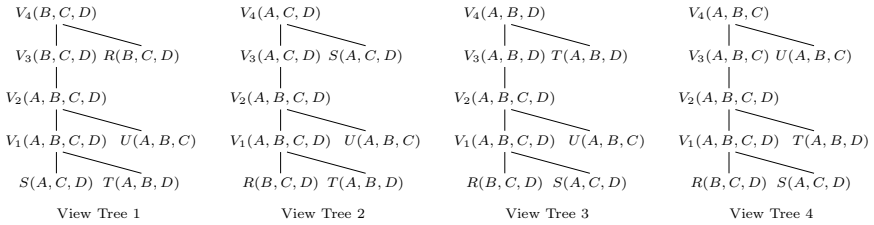
Qichen Wang, Xiao Hu, Binyang Dai, and Ke Yi. Change propagation without joins.Proc. VLDB Endow., 16(5):1046–1058, 2023.doi:10.14778/3579075.3579080. A Additional Examples In this section, we provide additional (and extended) examples of our maintenance approach and show how it can recover all results of existing IVM approaches (where the update time is a...
-
[33]
aboveV 1(X 1), it holdsX /∈X ′ 1, and (iv) for any viewV ′ 2(X ′
-
[34]
aboveV 2(X 2), it holdsX /∈X ′
-
[35]
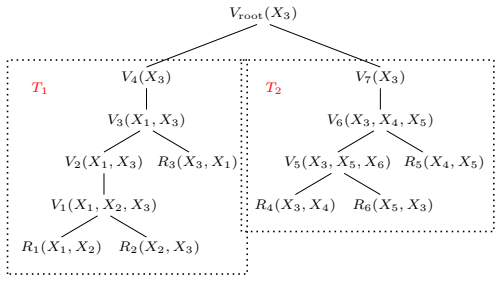
The definition of view trees requires that V2 must be in the subtree rooted atV 1 (Definition 1)
This implies that the parent view ˆV1( ˆX1) ofV 1(X 1) is a projection view that projects awayX, which meansX /∈ ˆX 1. The definition of view trees requires that V2 must be in the subtree rooted atV 1 (Definition 1). This means thatV 1 andV 2 cannot be independent, which is a contradiction. Equipped with Proposition 28, we are ready to prove Proposition 2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.