Recognition: no theorem link
Beyond Bag-of-Patches: Learning Global Layout via Textual Supervision for Late-Interaction Visual Document Retrieval
Pith reviewed 2026-05-12 01:10 UTC · model grok-4.3
The pith
Augmenting local patch embeddings with a global layout embedding learned from textual descriptions improves late-interaction visual document retrieval without changing inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
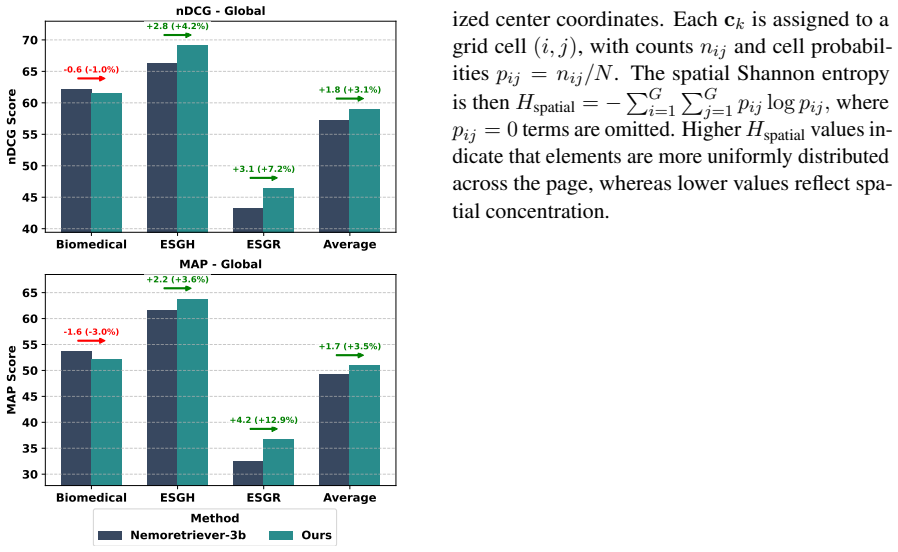
We make document layout learnable without changing inference. We propose a multimodal encoder that augments local patch representations with a global layout embedding, trained via textual descriptions encoding document layout information. Across four ViDoRe-v2 datasets, our model improves over the strongest architecturally comparable ColPali/ColQwen baseline by +2.4 nDCG@5 and +2.3 MAP@5, with statistically significant per-dataset gains over ColQwen.
What carries the argument
The global layout embedding produced by a multimodal encoder from textual layout descriptions and added to the set of local patch embeddings for late-interaction matching.
If this is right
- Relevance estimation improves because global layout information complements local patch similarity.
- Gains hold across multiple datasets containing heterogeneous document layouts.
- No architectural changes are needed at inference time, so efficiency stays the same.
- Statistically significant per-dataset improvements appear over comparable late-interaction baselines.
Where Pith is reading between the lines
- The same textual-supervision trick could be tested on retrieval tasks outside documents, such as diagrams or infographics.
- Automatically generated layout descriptions might replace human-written ones and still deliver gains.
- The global embedding could be inspected to see which layout features most influence query relevance.
Load-bearing premise
Textual descriptions of layout can be used to train a global embedding that meaningfully augments local patch representations and improves relevance estimation without any change to the inference architecture.
What would settle it
Evaluating the model with and without the global layout embedding on the ViDoRe-v2 datasets and observing no statistically significant gains in nDCG@5 or MAP@5 would falsify the claim.
Figures




read the original abstract
Visual Document Retrieval (VDR) models mostly rely on late interaction architectures, in which documents are represented by a set of local patch embeddings and then matched against query tokens. While efficient, this architecture prioritizes local similarity over global layout structure of documents to estimate relevancy between documents and query. In practice, this leads to errors as relevance originates from layout structure of documents with heterogeneous layouts combining figures, tables, and text. We make document layout learnable without changing inference. We propose a multimodal encoder that augments local patch representations with a global layout embedding, trained via textual descriptions encoding document layout information. Across four ViDoRe-v2 datasets, our model improves over the strongest architecturally comparable ColPali/ColQwen baseline by +2.4 nDCG@5 and +2.3 MAP@5, with statistically significant per-dataset gains over ColQwen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multimodal encoder for late-interaction visual document retrieval that augments local patch embeddings with a global layout embedding learned from textual descriptions of document layout. The approach is presented as preserving the original inference architecture (token-to-patch MaxSim) while addressing limitations of bag-of-patches models on heterogeneous layouts. On four ViDoRe-v2 datasets the method reports gains of +2.4 nDCG@5 and +2.3 MAP@5 over the strongest ColPali/ColQwen baseline, with per-dataset statistical significance.
Significance. If the global layout embedding can be shown to integrate layout information without altering the inference-time scoring function, the work would usefully extend late-interaction VDR models. The use of textual supervision to supervise layout is a reasonable idea. However, the absence of any equations, diagrams, or pseudocode showing how the global vector is fused (or not) into the patch representations, combined with missing experimental details, makes it impossible to attribute the reported gains to the claimed mechanism rather than to training differences alone.
major comments (2)
- [Abstract] Abstract: the claim that the model 'augments local patch representations with a global layout embedding' while remaining 'architecturally comparable to ColPali/ColQwen' and 'without any change to the inference architecture' is load-bearing yet undefined. Standard late-interaction scoring uses MaxSim over local patch embeddings only; it is never stated whether the global vector is (a) concatenated or added to every patch embedding at encoding time (training-only change) or (b) incorporated into the relevance score at inference. The former would make the baselines non-comparable; the latter would violate the 'no change' assertion. This ambiguity prevents verification of the +2.4 nDCG@5 headline.
- [Abstract] The manuscript asserts statistically significant per-dataset gains but provides no description of the significance test, number of queries per dataset, variance across runs, or correction for multiple comparisons. Without these details the quantitative claim cannot be assessed.
minor comments (1)
- [Abstract] The four ViDoRe-v2 datasets are never enumerated in the abstract or early sections; this should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We clarify the architectural details of the global layout embedding and commit to adding the requested statistical information and diagrams in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the model 'augments local patch representations with a global layout embedding' while remaining 'architecturally comparable to ColPali/ColQwen' and 'without any change to the inference architecture' is load-bearing yet undefined. Standard late-interaction scoring uses MaxSim over local patch embeddings only; it is never stated whether the global vector is (a) concatenated or added to every patch embedding at encoding time (training-only change) or (b) incorporated into the relevance score at inference. The former would make the baselines non-comparable; the latter would violate the 'no change' assertion. This ambiguity prevents verification of the +2.4 nDCG@5 headline.
Authors: The global layout embedding is produced by the multimodal encoder (conditioned on both the document image and the textual layout descriptions) and fused into the local patch embeddings at encoding time via a learned projection and addition. The resulting augmented patch embeddings are the only document representations passed to inference. Scoring remains exactly the standard token-to-patch MaxSim used by ColPali/ColQwen; no global vector participates in the relevance score. Because the inference-time forward pass and scoring function are identical, the architecture is unchanged. The baselines are trained on the same document images but without textual layout supervision, so the comparison isolates the effect of our training objective. We will add an explicit diagram and equations in Section 3 showing the fusion step. revision: yes
-
Referee: [Abstract] The manuscript asserts statistically significant per-dataset gains but provides no description of the significance test, number of queries per dataset, variance across runs, or correction for multiple comparisons. Without these details the quantitative claim cannot be assessed.
Authors: We agree these details must be reported. Significance was evaluated with a paired t-test on per-query nDCG@5 and MAP@5 scores. Each ViDoRe-v2 dataset contains between 120 and 180 queries; we will list the exact counts. Results are averaged over three random seeds with standard deviation reported. Bonferroni correction was applied across the four datasets. We will insert a short paragraph (and an appendix table of p-values) in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical gains measured against external baselines
full rationale
The paper reports empirical improvements (+2.4 nDCG@5) on ViDoRe-v2 datasets by training a multimodal encoder to augment local patch embeddings with a global layout embedding derived from textual layout descriptions. No equations, derivations, or first-principles results are presented that reduce the gains to fitted inputs, self-definitions, or self-citation chains by construction. The central claim rests on direct comparisons to independent public baselines (ColPali/ColQwen), which are external and not derived from the present work. Any architectural description (e.g., 'without any change to the inference architecture') is a modeling choice whose validity can be checked against the stated method and results; it does not create a tautological reduction. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Textual layout descriptions provide sufficient supervision to learn a global embedding that improves relevance estimation when added to local patch representations.
invented entities (1)
-
Global layout embedding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
FirstName Alpher , title =
-
[3]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[4]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[5]
FirstName Alpher and FirstName Gamow , title =
-
[6]
LiT: Zero-Shot Transfer with Locked-image text Tuning , author=. 2022 , eprint=
work page 2022
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
work page 2021
-
[8]
Vidore benchmark V2: raising the bar for visual retrieval.CoRR, abs/2505.17166,
ViDoRe Benchmark V2: Raising the Bar for Visual Retrieval , author=. arXiv preprint arXiv:2505.17166 , year=
-
[9]
The Thirteenth International Conference on Learning Representations , year=
ColPali: Efficient Document Retrieval with Vision Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[10]
Colbert: Efficient and effective passage search via contextualized late interaction over bert , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
- [11]
-
[12]
Communications of the ACM , volume=
A vector space model for automatic indexing , author=. Communications of the ACM , volume=. 1975 , publisher=
work page 1975
-
[13]
Journal of documentation , volume=
A statistical interpretation of term specificity and its application in retrieval , author=. Journal of documentation , volume=. 1972 , publisher=
work page 1972
-
[14]
Robertson, Stephen and Walker, Steve and Jones, Susan and Hancock-Beaulieu, Micheline and Gatford, Mike , year =
-
[15]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[16]
arXiv preprint arXiv:2410.02729 , year=
Unified Multimodal Interleaved Document Representation for Retrieval , author=. arXiv preprint arXiv:2410.02729 , year=
-
[17]
jina-embeddings-v4: Universal embeddings for multimodal multilingual retrieval.CoRR, abs/2506.18902,
jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval , author=. arXiv preprint arXiv:2506.18902 , year=
-
[18]
Llama Nemoretriever Colembed: Top-Performing Text-Image Retrieval Model , author=. arXiv preprint arXiv:2507.05513 , year=
-
[19]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Bridging Modalities: Improving Universal Multimodal Retrieval by Multimodal Large Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[20]
Proceedings of the 30th ACM international conference on multimedia , pages=
Layoutlmv3: Pre-training for document ai with unified text and image masking , author=. Proceedings of the 30th ACM international conference on multimedia , pages=
-
[21]
Layoutlm: Pre-training of text and layout for document image understanding , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[22]
Shi Yu and Chaoyue Tang and Bokai Xu and Junbo Cui and Junhao Ran and Yukun Yan and Zhenghao Liu and Shuo Wang and Xu Han and Zhiyuan Liu and Maosong Sun , booktitle=. Vis. 2025 , url=
work page 2025
-
[23]
arXiv preprint arXiv:2504.08748 , year=
A survey of multimodal retrieval-augmented generation , author=. arXiv preprint arXiv:2504.08748 , year=
-
[24]
Zhichao Xu and Fengran Mo and Zhiqi Huang and Crystina Zhang and Puxuan Yu and Bei Wang and Jimmy Lin and Vivek Srikumar , title=. CoRR , volume=. 2025 , month=
work page 2025
-
[25]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
work page 2022
-
[26]
Nomic Embed Multimodal: Interleaved Text, Image, and Screenshots for Visual Document Retrieval , author=. 2025 , publisher=
work page 2025
-
[27]
jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval , author=. 2025 , eprint=
work page 2025
-
[28]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =. Advances in Neural Information Processing Systems , editor =
-
[29]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG , author=. 2025 , eprint=
work page 2025
-
[30]
arXiv preprint arXiv:2501.08828 , year=
Mmdocir: Benchmarking multi-modal retrieval for long documents , author=. arXiv preprint arXiv:2501.08828 , year=
-
[31]
arXiv preprint arXiv:2510.03663 , year=
UNIDOC-BENCH: A Unified Benchmark for Document-Centric Multimodal RAG , author=. arXiv preprint arXiv:2510.03663 , year=
-
[32]
The claude 3 model family: Opus, sonnet, haiku , author=. Claude-3 Model Card , volume=
-
[33]
Hidden in plain sight: VLMs overlook their visual representations , author=. 2025 , eprint=
work page 2025
-
[34]
DeepSeek-OCR: Contexts Optical Compression
DeepSeek-OCR: Contexts Optical Compression , author=. arXiv preprint arXiv:2510.18234 , year=
work page internal anchor Pith review arXiv
-
[35]
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model , author=. 2024 , eprint=
work page 2024
-
[36]
Granite Vision: a lightweight, open-source multimodal model for enterprise Intelligence , author=. arXiv preprint arXiv:2502.09927 , year=
-
[37]
arXiv preprint arXiv:2506.21182 , year=
Maintaining MTEB: Towards Long Term Usability and Reproducibility of Embedding Benchmarks , author=. arXiv preprint arXiv:2506.21182 , year=
-
[38]
Xu Zheng and Ziqiao Weng and Yuanhuiyi Lyu and Lutao Jiang and Haiwei Xue and Bin Ren and Danda Pani Paudel and Nicu Sebe and Luc Van Gool and Xuming Hu , title=. CoRR , volume=. 2025 , month=
work page 2025
-
[39]
ICML 2024 Workshop on Theoretical Foundations of Foundation Models , year=
Efficient Document Ranking with Learnable Late Interactions , author=. ICML 2024 Workshop on Theoretical Foundations of Foundation Models , year=
work page 2024
-
[40]
Ansel, Jason and Yang, Edward and He, Horace and Gimelshein, Natalia and Jain, Animesh and Voznesensky, Michael and Bao, Bin and Bell, Peter and Berard, David and Burovski, Evgeni and Chauhan, Geeta and Chourdia, Anjali and Constable, Will and Desmaison, Alban and DeVito, Zachary and Ellison, Elias and Feng, Will and Gong, Jiong and Gschwind, Michael and ...
-
[41]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
work page 2020
-
[42]
Training Deep Nets with Sublinear Memory Cost
Training deep nets with sublinear memory cost , author=. arXiv preprint arXiv:1604.06174 , year=
work page internal anchor Pith review arXiv
-
[43]
arXiv preprint arXiv:2508.21038 , year=
On the theoretical limitations of embedding-based retrieval , author=. arXiv preprint arXiv:2508.21038 , year=
-
[44]
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
GlobalDoc: A Cross-Modal Vision-Language Framework for Real-World Document Image Retrieval and Classification , author=. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. 2025 , organization=
work page 2025
-
[45]
Maniparambil, Mayug and Akshulakov, Raiymbek and Dahou Djilali, Yasser Abdelaziz and Seddik, Mohamed EI Amine and Narayan, Sanath and Mangalam, Karttikeya and O'Connor, Noel E. , booktitle=. Do Vision and Language Encoders Represent the World Similarly? , year=
-
[46]
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing , author=. 2025 , eprint=
work page 2025
-
[47]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
and McAuley, Julian and Li, Yunyao and Sinha, Ritwik
Wu, Junda and Xia, Yu and Yu, Tong and Chen, Xiang and Harsha, Sai Sree and Maharaj, Akash V and Zhang, Ruiyi and Bursztyn, Victor and Kim, Sungchul and Rossi, Ryan A. and McAuley, Julian and Li, Yunyao and Sinha, Ritwik. Doc-React: Multi-page Heterogeneous Document Question-answering. Proceedings of the 63rd Annual Meeting of the Association for Computat...
-
[49]
Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation
Abootorabi, Mohammad Mahdi and Zobeiri, Amirhosein and Dehghani, Mahdi and Mohammadkhani, Mohammadali and Mohammadi, Bardia and Ghahroodi, Omid and Baghshah, Mahdieh Soleymani and Asgari, Ehsaneddin. Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation. Findings of the Association for Computational Linguistics: ACL 2025...
-
[50]
Improving text embeddings with large language models
Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu. Improving Text Embeddings with Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.642
-
[51]
In: Inui, K., Jiang, J., Ng, V., Wan, X
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[52]
L ayout LM v2: Multi-modal Pre-training for Visually-rich Document Understanding
Xu, Yang and Xu, Yiheng and Lv, Tengchao and Cui, Lei and Wei, Furu and Wang, Guoxin and Lu, Yijuan and Florencio, Dinei and Zhang, Cha and Che, Wanxiang and Zhang, Min and Zhou, Lidong. L ayout LM v2: Multi-modal Pre-training for Visually-rich Document Understanding. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.