Recognition: 1 theorem link
· Lean TheoremTeachers' Perceived Benefits and Risks of AI Across Fifty-Five Countries: An Audit of LLM Alignment and Steerability
Pith reviewed 2026-05-12 01:19 UTC · model grok-4.3
The pith
Large language models compress cross-national differences in how teachers perceive AI benefits and risks and overestimate both.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
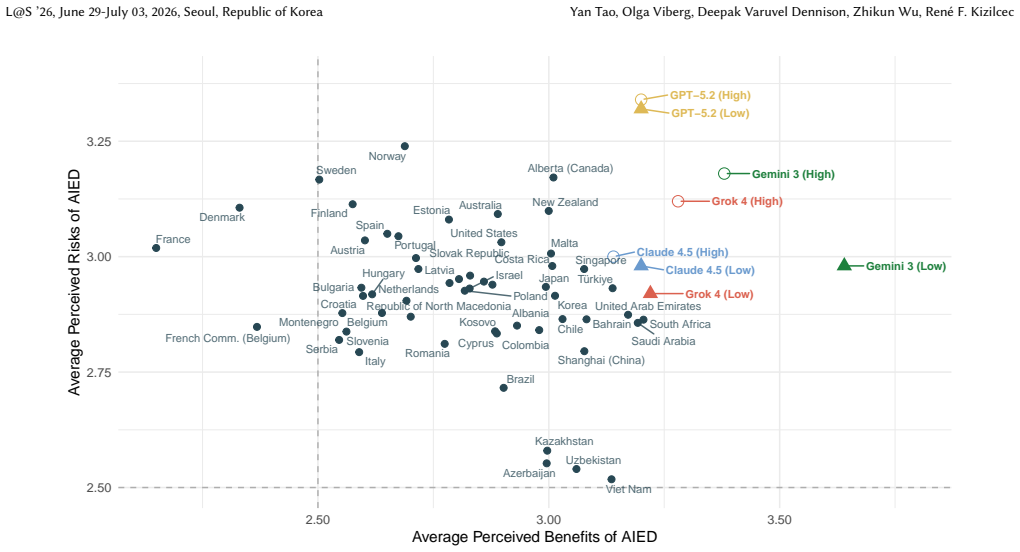
Using TALIS data, teachers report substantial country-to-country differences in the perceived benefits and risks of AI; when eight state-of-the-art LLMs are asked to answer the same items under general or country-specific prompting, their responses compress those differences, overestimate both benefits and risks, and show only limited improvement from higher-reasoning variants or identity prompts, with partial exceptions such as Gemini 3 Fast preserving some ranking patterns.
What carries the argument
Direct benchmarking of LLM survey responses against the TALIS international teacher sample under controlled prompting conditions.
If this is right
- LLM outputs should not be used as substitutes for direct teacher input when designing global AI-in-education policies.
- Some models retain partial ability to recover cross-national ranking patterns and may still support exploratory hypothesis generation.
- Professional development materials and policy briefs that rely on LLMs risk transmitting flattened or exaggerated views of AI to teachers.
- Steerability techniques such as country-identity prompting produce only marginal gains in matching real teacher distributions.
Where Pith is reading between the lines
- Model developers could fine-tune on disaggregated TALIS-style items to reduce compression of country differences.
- Policy bodies may need separate mechanisms for collecting localized teacher feedback rather than relying on LLM synthesis.
- Experimental studies could test whether exposure to aligned versus misaligned LLM content changes teachers' actual classroom AI use.
- The same audit method could be applied to other stakeholder groups such as school leaders or parents to map broader perception gaps.
Load-bearing premise
That LLM answers to survey-style questions about AI can be read as meaningful indicators of alignment with teachers' real-world perceptions across cultures.
What would settle it
A new round of surveys in which teachers from high- and low-variation countries rate LLM-generated summaries of AI benefits and risks and show no systematic difference in trust or adoption intent compared with summaries drawn from their own country's TALIS responses.
Figures


read the original abstract
Teachers' trust in artificial intelligence (AI) in education depends on how they balance its perceived benefits and risks. Yet global discussions about scaling AI in education rely on fragmented evidence, as most studies of teachers' perceptions focus on single countries or small samples. This lack of representative cross-national evidence limits both theory building and policy development. At the same time, large language models (LLMs) are increasingly used in research, policy, and teachers' professional workflows, despite limited validation in education. To address these gaps, we conduct a large-scale audit of LLM alignment with teachers' perceptions of AI by combining representative international survey data with systematic model evaluation. Using OECD TALIS data from 55 countries and territories, we measure cross-national variation in teachers' perceived benefits and risks of AI. We then benchmark responses from eight state-of-the-art LLMs across four providers under both general and country-specific prompting, comparing higher- and lower-reasoning models. Results reveal substantial cross-national variation in teacher perceptions that is not reliably reflected in LLM outputs. Models compress country differences, overestimate both benefits and risks, and show limited gains from identity prompting or enhanced reasoning. This misalignment matters because LLM-generated guidance and professional discourse increasingly shape how teachers learn about and discuss AI, potentially influencing trust and future adoption decisions. Our findings caution against treating LLM outputs as substitutes for direct engagement with teachers when informing global AI-in-education initiatives. At the same time, some models (e.g., Gemini 3 Fast) partially capture cross-national ranking patterns, suggesting a complementary role in hypothesis generation and exploratory comparative analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits LLM alignment with teachers' perceptions of AI benefits and risks by combining OECD TALIS survey data from 55 countries/territories with systematic evaluations of eight state-of-the-art LLMs. It reports substantial cross-national variation in teacher perceptions that LLMs fail to capture reliably: models compress country differences, overestimate both benefits and risks, and exhibit only limited improvements under country-specific identity prompting or enhanced reasoning. The work concludes that LLM outputs should not substitute for direct teacher engagement in global AI-in-education initiatives, while noting partial capture of ranking patterns by some models (e.g., Gemini 3 Fast).
Significance. If the empirical comparisons hold after methodological clarification, the study offers a valuable large-scale benchmark (55 countries, multiple providers and reasoning levels) that cautions against over-reliance on LLMs for cross-cultural perception modeling in education. It provides falsifiable, quantitative evidence of misalignment that can inform both theory on AI trust and practical guidelines for using LLMs in policy or professional development. The scale and direct comparison to representative survey data are strengths that distinguish it from smaller single-country studies.
major comments (2)
- [Methods] Methods section: the manuscript provides no details on statistical methods for quantifying overestimation or compression of country differences, TALIS response rates, exact prompting templates (including country-specific identity prompts), model versions, temperature settings, or how Likert-scale equivalence was established between human and LLM responses. These omissions are load-bearing for the central claim that observed misalignment is substantive rather than methodological.
- [Results] Results and Discussion: the claims of limited gains from identity prompting and enhanced reasoning, and of scale compression, rest on the unvalidated assumption that LLM outputs can be directly compared to TALIS Likert items as alignment proxies. Without reported checks for prompt artifacts, response anchoring, or cultural response-style controls, the reported patterns could arise from how LLMs interpret survey-style prompts rather than gaps in model knowledge.
minor comments (2)
- [Abstract] Abstract: the distinction between 'higher- and lower-reasoning models' is stated but not defined; the main text should explicitly list which models belong to each category and the criteria used.
- [Methods] The paper would benefit from a table summarizing the eight LLMs, their providers, and the four prompting conditions to improve readability of the experimental design.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has helped us strengthen the methodological transparency and robustness of our claims. We have revised the manuscript to address both major comments and provide the requested details and validations. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript provides no details on statistical methods for quantifying overestimation or compression of country differences, TALIS response rates, exact prompting templates (including country-specific identity prompts), model versions, temperature settings, or how Likert-scale equivalence was established between human and LLM responses. These omissions are load-bearing for the central claim that observed misalignment is substantive rather than methodological.
Authors: We agree these details are essential. In the revised manuscript we have expanded the Methods section with a new subsection on 'Quantification of Misalignment and Prompting Protocol.' This now specifies: (1) statistical methods, including mean absolute differences and Cohen's d for overestimation, and country-level variance ratios plus range compression metrics for cross-national differences; (2) TALIS response rates, drawn from the official OECD documentation (overall participation >75% in 52 of 55 entities, with country-specific figures now tabulated in Appendix A); (3) verbatim prompting templates, including the exact country-identity phrasing (e.g., 'You are a teacher in [Country] responding to the following survey...'), provided in full in Appendix B; (4) model versions (GPT-4o-2024-08, Claude-3.5-Sonnet-20240620, Gemini-1.5-Pro, etc.) and temperature settings (0.0 for all deterministic runs, 0.7 for exploratory checks); and (5) Likert equivalence, achieved by instructing models to output integer scores on the identical 1-5 scale with the same verbal anchors used in TALIS. These additions directly substantiate that the reported misalignment is not an artifact of omitted protocol details. revision: yes
-
Referee: [Results] Results and Discussion: the claims of limited gains from identity prompting and enhanced reasoning, and of scale compression, rest on the unvalidated assumption that LLM outputs can be directly compared to TALIS Likert items as alignment proxies. Without reported checks for prompt artifacts, response anchoring, or cultural response-style controls, the reported patterns could arise from how LLMs interpret survey-style prompts rather than gaps in model knowledge.
Authors: We acknowledge the need for explicit validation of the proxy assumption. The original manuscript already contained robustness tests across prompt variations, but we have now added a dedicated 'Validation of Survey-Style Prompting' paragraph in Results. This reports: (a) re-runs with three alternative phrasings (neutral, role-play, and forced-choice) showing stable overestimation and compression patterns (correlation of country rankings >0.85 across phrasings); (b) checks for anchoring by comparing mean responses under different scale instructions; and (c) discussion of cultural response-style limitations, noting that while full controls are infeasible without matched human experiments, the partial capture of known TALIS rankings by Gemini 3 Fast and the consistency across eight independent models support that the misalignment reflects knowledge gaps rather than prompt artifacts alone. We have also added this as an explicit limitation in the Discussion. The revision is partial because core robustness evidence was already present but has been expanded and foregrounded. revision: partial
Circularity Check
No circularity: empirical audit relies on external TALIS data and model outputs
full rationale
The paper performs a direct empirical comparison between representative OECD TALIS survey responses from 55 countries and LLM outputs under varied prompting conditions. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations reduce any central claim (e.g., compression of country differences or overestimation of benefits/risks) to a tautology or input-derived result. The derivation chain consists of independent data collection, prompting protocols, and statistical benchmarking that remain falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption TALIS survey responses accurately reflect teachers' genuine perceptions of AI benefits and risks
- domain assumption LLM outputs under the tested prompts can be scored for alignment against human survey distributions
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We conduct a large-scale audit of LLM alignment with teachers' perceptions of AI by combining representative international survey data with systematic model evaluation. Using OECD TALIS data from 55 countries...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Saleh Afroogh, Ali Akbari, Emmie Malone, Mohammadali Kargar, and Hananeh Alambeigi. 2024. Trust in AI: progress, challenges, and future directions.Hu- manities and Social Sciences Communications11, 1 (2024), 1–30
work page 2024
-
[2]
Guilherme FCF Almeida, José Luiz Nunes, Neele Engelmann, Alex Wiegmann, and Marcelo De Araújo. 2024. Exploring the psychology of LLMs’ moral and legal reasoning.Artificial Intelligence333 (2024), 104145
work page 2024
-
[3]
Arnav Arora, Lucie-aimée Kaffee, and Isabelle Augenstein. 2023. Probing Pre- Trained Language Models for Cross-Cultural Differences in Values. InProceedings of the First Workshop on Cross-Cultural Considerations in NLP (C3NLP), Sunipa Dev, Vinodkumar Prabhakaran, David Ifeoluwa Adelani, Dirk Hovy, and Luciana Benotti (Eds.). Association for Computational ...
-
[4]
Mohammad Atari, Mona J Xue, Peter S Park, Damián E Blasi, and Joseph Henrich
-
[5]
Which Humans? PsyArXiv. doi:10.31234/osf.io/5b26t
-
[6]
Ryan S Baker, Amy E Ogan, Michael Madaio, and Erin Walker. 2019. Culture in Computer-Based Learning Systems: Challenges and Opportunities.Computer- Based Learning in Context1, 1 (2019), 1–13
work page 2019
-
[7]
Duncan Wadsworth, and Hanna Wallach
Solon Barocas, Anhong Guo, Ece Kamar, Jacquelyn Krones, Meredith Ringel Morris, Jennifer Wortman Vaughan, W. Duncan Wadsworth, and Hanna Wallach
-
[8]
In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society
Designing Disaggregated Evaluations of AI Systems: Choices, Consider- ations, and Tradeoffs. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society(Virtual Event, USA)(AIES ’21). Association for Computing Machinery, New York, NY, USA, 368–378. doi:10.1145/3461702.3462610
-
[9]
James Calleja and Patrick Camilleri. 2025. Primary school teachers’ perceptions towards the use of generative AI in teaching using lesson study.International Journal for Lesson and Learning Studies14, 3 (2025), 237–252. doi:10.1108/IJLLS- 11-2024-0268
-
[10]
Yong Cao, Li Zhou, Seolhwa Lee, Laura Cabello, Min Chen, and Daniel Hersh- covich. 2023. Assessing Cross-Cultural Alignment between ChatGPT and Human Societies: An Empirical Study. InProceedings of the First Workshop on Cross- Cultural Considerations in NLP (C3NLP), Sunipa Dev, Vinodkumar Prabhakaran, David Ifeoluwa Adelani, Dirk Hovy, and Luciana Benotti...
-
[11]
Ismail Celik, Muhterem Dindar, Hanni Muukkonen, and Sanna Järvelä. 2022. The promises and challenges of artificial intelligence for teachers: A systematic review of research.TechTrends66, 4 (2022), 616–630. doi:10.1007/s11528-022-00715-y
-
[12]
Ismail Celik, Sini Kontkanen, Jari Laru, and Alanur Ahsen Dalyanci. 2026. Co- constructing adaptive lesson plans with GenAI: Pre-service teachers’ Intelligent- TPACK and prompt engineering strategies.Computers & Education241 (2026), 105485. doi:10.1016/j.compedu.2025.105485
-
[13]
Shu-Yang Chien, Michael Lewis, Katia Sycara, Jui-Shiang Liu, and Asli Kumru
-
[14]
ACM Transactions on Interactive Intelligent Systems8, 4 (2018), 1–31
The effect of culture on trust in automation: reliability and workload. ACM Transactions on Interactive Intelligent Systems8, 4 (2018), 1–31. doi:10.1145/ 3230736
work page 2018
-
[15]
Iris Delikoura, Yi R Fung, and Pan Hui. 2025. From superficial out- puts to superficial learning: Risks of large language models in education. arXiv:2509.21972 [cs.CY] https://doi.org/10.48550/arXiv.2509.21972
-
[16]
Haoxiang Fan, Guanzheng Chen, Xingbo Wang, and Zhenhui Peng. 2024. Lesson- Planner: Assisting Novice Teachers to Prepare Pedagogy-Driven Lesson Plans with Large Language Models. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(Pittsburgh, PA, USA)(UIST ’24). As- sociation for Computing Machinery, New York, NY, USA, ...
-
[17]
Ozan Filiz, Mehmet Haldun Kaya, and Tufan Adiguzel. 2025. Teachers and AI: Understanding the factors influencing AI integration in K-12 education.Education and Information Technologies30 (2025), 17931–17967. doi:10.1007/s10639-025- 13463-2
- [18]
-
[19]
Yuan Gao, Dokyun Lee, Gordon Burtch, and Sina Fazelpour. 2025. Take caution in using LLMs as human surrogates.Proceedings of the National Academy of Sciences122, 24 (2025), e2501660122
work page 2025
-
[20]
Olga Arranz Garcia, María del Carmen Romero García, and Vidal Alonso-Secades
-
[21]
Perceptions, strategies, and challenges of teachers in the integration of artificial intelligence in primary education: A systematic review.Journal of Information Technology Education: Research24 (2025), 006
work page 2025
-
[22]
Anastasia Gouseti, Fiona James, Lee Fallin, and Kevin Burden. 2025. The ethics of using AI in K-12 education: A systematic literature review.Technology, Pedagogy and Education34, 2 (2025), 161–182
work page 2025
-
[23]
2023.Guidance for generative AI in education and research
Wayne Holmes, Fengchun Miao, et al. 2023.Guidance for generative AI in education and research. Unesco Publishing
work page 2023
-
[24]
Wayne Holmes and Ilkka Tuomi. 2022. State of the art and practice in AI in education.European journal of education57, 4 (2022), 542–570
work page 2022
-
[25]
Jie Huang and Kevin Chen-Chuan Chang. 2023. Towards Reasoning in Large Language Models: A Survey. InFindings of the Association for Computational Linguistics: ACL 2023, Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 1049–1065. doi:10.18653/v1/2023.findings-acl.67
-
[26]
Ruiping Huang, Yue Yin, Na Zhou, and Fei Lang. 2025. Artificial intelligence in K- 12 education: An umbrella review.Computers and Education: Artificial Intelligence (2025), 100519
work page 2025
-
[27]
Ben Hutchinson, Negar Rostamzadeh, Christina Greer, Katherine Heller, and Vinodkumar Prabhakaran. 2022. Evaluation Gaps in Machine Learning Prac- tice. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency(Seoul, Republic of Korea)(FAccT ’22). Association for Computing Machinery, New York, NY, USA, 1859–1876. doi:10.1145/3...
-
[28]
Zhuoren Jiang, Biao Huang, Jianan Ge, Chenxi Lin, Yueqian Xu, and Jianxing Yu
-
[29]
Simulating social perception with large language models: perceptions of China’s common prosperity.Journal of Chinese Governance(2025), 1–29
work page 2025
-
[30]
Alexander John Karran, Patrick Charland, Joé Trempe-Martineau, Ana Ortiz de Guinea Lopez de Arana, Anne-Marie Lesage, Sylvain Senecal, and Pierre- Majorique Leger. 2025. Multi-stakeholder perspective on responsible artificial intelligence and acceptability in education.npj Science of Learning10, 1 (2025), 44
work page 2025
-
[31]
Mehdi Khamassi, Marceau Nahon, and Raja Chatila. 2024. Strong and weak alignment of large language models with human values.Scientific Reports14, 1 (2024), 19399
work page 2024
-
[32]
Ariba Khan, Stephen Casper, and Dylan Hadfield-Menell. 2025. Randomness, Not Representation: The Unreliability of Evaluating Cultural Alignment in LLMs. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Trans- parency (FAccT ’25). Association for Computing Machinery, New York, NY, USA, 2151–2165. doi:10.1145/3715275.3732147
-
[33]
Aidan Kierans and Shiri Dori-Hacohen. 2026. Position: Aligning AI requires automating reasoning norms. SSRN. doi:10.2139/ssrn.5399451 Available at SSRN
-
[34]
Juhee Kim. 2025. Perceptions and preparedness of K-12 educators in adopting generative AI.Research in Learning Technology33 (2025), 3448. doi:10.25304/rlt. v33.3448
-
[35]
René F Kizilcec. 2024. To advance AI use in education, focus on understanding educators.International Journal of Artificial Intelligence in Education34, 1 (2024), 12–19
work page 2024
-
[36]
Dorothy E. Leidner and Timothy Kayworth. 2006. A review of culture in infor- mation systems research: Toward a theory of information technology culture conflict.MIS Quarterly30, 2 (2006), 357–399. doi:10.2307/25148735
-
[37]
Zhuoran Lu, Gionnieve Lim, and Ming Yin. 2025. Understanding the Effects of Large Language Model (LLM)-driven Adversarial Social Influences in Online Information Spread. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’25). Association for Computing Machinery, New York, NY, USA, Article 555, 7 pa...
-
[38]
Sandra C Matz, Jacob D Teeny, Sumer S Vaid, Heinrich Peters, Gabriella M Harari, and Moran Cerf. 2024. The potential of generative AI for personalized persuasion at scale.Scientific Reports14, 1 (2024), 4692
work page 2024
-
[39]
Timothy R McIntosh, Tong Liu, Teo Susnjak, Paul Watters, and Malka N Hal- gamuge. 2024. A reasoning and value alignment test to assess advanced gpt reasoning.ACM Transactions on Interactive Intelligent Systems14, 3 (2024), 1–37
work page 2024
-
[40]
Tarek Naous, Michael J. Ryan, Alan Ritter, and Wei Xu. 2024. Having beer after prayer? Measuring cultural bias in large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand, 16366–16393
work page 2024
-
[41]
Tanya Nazaretsky, Moriah Ariely, Mutlu Cukurova, and Giora Alexandron. 2022. Teachers’ trust in AI-powered educational technology and a professional devel- opment program to improve it.British journal of educational technology53, 4 (2022), 914–931
work page 2022
-
[42]
OECD. 2024. . Technical Report. OECD Publishing, Paris. https://www.oecd. org/en/publications/results-from-talis-2024_90df6235-en/full-report
work page 2024
-
[43]
2025.Teaching and Learning International Survey (TALIS) 2024 Conceptual Framework
OECD. 2025.Teaching and Learning International Survey (TALIS) 2024 Conceptual Framework. Technical Report. OECD Publishing, Paris. doi:10.1787/7b8f85d4-en
-
[44]
OpenAI. 2024. Learning to Reason with LLMs. https://openai.com/index/learning- to-reason-with-llms/. Accessed: 2026-02-12
work page 2024
- [45]
-
[46]
Data and Discrimination: Converting Critical Concerns into Productive Inquiry,
Christian Sandvig, Kevin Hamilton, Karrie Karahalios, and Cedric Langbort. 2014. Auditing algorithms: research methods for detecting discrimination on internet platforms. (May 2014). Paper presented at "Data and Discrimination: Converting Critical Concerns into Productive Inquiry, " preconference at the 64th Annual Meeting of the International Communicati...
work page 2014
-
[47]
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. 2023. Whose opinions do language models reflect?. In Proceedings of the 40th International Conference on Machine Learning(Honolulu, Hawaii, USA)(ICML’23). JMLR.org, Article 1244, 34 pages
work page 2023
-
[48]
Agrima Seth, Monojit Choudhury, Sunayana Sitaram, Kentaro Toyama, Aditya Vashistha, and Kalika Bali. 2025. How deep is representational bias in llms? the cases of caste and religion.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society8, 3 (2025), 2319–2330
work page 2025
-
[49]
Lijuan Shen, Nengsheng Qiu, and Zhanfeng Wang. 2025. Psychological safety and trust as drivers of teachers’ continued use of AI tools in classrooms.Scientific Reports15, 1 (2025), 31426
work page 2025
-
[50]
Rana Taheri, Neda Nazemi, Sarah E Pennington, Jason A Clark, and Faraz Dad- gostari. 2025. Factors Influencing Educators’ AI Adoption: A Grounded Meta- Analysis Review.Computers and Education: Artificial Intelligence(2025), 100464. doi:10.1080/23812346.2025.2603822
-
[51]
Xiao Tan, Gary Cheng, and Man Ho Ling. 2025. Artificial intelligence in teaching and teacher professional development: A systematic review.Computers and L@S ’26, June 29-July 03, 2026, Seoul, Republic of Korea Yan Tao, Olga Viberg, Deepak Varuvel Dennison, Zhikun Wu, René F. Kizilcec Education: Artificial Intelligence8 (2025), 100355
work page 2025
-
[52]
Yan Tao, Olga Viberg, Ryan S. Baker, and René F. Kizilcec. 2024. Cultural bias and cultural alignment of large language models.PNAS Nexus3, 9 (2024), pgae346. doi:10.1093/pnasnexus/pgae346
-
[53]
Tarang Tripathi, Smriti R Sharma, Vatsala Singh, Palaash Bhargava, and Chan- draditya Raj. 2025. Teaching and learning with AI: a qualitative study on K-12 teachers’ use and engagement with artificial intelligence. InFrontiers in Education, Vol. 10. Frontiers, 1651217
work page 2025
-
[54]
Johanna Velander, M. A. Taiye, N. Otero, and Marcelo Milrad. 2024. Artificial intelligence in K-12 education: eliciting and reflecting on Swedish teachers’ understanding of AI and its implications for teaching & learning.Education and Information Technologies29 (2024), 4085–4105. doi:10.1007/s10639-023-11990-4
-
[55]
Olga Viberg, Mutlu Cukurova, Yael Feldman-Maggor, Giora Alexandron, Shizuka Shirai, Susumu Kanemune, Barbara Wasson, Cathrine Tømte, Daniel Spikol, Marcelo Milrad, Raquel Coelho, and René F. Kizilcec. 2025. What Explains Teachers’ Trust of AI in Education across Six Countries?International Journal of Artificial Intelligence in Education35, 3 (2025), 1288–1316
work page 2025
-
[56]
Angelina Wang, Jamie Morgenstern, and John P Dickerson. 2025. Large language models that replace human participants can harmfully misportray and flatten identity groups.Nature Machine Intelligence7 (2025), 400–411. doi:10.1038/s42256- 025-00986-z
-
[57]
Rose Wang and Dorottya Demszky. 2023. Is ChatGPT a Good Teacher Coach? Measuring Zero-Shot Performance For Scoring and Providing Actionable Insights on Classroom Instruction. InProceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), Ekaterina Kochmar, Jill Burstein, Andrea Horbach, Ronja Laarmann-Quante,...
-
[58]
Jing Yao, Xiaoyuan Yi, Yifan Gong, Xiting Wang, and Xing Xie. 2024. Value FULCRA: Mapping Large Language Models to the Multidimensional Spectrum of Basic Human Value. InProceedings of the 2024 Conference of the North Ameri- can Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Kevin Duh, Helena ...
-
[59]
Yaxuan Yin, Shamya Karumbaiah, and Shona Acquaye. 2025. Responsible AI in Education: Understanding Teachers’ Priorities and Contextual Challenges. In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Trans- parency (FAccT ’25). Association for Computing Machinery, New York, NY, USA, 2705–2727. doi:10.1145/3715275.3732176
-
[60]
Marín, Melissa Bond, and Franziska Gouverneur
Olaf Zawacki-Richter, Victoria I. Marín, Melissa Bond, and Franziska Gouverneur
-
[61]
Systematic review of research on artificial intelligence applications in higher education,
Systematic review of research on artificial intelligence applications in higher education—where are the educators?International Journal of Educational Technology in Higher Education16, 1 (2019), 1–27. doi:10.1186/s41239-019-0171-0
-
[62]
Self-discover: Large language models self-compose reasoning structures
Pei Zhou, Jay Pujara, Xiang Ren, Xinyun Chen, Heng-Tze Cheng, Quoc V. Le, Ed H. Chi, Denny Zhou, Swaroop Mishra, and Huaixiu Steven Zheng. 2024. Self-Discover: Large Language Models Self-Compose Reasoning Structures. arXiv:2402.03620 [cs.AI] https://arxiv.org/abs/2402.03620
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.