Recognition: 2 theorem links
· Lean TheoremCapCLIP: A Vision-Language Representation Alignment Approach for Wireless Capsule Endoscopy Analysis
Pith reviewed 2026-05-12 01:35 UTC · model grok-4.3
The pith
Aligning WCE images with clinical text descriptions yields transferable embeddings for zero-shot tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
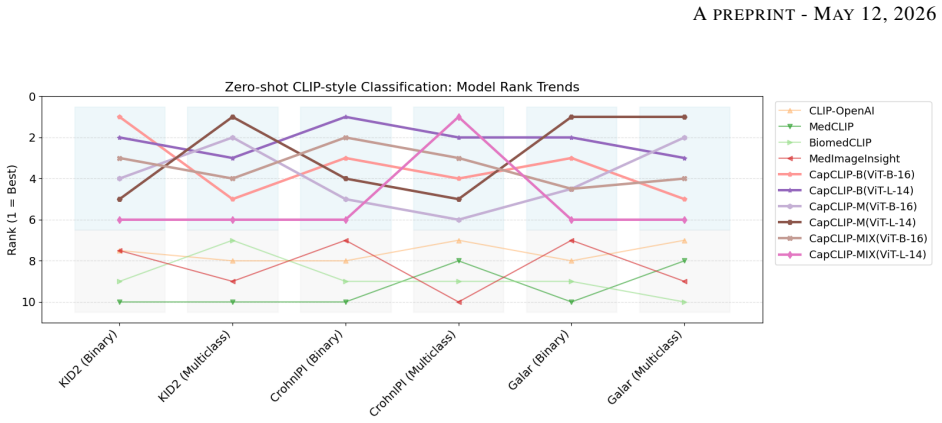
CapCLIP aligns capsule endoscopy frames with clinically grounded textual descriptions derived from standardised nomenclature and pathology-aware caption templates to learn embeddings that are semantically informed and transferable. Under strict zero-shot evaluation on unseen datasets, the method outperforms relevant vision and vision-language baselines in nearest-neighbour classification, image-text classification, and text-to-image retrieval tasks. The gains are especially notable in out-of-distribution settings, suggesting that language guidance enhances generalisation and interpretability for analysing subtle abnormalities in variable imaging conditions.
What carries the argument
The vision-language alignment process using pathology-aware caption templates that connect visual features of WCE frames to standardised medical descriptions.
If this is right
- Improved accuracy in identifying abnormalities without task-specific training on new data.
- Enhanced ability to retrieve relevant textual explanations for given images across different centres.
- Greater semantic interpretability of the model's decisions in clinical settings.
- Foundation for developing more robust models tailored to capsule endoscopy examinations.
Where Pith is reading between the lines
- Integrating this approach with real-time frame analysis could reduce the time doctors spend reviewing long video sequences.
- Similar text-alignment techniques might apply to other medical imaging modalities facing data variability issues.
- Testing on images with rare pathologies not covered in the caption templates would reveal the limits of the current descriptions.
Load-bearing premise
The textual descriptions based on standardised nomenclature accurately represent the visual content of the images and produce representations that remain effective across different datasets and imaging centres.
What would settle it
Performance on a new WCE dataset where independent clinical annotations show that the generated captions frequently mismatch the actual image content, resulting in no advantage over purely visual models in zero-shot tasks.
Figures











read the original abstract
Wireless capsule endoscopy (WCE) enables non-invasive visual assessment of the small bowel, but its clinical utility is constrained by the large volume of frames generated per examination and the difficulty of recognising subtle abnormalities under highly variable imaging conditions. Existing learning-based approaches for WCE are predominantly vision-only, often confined to narrow pathology sets, and show limited transfer across datasets and centres. To address these limitations, this study introduces CapCLIP, a domain-specific vision-language representation learning framework for WCE. CapCLIP aligns capsule endoscopy frames with clinically grounded textual descriptions derived from standardised nomenclature and pathology-aware caption templates, thereby learning embeddings that are both semantically informed and transferable. The proposed framework is evaluated against relevant open-source vision and vision-language foundation models under strict zero-shot conditions using unseen WCE datasets. Evaluation covers three downstream tasks: K-nearest neighbour classification, CLIP-style image-text classification, and text-to-image retrieval. Across these settings, CapCLIP consistently outperforms the compared baselines, with particularly strong gains in zero-shot image-text classification and cross-modal retrieval on out-of-distribution datasets. The results indicate that language-guided representation learning can improve both generalisation and semantic interpretability in WCE analysis. These findings position CapCLIP as a step toward foundation models tailored to capsule endoscopy and support the use of language-grounded WCE analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CapCLIP, a domain-specific vision-language model for wireless capsule endoscopy (WCE) that performs contrastive alignment between image frames and clinically grounded textual descriptions generated via standardized nomenclature and pathology-aware caption templates. It evaluates the resulting embeddings under strict zero-shot conditions on three downstream tasks—k-nearest-neighbor classification, CLIP-style image-text classification, and text-to-image retrieval—using previously unseen WCE datasets, claiming consistent outperformance over open-source vision and vision-language baselines with particularly large gains on out-of-distribution data.
Significance. If the empirical claims hold after addressing the validation gaps, the work would provide evidence that language-guided pretraining can improve generalization and semantic interpretability for WCE analysis, a setting where frame volume and imaging variability make purely vision-based approaches brittle. It would constitute a concrete step toward foundation models tailored to capsule endoscopy and support broader adoption of clinically grounded text supervision in medical imaging.
major comments (2)
- [§3.2] §3.2 (Caption Generation): The central claim that CapCLIP yields transferable embeddings on out-of-distribution datasets rests on the assumption that the pathology-aware caption templates accurately reflect image content. No quantitative validation is reported (e.g., caption accuracy against expert annotations, inter-annotator agreement, or ablation replacing templates with free-text captions), leaving open the possibility that systematic mismatches in the templates undermine the reported zero-shot gains.
- [§4.3] §4.3 (Zero-shot Evaluation Protocol): The abstract and experimental sections assert strict zero-shot conditions on unseen datasets, yet the manuscript does not specify whether any form of dataset leakage (e.g., via shared patient cohorts, similar imaging hardware, or pre-training data overlap) was audited. This detail is load-bearing for the generalization claim.
minor comments (2)
- [Table 2] Table 2: The reported standard deviations for the image-text classification task are omitted for several baselines; adding them would allow readers to assess whether the claimed gains are statistically distinguishable.
- [§4.1] §4.1: The description of the three evaluation datasets would benefit from explicit mention of the number of centers, acquisition devices, and pathology prevalence to contextualize the out-of-distribution claim.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Caption Generation): The central claim that CapCLIP yields transferable embeddings on out-of-distribution datasets rests on the assumption that the pathology-aware caption templates accurately reflect image content. No quantitative validation is reported (e.g., caption accuracy against expert annotations, inter-annotator agreement, or ablation replacing templates with free-text captions), leaving open the possibility that systematic mismatches in the templates undermine the reported zero-shot gains.
Authors: We agree that quantitative validation of the caption templates would strengthen the work. The templates were constructed from standardized WCE nomenclature in consultation with clinical experts, but the manuscript does not include accuracy metrics or inter-annotator agreement. In the revised manuscript we will add (i) caption accuracy measured against expert annotations on a held-out subset and (ii) an ablation that replaces the templates with free-text expert captions, thereby quantifying any systematic mismatches and their effect on downstream zero-shot performance. revision: yes
-
Referee: [§4.3] §4.3 (Zero-shot Evaluation Protocol): The abstract and experimental sections assert strict zero-shot conditions on unseen datasets, yet the manuscript does not specify whether any form of dataset leakage (e.g., via shared patient cohorts, similar imaging hardware, or pre-training data overlap) was audited. This detail is load-bearing for the generalization claim.
Authors: We concur that explicit documentation of leakage controls is essential. The pre-training and evaluation datasets originate from distinct public collections that differ in patient populations, acquisition centers, and hardware. In the revised manuscript we will insert a dedicated subsection under the experimental protocol that details the leakage-audit steps performed, including verification of no patient overlap and hardware dissimilarity between the pre-training corpus and each zero-shot test set. revision: yes
Circularity Check
No circularity; standard contrastive alignment applied to domain data without self-referential reductions.
full rationale
The paper introduces CapCLIP as a vision-language framework aligning WCE frames with clinically grounded textual descriptions from standardised nomenclature and pathology-aware caption templates. It evaluates this on zero-shot KNN classification, image-text classification, and text-to-image retrieval using unseen out-of-distribution datasets, reporting outperformance over baselines. No equations, derivations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed result to its inputs by construction. The method follows established CLIP-style contrastive learning without introducing self-definitional loops, uniqueness theorems from prior self-work, or renaming of known patterns as novel derivations. The central assumption regarding template fidelity is an empirical claim subject to external validation rather than a circular definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive alignment between image and text embeddings produces semantically meaningful and transferable representations
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CapCLIP aligns capsule endoscopy frames with clinically grounded textual descriptions ... using symmetric cross entropy loss ... LCLIP = 1/2 (Li→t + Lt→i)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
zero-shot image-text classification and cross-modal retrieval on out-of-distribution datasets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
G. Iddan, G. Meron, A. Glukhovsky, and P. Swain, “Wireless capsule endoscopy,”Nature, vol. 405, no. 6785, p. 417, May 2000
work page 2000
-
[2]
Machine learning based small bowel video capsule endoscopy analysis: Challenges and opportunities,
H. Wahab, I. Mehmood, H. Ugail, A. K. Sangaiah, and K. Muhammad, “Machine learning based small bowel video capsule endoscopy analysis: Challenges and opportunities,”Future Generation Computer Systems, vol. 143, pp. 191–214, 2023
work page 2023
-
[3]
Cross-modal discrete representation learning,
A. Liu, S. Jin, C.-I. Lai, A. Rouditchenko, A. Oliva, and J. Glass, “Cross-modal discrete representation learning,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2022, pp. 3013–3035
work page 2022
-
[4]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[5]
E. M. El-Gammal, W. El-Shafai, T. E. Taha, A. S. El-Fishawy, and F. E. Abd El-Samie, “A survey of artificial intelligence models for wireless capsule endoscopy videos for superior automatic diagnosis: problems and solutions,”Multimedia Tools and Applications, vol. 84, no. 33, pp. 40 555–40 589, Mar. 2025
work page 2025
-
[6]
Detection of small bowel polyps and ulcers in wireless capsule endoscopy videos,
A. Karargyris and N. Bourbakis, “Detection of small bowel polyps and ulcers in wireless capsule endoscopy videos,”IEEE Transactions on Biomedical Engineering, vol. 58, no. 10, pp. 2777–2786, 2011
work page 2011
-
[7]
B. Li and M. Q.-H. Meng, “Tumor recognition in wireless capsule endoscopy images using textural features and svm-based feature selection,”IEEE Transactions on Information Technology in Biomedicine, vol. 16, no. 3, pp. 323–329, May 2012
work page 2012
-
[8]
H. Wahab, R. Goel, M. Alamgir, I. Mehmood, K. Muhammad, and H. Ugail, “Towards holistic analysis of wireless capsule endoscopic videos: A taxonomy-driven machine learning framework for clinically comprehensive wce frame level analysis,” in2024 4th Interdisciplinary Conference on Electrics and Computer (INTCEC), 2024, pp. 1–8
work page 2024
-
[9]
H. Wahab, I. Mehmood, H. Ugail, J. Del Ser, and K. Muhammad, “Federated deep learning for wireless capsule endoscopy analysis: Enabling collaboration across multiple data centres for robust learning of diverse pathologies,” Future Generation Computer Systems, vol. 152, pp. 361–371, 2024
work page 2024
-
[10]
Visual genome: Connecting language and vision using crowdsourced dense image annotations,
R. Krishna, Y . Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y . Kalantidis, L.-J. Li, D. A. Shamma, M. S. Bernstein, and L. Fei-Fei, “Visual genome: Connecting language and vision using crowdsourced dense image annotations,”International Journal of Computer Vision, vol. 123, no. 1, pp. 32–73, Feb. 2017
work page 2017
-
[11]
Self-supervised learning for endoscopic video analysis,
R. Hirsch, M. Caron, R. Cohen, A. Livne, R. Shapiro, T. Golany, R. Goldenberg, D. Freedman, and E. Rivlin, “Self-supervised learning for endoscopic video analysis,” inMedical Image Computing and Computer Assisted Intervention – MICCAI 2023: 26th International Conference, V ancouver , BC, Canada, October 8–12, 2023, Proceedings, Part V. Berlin, Heidelberg:...
-
[12]
Foundation model for endoscopy video analysis via large-scale self- supervised pre-train,
Z. Wang, C. Liu, S. Zhang, and Q. Dou, “Foundation model for endoscopy video analysis via large-scale self- supervised pre-train,” inInternational conference on medical image computing and computer-assisted intervention. Springer, 2023, pp. 101–111
work page 2023
-
[13]
Z. Wang, C. Liu, L. Zhu, T. Wang, S. Zhang, and Q. Dou, “Improving foundation model for endoscopy video analysis via representation learning on long sequences,”IEEE Journal of Biomedical and Health Informatics, vol. 29, no. 5, pp. 3526–3536, 2025
work page 2025
-
[14]
Contrastive learning of medical visual representations from paired images and text,
Y . Zhang, H. Jiang, Y . Miura, C. D. Manning, and C. P. Langlotz, “Contrastive learning of medical visual representations from paired images and text,” inMachine learning for healthcare conference. PMLR, 2022, pp. 2–25
work page 2022
-
[15]
S.-C. Huang, L. Shen, M. P. Lungren, and S. Yeung, “Gloria: A multimodal global-local representation learn- ing framework for label-efficient medical image recognition,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3942–3951
work page 2021
-
[16]
Medclip: Contrastive learning from unpaired medical images and text,
Z. Wang, Z. Wu, D. Agarwal, and J. Sun, “Medclip: Contrastive learning from unpaired medical images and text,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022, pp. 3876–3887
work page 2022
-
[17]
S. Zhang, Y . Xu, N. Usuyama, H. Xu, J. Bagga, R. Tinn, S. Preston, R. Rao, M. Wei, N. Valluriet al., “Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs,”arXiv preprint arXiv:2303.00915, 2023. 30 APREPRINT- MAY12, 2026
work page internal anchor Pith review arXiv 2023
-
[18]
Med-flamingo: a multimodal medical few-shot learner,
M. Moor, Q. Huang, S. Wu, M. Yasunaga, Y . Dalmia, J. Leskovec, C. Zakka, E. P. Reis, and P. Rajpurkar, “Med-flamingo: a multimodal medical few-shot learner,” inProceedings of the 3rd Machine Learning for Health Symposium, ser. Proceedings of Machine Learning Research, S. Hegselmann, A. Parziale, D. Shanmugam, S. Tang, M. N. Asiedu, S. Chang, T. Hartvigse...
work page 2023
-
[19]
Skingpt-4: an interactive dermatology diagnostic system with visual large language model,
J. Zhou, X. He, L. Sun, J. Xu, X. Chen, Y . Chu, L. Zhou, X. Liao, B. Zhang, and X. Gao, “Skingpt-4: an interactive dermatology diagnostic system with visual large language model,”arXiv preprint arXiv:2304.10691, 2023
-
[20]
A foundational multimodal vision language ai assistant for human pathology,
M. Y . Lu, B. Chen, D. F. Williamson, R. J. Chen, K. Ikamura, G. Gerber, I. Liang, L. P. Le, T. Ding, A. V . Parwaniet al., “A foundational multimodal vision language ai assistant for human pathology,”arXiv preprint arXiv:2312.07814, 2023
-
[21]
Eyeclip: A visual-language foundation model for multi-modal ophthalmic image analysis,
D. Shi, W. Zhang, J. Yang, S. Huang, X. Chen, M. Yusufu, K. Jin, S. Lin, S. Liu, Q. Zhanget al., “Eyeclip: A visual-language foundation model for multi-modal ophthalmic image analysis,”arXiv preprint arXiv:2409.06644, 2024
-
[22]
Medimageinsight: An open-source embedding model for general domain medical imaging,
N. C. Codella, Y . Jin, S. Jain, Y . Gu, H. H. Lee, A. B. Abacha, A. Santamaria-Pang, W. Guyman, N. Sangani, S. Zhanget al., “Medimageinsight: An open-source embedding model for general domain medical imaging,” arXiv preprint arXiv:2410.06542, 2024
-
[23]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[24]
Neural machine translation of rare words with subword units,
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” in Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers), 2016, pp. 1715–1725
work page 2016
-
[25]
Meta-prompting for automating zero-shot visual recognition with llms,
M. J. Mirza, L. Karlinsky, W. Lin, S. Doveh, J. Micorek, M. Kozinski, H. Kuehne, and H. Possegger, “Meta-prompting for automating zero-shot visual recognition with llms,” inComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part II. Berlin, Heidelberg: Springer-Verlag, 2024, p. 370–387. [Online]...
-
[26]
R. Leenhardt, C. Li, A. Koulaouzidis, F. Cavallaro, F. Cholet, R. Eliakim, I. Fernandez-Urien, U. Kopylov, M. McAlindon, A. Németh, J. N. Plevris, G. Rahmi, E. Rondonotti, J.-C. Saurin, G. E. Tontini, E. Toth, D. Yung, P. Marteau, and X. Dray, “Nomenclature and semantic description of vascular lesions in small bowel capsule endoscopy: an international del...
work page 2019
-
[27]
R. Leenhardt, A. Buisson, A. Bourreille, P. Marteau, A. Koulaouzidis, C. Li, M. Keuchel, E. Rondonotti, E. Toth, J. N. Plevris, R. Eliakim, B. Rosa, K. Triantafyllou, L. Elli, G. Wurm Johansson, S. Panter, P. Ellul, E. Pérez- Cuadrado Robles, D. McNamara, H. Beaumont, C. Spada, F. Cavallaro, F. Cholet, I. Fernandez-Urien Sainz, U. Kopylov, M. E. McAlindon...
work page 2020
-
[28]
Large language models for data annotation and synthesis: A survey,
Z. Tan, D. Li, S. Wang, A. Beigi, B. Jiang, A. Bhattacharjee, M. Karami, J. Li, L. Cheng, and H. Liu, “Large language models for data annotation and synthesis: A survey,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 930–957
work page 2024
-
[29]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inProceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol. 119. PMLR, 13–18 Jul 2020, pp. 1597–1607. [Online]. Available: https://proceedin...
work page 2020
-
[30]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660
work page 2021
-
[31]
Online zero-shot classification with clip,
Q. Qian and J. Hu, “Online zero-shot classification with clip,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 462–477
work page 2024
-
[32]
L. van der Maaten and G. Hinton, “Visualizing data using t-sne,”Journal of Machine Learning Research, vol. 9, no. 86, pp. 2579–2605, 2008. [Online]. Available: http://jmlr.org/papers/v9/vandermaaten08a.html 31
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.