Recognition: no theorem link
OracleTSC: Oracle-Informed Reward Hurdle and Uncertainty Regularization for Traffic Signal Control
Pith reviewed 2026-05-12 00:49 UTC · model grok-4.3
The pith
OracleTSC stabilizes LLM finetuning for traffic signal control by filtering weak rewards and enforcing decision consistency, yielding large efficiency gains and cross-intersection transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OracleTSC stabilizes LLM-based traffic signal control through an oracle-informed reward hurdle that subtracts a calibrated threshold from environmental rewards to discard weak learning signals and uncertainty regularization that maximizes the probability of the selected response across sampled outputs. Applied to a LLaMA3-8B model, the method produces stable policy improvement on the LibSignal benchmark, delivering a 75 percent reduction in travel time and 67 percent reduction in queue length versus the pretrained baseline while retaining natural-language reasoning. The resulting policy further generalizes across intersections, transferring to a structurally different site with 17 percent (1
What carries the argument
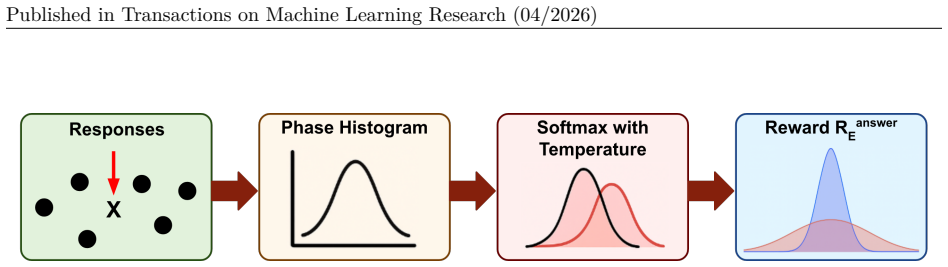
Oracle-informed reward hurdle that filters marginal reward signals by subtracting a calibrated threshold, combined with uncertainty regularization that maximizes probability of the chosen response across samples to promote consistent decisions during LLM reinforcement finetuning for traffic signal control.
If this is right
- A compact LLaMA3-8B model achieves 75 percent lower travel time and 67 percent lower queue length than its pretrained baseline on the LibSignal benchmark.
- The finetuned policy transfers to a structurally different intersection without further training, producing 17 percent lower travel time and 39 percent lower queue length.
- Natural language explanations of each control decision remain available, preserving interpretability.
- The same stabilization pattern applies to any reinforcement-finetuning task whose rewards are both sparse and delayed.
Where Pith is reading between the lines
- The same two mechanisms could be tested on other sequential decisions with delayed sparse feedback, such as energy dispatch or autonomous vehicle routing.
- Natural-language outputs open the possibility of human-in-the-loop oversight where operators can query or override the model's reasoning at runtime.
- Cross-intersection transfer reduces the data-collection burden when scaling a single trained model across an entire city network.
Load-bearing premise
The reward hurdle threshold can be calibrated in advance so that it reliably filters weak signals without discarding useful learning information, and that maximizing the probability of the selected response across sampled outputs will produce stable policy improvement despite the sparse and delayed nature of traffic congestion feedback.
What would settle it
Re-running the LibSignal experiments with the reward hurdle removed and finding travel-time reductions below 20 percent or markedly higher performance variance would show the two mechanisms are not responsible for the reported stability and gains.
Figures









read the original abstract
Transparent decision-making is essential for traffic signal control (TSC) systems to earn public trust. However, traditional reinforcement learning-based TSC methods function as black boxes with limited interpretability. Although large language models (LLMs) can provide natural language reasoning, reinforcement finetuning for TSC remains unstable because feedback is sparse and delayed, while most actions produce only marginal changes in congestion metrics. We introduce OracleTSC, which stabilizes LLM-based TSC through two mechanisms: (1) a reward hurdle mechanism that filters weak learning signals by subtracting a calibrated threshold from environmental rewards, and (2) uncertainty regularization that maximizes the probability of the selected response to encourage consistent decisions across sampled outputs. Experiments on the LibSignal benchmark show that OracleTSC enables a compact LLaMA3-8B model to substantially improve traffic efficiency, achieving a 75% reduction in travel time and a 67% decrease in queue length compared with the pretrained baseline while preserving interpretability through natural language explanations. OracleTSC also demonstrates strong cross-intersection generalization: a policy trained on one intersection transfers to a structurally different intersection with 17% lower travel time and 39% lower queue length without additional finetuning. These results suggest that uncertainty-aware reward shaping can improve the stability and effectiveness of reinforcement fine-tuning for TSC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OracleTSC, a framework for stabilizing reinforcement learning fine-tuning of large language models for traffic signal control. It proposes two mechanisms: an oracle-informed reward hurdle that subtracts a calibrated threshold from environmental rewards to filter weak signals, and uncertainty regularization that maximizes the probability of the selected response across sampled outputs to encourage consistent decisions. On the LibSignal benchmark, the method is claimed to enable a LLaMA3-8B model to achieve 75% reduction in travel time and 67% decrease in queue length compared to the pretrained baseline, while also showing cross-intersection generalization with 17% lower travel time and 39% lower queue length without additional fine-tuning, all while preserving interpretability via natural language explanations.
Significance. If the experimental results prove robust, this work could meaningfully advance interpretable LLM-based controllers for traffic signal control by addressing instability from sparse and delayed rewards. The reported cross-intersection transfer without retraining is a notable strength that could support scalable deployment. The combination of reward shaping and output-consistency regularization offers a concrete direction for RL fine-tuning in control domains, and the emphasis on natural-language explanations directly tackles the black-box limitation of prior TSC methods.
major comments (3)
- [Abstract] Abstract: The abstract states large performance numbers (75% travel-time reduction, 67% queue-length decrease) but supplies no information on how the threshold is calibrated, whether error bars or statistical tests were used, the exact training procedure, or any ablation that isolates each component; without these details the data cannot be verified to support the central claims.
- [§3] §3 (Method, reward-hurdle subsection): The claim that the oracle-informed threshold reliably filters weak signals without discarding useful gradients is load-bearing for the reported gains, yet the manuscript provides neither the explicit calibration procedure nor a sensitivity analysis across intersections or reward scales; the skeptic correctly notes that this leaves open whether the mechanism works without future/global information unavailable at deployment.
- [§4] §4 (Experiments, cross-intersection results): The 17% travel-time and 39% queue-length transfer gains are presented without ablations that isolate the uncertainty-regularization term from standard RL fine-tuning or demonstrate that it specifically mitigates the credit-assignment problem under sparse congestion feedback; this makes it impossible to attribute the improvements to the two proposed stabilisers rather than generic fine-tuning.
minor comments (1)
- [§3] Notation for the selected-response probability in the uncertainty-regularization objective is introduced without an explicit equation reference, making it harder to connect the textual description to the implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications, procedures, and ablations.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states large performance numbers (75% travel-time reduction, 67% queue-length decrease) but supplies no information on how the threshold is calibrated, whether error bars or statistical tests were used, the exact training procedure, or any ablation that isolates each component; without these details the data cannot be verified to support the central claims.
Authors: We agree that the abstract would benefit from additional supporting details. In the revised version we will expand the abstract to briefly describe the threshold calibration approach, note the inclusion of error bars and statistical tests, outline the main elements of the training procedure, and reference the component ablations. These additions will make the performance claims more verifiable while remaining within abstract length constraints. revision: yes
-
Referee: [§3] §3 (Method, reward-hurdle subsection): The claim that the oracle-informed threshold reliably filters weak signals without discarding useful gradients is load-bearing for the reported gains, yet the manuscript provides neither the explicit calibration procedure nor a sensitivity analysis across intersections or reward scales; the skeptic correctly notes that this leaves open whether the mechanism works without future/global information unavailable at deployment.
Authors: We acknowledge that the current description of the reward-hurdle mechanism is high-level and lacks the requested explicit calibration steps and sensitivity analysis. We will add a detailed calibration procedure in Section 3 that specifies how the threshold is computed from oracle data collected during training (for example, as a percentile of observed rewards on a validation set of episodes). We will also include sensitivity plots and tables in the experiments section that vary the threshold across intersections and reward scales. On the deployment concern: the oracle is used exclusively for offline calibration; once the threshold is fixed, the learned policy operates without any future or global information, and the uncertainty regularization is intended to promote stable decisions under this constraint. revision: yes
-
Referee: [§4] §4 (Experiments, cross-intersection results): The 17% travel-time and 39% queue-length transfer gains are presented without ablations that isolate the uncertainty-regularization term from standard RL fine-tuning or demonstrate that it specifically mitigates the credit-assignment problem under sparse congestion feedback; this makes it impossible to attribute the improvements to the two proposed stabilisers rather than generic fine-tuning.
Authors: We agree that isolating the contribution of uncertainty regularization is necessary to support the attribution of gains. The current cross-intersection results compare the full OracleTSC policy against the pretrained baseline but do not include the requested ablations. In the revision we will add experiments that report performance for (i) standard RL fine-tuning without uncertainty regularization, (ii) the reward-hurdle component alone, and (iii) the complete method. We will also present learning-curve analyses that examine how the regularization term affects convergence under sparse congestion feedback, thereby clarifying its role in addressing credit assignment. revision: yes
Circularity Check
No significant circularity; claims rest on experimental outcomes
full rationale
The paper defines OracleTSC via two explicit mechanisms (reward hurdle as threshold subtraction from environmental rewards, uncertainty regularization as maximizing selected-response probability across samples) without any equations that equate these to fitted parameters or prior results by construction. No derivations, self-citations, uniqueness theorems, or ansatzes are presented that reduce the reported travel-time or queue-length gains to definitional equivalence. Performance claims derive from LibSignal benchmark experiments rather than internal fitting or renaming, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward hurdle threshold
axioms (1)
- domain assumption LLMs can generate useful natural-language reasoning for traffic signal decisions when fine-tuned with the proposed mechanisms
Reference graph
Works this paper leans on
-
[1]
ISBN 978- 0-309-30888-5. doi: 10.17226/22097. URLhttps://nap.nationalacademies.org/catalog/22097/ signal-timing-manual-second-edition. Lili Chen, Mihir Prabhudesai, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. Self-questioning language models,
-
[2]
URLhttps://arxiv.org/abs/2508.03682. 21 Published in Transactions on Machine Learning Research (04/2026) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[3]
doi: 10.1038/s41586-024-07421-0. Evan Greensmith, Peter L. Bartlett, and Jonathan Baxter. Variance reduction techniques for gradient estimates in reinforcement learning.J. Mach. Learn. Res., 5:1471–1530, December
-
[4]
Pan He, Quanyi Li, Xiaoyong Yuan, and Bolei Zhou
ISSN 1532-4435. Pan He, Quanyi Li, Xiaoyong Yuan, and Bolei Zhou. A holistic framework towards vision-based traffic signal control with microscopic simulation.arXiv preprint arXiv:2403.06884,
-
[5]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Haoyuan Jiang, Ziyue Li, Zhishuai Li, Lei Bai, Hangyu Mao, Wolfgang Ketter, and Rui Zhao
URLhttps://arxiv.org/abs/2402.03271. Haoyuan Jiang, Ziyue Li, Zhishuai Li, Lei Bai, Hangyu Mao, Wolfgang Ketter, and Rui Zhao. A gen- eral scenario-agnostic reinforcement learning for traffic signal control.IEEE Transactions on Intelligent Transportation Systems, 25(9):11330–11344,
-
[7]
doi: 10.1109/TITS.2024.3377106. Zixuan Ke, Fangkai Jiao, Yifei Ming, Xuan-Phi Nguyen, Austin Xu, Do Xuan Long, Minzhi Li, Chengwei Qin, Peifeng Wang, Silvio Savarese, Caiming Xiong, and Shafiq Joty. A survey of frontiers in llm reasoning: Inference scaling, learning to reason, and agentic systems,
-
[8]
LLMLight: Large language models as traffic signal control agents,
URLhttps://arxiv.org/abs/2302.09664. Siqi Lai, Zhao Xu, Weijia Zhang, Hao Liu, and Hui Xiong. Llmlight: Large language models as traffic signal control agents. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1, KDD ’25, pp. 2335–2346, New York, NY, USA, 2025a. Association for Computing Machinery. ISBN 9798400712456...
-
[9]
A systematic survey on large language models for algorithm design.ACM Comput
22 Published in Transactions on Machine Learning Research (04/2026) Fei Liu, Yiming Yao, Ping Guo, Zhiyuan Yang, Xi Lin, Zhe Zhao, Xialiang Tong, Kun Mao, Zhichao Lu, Zhenkun Wang, Mingxuan Yuan, and Qingfu Zhang. A systematic survey on large language models for algorithm design.ACM Comput. Surv., 58(8), February
work page 2026
-
[10]
ISSN 0360-0300. doi: 10.1145/3787585. URLhttps://doi.org/10.1145/3787585. Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. Reft: Reasoning with reinforced fine-tuning,
-
[11]
Reft: Reasoning with reinforced fine-tuning, 2024
URLhttps://arxiv.org/abs/2401.08967. Francisco J. Martinez, Chai Keong Toh, Juan-Carlos Cano, Carlos T. Calafate, and Pietro Manzoni. A survey and comparative study of simulators for vehicular ad hoc networks (vanets).Wireless Communications and Mobile Computing, 11(7):813–828,
-
[12]
URLhttps:// onlinelibrary.wiley.com/doi/abs/10.1002/wcm.859
doi: https://doi.org/10.1002/wcm.859. URLhttps:// onlinelibrary.wiley.com/doi/abs/10.1002/wcm.859. Hao Mei, Xiaoliang Lei, Longchao Da, Bin Shi, and Hua Wei. Libsignal: An open library for traffic signal control.Machine Learning, 113(8):5235–5271,
-
[13]
Mihir Prabhudesai, Lili Chen, Alex Ippoliti, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak
URLhttps://proceedings.neurips.cc/ paper_files/paper/2024/file/10c456d2160517581a234dfde15a7505-Paper-Conference.pdf. Mihir Prabhudesai, Lili Chen, Alex Ippoliti, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. Maximizing confidence alone improves reasoning,
work page 2024
-
[14]
URLhttps://arxiv.org/abs/2505.22660. David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling,
-
[15]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pp. 1889–1897. PMLR, 2015a. John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv prep...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URLhttps://arxiv.org/abs/2509.03493. Pravin Varaiya. Max pressure control of a network of signalized intersections.Transportation Research Part C: Emerging Technologies, 36:177–195,
-
[17]
doi: https://doi.org/10.1016/j.trc.2013
ISSN 0968-090X. doi: https://doi.org/10.1016/j.trc.2013. 08.014. URLhttps://www.sciencedirect.com/science/article/pii/S0968090X13001782. Théo Vincent, Boris Belousov, Carlo D’Eramo, and Jan Peters. Iterated deep q-network: Efficient learning of bellman iterations for deep reinforcement learning. InSixteenth European Workshop on Reinforcement Learning,
-
[18]
Maonan Wang, Aoyu Pang, Yuheng Kan, Man-On Pun, Chung Shue Chen, and Bo Huang
URLhttps: //arxiv.org/abs/2210.13378. Maonan Wang, Aoyu Pang, Yuheng Kan, Man-On Pun, Chung Shue Chen, and Bo Huang. Llm-assisted light: Leveraging large language model capabilities for human-mimetic traffic signal control in complex urban environments.arXiv preprint arXiv:2403.08337, 2024a. MaonanWang, XiXiong, YuhengKan, ChengchengXu, andMan-OnPun. Unit...
-
[19]
Hua Wei, Guanjie Zheng, Huaxiu Yao, and Zhenhui Li
URL https://arxiv.org/abs/2505.19486. Hua Wei, Guanjie Zheng, Huaxiu Yao, and Zhenhui Li. Intellilight: A reinforcement learning approach for intelligent traffic light control. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’18, pp. 2496–2505, New York, NY, USA,
-
[20]
Association for Computing Machinery. ISBN 9781450355520. doi: 10.1145/3219819.3220096. URLhttps://doi.org/ 10.1145/3219819.3220096. Hua Wei, Chacha Chen, Guanjie Zheng, Kan Wu, Vikash Gayah, Kai Xu, and Zhenhui Li. Presslight: Learning max pressure control to coordinate traffic signals in arterial network. InProceedings of the 25th ACM SIGKDD Internationa...
-
[21]
URLhttps://arxiv.org/abs/2411.17375. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[22]
URLhttps://arxiv.org/abs/ 2504.05812. Yuqi Zhu, Ge Li, Xue Jiang, Jia Li, Hong Mei, Zhi Jin, and Yihong Dong. Uncertainty-guided chain-of- thought for code generation with llms,
-
[23]
URLhttps://arxiv.org/abs/2503.15341. 24 Published in Transactions on Machine Learning Research (04/2026) A Appendix Contents A.1 Reward Design and PPO Stabilization Sensitivity . . . . . . . . . . . . . . . . . . . . . . . . . 26 A.2 Hyper-Parameters for Table 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 A.3 Supported Phase...
-
[24]
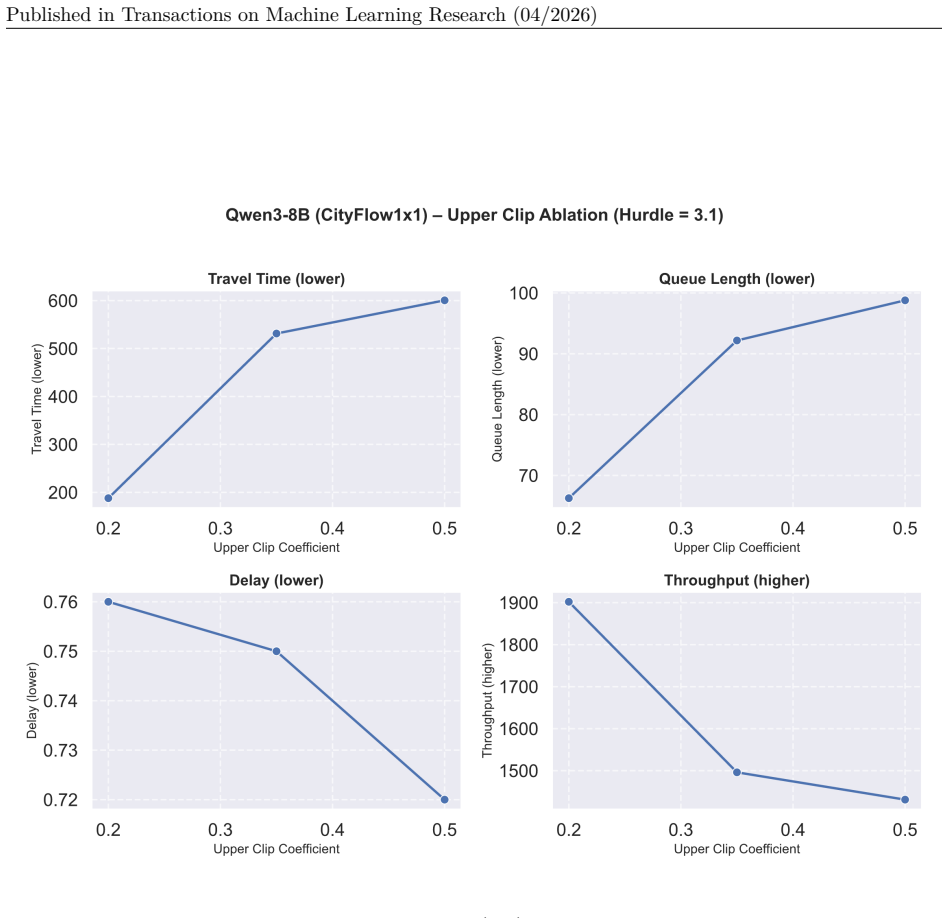
Model-specific and intersection-specific hyperparameters are detailed in Table 8, whereϵl andϵu denote the lower and upper PPO clipping bounds, andHR represents the reward hurdle threshold. Table 8: Model-specific hyperparameters for experiments in Table 1 Model Intersection Actor LR Actor Weight Decay ϵl ϵu HR Qwen3-0.6B CityFlow1x1 2.5×10−5 10−6 0.2 0.5...
work page 2026
-
[25]
Updateθ,ϕwith∇J(θ,ϕ)using Equa- tion 6 end for # Clear buffer SetB←∅ end for 29 Published in Transactions on Machine Learning Research (04/2026) Algorithm 2Extract Phase from Output Text Require:Output texts, valid phase mnemonicsK, phase descriptionsD, mapping from phase mnemonics to OpenAI Gym action classesphase_to_code, default action classdefault_cod...
work page 2026
-
[26]
to examine how it influences the policy stability and learning dynamics of language-model-based controllers. In tradi- tional PPO, a smaller clip range (1±ϵ) constrains the policy update and prevents destructive policy shifts, while a larger range permits more aggressive updates but risks over-fitting to noisy or stochastic rewards. In our entropy-control...
work page 2025
-
[27]
Number of Responses (G) Travel Time Queue Length Delay Throughput 2 377 82.04 0.73 1665 4 315.5 103.86 0.76 1750 8 146.9 45.5 0.67 1946 AsGincreases, performance improves consistently in terms of travel time and throughput. IncreasingG strengthens semantic-level uncertainty estimation by aggregating agreement across multiple independently sampled reasonin...
work page 1946
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.