Recognition: no theorem link
MoMo: Conditioned Contrastive Representation Learning for Preference-Modulated Planning
Pith reviewed 2026-05-15 06:03 UTC · model grok-4.3
The pith
MoMo conditions contrastive representations with a scalar preference to modulate planning conservativeness at inference time while preserving density ratios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MoMo learns a joint conditioning of the representation geometry and latent prediction operator via Feature-Wise Linear Modulation and low-rank neural modulation, respectively, which preserves the probability density ratio encoded in the representation space required for inference-driven contrastive planning and retains its inference-time efficiency.
What carries the argument
Feature-Wise Linear Modulation of the representation geometry combined with low-rank neural modulation of the prediction operator, which together enable preference-conditioned planning without altering the core contrastive structure.
If this is right
- MoMo smoothly adapts plan safety according to user preferences across environments.
- It yields improved temporal and preferential consistency over state augmentation baselines.
- The formulation retains inference-time efficiency of contrastive planning.
- Plans can trade task efficiency against risk exposure continuously for the same start-goal query.
Where Pith is reading between the lines
- Similar modulation techniques could extend to other latent-space planning methods beyond contrastive ones.
- Users might achieve fine-grained control in real-world robotics by tuning a single preference parameter.
- Testing in more dynamic environments could reveal limits of the preservation of density ratios.
Load-bearing premise
That Feature-Wise Linear Modulation of the representation geometry combined with low-rank neural modulation of the prediction operator preserves the probability density ratio without introducing inconsistencies or requiring retraining.
What would settle it
An observation that the modulated representations lead to inconsistent probability density ratios or require retraining to maintain planning accuracy would falsify the claim.
Figures

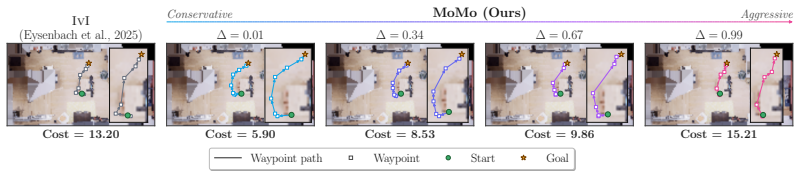

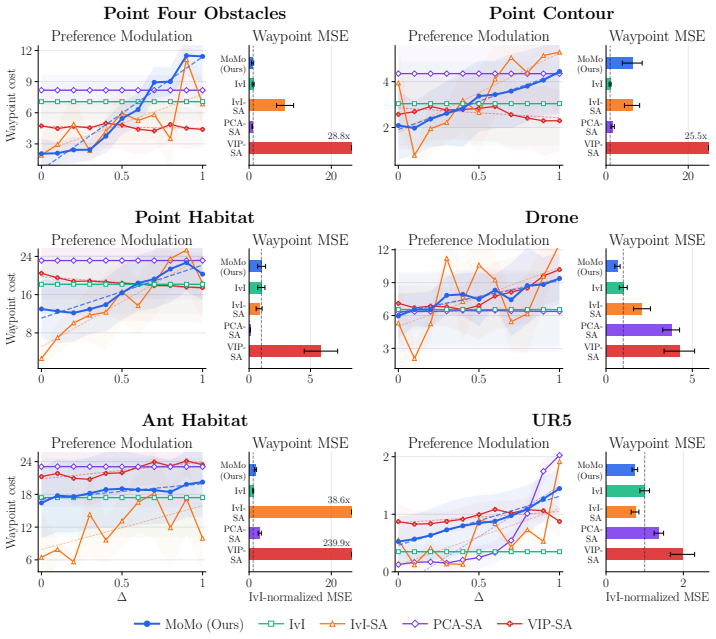


read the original abstract
Temporally contrastive representation learning induces a latent structure capable of reducing long-horizon planning to inference in a low-dimensional linear system. However, existing contrastive planning work learns a single latent geometry which cannot distinguish multiple valid behaviors trading task efficiency against risk exposure for the same start-goal query. We introduce MoMo, a preference-conditioned contrastive planner allowing a scalar user preference to continuously modulate plan conservativeness at inference time, without retraining. MoMo learns a joint conditioning of the representation geometry and latent prediction operator via Feature-Wise Linear Modulation and low-rank neural modulation, respectively. We show that our formulation preserves the probability density ratio encoded in the representation space that is required for inference-driven contrastive planning, further retaining its inference-time efficiency. Across six environments, MoMo smoothly adapts plan safety according to user preferences, yielding improved temporal and preferential consistency over state augmentation baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MoMo, a preference-conditioned contrastive representation learning approach for planning. It jointly conditions the latent representation geometry via Feature-Wise Linear Modulation (FiLM) and the latent prediction operator via low-rank neural modulation, allowing a scalar user preference to modulate plan conservativeness continuously at inference time without retraining. The central claim is that this formulation preserves the probability density ratio encoded in the representation space required for inference-driven contrastive planning, while retaining inference efficiency; experiments across six environments demonstrate improved temporal and preferential consistency over state-augmentation baselines.
Significance. If the density-ratio preservation is rigorously established, MoMo would enable tunable safety-efficiency trade-offs in contrastive planning without sacrificing the core inference advantages of the latent linear system, which is a meaningful extension for applications such as robotics where user-specified risk preferences matter.
major comments (3)
- [§3] §3 (Method): The claim that FiLM conditioning of the representation and low-rank modulation of the prediction operator preserve the probability density ratio p(z|s,g,preference)/p(z|s,g) is asserted without an explicit derivation or algebraic cancellation steps. No equations demonstrate invariance of the ratio to the preference scalar under the chosen modulation forms.
- [Abstract] Abstract and §3.1: The preservation is presented as an independent property of the modulation choice, yet the manuscript supplies no section reference or proof showing that the FiLM scales and low-rank updates cancel identically in the numerator and denominator for arbitrary preference values.
- [§4] §4 (Experiments): Reported improvements in consistency lack error bars, quantitative metrics confirming density-ratio preservation, or ablations isolating the contribution of FiLM versus low-rank modulation, leaving the empirical support for the central theoretical claim incomplete.
minor comments (2)
- [§3] Notation for the preference scalar and its injection points should be standardized across equations to avoid ambiguity with conditioning variables.
- [Figure 1] Figure captions could explicitly label the FiLM and low-rank modules to improve readability of the architecture diagram.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address the concerns regarding the theoretical derivation and experimental reporting. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [§3] §3 (Method): The claim that FiLM conditioning of the representation and low-rank modulation of the prediction operator preserve the probability density ratio p(z|s,g,preference)/p(z|s,g) is asserted without an explicit derivation or algebraic cancellation steps. No equations demonstrate invariance of the ratio to the preference scalar under the chosen modulation forms.
Authors: We agree that an explicit algebraic derivation was not included in the original submission. In the revised manuscript we have added a new subsection (now §3.3) that derives the invariance step-by-step. Starting from the modulated encoder and predictor forms, we show that the FiLM scale and shift terms appear identically in both the numerator and denominator of the density ratio, while the low-rank update to the transition matrix factors out of the linear system solution, leaving the ratio unchanged for any scalar preference value. The derivation confirms that the contrastive planning objective remains valid under continuous modulation. revision: yes
-
Referee: [Abstract] Abstract and §3.1: The preservation is presented as an independent property of the modulation choice, yet the manuscript supplies no section reference or proof showing that the FiLM scales and low-rank updates cancel identically in the numerator and denominator for arbitrary preference values.
Authors: We have updated both the abstract and §3.1 to explicitly reference the new derivation subsection. The abstract now states that the preservation follows from the algebraic cancellation shown in §3.3, and §3.1 includes a brief forward pointer to the proof. This makes the independence of the property from specific preference values clear. revision: yes
-
Referee: [§4] §4 (Experiments): Reported improvements in consistency lack error bars, quantitative metrics confirming density-ratio preservation, or ablations isolating the contribution of FiLM versus low-rank modulation, leaving the empirical support for the central theoretical claim incomplete.
Authors: We have added error bars (standard deviation over 5 random seeds) to all consistency metrics in Tables 1–3 and Figure 4. We also include a new ablation table (Table 4) that isolates FiLM-only, low-rank-only, and joint modulation, showing that both components are required for smooth preference modulation. A direct quantitative metric for density-ratio preservation is difficult to obtain in high-dimensional latent spaces without ground-truth densities; we therefore rely on the indirect but theoretically grounded consistency metrics, which we now explicitly link back to the derivation in §3.3. revision: partial
Circularity Check
No circularity: density-ratio preservation presented as independent property of modulation
full rationale
The paper claims that Feature-Wise Linear Modulation of the representation geometry combined with low-rank neural modulation of the prediction operator preserves the probability density ratio required for inference-driven contrastive planning. No equations, self-citations, or fitted parameters are exhibited that reduce this preservation to a tautology, a renamed input, or a self-referential result by construction. The central assertion is offered as a mathematical consequence of the chosen conditioning operators rather than a re-expression of the training objective or a prior author result. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Temporally contrastive representation learning induces a latent structure that reduces planning to inference in a low-dimensional linear system
- ad hoc to paper Joint conditioning via FiLM and low-rank modulation preserves the probability density ratio
Reference graph
Works this paper leans on
-
[1]
Roberto Bolli and H. Harry Asada. Elderly bodily assistance robot (e-bar): A robot system for body-weight support, ambulation assistance, and fall catching, without the use of a harness. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 713–719,
-
[2]
doi: 10.1109/ICRA55743.2025.11127403
-
[3]
Jorgen Cani, Panagiotis Koletsis, Konstantinos Foteinos, Ioannis Kefaloukos, Lampros Argyriou, Manolis Falelakis, Iván Del Pino, Angel Santamaria-Navarro, Martin ˇCech, Ondˇrej Severa, Alessandro Umbrico, Francesca Fracasso, AndreA Orlandini, Dimitrios Drakoulis, Evangelos Markakis, Iraklis Varlamis, and Georgios Th. Papadopoulos. Triffid: Autonomous robo...
-
[4]
Wu, Yonjae Kim, Axel Krieger, and Peter C.W
Simon Leonard, Kyle L. Wu, Yonjae Kim, Axel Krieger, and Peter C.W. Kim. Smart tissue anastomosis robot (star): A vision-guided robotics system for laparoscopic suturing.IEEE Transactions on Biomedical Engineering, 61(4):1305–1317, 2014. doi: 10.1109/TBME.2014. 2302385
-
[5]
Lars Blackmore and Masahiro Ono.Convex Chance Constrained Predictive Control Without Sampling. 2009. doi: 10.2514/6.2009-5876. URL https://arc.aiaa.org/doi/abs/10. 2514/6.2009-5876
-
[6]
Masahiro Ono and Brian C. Williams. Iterative risk allocation: A new approach to robust model predictive control with a joint chance constraint. In2008 47th IEEE Conference on Decision and Control, pages 3427–3432, 2008. doi: 10.1109/CDC.2008.4739221
-
[7]
Charles Dawson, Ashkan Jasour, Andreas G. Hofmann, and Brian C. Williams. Provably safe trajectory optimization in the presence of uncertain convex obstacles.CoRR, 2020. URL https://arxiv.org/abs/2003.07811
-
[8]
Gavrila, and Javier Alonso-Mora
Oscar de Groot, Laura Ferranti, Dariu M. Gavrila, and Javier Alonso-Mora. Scenario-based motion planning with bounded probability of collision.The International Journal of Robotics Research, 44(9):1507–1525, 2025. doi: 10.1177/02783649251315203. URL https://doi. org/10.1177/02783649251315203
-
[9]
Xin Huang, Sungkweon Hong, Andreas Hofmann, and Brian C. Williams. Online risk-bounded motion planning for autonomous vehicles in dynamic environments.Proceedings of the Interna- tional Conference on Automated Planning and Scheduling, 29(1):214–222, Jul. 2019. doi: 10.1609/icaps.v29i1.3479. URL https://ojs.aaai.org/index.php/ICAPS/article/ view/3479
-
[10]
Chance constrained motion planning for high-dimensional robots
Siyu Dai, Shawn Schaffert, Ashkan Jasour, Andreas Hofmann, and Brian Williams. Chance constrained motion planning for high-dimensional robots. In2019 International Conference on Robotics and Automation (ICRA), pages 8805–8811, 2019. doi: 10.1109/ICRA.2019.8793660
-
[11]
Safe multi-agent navigation guided by goal- conditioned safe reinforcement learning
Meng Feng, Viraj Parimi, and Brian Williams. Safe multi-agent navigation guided by goal- conditioned safe reinforcement learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), page 16869–16875. IEEE, May 2025. doi: 10.1109/icra55743.2025. 11127461. URLhttp://dx.doi.org/10.1109/ICRA55743.2025.11127461
-
[12]
RAIL: Risk-Averse Imitation Learning
Anirban Santara, Abhishek Naik, Balaraman Ravindran, Dipankar Das, Dheevatsa Mudigere, Sasikanth Avancha, and Bharat Kaul. Rail: Risk-averse imitation learning, 2017. URL https://arxiv.org/abs/1707.06658
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Jasour, Guy Rosman, and Brian Charles Williams
Xin Huang, Meng Feng, Ashkan M. Jasour, Guy Rosman, and Brian Charles Williams. Risk conditioned neural motion planning.2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9057–9063, 2021. URL https://api.semanticscholar. org/CorpusID:236912881
work page 2021
-
[14]
Gwangpyo Yoo, Jinwoo Park, and Honguk Woo. Risk-conditioned reinforcement learning: A generalized approach for adapting to varying risk measures.Proceedings of the AAAI Conference on Artificial Intelligence, 38(15):16513–16521, Mar. 2024. doi: 10.1609/aaai.v38i15.29589. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/29589. 10
-
[15]
Saformer: A conditional sequence modeling approach to offline safe reinforcement learning, 2023
Qin Zhang, Linrui Zhang, Haoran Xu, Li Shen, Bowen Wang, Yongzhe Chang, Xueqian Wang, Bo Yuan, and Dacheng Tao. Saformer: A conditional sequence modeling approach to offline safe reinforcement learning, 2023. URLhttps://arxiv.org/abs/2301.12203
-
[16]
Pacer: Preference-conditioned all-terrain costmap generation.arXiv preprint arXiv:2410.23488, 2024
Luisa Mao, Garrett Warnell, Peter Stone, and Joydeep Biswas. Pacer: Preference-conditioned all-terrain costmap generation.arXiv preprint arXiv:2410.23488, 2024. URL https://arxiv. org/abs/2410.23488
-
[17]
Contrastive learning as goal-conditioned reinforcement learning, 2023
Benjamin Eysenbach, Tianjun Zhang, Ruslan Salakhutdinov, and Sergey Levine. Contrastive learning as goal-conditioned reinforcement learning, 2023. URLhttps://arxiv.org/abs/ 2206.07568
-
[18]
Benjamin Eysenbach, Vivek Myers, Ruslan Salakhutdinov, and Sergey Levine. Inference via interpolation: Contrastive representations provably enable planning and inference, 2025. URL https://arxiv.org/abs/2403.04082
-
[19]
Contrastive difference predictive coding, 2025
Chongyi Zheng, Ruslan Salakhutdinov, and Benjamin Eysenbach. Contrastive difference predictive coding, 2025. URLhttps://arxiv.org/abs/2310.20141
-
[20]
Stabilizing contrastive rl: Techniques for robotic goal reaching from offline data, 2025
Chongyi Zheng, Benjamin Eysenbach, Homer Walke, Patrick Yin, Kuan Fang, Ruslan Salakhut- dinov, and Sergey Levine. Stabilizing contrastive rl: Techniques for robotic goal reaching from offline data, 2025. URLhttps://arxiv.org/abs/2306.03346
-
[21]
Astghik Hakobyan, Gyeong Chan Kim, and Insoon Yang. Risk-aware motion planning and control using cvar-constrained optimization.IEEE Robotics and Automation Letters, 4(4): 3924–3931, 2019. doi: 10.1109/LRA.2019.2929980
-
[22]
Belief control barrier functions for risk-aware control, 2023
Matti Vahs, Christian Pek, and Jana Tumova. Belief control barrier functions for risk-aware control, 2023. URLhttps://arxiv.org/abs/2309.06499
- [23]
-
[24]
Constrained decision transformer for offline safe reinforcement learning
Zuxin Liu, Zijian Guo, Yihang Yao, Zhepeng Cen, Wenhao Yu, Tingnan Zhang, and Ding Zhao. Constrained decision transformer for offline safe reinforcement learning. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 21611–21630. PMLR, 2023. URL https://proceedings.mlr. press/v...
work page 2023
-
[25]
Zijian Guo, Weichao Zhou, and Wenchao Li. Temporal logic specification-conditioned deci- sion transformer for offline safe reinforcement learning. InProceedings of the 41st Interna- tional Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 17003–17019. PMLR, 2024. URL https://proceedings.mlr.press/ v235/guo24j.html
work page 2024
-
[26]
Constraint-conditioned actor-critic for offline safe reinforcement learning
Zijian Guo, Weichao Zhou, Shengao Wang, and Wenchao Li. Constraint-conditioned actor-critic for offline safe reinforcement learning. InInternational Conference on Learning Representa- tions, 2025. URLhttps://openreview.net/forum?id=nrRkAAAufl
work page 2025
-
[27]
Zuxin Liu, Zijian Guo, Haohong Lin, Yihang Yao, Jiacheng Zhu, Zhepeng Cen, Hanjiang Hu, Wenhao Yu, Tingnan Zhang, Jie Tan, and Ding Zhao. Datasets and benchmarks for offline safe reinforcement learning.Journal of Data-centric Machine Learning Research, 2024
work page 2024
-
[28]
A generalized algorithm for multi- objective reinforcement learning and policy adaptation
Runzhe Yang, Xingyuan Sun, and Karthik Narasimhan. A generalized algorithm for multi- objective reinforcement learning and policy adaptation. InAdvances in Neural Information Processing Systems, 2019. URLhttps://openreview.net/forum?id=B1lR3HBeUB
work page 2019
-
[29]
Distributional pareto-optimal multi-objective reinforcement learning
Xin-Qiang Cai, Pushi Zhang, Li Zhao, Jiang Bian, Masashi Sugiyama, and Ashley Juan Llorens. Distributional pareto-optimal multi-objective reinforcement learning. InAdvances in Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id= prIwYTU9PV. 11
work page 2023
-
[30]
Scaling pareto-efficient decision making via offline multi-objective rl
Baiting Zhu, Meihua Dang, and Aditya Grover. Scaling pareto-efficient decision making via offline multi-objective rl. ICLR 2023 Poster, 2023. URL https://openreview.net/forum? id=Ki4ocDm364
work page 2023
-
[31]
Efficient discovery of pareto front for multi-objective reinforcement learning
Ruohong Liu, Yuxin Pan, Linjie Xu, Lei Song, Pengcheng You, Yize Chen, and Jiang Bian. Efficient discovery of pareto front for multi-objective reinforcement learning. InInternational Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=fDGPIuCdGi
work page 2025
-
[32]
Embed to Control: A Locally Linear Latent Dynamics Model for Control from Raw Images
Manuel Watter, Jost Tobias Springenberg, Joschka Boedecker, and Martin Riedmiller. Embed to control: A locally linear latent dynamics model for control from raw images, 2015. URL https://arxiv.org/abs/1506.07365
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
Learning Latent Dynamics for Planning from Pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels, 2019. URL https: //arxiv.org/abs/1811.04551
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[34]
Robot Motion Planning in Learned Latent Spaces
Brian Ichter and Marco Pavone. Robot motion planning in learned latent spaces, 2018. URL https://arxiv.org/abs/1807.10366
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Suhan Park, Suhyun Jeon, and Jaeheung Park. A constrained motion planning method exploiting learned latent space for high-dimensional state and constraint spaces.IEEE/ASME Transactions on Mechatronics, 29(4):3001–3009, 2024. doi: 10.1109/TMECH.2024.3399594
-
[36]
Local path opti- mization in the latent space using learned distance gradient
Jiawei Zhang, Chengchao Bai, Wei Pan, Tianhang Liu, and Jifeng Guo. Local path opti- mization in the latent space using learned distance gradient. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), page 15940–15946. IEEE, 2025. doi: 10.1109/iros60139.2025.11247535. URL http://dx.doi.org/10.1109/IROS60139.2025. 11247535
- [37]
- [38]
-
[39]
Shuonan Dong and Brian Williams. Learning and recognition of hybrid manipulation motions in variable environments using probabilistic flow tubes.International Journal of Social Robotics, 4(4):357–368, 2012. doi: 10.1007/s12369-012-0155-x. URL https://doi.org/10.1007/ s12369-012-0155-x
-
[40]
Diederik P. Kingma and Max Welling. An introduction to variational autoencoders.Foundations and Trends® in Machine Learning, 12(4):307–392, November 2019. ISSN 1935-8245. doi: 10.1561/2200000056. URLhttp://dx.doi.org/10.1561/2200000056
-
[41]
Time-contrastive networks: Self-supervised learning from video
Pierre Sermanet, Corey Lynch, Yevgen Chebotar, Jasmine Hsu, Eric Jang, Stefan Schaal, and Sergey Levine. Time-contrastive networks: Self-supervised learning from video. In2018 IEEE International Conference on Robotics and Automation (ICRA), pages 1134–1141, 2018. doi: 10.1109/ICRA.2018.8462891. URLhttps://doi.org/10.1109/ICRA.2018.8462891
-
[42]
Peter Dayan. Improving generalization for temporal difference learning: The successor repre- sentation.Neural Computation, 5(4):613–624, 1993. doi: 10.1162/neco.1993.5.4.613. URL https://doi.org/10.1162/neco.1993.5.4.613
-
[43]
André Barreto, Will Dabney, Rémi Munos, Jonathan J. Hunt, Tom Schaul, Hado P. van Hasselt, and David Silver. Successor features for transfer in reinforce- ment learning. InAdvances in Neural Information Processing Systems 30, pages 4058–4068, 2017. URL https://papers.nips.cc/paper_files/paper/2017/hash/ 350db081a661525235354dd3e19b8c05-Abstract.html
work page 2017
-
[44]
Conditional Similarity Networks
Andreas Veit, Serge Belongie, and Theofanis Karaletsos. Conditional similarity networks, 2017. URLhttps://arxiv.org/abs/1603.07810
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Martin Q. Ma, Yao-Hung Hubert Tsai, Paul Pu Liang, Han Zhao, Kun Zhang, Ruslan Salakhut- dinov, and Louis-Philippe Morency. Conditional contrastive learning for improving fairness in self-supervised learning, 2022. URLhttps://arxiv.org/abs/2106.02866. 12
-
[46]
Ma, Han Zhao, Kun Zhang, Louis-Philippe Morency, and Ruslan Salakhutdinov
Yao-Hung Hubert Tsai, Tianqin Li, Martin Q. Ma, Han Zhao, Kun Zhang, Louis-Philippe Morency, and Ruslan Salakhutdinov. Conditional contrastive learning with kernel, 2022. URL https://arxiv.org/abs/2202.05458
-
[47]
Conditional contrastive networks, 2022
Emily Mu and John Guttag. Conditional contrastive networks, 2022. URL https: //table-representation-learning.github.io/assets/papers/conditional_ contrastive_networ.pdf
work page 2022
-
[48]
FiLM: Visual Reasoning with a General Conditioning Layer
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer, 2017. URL https://arxiv.org/abs/ 1709.07871
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
David Ha, Andrew Dai, and Quoc V . Le. Hypernetworks, 2016. URLhttps://arxiv.org/ abs/1609.09106
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[50]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding, 2019. URLhttps://arxiv.org/abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[51]
Tyrrell Rockafellar and Stanislav Uryasev
R. Tyrrell Rockafellar and Stanislav Uryasev. Optimization of conditional value-at risk.Journal of Risk, 3:21–41, 2000. URLhttps://api.semanticscholar.org/CorpusID:854622
work page 2000
-
[52]
Prajit Ramachandran, Barret Zoph, and Quoc V . Le. Searching for activation functions, 2017. URLhttps://arxiv.org/abs/1710.05941
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains, 2020. URL https: //arxiv.org/abs/2006.10739
-
[54]
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M. S...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[55]
Habitat: A Platform for Embodied AI Research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A Platform for Embodied AI Research. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
work page 2019
-
[56]
Habitat 2.0: Training home assistants to rearrange their habitat
Andrew Szot, Alex Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Chaplot, Oleksandr Maksymets, Aaron Gokaslan, Vladimir V ondrus, Sameer Dharur, Franziska Meier, Wojciech Galuba, Angel Chang, Zsolt Kira, Vladlen Koltun, Jitendra Malik, Manolis Savva, and Dhruv Batra. Habitat 2.0: Training home assist...
work page 2021
-
[57]
Habitat 3.0: A co-habitat for humans, avatars and robots, 2023
Xavi Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Ruslan Partsey, Jimmy Yang, Ruta Desai, Alexander William Clegg, Michal Hlavac, Tiffany Min, Theo Gervet, Vladimir V ondrus, Vincent-Pierre Berges, John Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakr- ishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshara Rai...
work page 2023
-
[58]
D4rl: Datasets for deep data-driven reinforcement learning, 2021
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning, 2021. URL https://arxiv.org/abs/2004. 07219
work page 2021
-
[59]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training, 2023. URLhttps://arxiv.org/abs/2210.00030. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
E. W. Hobson. On the fundamental lemma of the calculus of variations, and on some related theorems.Proceedings of the London Mathematical Society, s2-11(1):17–28, 1913. doi: https: //doi.org/10.1112/plms/s2-11.1.17. URL https://londmathsoc.onlinelibrary.wiley. com/doi/abs/10.1112/plms/s2-11.1.17
-
[61]
f-micl: Understanding and generalizing infonce-based contrastive learning, 2024
Yiwei Lu, Guojun Zhang, Sun Sun, Hongyu Guo, and Yaoliang Yu. f-micl: Understanding and generalizing infonce-based contrastive learning, 2024. URL https://arxiv.org/abs/2402. 10150
work page 2024
-
[62]
Zhuang Ma and Michael Collins. Noise contrastive estimation and negative sampling for conditional models: Consistency and statistical efficiency, 2018. URL https://arxiv.org/ abs/1809.01812
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[63]
J.J. Kuffner and S.M. LaValle. Rrt-connect: An efficient approach to single-query path planning. InProceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No.00CH37065), volume 2, pages 995–1001 vol.2, 2000. doi: 10.1109/ROBOT.2000.844730
-
[64]
On the Spectral Bias of Neural Networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred A. Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks, 2019. URL https://arxiv.org/abs/1806.08734
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[65]
Infonce induces gaussian distribu- tion, 2026
Roy Betser, Eyal Gofer, Meir Yossef Levi, and Guy Gilboa. Infonce induces gaussian distribu- tion, 2026. URLhttps://arxiv.org/abs/2602.24012. 14 A Conditioned Contrastive Theory A.1 Density Encoding in Learned Logits The Gauss-Markov inference-driven planning method outlined in Section 3.2 requires learned logits to encode the probability ratio expressed ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.