Recognition: 2 theorem links
· Lean TheoremNICE FACT: Diagnosing and Calibrating VLMs in Quantitative Reasoning for Kinematic Physics
Pith reviewed 2026-05-12 02:19 UTC · model grok-4.3
The pith
Vision-language models fail to identify visual preconditions or apply physical laws when solving kinematic physics problems, often guessing instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Evaluated across six state-of-the-art VLMs, the models fail to identify visual preconditions or utilize necessary physical laws to reach answers in kinematic physics, instead producing plausible guesses, as shown by the FACT decomposition of visual fidelity, law comprehension, and temporal grounding combined with NICE calibration of confidence reliability.
What carries the argument
The FACT diagnostic that explicitly decomposes quantitative kinematic reasoning into visual fidelity, physical law comprehension, and temporal grounding, together with the NICE neighborhood-informed calibration method and metrics for assessing confidence reliability.
If this is right
- Models must improve at detecting and using specific visual preconditions rather than relying on pattern matching.
- Explicit incorporation of physical laws is required beyond current implicit learning in VLMs for kinematic tasks.
- Temporal grounding in sequential physics scenarios remains a distinct failure mode needing targeted fixes.
- Neighborhood-based calibration offers a practical route to make model confidence scores more trustworthy.
- A standardized diagnostic paradigm can serve as a benchmark to track progress toward physically faithful VLMs.
Where Pith is reading between the lines
- Similar decomposition diagnostics could be adapted to test law application in other quantitative domains such as biology or chemistry.
- The results imply that purely scaling data or model size may not resolve these failures without architectural changes for explicit law handling.
- Hybrid systems combining VLMs with symbolic physics engines could be tested as a direct extension of the identified gaps.
- Wider application to non-kinematic physics or real-world video inputs would likely surface additional grounding issues.
Load-bearing premise
The proposed FACT diagnostics and NICE calibration accurately isolate and measure deficiencies in visual fidelity, law comprehension, and temporal grounding without introducing their own methodological biases or task-specific artifacts.
What would settle it
An experiment that supplies VLMs with explicit statements of the required physical laws and visual preconditions for each problem and measures whether accuracy rises substantially above the unaided baseline would falsify the claim that models primarily fail at identification and utilization of those elements.
Figures





read the original abstract
The ability to derive precise spatial and physical insights is a cornerstone of vision-language models (VLMs), yet their poor performances in related spatial intelligence tasks such as physical reasoning remain a fundamental barrier. The community critically lacks a scientific analysis revealing whether VLMs faithfully reach answers or plausibly make guesses. This work aims to provide a fundamental understanding of how VLMs perceive the physical world, and utilize physical laws, while assessing the reliability of model confidence. We propose NICE and FACT, a dual-diagnostic paradigm that explicitly decomposes quantitative reasoning for kinematic physics: FACT diagnoses visual fidelity, physical law comprehension, and temporal grounding. NICE studies our novel neighborhood-informed calibration method and novel metrics to evaluate and calibrate confidence reliability. Evaluated across 6 latest state-of-the-art VLMs, we uncover that models fail to identify visual preconditions or utilize necessary physical laws to reach answers. This work highlights and establishes a standardized diagnostic paradigm to guide the development of faithful, physically-grounded VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NICE and FACT as a dual-diagnostic paradigm for analyzing vision-language models (VLMs) on quantitative reasoning in kinematic physics. FACT decomposes reasoning into explicit diagnostics for visual fidelity, physical law comprehension, and temporal grounding. NICE introduces a neighborhood-informed calibration method with novel metrics to assess and improve confidence reliability. Evaluation on six state-of-the-art VLMs shows consistent failures to identify visual preconditions or apply necessary physical laws, even under controlled visual inputs.
Significance. If the diagnostics hold, the work supplies a standardized, decomposable framework for diagnosing whether VLMs perform genuine physical reasoning or plausible guessing, directly addressing a core barrier in spatial intelligence. The explicit probe definitions and reported under-performance on law-utilization tasks (with visual controls) provide actionable, falsifiable insights that could guide development of more reliable, physically-grounded VLMs.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation for minor revision. The referee summary accurately reflects the contributions of the NICE and FACT framework for diagnosing VLM failures in visual precondition identification and physical law application on kinematic physics tasks.
Circularity Check
No significant circularity identified
full rationale
The paper defines FACT as an explicit decomposition of quantitative reasoning into three diagnostic probes (visual fidelity, physical law comprehension, temporal grounding) and NICE as a neighborhood-informed calibration procedure with associated metrics. These are introduced as independent evaluation tools rather than derived quantities. No equations, parameter-fitting steps, or self-referential definitions appear that would render any reported outcome equivalent to its inputs by construction. The central findings rest on empirical performance differences across six VLMs on the defined probes, with no load-bearing self-citations or uniqueness claims imported from prior author work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard VLM evaluation tasks can be decomposed into visual fidelity, physical law comprehension, and temporal grounding components.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearFACT diagnoses visual fidelity, physical law comprehension, and temporal grounding. NICE studies our novel neighborhood-informed calibration method
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose NICE and FACT, a dual-diagnostic paradigm that explicitly decomposes quantitative reasoning for kinematic physics
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Physbench: Benchmarking and enhancing vision-language models for physical world under- standing
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Campagnolo Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physical world under- standing. InICLR 2025 Workshop on Foundation Models in the Wild,
work page 2025
-
[4]
STAR: A Benchmark for Situ- ated Reasoning in Real-World Videos.arXiv e-prints, art
URL https: //openreview.net/forum?id=8CH4KIEVNz. Bo Wu, Shoubin Yu, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. Star: A benchmark for situated reasoning in real-world videos.arXiv preprint arXiv:2405.09711,
-
[5]
Mingrui Wu, Zhaozhi Wang, Fangjinhua Wang, Jiaolong Yang, Marc Pollefeys, and Tong Zhang. From indoor to open world: Revealing the spatial reasoning gap in mllms.arXiv preprint arXiv:2512.19683,
-
[6]
Reasoning in space via grounding in the world.arXiv preprint arXiv:2510.13800, 2025
Yiming Chen, Zekun Qi, Wenyao Zhang, Xin Jin, Li Zhang, and Peidong Liu. Reasoning in space via grounding in the world.arXiv preprint arXiv:2510.13800,
-
[7]
Jihan Yang, Shusheng Yang, Anjali W
URLhttps://arxiv.org/abs/2601.15533. Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10632– 10643, June 2025b. Boyuan Chen, Zhuo Xu, ...
-
[8]
Control-oriented model-based reinforcement learning with implicit differentiation
doi: 10.1609/aaai. v39i4.32468. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/32468. Jian Lan, Udo Schlegel, Tanveer Hannan, Gengyuan Zhang, Haokun Chen, and Thomas Seidl. Unveiling the "fairness seesaw": Discovering and mitigating gender and race bias in vision- language models, 2026b. URLhttps://arxiv.org/abs/2505.23798. Judea Pearl.Causality: Mod...
-
[9]
Stop measuring calibration when humans disagree
Joris Baan, Wilker Aziz, Barbara Plank, and Raquel Fernandez. Stop measuring calibration when humans disagree. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1892–1915, Abu Dhabi, United Arab Emirates, December
work page 2022
-
[10]
doi: 10.18653/v1/2022.emnlp-main.124
Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.124. URL https: //aclanthology.org/2022.emnlp-main.124. Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, et al. Molmo2: Open weights and data for vision-language models with vi...
-
[11]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URL https://arxiv.org/abs/2503. 19786. Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, et al. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299,
work page internal anchor Pith review arXiv
-
[16]
ISSN 2835-8856. URLhttps://openreview.net/forum?id=EElFGvt39K. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv prep...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Unifying discrete and continuous representations for unsupervised paraphrase generation
12 Mingfeng Xue, Dayiheng Liu, Wenqiang Lei, Jie Fu, Jian Lan, Mei Li, Baosong Yang, Jun Xie, Yidan Zhang, Dezhong Peng, and Jiancheng Lv. Unifying discrete and continuous representations for unsupervised paraphrase generation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Languag...
work page 2023
-
[18]
doi: 10.18653/v1/2023.emnlp-main.852
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.852. URL https://aclanthology.org/2023.emnlp-main. 852/. Jian Lan, Runfeng Shi, Ye Cao, and Jiancheng Lv. Knowledge graph-based conversational recom- mender system in travel. In2022 International Joint Conference on Neural Networks (IJCNN), pages 1–8,
-
[19]
Speech recognition through physical reservoir computing with neuromorphic nanowire networks,
doi: 10.1109/IJCNN55064.2022.9892176. Jian Lan, Mingfeng Xue, and Jiancheng Lv. Rulepg: Syntactic rule-enhanced paraphrase generation. In2023 International Joint Conference on Neural Networks (IJCNN), pages 1–8,
-
[20]
doi: 10.1109/IJCNN54540.2023.10191854. 13 Technical appendices and supplementary material A More Justification for Theoretical Design We justify this diagnostic approach through three theoretical lenses:Causal Identifiability via Inter- vention: According to the Causal Hierarchy [Pearl, 2009], purely observational data P(a|V,Q) is insufficient to distingu...
-
[21]
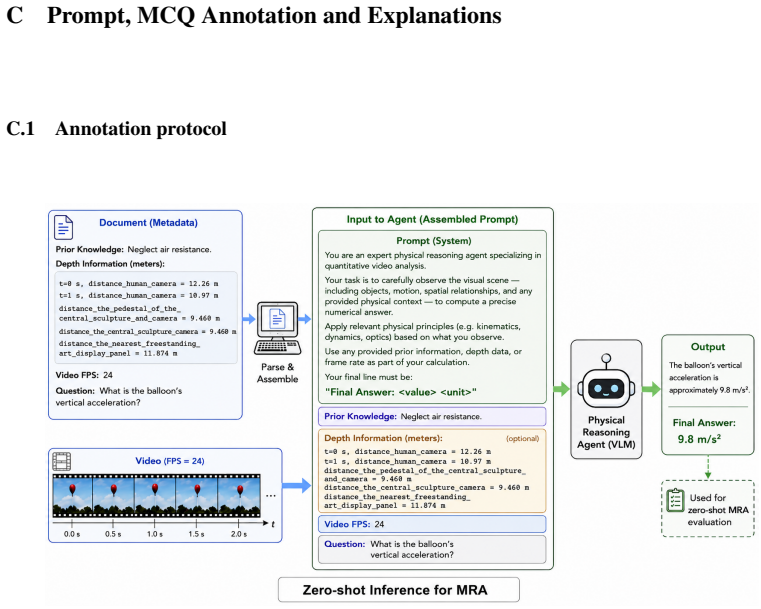
is one of the most widely used and most traditional methods. When we apply temperature scaling, the log-probability of the entire sequence S becomes: logP(S;T) = nX i=1 zi,idx(xi) T −log |V|X j=1 exp zi,j T (14) 16 C Prompt, MCQ Annotation and Explanations C.1 Annotation protocol Figure 4: Illustration our prompt for generating zero-shot MRA. Figu...
work page 2025
-
[22]
For physical law comprehension,[Formula-C] Average Velocity Definition v= ∆x ∆t (15) This equation establishes the definition ofaverage velocity. It quantifies the rate of change of position, calculated as the ratio of the total displacement (∆x) to the duration of the time interval (∆t). [Formula-D] Displacement in Uniformly Accelerated Motion x=v 0t+ 1 ...
work page 2054
-
[23]
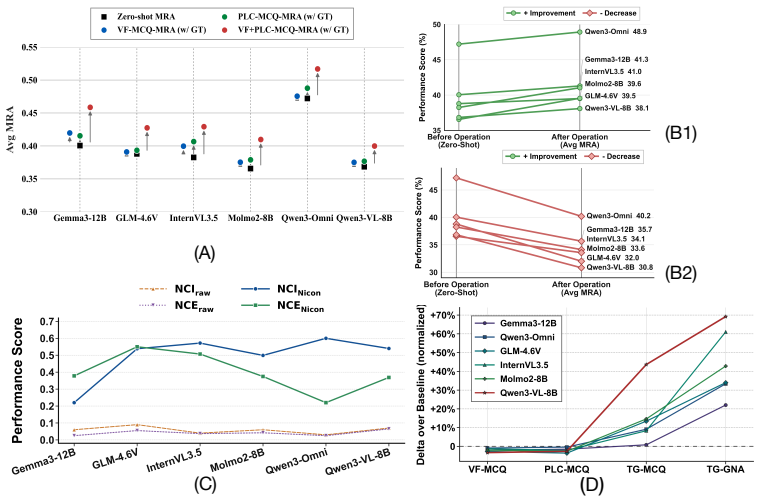
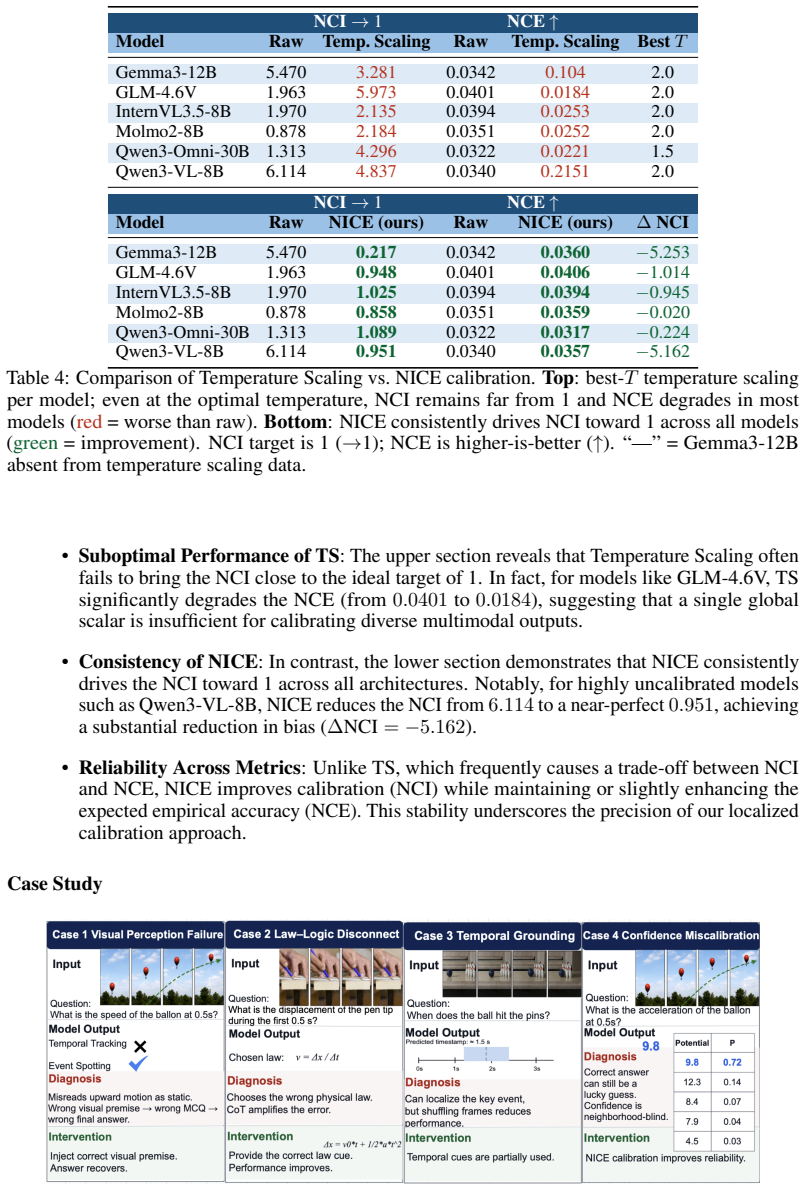
In fact, for models like GLM-4.6V , TS significantly degrades the NCE (from 0.0401 to 0.0184), suggesting that a single global scalar is insufficient for calibrating diverse multimodal outputs. • Consistency of NICE: In contrast, the lower section demonstrates that NICE consistently drives the NCI toward 1 across all architectures. Notably, for highly unc...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.