Recognition: 2 theorem links
· Lean TheoremA Single Layer to Explain Them All:Understanding Massive Activations in Large Language Models
Pith reviewed 2026-05-12 02:25 UTC · model grok-4.3
The pith
Massive activations in large language models first emerge in one consistent layer and then propagate through residual connections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
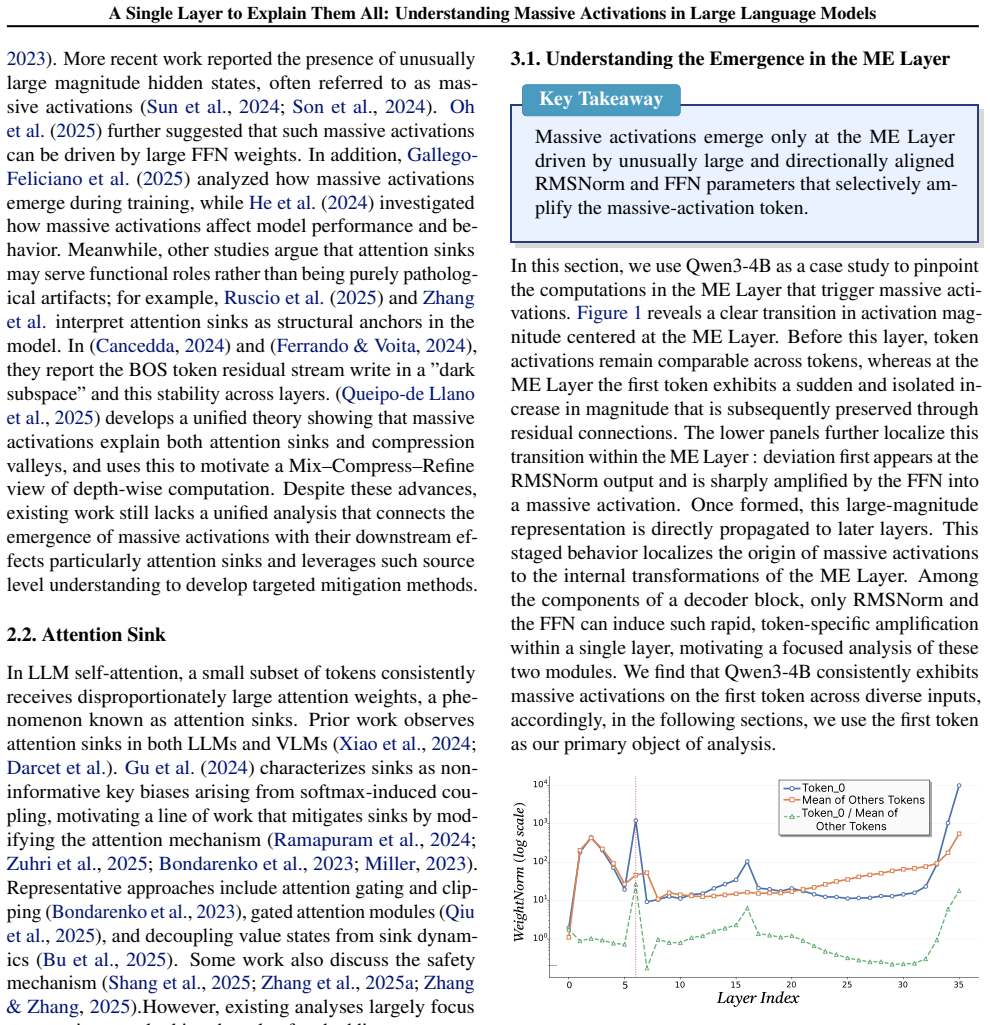
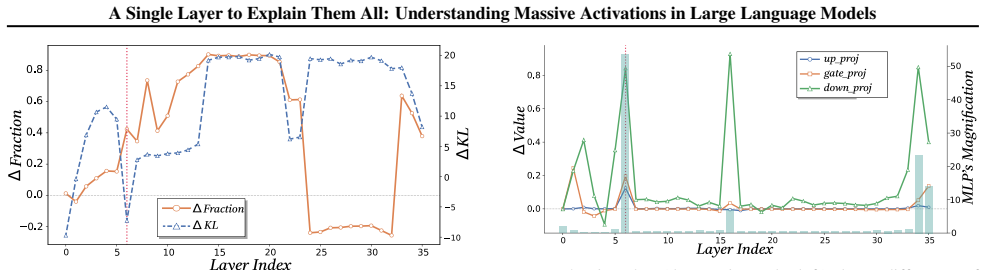
The authors establish that massive activations arise at a single identifiable layer, the ME Layer, where RMSNorm and FFN parameters together produce them, after which the activation token stays largely unchanged across subsequent layers via residual connections and thereby limits representation diversity for attention.
What carries the argument
The Massive Emergence Layer (ME Layer), the specific layer where massive activations first form due to RMSNorm and FFN and then propagate invariantly through residuals.
If this is right
- Massive activation tokens remain largely invariant across deeper layers after the ME Layer.
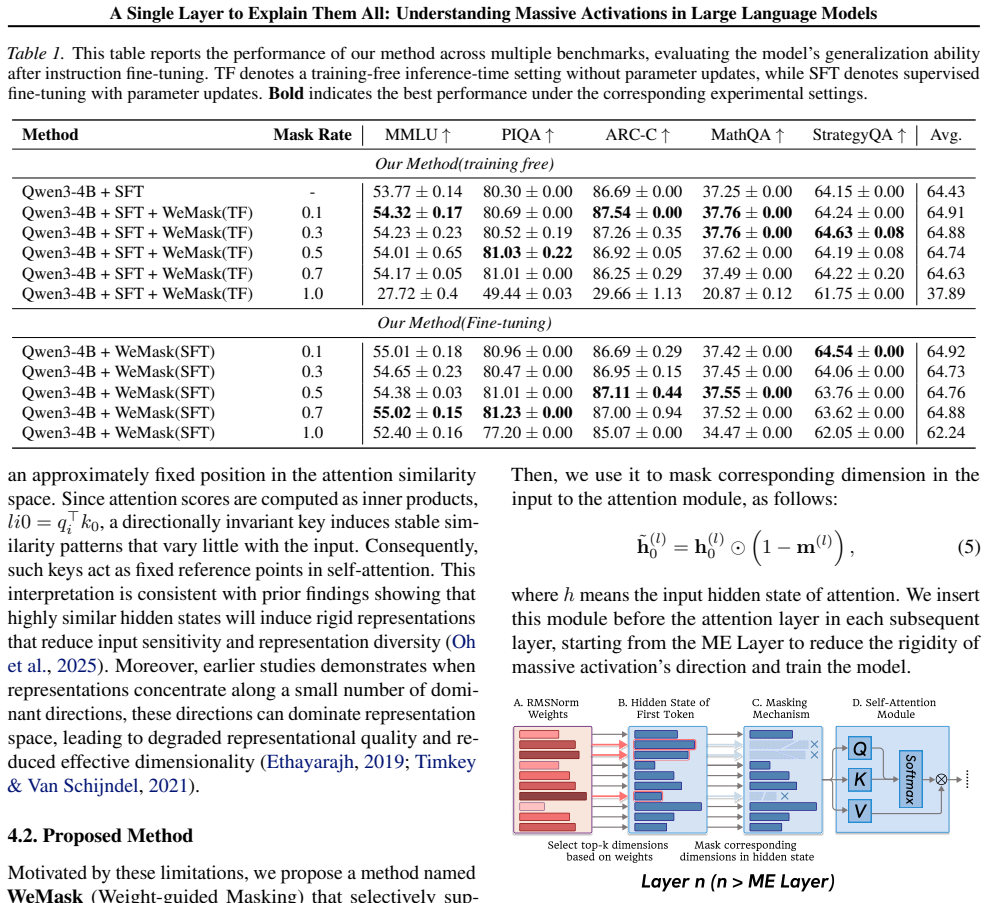
- Reducing the rigidity of the massive activation token improves performance on instruction following and math reasoning.
- The improvement occurs in both training-free and fine-tuning settings.
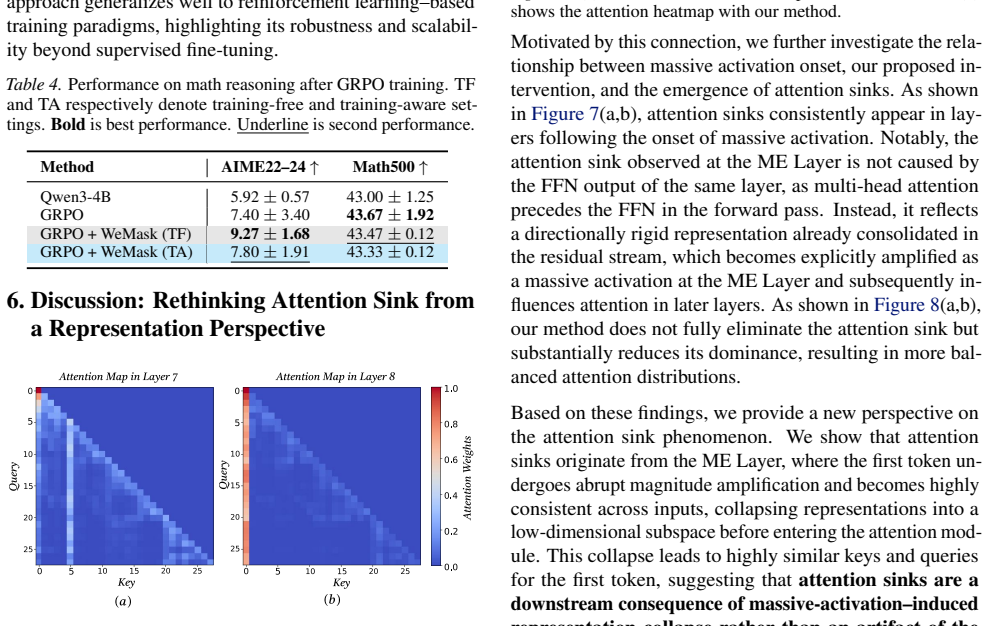
- The method also mitigates attention sinks by selectively weakening their influence at the hidden-state level.
Where Pith is reading between the lines
- Intervening only at the ME Layer could offer a more targeted way to handle attention sinks than direct changes to attention weights.
- The joint role of RMSNorm and FFN at one layer suggests that similar single-layer origins might be found for other activation anomalies if the same post-hoc tracing approach is applied.
- Architectures that avoid strong residual propagation of early dominant tokens might prevent the rigidity problem from arising in the first place.
Load-bearing premise
The layer identified after the fact as the first site of massive activations is their actual root cause in typical models, and making the massive activation token less rigid will raise performance on downstream tasks without harming other model abilities.
What would settle it
An experiment that applies the rigidity-reduction method only at the identified ME Layer and measures whether massive activations disappear in all deeper layers while performance gains appear on the target tasks but not when the same method is applied at other layers instead.
Figures















read the original abstract
We investigate the origins of massive activations in large language models (LLMs) and identify a specific layer named the \textbf{Massive Emergence Layer (ME Layer)}, that is consistently observed across model families, where massive activations first emerge and subsequently propagate to deeper layers through residual connections. We show that, within the ME Layer both the RMSNorm and the FFN parameters jointly contribute to the emergence of massive activations. Once formed, the massive activation token representation remains largely invariant across layers, reducing the diversity of hidden representations passed to the attention module. Motivated by this limitation, we propose a simple and effective method to reduce the rigidity of the massive activation token. Our approach consistently improves LLM performance across multiple tasks, including instruction following and math reasoning, in both training free and fine tuning settings. Moreover, we show that our method mitigates attention sinks by selectively weakening their influence, elucidating their origin at the hidden state level and shedding new light on principled mitigation strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify a consistent 'Massive Emergence Layer' (ME Layer) across LLM families as the point where massive activations first originate due to joint RMSNorm and FFN effects, propagate invariantly via residuals (reducing hidden-state diversity), and proposes a simple intervention to reduce the rigidity of these tokens. This intervention is reported to improve performance on instruction following and math reasoning in both training-free and fine-tuning settings while also mitigating attention sinks.
Significance. If the ME Layer identification and causal attribution hold, the work would offer a mechanistic account of activation magnitude patterns and attention sinks at the hidden-state level, along with a lightweight, architecture-aligned mitigation strategy that generalizes across model families and training regimes. The empirical consistency across families and the dual training-free/fine-tuning gains would be notable strengths.
major comments (3)
- [Abstract and §3 (ME Layer identification)] The central claim that the ME Layer is the causal origin of massive activations (rather than the first layer where a chosen magnitude threshold is crossed) rests on post-hoc observation without targeted layer-specific interventions. No ablation is described that modifies only the ME Layer's RMSNorm scale or FFN weights while freezing all other layers and verifies suppression of massive activations downstream; residual propagation alone does not establish origin.
- [Abstract and §4 (component analysis)] The joint contribution of RMSNorm and FFN parameters within the ME Layer is asserted but lacks the necessary controlled experiments. A full-factorial ablation (RMSNorm-only, FFN-only, both, neither) at the identified layer, with downstream activation norms measured, is required to move from correlation to attribution; current evidence appears observational.
- [Abstract and §5 (experiments)] Performance improvements and attention-sink mitigation are reported without sufficient experimental detail: no mention of statistical tests, number of runs, exact data splits, or comparison against strong baselines that also target token rigidity or attention. The risk that gains arise from generic regularization rather than the ME-Layer hypothesis cannot be assessed from the current description.
minor comments (3)
- [§3] The precise numerical criterion used to label an activation 'massive' (e.g., norm threshold relative to other tokens or layers) should be stated explicitly and held constant across all models and figures.
- [§4] Notation for the proposed rigidity-reduction method (scaling factor, which parameters are adjusted, whether it is applied only at the ME Layer) is unclear from the abstract and should be formalized with an equation or pseudocode.
- [Figures 2-4] Figure captions and axis labels for activation-norm plots should include the exact threshold used and the model/layer indices to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key opportunities to strengthen the causal evidence for the ME Layer and enhance the transparency of our experimental results. We address each major comment in detail below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §3 (ME Layer identification)] The central claim that the ME Layer is the causal origin of massive activations (rather than the first layer where a chosen magnitude threshold is crossed) rests on post-hoc observation without targeted layer-specific interventions. No ablation is described that modifies only the ME Layer's RMSNorm scale or FFN weights while freezing all other layers and verifies suppression of massive activations downstream; residual propagation alone does not establish origin.
Authors: We agree that establishing the ME Layer as the causal origin requires more than consistent observational patterns across models. Our current evidence centers on the layer being the first where massive activations reliably appear due to the interaction of RMSNorm and FFN, followed by invariant propagation through residuals that reduces hidden-state diversity. We acknowledge that this does not fully rule out threshold-based emergence at other layers. In revision, we will add a targeted intervention: we will selectively modify RMSNorm scale and FFN weights only within the identified ME Layer (freezing all other layers) and measure whether massive activations are suppressed in downstream layers. revision: yes
-
Referee: [Abstract and §4 (component analysis)] The joint contribution of RMSNorm and FFN parameters within the ME Layer is asserted but lacks the necessary controlled experiments. A full-factorial ablation (RMSNorm-only, FFN-only, both, neither) at the identified layer, with downstream activation norms measured, is required to move from correlation to attribution; current evidence appears observational.
Authors: We recognize that our component analysis, while showing joint effects through targeted examination of RMSNorm and FFN within the ME Layer, remains observational without a complete factorial design. To move toward stronger attribution, the revised manuscript will include the full-factorial ablation (RMSNorm-only, FFN-only, both, and neither) performed specifically at the ME Layer, with quantitative reporting of downstream activation norms to isolate the joint contribution. revision: yes
-
Referee: [Abstract and §5 (experiments)] Performance improvements and attention-sink mitigation are reported without sufficient experimental detail: no mention of statistical tests, number of runs, exact data splits, or comparison against strong baselines that also target token rigidity or attention. The risk that gains arise from generic regularization rather than the ME-Layer hypothesis cannot be assessed from the current description.
Authors: We accept that the experimental reporting requires greater detail to allow proper evaluation. In the revision, we will specify the number of runs, report means with standard deviations, include statistical significance tests, detail the exact data splits, and add comparisons against strong baselines that address token rigidity or attention sinks. This will help demonstrate that the observed gains are tied to the ME-Layer hypothesis rather than generic regularization effects. revision: yes
Circularity Check
No circularity: empirical layer identification and observations are self-contained
full rationale
The paper's core claims rest on post-hoc empirical observations of activation norms across model families to label the first layer exceeding a magnitude threshold as the ME Layer, followed by analysis of RMSNorm and FFN contributions at that point and a proposed mitigation technique. No equations, fitted parameters, or self-citations are shown to reduce the identification, propagation claim, or performance improvements back to the inputs by construction. The derivation chain consists of direct measurements and interventions rather than self-definitional renaming or load-bearing self-citation chains, making the findings independent of the observed patterns themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Transformer architectures employ residual connections that propagate hidden states across layers.
invented entities (1)
-
Massive Emergence Layer (ME Layer)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe identify a specific layer named the Massive Emergence Layer (ME Layer)... where massive activations first emerge and subsequently propagate to deeper layers through residual connections. We show that, within the ME Layer both the RMSNorm and the FFN parameters jointly contribute to the emergence of massive activations.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearOnce formed, the massive activation token representation remains largely invariant across layers, reducing the diversity of hidden representations passed to the attention module.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.