Recognition: 2 theorem links
· Lean TheoremA meshfree exterior calculus for generalizable and data-efficient learning of physics from point clouds
Pith reviewed 2026-05-12 02:04 UTC · model grok-4.3
The pith
MEEC equips arbitrary point clouds with exact discrete conservation via one Schur solve so learned physics transfers across geometries and parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MEEC equips an ε-ball graph with virtual node and edge measures via a single sparse Schur complement solve; the resulting complex satisfies discrete conservation exactly, is end-to-end differentiable in the point positions, and exposes a direct geometry-to-physics link without the mesh-generation step required by conventional structure-preserving discretizations. MEEC-Net learns unknown physics as a shared edge-wise flux law in an SO(d)-invariant local frame, so the same kernel produces compatible fluxes on any point cloud whose features lie in the training range. A solution-error bound splits into discretization and kernel-approximation terms which is independent of problem geometry.
What carries the argument
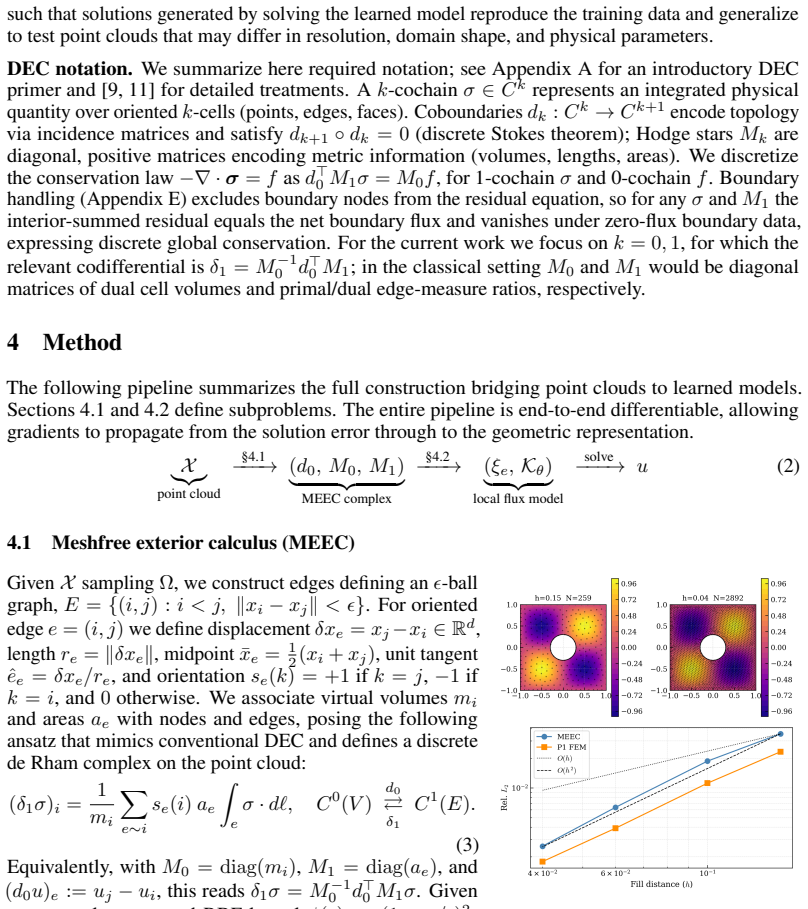
The ε-ball graph equipped with virtual node and edge measures obtained from a single sparse Schur complement solve, forming a discrete exterior complex that satisfies exact conservation.
If this is right
- The same learned kernel produces compatible fluxes on any point cloud whose features lie in the training range.
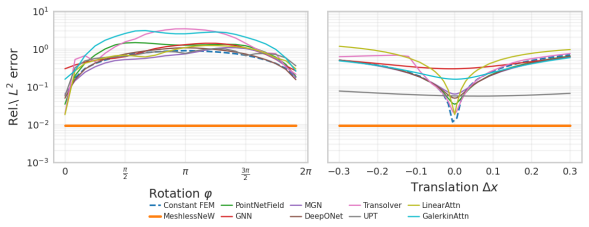
- Single-solution training transfers to unseen geometries, boundary conditions, and physical parameters.
- The solution-error bound splits into discretization and kernel-approximation terms independent of problem geometry.
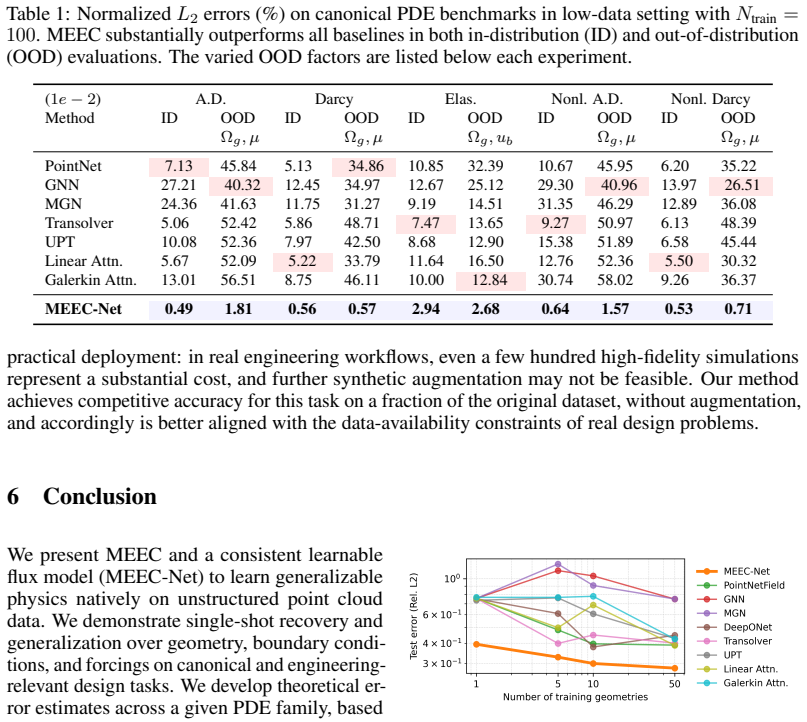
- On five canonical PDE benchmarks MEEC-Net achieves 1-2 orders of magnitude lower out-of-distribution error than baseline neural-operator approaches.
- On the SimJEB structural-bracket benchmark it achieves competitive error while using substantially fewer training geometries.
Where Pith is reading between the lines
- The approach could eliminate mesh generation entirely for simulations on irregular or deforming domains where conventional meshing fails.
- Embedding exact discrete conservation directly into the network architecture may improve long-term stability when the model is used inside larger time-stepping loops.
- The SO(d)-invariant local frame could allow the same trained model to handle data from both two- and three-dimensional sources without retraining.
Load-bearing premise
The ε-ball graph plus single Schur complement solve produces a complex that satisfies discrete conservation exactly and remains end-to-end differentiable for arbitrary point clouds whose features lie in the training range.
What would settle it
Apply the trained model to a point cloud whose local geometric features lie outside the training distribution and check whether discrete conservation is violated or the observed error exceeds the geometry-independent bound.
Figures










read the original abstract
We introduce a meshfree exterior calculus (MEEC) for learning structure-preserving descriptions of physics on point clouds, and use it to build MEEC-Net, a data-efficient surrogate that transfers across resolutions, geometries, and physical parameters. MEEC equips an $\varepsilon$-ball graph with virtual node and edge measures via a single sparse Schur complement solve; the resulting complex satisfies discrete conservation exactly, is end-to-end differentiable in the point positions, and exposes a direct geometry-to-physics link without the mesh-generation step required by conventional structure-preserving discretizations. MEEC-Net learns unknown physics as a shared edge-wise flux law in an SO($d$)-invariant local frame, so the same kernel produces compatible fluxes on any point cloud whose features lie in the training range. We prove a solution-error bound that splits into discretization and kernel-approximation terms which is independent of problem geometry, explaining the observed transfer from very few examples. We show that single-solution training transfers to unseen geometries, boundary conditions, and physical parameters. On five canonical PDE benchmarks MEEC-Net achieves 1-2 orders of magnitude lower out-of-distribution error than baseline neural-operator approaches. On the SimJEB structural-bracket benchmark it achieves competitive error while using substantially fewer training geometries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a meshfree exterior calculus (MEEC) that augments an ε-ball graph on point clouds with virtual node and edge measures obtained from a single sparse Schur complement solve. This construction yields a discrete complex that satisfies exact conservation (d²=0) and is end-to-end differentiable with respect to point positions. MEEC-Net then learns unknown physics as a shared, SO(d)-invariant edge-wise flux law, enabling transfer across resolutions, geometries, and parameters. The paper proves a solution-error bound that decomposes into geometry-independent discretization and kernel-approximation terms, and reports 1–2 orders of magnitude lower out-of-distribution error than neural-operator baselines on five PDE benchmarks while using substantially fewer training geometries; competitive results are also shown on the SimJEB structural-bracket benchmark.
Significance. If the claimed geometry-independent error bound and the robustness of the Schur-based complex hold under the stated conditions, the work would constitute a meaningful advance at the intersection of discrete exterior calculus and neural operators. The exact discrete conservation, differentiability in point positions, and direct geometry-to-physics link without meshing are notable technical strengths. The provision of a theoretical bound that explains observed transfer from very few examples adds explanatory power beyond empirical gains.
major comments (2)
- [Abstract] Abstract: the solution-error bound is asserted to split into discretization and kernel-approximation terms that are independent of problem geometry. This independence presupposes that the single Schur complement solve on an arbitrary ε-ball graph always produces a valid chain complex satisfying d²=0 exactly and remaining numerically stable. No regularity conditions on point-cloud density, minimum degree, or quasi-uniformity are referenced to preclude disconnected components or singular Schur complements, which would violate the exact-conservation premise and invalidate the geometry-independent claim.
- [Abstract] Abstract and theoretical development: the end-to-end differentiability and exact conservation are stated to hold for any point cloud whose local features lie in the training range. For globally non-uniform or sparse distributions the ε-ball graph can produce ill-conditioned incidence matrices or disconnected subgraphs; the manuscript should supply either a proof that the Schur construction remains well-defined or an explicit statement of the sampling assumptions under which the bound and differentiability are guaranteed.
minor comments (2)
- The abstract refers to “five canonical PDE benchmarks” without naming them; an explicit list (with references to the corresponding tables or figures) would improve reproducibility.
- Notation for the virtual measures obtained from the Schur complement and for the local SO(d)-invariant frame should be introduced with a single, self-contained equation block early in the methods section.
Simulated Author's Rebuttal
We thank the referee for the careful identification of implicit assumptions underlying the geometry-independent error bound and the claims of exact conservation and differentiability. We agree that these claims require explicit regularity conditions on the point cloud to guarantee a valid chain complex. We will revise the abstract, Section 3, and the proof of the error bound to state the necessary sampling assumptions. Responses to each major comment follow.
read point-by-point responses
-
Referee: The solution-error bound is asserted to split into discretization and kernel-approximation terms that are independent of problem geometry. This independence presupposes that the single Schur complement solve on an arbitrary ε-ball graph always produces a valid chain complex satisfying d²=0 exactly and remaining numerically stable. No regularity conditions on point-cloud density, minimum degree, or quasi-uniformity are referenced to preclude disconnected components or singular Schur complements.
Authors: We agree that the geometry-independence claim presupposes a valid complex. In the construction, d²=0 holds exactly by the algebraic properties of the Schur complement applied to the incidence matrix (the virtual measures are chosen to enforce the chain complex relation). Numerical stability and connectedness, however, do require regularity. We will add a new paragraph in Section 3 stating the assumptions: the ε-ball graph must be connected with minimum degree at least 1, and the point cloud must be quasi-uniform (local density bounded between positive constants c1 and c2 independent of the global geometry). Under these conditions the Schur complement is positive definite and the discretization-error term in the bound is independent of geometry. The proof will be annotated accordingly. This is a clarification rather than a change to the core result. revision: yes
-
Referee: The end-to-end differentiability and exact conservation are stated to hold for any point cloud whose local features lie in the training range. For globally non-uniform or sparse distributions the ε-ball graph can produce ill-conditioned incidence matrices or disconnected subgraphs; the manuscript should supply either a proof that the Schur construction remains well-defined or an explicit statement of the sampling assumptions under which the bound and differentiability are guaranteed.
Authors: Exact conservation (d²=0) is algebraic and holds for any ε-ball graph on which the Schur complement is defined, because the virtual node/edge measures are constructed to lie in the kernel of the coboundary operator. Differentiability with respect to point positions follows from the implicit-function theorem applied to the sparse linear solve, which is differentiable wherever the matrix is invertible. We acknowledge that global non-uniformity or sparsity can produce disconnected components or ill-conditioning. We will revise the abstract and Section 3 to list the same quasi-uniformity and connectivity assumptions above, and add a short remark that, in practice, disconnected graphs can be handled by a connectivity check or adaptive ε before the Schur solve. This makes the scope of the differentiability and bound claims explicit without altering the technical development. revision: yes
Circularity Check
No circularity: construction and bound are presented as direct mathematical results from the Schur complement on the graph.
full rationale
The paper defines MEEC via a single sparse Schur complement solve on the ε-ball graph, asserts that the resulting complex satisfies d²=0 exactly and is differentiable by construction, and states that a solution-error bound is proved with terms independent of geometry. No quoted step reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation whose content is the target claim itself. The transferability across geometries is supported by the explicit construction plus empirical benchmarks rather than by re-labeling inputs as outputs. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- epsilon for ball graph
axioms (1)
- domain assumption The Schur complement of the graph Laplacian or incidence matrix yields exact discrete conservation on the virtual complex.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.lean (and AbsoluteFloorClosure, Cost)reality_from_one_distinction; alexander_duality_circle_linking unclearMEEC equips an ε-ball graph with virtual node and edge measures via a single sparse Schur complement solve; the resulting complex satisfies discrete conservation exactly... We prove a solution-error bound that splits into discretization and kernel-approximation terms which is independent of problem geometry
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery; embed_injective unclearthe operator is conservative by algebraic identity and O(h)-consistent, without any mesh or dual-cell construction
Reference graph
Works this paper leans on
-
[1]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021
work page 2021
-
[2]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485, 2020
work page internal anchor Pith review arXiv 2003
-
[3]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
work page 2017
-
[4]
Ali Kashefi, Davis Rempe, and Leonidas J Guibas. A point-cloud deep learning framework for prediction of fluid flow fields on irregular geometries.Physics of Fluids, 33(2), 2021
work page 2021
-
[5]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
work page 2023
-
[6]
Ted Belytschko, Yury Krongauz, Daniel Organ, Mark Fleming, and Petr Krysl. Meshless methods: an overview and recent developments.Computer methods in applied mechanics and engineering, 139(1-4):3–47, 1996
work page 1996
-
[7]
Gui-Rong Liu.Meshfree methods: moving beyond the finite element method. CRC press, 2009
work page 2009
-
[8]
Paul T Boggs, Alan Althsuler, Alex R Larzelere, Edward J Walsh, Ruuobert L Clay, and Michael F Hardwick. Dart system analysis. Technical report, Sandia National Laboratories, 2005
work page 2005
-
[9]
California Institute of Technology, 2003
Anil Nirmal Hirani.Discrete exterior calculus. California Institute of Technology, 2003
work page 2003
- [10]
-
[11]
Nathaniel Trask, Andy Huang, and Xiaozhe Hu. Enforcing exact physics in scientific machine learning: a data-driven exterior calculus on graphs.Journal of Computational Physics, 456: 110969, 2022
work page 2022
-
[12]
Jonas A Actor, Xiaozhe Hu, Andy Huang, Scott A Roberts, and Nathaniel Trask. Data-driven whitney forms for structure-preserving control volume analysis.Journal of Computational Physics, 496:112520, 2024
work page 2024
-
[13]
Brooks Kinch, Benjamin Shaffer, Elizabeth Armstrong, Michael Meehan, John Hewson, and Nathaniel Trask. Structure-preserving digital twins via conditional neural whitney forms.arXiv preprint arXiv:2508.06981, 2025
-
[14]
Benjamin D Shaffer, Shawn Koohy, Brooks Kinch, M Ani Hsieh, and Nathaniel Trask. Structure-preserving learning improves geometry generalization in neural pdes.arXiv preprint arXiv:2602.02788, 2026
-
[15]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
work page 2021
-
[16]
Benjamin Sanderse, Panos Stinis, Romit Maulik, and Shady E Ahmed. Scientific machine learning for closure models in multiscale problems: A review.arXiv preprint arXiv:2403.02913, 2024. 10
-
[17]
Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. Physics informed deep learn- ing (part i): Data-driven solutions of nonlinear partial differential equations.arXiv preprint arXiv:1711.10561, 2017
work page Pith review arXiv 2017
-
[18]
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023
work page 2023
-
[19]
Learning mesh- based simulation with graph networks
Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter Battaglia. Learning mesh- based simulation with graph networks. InInternational Conference on Learning Representations, 2020
work page 2020
-
[20]
Message passing neural pde solvers
Johannes Brandstetter, Daniel Worrall, and Max Welling. Message passing neural pde solvers. arXiv preprint arXiv:2202.03376, 2022
-
[21]
Bocheng Zeng, Qi Wang, Mengtao Yan, Yang Liu, Ruizhi Chengze, Yi Zhang, Hongsheng Liu, Zidong Wang, and Hao Sun. Phympgn: Physics-encoded message passing graph network for spatiotemporal pde systems.arXiv preprint arXiv:2410.01337, 2024
-
[22]
Continuum attention for neural operators.Journal of Machine Learning Research, 26(300):1–52, 2025
Edoardo Calvello, Nikola B Kovachki, Matthew E Levine, and Andrew M Stuart. Continuum attention for neural operators.Journal of Machine Learning Research, 26(300):1–52, 2025
work page 2025
-
[23]
arXiv preprint arXiv:2402.02366 , year=
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for pdes on general geometries.arXiv preprint arXiv:2402.02366, 2024
-
[24]
Benedikt Alkin, Andreas Fürst, Simon Schmid, Lukas Gruber, Markus Holzleitner, and Johannes Brandstetter. Universal physics transformers: A framework for efficiently scaling neural operators.Advances in Neural Information Processing Systems, 37:25152–25194, 2024
work page 2024
-
[25]
Gnot: A general neural operator transformer for operator learning
Zhongkai Hao, Zhengyi Wang, Hang Su, Chengyang Ying, Yinpeng Dong, Songming Liu, Ze Cheng, Jian Song, and Jun Zhu. Gnot: A general neural operator transformer for operator learning. InInternational Conference on Machine Learning, pages 12556–12569. PMLR, 2023
work page 2023
-
[26]
Qibang Liu, Weiheng Zhong, Hadi Meidani, Diab Abueidda, Seid Koric, and Philippe Geubelle. Geometry-informed neural operator transformer for partial differential equations on arbitrary geometries.Computer Methods in Applied Mechanics and Engineering, 451:118668, 2026
work page 2026
-
[27]
Tian Wang and Chuang Wang. Latent neural operator for solving forward and inverse pde problems.Advances in Neural Information Processing Systems, 37:33085–33107, 2024
work page 2024
-
[28]
Zongyi Li, Nikola Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Otta, Moham- mad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, et al. Geometry-informed neural operator for large-scale 3d pdes.Advances in Neural Information Processing Systems, 36:35836–35854, 2023
work page 2023
-
[29]
Shizheng Wen, Arsh Kumbhat, Levi Lingsch, Sepehr Mousavi, Praveen Chandrashekar, and Siddhartha Mishra. Geometry aware operator transformer as an efficient and accurate neural surrogate for pdes on arbitrary domains.arXiv preprint arXiv:2505.18781, 2025
-
[30]
Nicola Rares Franco, Andrea Manzoni, and Paolo Zunino. Mesh-informed neural networks for operator learning in finite element spaces.Journal of Scientific Computing, 97(2):35, 2023
work page 2023
-
[31]
Yusuke Yamazaki, Ali Harandi, Mayu Muramatsu, Alexandre Viardin, Markus Apel, Tim Brepols, Stefanie Reese, and Shahed Rezaei. A finite element-based physics-informed operator learning framework for spatiotemporal partial differential equations on arbitrary domains. Engineering with Computers, 41(1):1–29, 2025
work page 2025
-
[32]
Maurits Bleeker, Matthias Dorfer, Tobias Kronlachner, Reinhard Sonnleitner, Benedikt Alkin, and Johannes Brandstetter. Neuralcfd: Deep learning on high-fidelity automotive aerodynamics simulations.arXiv e-prints, pages arXiv–2502, 2025
work page 2025
-
[33]
Louis Serrano, Thomas X Wang, Etienne Le Naour, Jean-Noël Vittaut, and Patrick Gallinari. Aroma: Preserving spatial structure for latent pde modeling with local neural fields.Advances in Neural Information Processing Systems, 37:13489–13521, 2024. 11
work page 2024
-
[34]
Benedikt Alkin, Maurits Bleeker, Richard Kurle, Tobias Kronlachner, Reinhard Sonnleit- ner, Matthias Dorfer, and Johannes Brandstetter. Ab-upt: Scaling neural cfd surrogates for high-fidelity automotive aerodynamics simulations via anchored-branched universal physics transformers.arXiv preprint arXiv:2502.09692, 2025
-
[35]
Brandon Amos and J Zico Kolter. Optnet: Differentiable optimization as a layer in neural networks.International Conference on Machine Learning, 2017
work page 2017
-
[36]
Deep equilibrium models.Advances in neural information processing systems, 32, 2019
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models.Advances in neural information processing systems, 32, 2019
work page 2019
-
[37]
Efficient and modular implicit differentiation
Mathieu Blondel, Quentin Berthet, Marco Cuturi, Roy Frostig, Stephan Hoyer, Felipe Llinares- López, Fabian Pedregosa, and Jean-Philippe Vert. Efficient and modular implicit differentiation. Advances in neural information processing systems, 35:5230–5242, 2022
work page 2022
-
[38]
Dmitrii Kochkov, Jamie A Smith, Ayya Alieva, Qing Wang, Michael P Brenner, and Stephan Hoyer. Machine learning–accelerated computational fluid dynamics.Proceedings of the National Academy of Sciences, 118(21):e2101784118, 2021
work page 2021
-
[39]
Huaiqian You, Quinn Zhang, Colton J Ross, Chung-Hao Lee, and Yue Yu. Learning deep implicit fourier neural operators (ifnos) with applications to heterogeneous material modeling. Computer Methods in Applied Mechanics and Engineering, 398:115296, 2022
work page 2022
-
[40]
Anran Jiao, Haiyang He, Rishikesh Ranade, Jay Pathak, and Lu Lu. One-shot learning for solution operators of partial differential equations.Nature Communications, 16(1):8386, 2025
work page 2025
-
[41]
Jiun-Shyan Chen, Michael Hillman, and Sheng-Wei Chi. Meshfree methods: progress made after 20 years.Journal of Engineering Mechanics, 143(4):04017001, 2017
work page 2017
-
[42]
Surfaces generated by moving least squares methods
Peter Lancaster and Kes Salkauskas. Surfaces generated by moving least squares methods. Mathematics of computation, 37(155):141–158, 1981
work page 1981
-
[43]
Nathaniel Trask, Mauro Perego, and Pavel Bochev. A high-order staggered meshless method for elliptic problems.SIAM Journal on Scientific Computing, 39(2):A479–A502, 2017
work page 2017
-
[44]
Birte Schrader, Sylvain Reboux, and Ivo F Sbalzarini. Discretization correction of general integral pse operators for particle methods.Journal of Computational Physics, 229(11):4159– 4182, 2010
work page 2010
-
[45]
Cambridge Monographs on Applied and Computational Mathematics
Holger Wendland.Scattered Data Approximation. Cambridge Monographs on Applied and Computational Mathematics. Cambridge University Press, Cambridge, 2004
work page 2004
-
[46]
Davoud Mirzaei, Robert Schaback, and Mehdi Dehghan. On generalized moving least squares and diffuse derivatives.IMA Journal of Numerical Analysis, 32(3):983–1000, 2012
work page 2012
-
[47]
Javier Bonet and T-SL Lok. Variational and momentum preservation aspects of smooth particle hydrodynamic formulations.Computer Methods in applied mechanics and engineering, 180 (1-2):97–115, 1999
work page 1999
-
[48]
Edmond Kay-yu Chiu, Qiqi Wang, Rui Hu, and Antony Jameson. A conservative mesh- free scheme and generalized framework for conservation laws.SIAM Journal on Scientific Computing, 34(6):A2896–A2916, 2012
work page 2012
-
[49]
Nathaniel Trask, Pavel Bochev, and Mauro Perego. A conservative, consistent, and scalable meshfree mimetic method.Journal of Computational Physics, 409:109187, 2020
work page 2020
-
[50]
Nathaniel Trask, Ravi G. Patel, Ben J. Gross, and Paul J. Atzberger. GMLS-Nets: A framework for learning from unstructured data.arXiv preprint arXiv:1909.05371, 2019
-
[51]
SPNets: Differentiable fluid dynamics for deep neural networks
Connor Schenck and Dieter Fox. SPNets: Differentiable fluid dynamics for deep neural networks. InProceedings of the 2nd Conference on Robot Learning, volume 87 ofProceedings of Machine Learning Research, pages 317–335. PMLR, 2018. 12
work page 2018
-
[52]
Toshev, Gianluca Galletti, Fabian Fritz, Stefan Adami, and Johannes Brandstetter
Artur P. Toshev, Gianluca Galletti, Fabian Fritz, Stefan Adami, and Johannes Brandstetter. Neural SPH: Improved neural modeling of lagrangian fluid dynamics. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research. PMLR, 2024
work page 2024
-
[53]
Michael M Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst. Geometric deep learning: going beyond euclidean data.IEEE Signal Processing Magazine, 34 (4):18–42, 2017
work page 2017
-
[54]
Principles of mimetic discretizations of differential operators
Pavel B Bochev and James M Hyman. Principles of mimetic discretizations of differential operators. InCompatible spatial discretizations, pages 89–119. Springer, 2006
work page 2006
-
[55]
Hamiltonian neural networks.Advances in neural information processing systems, 32, 2019
Samuel Greydanus, Misko Dzamba, and Jason Yosinski. Hamiltonian neural networks.Advances in neural information processing systems, 32, 2019
work page 2019
-
[56]
E (n) equivariant graph neural networks
Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E (n) equivariant graph neural networks. InInternational conference on machine learning, pages 9323–9332. PMLR, 2021
work page 2021
-
[57]
Simon Batzner, Albert Musaelian, Lixin Sun, Mario Geiger, Jonathan P Mailoa, Mordechai Kornbluth, Nicola Molinari, Tess E Smidt, and Boris Kozinsky. E (3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials.Nature communications, 13(1): 2453, 2022
work page 2022
-
[58]
Se (3) equivariant graph neural networks with complete local frames
Weitao Du, He Zhang, Yuanqi Du, Qi Meng, Wei Chen, Nanning Zheng, Bin Shao, and Tie-Yan Liu. Se (3) equivariant graph neural networks with complete local frames. InInternational Conference on Machine Learning, pages 5583–5608. PMLR, 2022
work page 2022
-
[59]
Chaoyu Liu, Yangming Li, Zhongying Deng, Chris Budd, and Carola-Bibiane Schönlieb. Conservation-preserved fourier neural operator through adaptive correction.arXiv preprint arXiv:2505.24579, 2025
-
[60]
Shuai Jiang, Jonas Actor, Scott Roberts, and Nathaniel Trask. A structure-preserving domain decomposition method for data-driven modeling.arXiv preprint arXiv:2406.05571, 2024
-
[61]
Peter D. Lax and Robert D. Richtmyer. Survey of the stability of linear finite difference equations.Communications on Pure and Applied Mathematics, 9(2):267–293, 1956. doi: 10.1002/cpa.3160090206
-
[62]
Simjeb: simulated jet engine bracket dataset
Eamon Whalen, Azariah Beyene, and Caitlin Mueller. Simjeb: simulated jet engine bracket dataset. InComputer Graphics Forum, volume 40, pages 9–17. Wiley Online Library, 2021
work page 2021
-
[63]
Seongjun Hong, Yongmin Kwon, Dongju Shin, Jangseop Park, and Namwoo Kang. Deepjeb: 3d deep learning-based synthetic jet engine bracket dataset.Journal of Mechanical Design, 147 (4):041703, 2025
work page 2025
-
[64]
James Rowbottom, Stefania Fresca, Pietro Lio, Carola-Bibiane Schönlieb, and Nicolas Boullé. Multi-level monte carlo training of neural operators.Computer Methods in Applied Mechanics and Engineering, 453:118800, 2026
work page 2026
- [65]
-
[66]
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd. OSQP: an operator splitting solver for quadratic programs.Mathematical Programming Computation, 12(4):637–672, 2020. doi: 10.1007/s12532-020-00179-2. URLhttps://doi.org/10.1007/s12532-020-00179-2
-
[67]
SOAP: Improving and stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321, 2024
-
[68]
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017. 13
work page 2017
-
[69]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on machine learning, pages 5156–5165. PMLR, 2020
work page 2020
-
[70]
Shuhao Cao. Choose a transformer: Fourier or galerkin.Advances in neural information processing systems, 34:24924–24940, 2021. A Discrete exterior calculus background This appendix is a short, self-contained primer on the discrete exterior calculus (DEC) constructions we use, following the graph-cochain conventions of Trask et al.[11]. The body of the pap...
work page 2021
-
[71]
holds only when test features lie in the training feature distribution. Practitioners deploying the method in safety-relevant workflows should verify feature coverage and validate against held-out high-fidelity simulations before relying on predictions. We do not see acute misuse risks of the kind associated with generative or surveillance technologies; t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.