Recognition: 2 theorem links
· Lean TheoremRobust Learning Meets Quasar-Convex Optimization: Inexact High-Order Proximal-Point Methods
Pith reviewed 2026-05-12 00:48 UTC · model grok-4.3
The pith
Robust learning tasks can be reformulated as quasar-convex problems, for which an inexact high-order proximal-point method converges globally with local linear or superlinear rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Robust learning problems can be expressed as strongly quasar-convex optimization problems that possess a benign landscape free of saddle points. For these problems the proposed inexact high-order proximal-point method HiPPA, whose subproblem accuracy is governed by the model-value gap, converges globally to a global minimizer. The local convergence rate is linear when the regularization order equals one and becomes superlinear for higher orders provided the inexactness tolerance decreases appropriately.
What carries the argument
HiPPA, the inexact high-order proximal-point method that employs the model-value gap to regulate the accuracy of each subproblem solution.
If this is right
- Global convergence to a global minimizer holds from arbitrary initial points once the problem is cast in strongly quasar-convex form.
- Local convergence improves from linear to superlinear when the proximal regularization order is raised and the model-value gap tolerance is tightened accordingly.
- The same framework applies to the robust feature-alignment distillation task used in the experiments.
- Absence of saddle points removes the need for escape techniques that many non-convex methods require.
Where Pith is reading between the lines
- The quasar-convex lens may extend to additional robustness settings such as adversarial training or distributionally robust optimization.
- If further robust learning problems prove to be quasar-convex, high-order proximal methods could replace heuristic solvers that lack global guarantees.
- Scaling the approach to larger neural networks would reveal whether the local superlinear rates produce practical wall-clock improvements.
Load-bearing premise
That core robust learning problems can be cast as strongly quasar-convex optimization problems whose landscapes contain no saddle points.
What would settle it
A concrete robust learning task that cannot be written as a strongly quasar-convex problem, or a numerical run of HiPPA that diverges or stalls at a non-minimizer on such a task, would refute the claim.
Figures
read the original abstract
Robust learning aims to maintain model performance under noise, corruption, and distributional shifts, which are prevalent in modern machine learning applications. This work shows that examples of robust learning problems can be formulated as (strongly) quasar-convex optimization problems, which admit a benign landscape with no saddle points. We then propose HiPPA, an inexact high-order proximal-point method that employs a model-value gap to control the inexactness of subproblem solutions. Notably, we prove global convergence of HiPPA to global minima and establish that it attains a (local) linear or superlinear convergence rate, depending on the regularization order and inexactness control. Our numerical experiments on robust feature-alignment distillation indicate strong empirical performance of HiPPA and results consistent with our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper shows that certain robust learning problems admit a (strongly) quasar-convex formulation with benign landscapes free of saddle points. It introduces the inexact high-order proximal-point algorithm HiPPA, which uses a model-value-gap criterion to control subproblem inexactness, and proves global convergence of HiPPA to global minima together with local linear or superlinear rates that depend on the regularization order. Supporting numerical results are given for robust feature-alignment distillation.
Significance. If the quasar-convex reformulations and the convergence analysis hold, the work supplies a principled algorithmic framework for robust learning problems that avoids the non-convexity obstacles common in the field. The model-value-gap inexactness control and the explicit rate dependence on regularization order are technically attractive features that could be reused in other high-order proximal methods.
major comments (2)
- [§3.2] §3.2, the statement that 'examples of robust learning problems can be formulated as strongly quasar-convex': the paper must exhibit the explicit quasar-convexity parameter μ and the function class for at least one concrete robust-learning objective (e.g., the feature-alignment loss) so that the global-convergence claim in Theorem 4.1 is not vacuous.
- [Theorem 5.3] Theorem 5.3 (local superlinear rate): the proof sketch invokes a model-value-gap tolerance that shrinks faster than the distance to the solution, but the precise relation between the regularization order p and the resulting rate exponent is stated only qualitatively; an explicit dependence (e.g., O(‖x−x*‖^{p−1})) should be derived or referenced.
minor comments (3)
- [Definition 2.4] Notation for the model-value gap (Definition 2.4) is introduced without a clear comparison to the standard proximal residual; a short remark relating the two would help readers familiar with classical proximal-point literature.
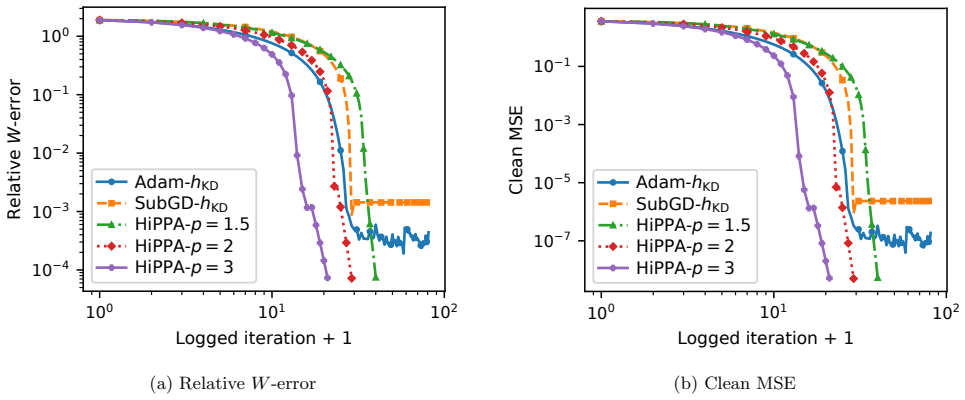
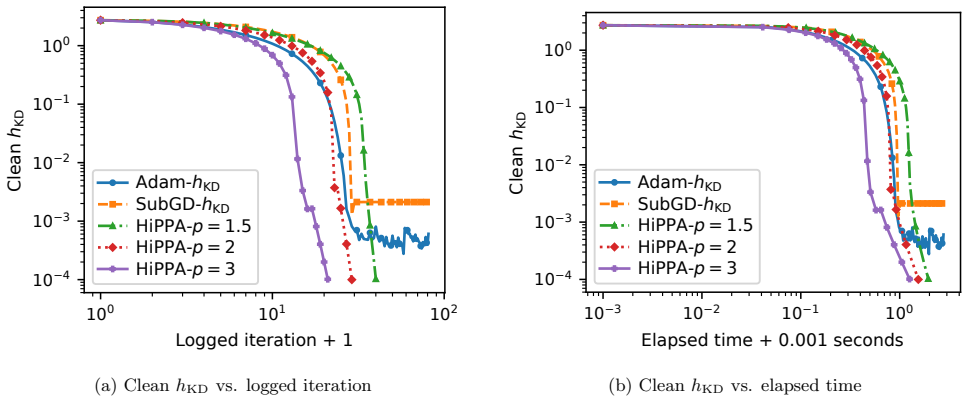
- [Figure 2] Figure 2 (convergence curves) lacks error bars or multiple random seeds; adding them would strengthen the empirical support for the claimed linear/superlinear regimes.
- [§6] The abstract claims 'strong empirical performance' but the experiments section only reports final accuracy; a table of iteration counts or wall-clock time versus baselines would make the practical advantage concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation. We address each major comment below and will incorporate the requested clarifications into the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2, the statement that 'examples of robust learning problems can be formulated as strongly quasar-convex': the paper must exhibit the explicit quasar-convexity parameter μ and the function class for at least one concrete robust-learning objective (e.g., the feature-alignment loss) so that the global-convergence claim in Theorem 4.1 is not vacuous.
Authors: We agree that an explicit parameter strengthens the claim. The feature-alignment distillation loss is shown in §3.2 to satisfy strong quasar-convexity, and we will add a short calculation in the revision that derives the concrete value μ = 1/2 together with the precise function class (strongly quasar-convex with modulus μ). This makes the invocation of Theorem 4.1 fully concrete without altering any existing proofs. revision: yes
-
Referee: [Theorem 5.3] Theorem 5.3 (local superlinear rate): the proof sketch invokes a model-value-gap tolerance that shrinks faster than the distance to the solution, but the precise relation between the regularization order p and the resulting rate exponent is stated only qualitatively; an explicit dependence (e.g., O(‖x−x*‖^{p−1})) should be derived or referenced.
Authors: We accept the suggestion. The model-value-gap condition already implies that the local error satisfies ‖x_{k+1} − x*‖ = O(‖x_k − x*‖^p) when the tolerance is chosen proportionally to the current gap; we will expand the proof of Theorem 5.3 by one paragraph to state the explicit local rate O(‖x_k − x*‖^{p−1}) for regularization order p ≥ 2. The argument follows directly from the existing Taylor expansion and the gap control, so no new assumptions are required. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper reformulates selected robust learning problems as (strongly) quasar-convex programs and supplies an independent convergence analysis for the proposed inexact high-order proximal-point method HiPPA, including global convergence to minima and local linear/superlinear rates governed by regularization order and model-value-gap inexactness. No load-bearing step reduces by definition or by self-citation to its own inputs; the reformulation is presented as an explicit modeling choice, and the convergence claims are stated as proven results separate from any data-specific fitting. The provided abstract and summary contain no self-definitional equations, fitted-input predictions, or uniqueness theorems imported solely from the authors' prior work. The argument chain therefore remains externally verifiable through standard quasar-convexity theory and proximal-point analysis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Robust learning problems can be formulated as (strongly) quasar-convex optimization problems
- domain assumption The model-value gap controls the inexactness of subproblem solutions appropriately
invented entities (1)
-
HiPPA (High-order Proximal-Point Algorithm)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearDefinition 1((Strong) quasar-convexity). ... h(λx+(1−λ)x*) ≤ κλ h(x) + (1−κλ)h(x*) − λ(1−λ/(2−κ))(κγ/2)∥x−x*∥²
Reference graph
Works this paper leans on
-
[1]
Absil, P. A. and Mahony, R. and Andrews, B. , title =. SIAM Journal on Optimization , volume =
-
[2]
Mathematical Programming , volume =
High-order methods beyond the classical complexity bounds: Inexact high-order proximal-point methods , author=. Mathematical Programming , volume =. 2024 , publisher=
work page 2024
-
[3]
Ahookhosh, Masoud and Nesterov, Yurii , title =. Submitted manuscript , year =
-
[4]
SIAM Journal on Optimization , volume =
Ahookhosh, Masoud and Themelis, Andreas and Patrinos, Panagiotis , title =. SIAM Journal on Optimization , volume =
-
[5]
Ahookhosh, Masoud and Ghaderi, Susan , journal=. On efficiency of nonmonotone. 2017 , publisher=
work page 2017
-
[6]
Mathematical Methods of Operations Research , volume=
Accelerated first-order methods for large-scale convex optimization: Nearly optimal complexity under strong convexity , author=. Mathematical Methods of Operations Research , volume=. 2019 , publisher=
work page 2019
-
[7]
Ahookhosh, M. and Iusem, A. and Kabgani, A. and Lara, F. , title =. arXiv:2505.20484 , pages =. 2025 , url =
-
[8]
Ahookhosh, M. and de Brito, J. and Kabgani, A. and Lara, F. and Yuan, J. , title =. 2026 , journal =
work page 2026
-
[9]
Al-Homidan, S. and Hadjisavvas, N. and Shaalan, L. , title =. Journal of Optimization Theory and Applications , pages =
-
[10]
SIAM Journal on Optimization , volume=
MGProx: A Nonsmooth Multigrid Proximal Gradient Method with Adaptive Restriction for Strongly Convex Optimization , author=. SIAM Journal on Optimization , volume=. 2024 , publisher=
work page 2024
-
[11]
Numerical Algorithms , volume=
An inexact line search approach using modified nonmonotone strategy for unconstrained optimization , author=. Numerical Algorithms , volume=
- [12]
-
[13]
Atenas, Felipe and Sagastiz\'. A Unified Analysis of Descent Sequences in Weakly Convex Optimization, Including Convergence Rates for Bundle Methods , journal =
- [14]
-
[15]
Attouch, Hedy and Wets, Roger J.-B. , journal =. Quantitative stability of variational systems: I. The epigraphical distance , volume =
-
[16]
Attouch, H. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the. Mathematics of operations research , volume=. 2010 , publisher=
work page 2010
-
[17]
Attouch, H. and Bolte, J. and Svaiter, B.F. , journal =. Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized
-
[18]
Aujol, J-F and Dossal, Ch and Rondepierre, Aude , journal=. 2024 , publisher=
work page 2024
-
[19]
SIAM Journal on Control and Optimization , volume =
Auslender, Alfred , title =. SIAM Journal on Control and Optimization , volume =
-
[20]
Mathematical Programming , volume=
Newton acceleration on manifolds identified by proximal gradient methods , author=. Mathematical Programming , volume=
-
[21]
Mathematical Programming , volume=
Principled analyses and design of first-order methods with inexact proximal operators , author=. Mathematical Programming , volume=. 2023 , publisher=
work page 2023
-
[22]
Barron, J. T. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[23]
Bauschke, H.-H. and Combettes, P.-L. , year=. Convex Analysis and Monotone Operator Theory in Hilbert Spaces , edition=
-
[24]
Set-Valued and Variational Analysis , volume=
Subgradient projectors: Extensions, theory, and characterizations , author=. Set-Valued and Variational Analysis , volume=
-
[25]
Mathematical Programming , volume=
Characterizing quasiconvexity of the pointwise infimum of a family of arbitrary translations of quasiconvex functions, with applications to sums and quasiconvex optimization , author=. Mathematical Programming , volume=. 2021 , publisher=
work page 2021
-
[26]
SIAM Journal on Imaging Sciences , volume=
A fast iterative shrinkage-thresholding algorithm for linear inverse problems , author=. SIAM Journal on Imaging Sciences , volume=. 2009 , publisher=
work page 2009
-
[27]
SIAM Journal on Optimization , volume =
Beck, Amir and Teboulle, Marc , title =. SIAM Journal on Optimization , volume =
- [28]
-
[29]
A smoothing technique for nondifferentiable optimization problems , author=. Optimization: Proceedings of the Fifth French-German Conference held in Castel-Novel (Varetz), France, Oct. 3--8, 1988, Lecture Notes in Mathematics, No. 1405 , pages=. 1989 , editor =
work page 1988
-
[30]
Foundations of Computational Mathematics , volume=
A theoretical and empirical comparison of gradient approximations in derivative-free optimization , author=. Foundations of Computational Mathematics , volume=. 2022 , publisher=
work page 2022
-
[31]
Nondifferentiable Optimization , pages=
Nondifferentiable optimization via approximation , author=. Nondifferentiable Optimization , pages=. 2009 , editor =
work page 2009
- [32]
- [33]
-
[34]
SIAM Journal on Optimization , volume=
Clarke subgradients of stratifiable functions , author=. SIAM Journal on Optimization , volume=
-
[35]
Proximal alternating linearized minimization for nonconvex and nonsmooth problems , journal =
J. Proximal alternating linearized minimization for nonconvex and nonsmooth problems , journal =
-
[36]
SIAM Journal on Optimization , volume=
Convergence of Inexact Forward--Backward Algorithms Using the Forward-Backward Envelope , author=. SIAM Journal on Optimization , volume=. 2020 , publisher=
work page 2020
- [37]
-
[38]
Journal of Scientific Computing , year =
Boţ, Radu Ioan and Böhm, Axel , title =. Journal of Scientific Computing , year =
- [39]
- [40]
-
[41]
Bredies, Kristian and Chenchene, Enis and Lorenz, Dirk A. and Naldi, Emanuele , title =. SIAM Journal on Optimization , volume =
-
[42]
Extending Linear Convergence of the Proximal Point Algorithm: The Quasar-Convex Case
Extending linear convergence of the proximal point algorithm: The quasar-convex case , author=. arXiv preprint arXiv:2509.04375 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Brooks, J. P. , title =. Operations Research , volume =
-
[44]
Journal of Optimization Theory and Applications , volume=
Local--global minimum property in unconstrained minimization problems , author=. Journal of Optimization Theory and Applications , volume=. 2014 , publisher=
work page 2014
-
[45]
and Hoheisel, Tobias , title =
Burke, James V. and Hoheisel, Tobias , title =. SIAM Journal on Optimization , volume =
-
[46]
Mathematical Programming , volume=
Sample size selection in optimization methods for machine learning , author=. Mathematical Programming , volume=
-
[47]
International Journal of Mathematical Sciences , volume=
Coercivity concepts and recession function in constrained problems , author=. International Journal of Mathematical Sciences , volume=
-
[48]
Generalized Convexity and Optimization: Theory and Applications , author=. 2009 , publisher=
work page 2009
- [49]
- [50]
- [51]
-
[52]
Similarity and matching of neural network representations , year =
Csisz. Similarity and matching of neural network representations , year =. arXiv: 2110.14633 , journal =
- [53]
-
[54]
Functional Analysis, Calculus of Variations and Optimal Control , author=. 2013 , publisher=
work page 2013
-
[55]
Conn, A. R. and Mongeau, M. , title =. Mathematical Programming , volume =
-
[56]
Continuity and differentiability of quasiconvex functions
Crouzeix, Jean-Pierre. Continuity and differentiability of quasiconvex functions. Handbook of Generalized Convexity and Generalized Monotonicity
-
[57]
and Paquette,Courtney , title =
Davis, Damek and Drusvyatskiy, Dmitriy and MacPhee, Kyle J. and Paquette,Courtney , title =. Journal of Optimization Theory and Applications , year =
-
[58]
Foundations of Computational Mathematics , volume=
Proximal methods avoid active strict saddles of weakly convex functions , author=. Foundations of Computational Mathematics , volume=. 2022 , publisher=
work page 2022
-
[59]
Escaping Strict Saddle Points of the
Davis, Damek and D\'. Escaping Strict Saddle Points of the. SIAM Journal on Optimization , volume =
-
[60]
Optimality Conditions in Convex Optimization: A Finite-Dimensional View , author=. 2012 , publisher=
work page 2012
-
[61]
Drusvyatskiy, Dmitriy , title =. 2018 , url =. 1712.06038 , archiveprefix =
-
[62]
Mathematical Programming , volume =
Drusvyatskiy, Dmitry and Paquette, Cedric , title =. Mathematical Programming , volume =
-
[63]
Duchi, J. and Namkoong, H. , title =. Journal of Machine Learning Research , volume =
-
[64]
Dvurechensky, P. E. , title =. Computer Research and Modeling , year =
-
[65]
arXiv preprint arXiv:2505.02281 , year=
Minimisation of quasar-convex functions using random zeroth-order oracles , author=. arXiv preprint arXiv:2505.02281 , year=
-
[66]
SIAM Journal on Optimization , volume=
A Globally and Superlinearly Convergent Algorithm for Nonsmooth Convex Minimization , author=. SIAM Journal on Optimization , volume=. 1996 , publisher=
work page 1996
-
[67]
International Journal of Systems Science , volume=
A generalized proximal point algorithm for certain non-convex minimization problems , author=. International Journal of Systems Science , volume=. 1981 , publisher=
work page 1981
-
[68]
Applied Mathematics and Computation , volume =
Ghaderi, Saeed and Ahookhosh, Masoud and Arany, Adam and Skupin, Alexander and Patrinos, Panagiotis and Moreau, Yves , title =. Applied Mathematics and Computation , volume =
-
[69]
Journal of Information and Optimization Sciences , volume =
Giorgio Giorgi and Angelo Guerraggio , title =. Journal of Information and Optimization Sciences , volume =
-
[70]
Dini derivatives in optimization—Part
Giorgi, Giorgio and Koml. Dini derivatives in optimization—Part. Rivista di matematica per le scienze economiche e sociali , volume=. 1992 , publisher=
work page 1992
-
[71]
Journal of Optimization Theory and Applications , volume=
Strongly quasiconvex functions: What we know (so far) , author=. Journal of Optimization Theory and Applications , volume=
-
[72]
Multi-Stage Multi-Task Feature Learning , volume =
Gong, Pinghua and Ye, Jieping and Zhang, Chang-shui , booktitle =. Multi-Stage Multi-Task Feature Learning , volume =
-
[73]
Mathematical Programming , pages=
Some primal-dual theory for subgradient methods for strongly convex optimization , author=. Mathematical Programming , pages=. 2025 , publisher=
work page 2025
-
[74]
SIAM Journal on Optimization , volume =
Gu, Guoyong and Yang, Junfeng , title =. SIAM Journal on Optimization , volume =
-
[75]
On the Convergence of the Proximal Point Algorithm for Convex Minimization , journal =
G\". On the Convergence of the Proximal Point Algorithm for Convex Minimization , journal =
-
[76]
New Proximal Point Algorithms for Convex Minimization , journal =
G\". New Proximal Point Algorithms for Convex Minimization , journal =
-
[77]
Accelerated methods for weakly-quasi-convex optimization problems: S. Guminov et al. , author=. Computational Management Science , volume=. 2023 , publisher=
work page 2023
-
[78]
Hermant, Julien and Aujol, Jean-Fran. Study of the behaviour of. arXiv preprint arXiv:2405.19809 , year=
-
[79]
Handbook of generalized convexity and generalized monotonicity , author=. 2005 , publisher=
work page 2005
-
[80]
Hadjisavvas, N. and Lara, F. and Marcavillaca, R. T. and Vuong, P. T. , title =. Applied Mathematics and Optimization , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.