Recognition: no theorem link
Learnability and Competition in High-Dimensional Multi-Component ICA
Pith reviewed 2026-05-12 01:28 UTC · model grok-4.3
The pith
In the high-dimensional limit, multi-component online ICA obeys a deterministic ODE for the overlap matrix that distinguishes decoupled and competition phases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the high-dimensional limit the joint empirical distribution of learned estimates and ground-truth components converges to a deterministic process, yielding a closed ODE system for the overlap matrix between learned directions and true components. This characterization reveals a genuinely multi-component, initialization-driven phase structure: a decoupled regime, where estimates align with distinct components and evolve nearly independently, and a competition regime, where overlapping initializations induce orthogonality-driven conflicts, slow reorientation, and delayed convergence. Steady-state analysis gives explicit learnability boundaries and competition conditions linking step size, 0
What carries the argument
The closed system of ordinary differential equations for the overlap matrix between learned directions and true components, derived from the mean-field limit of the stochastic online updates together with orthogonalization.
If this is right
- Larger higher-order moments shrink the interval of stable learning rates.
- Overlapping initializations lengthen convergence times through orthogonality-driven conflicts.
- The number of recoverable components increases in discrete steps as the learning rate is raised.
- The phase boundaries link step size, data moments, and initialization to predict when the decoupled regime is reached.
Where Pith is reading between the lines
- The ODE description could be used to select initializations that avoid the competition regime and thereby shorten training.
- Similar mean-field closures might characterize competition effects in other simultaneous orthogonalized learning rules.
- The predicted staircase in the number of recoverable components can be checked directly on large synthetic ensembles by counting successful recoveries at different learning rates.
Load-bearing premise
The high-dimensional limit and the mean-field closure that converts the stochastic online updates plus orthogonalization into a deterministic ODE system for the overlap matrix remain valid when multiple components are learned simultaneously.
What would settle it
Simulations of the multi-component ICA algorithm in successively higher dimensions should show the empirical trajectories of the overlap matrix approaching the numerical solution of the derived ODE system, with the difference vanishing as dimension tends to infinity.
Figures
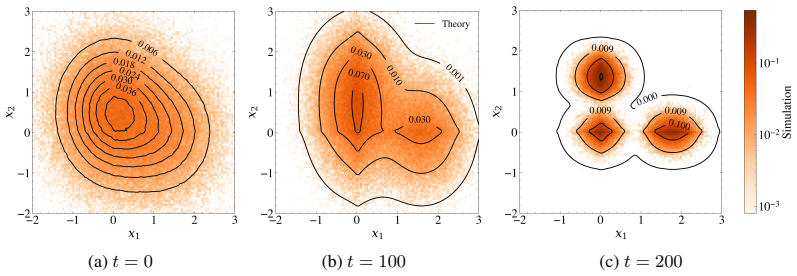

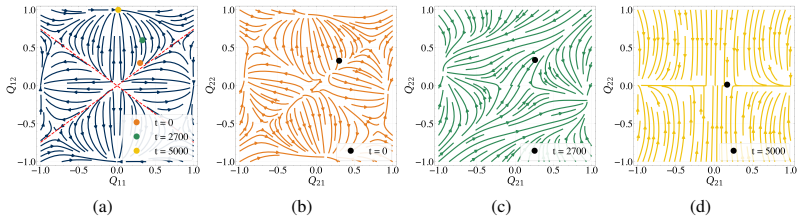


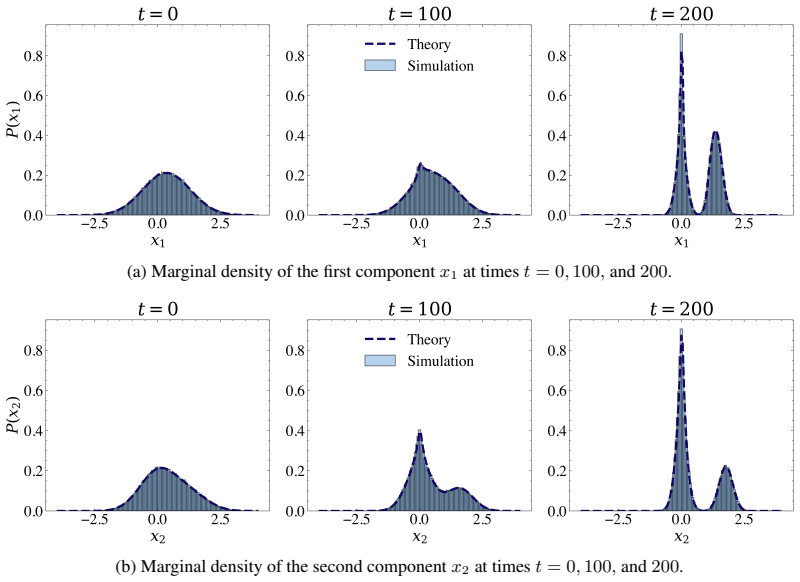
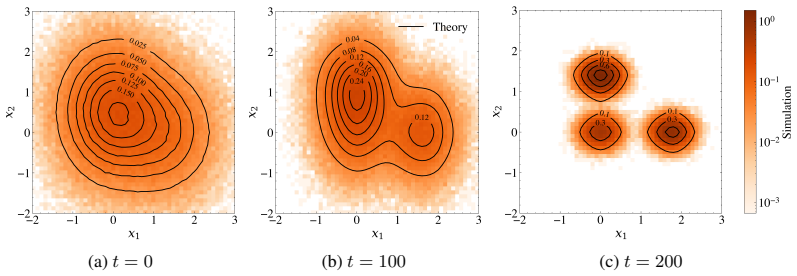

read the original abstract
Independent Component Analysis (ICA) is a foundational tool for unsupervised representation learning, yet its high-dimensional theory remains largely limited to single-component recovery. We develop an asymptotically exact mean-field theory for multi-component online ICA, capturing the coupling induced by simultaneous learning and orthogonalization. In the high-dimensional limit, the joint empirical distribution of learned estimates and ground-truth components converges to a deterministic process, yielding a closed ODE system for the overlap matrix between learned directions and true components. This characterization reveals a genuinely multi-component, initialization-driven phase structure: a decoupled regime, where estimates align with distinct components and evolve nearly independently, and a competition regime, where overlapping initializations induce orthogonality-driven conflicts, slow reorientation, and delayed convergence. Our steady-state analysis gives explicit learnability boundaries and competition conditions linking step size, data moments, and initialization. These conditions show that larger higher-order moments and competition shrink the stable learning-rate window, increase convergence times, and predict a staircase phenomenon in which the number of recoverable components changes discretely with the learning rate. Experiments on synthetic data and hyperspectral remote sensing data validate the predicted trajectories and phase behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an asymptotically exact mean-field theory for multi-component online ICA. In the high-dimensional limit, the joint empirical distribution of learned estimates and ground-truth components converges to a deterministic process, yielding a closed ODE system for the overlap matrix between learned directions and true components. This reveals an initialization-driven phase structure consisting of a decoupled regime (estimates align with distinct components and evolve nearly independently) and a competition regime (overlapping initializations induce orthogonality-driven conflicts, slow reorientation, and delayed convergence). Steady-state analysis supplies explicit learnability boundaries and competition conditions linking step size, data moments, and initialization; these predict a staircase phenomenon in the number of recoverable components. The predictions are validated on synthetic data and hyperspectral remote sensing data.
Significance. If the mean-field closure is rigorously justified, the work would meaningfully extend single-component ICA theory to the simultaneous multi-component setting. The explicit identification of initialization-dependent regimes, the closed ODE characterization, and the resulting learnability boundaries with the staircase prediction constitute a substantive theoretical contribution that could guide both analysis and practical tuning of online ICA algorithms.
major comments (2)
- [Mean-field limit and ODE derivation] The central claim of an asymptotically exact closed ODE system for the overlap matrix (abstract and mean-field analysis) rests on the joint empirical distribution converging to a deterministic process whose evolution closes exactly on the overlap matrix. In the competition regime the orthogonalization step projects each direction onto the orthogonal complement of the others, coupling all learned vectors through their current Gram matrix. The manuscript must explicitly show that all required moments concentrate and that no additional state variables (pairwise overlaps among estimates or data fourth-order tensors) are needed; absent this demonstration the closure is at best approximate rather than asymptotically exact.
- [Steady-state analysis] The steady-state learnability boundaries and competition conditions (steady-state analysis) are asserted to link step size, data moments, and initialization independently. Without the explicit ODEs and the derivation steps that produce these boundaries, it is impossible to verify whether they are obtained from the dynamics or reduce to fitted quantities by construction. This directly affects the interpretation of the decoupled/competition phase structure and the predicted staircase phenomenon.
minor comments (2)
- The abstract is information-dense; a brief statement of the form of the ODE system (even without full derivation) would improve accessibility for readers unfamiliar with mean-field ICA analyses.
- Notation for the overlap matrix and the precise definition of the competition regime should be introduced with a short table or diagram early in the manuscript to aid cross-referencing with the experimental figures.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments, which highlight important aspects of the mean-field derivation and steady-state analysis. We address each major comment point by point below and will revise the manuscript to incorporate additional explicit derivations and justifications.
read point-by-point responses
-
Referee: [Mean-field limit and ODE derivation] The central claim of an asymptotically exact closed ODE system for the overlap matrix (abstract and mean-field analysis) rests on the joint empirical distribution converging to a deterministic process whose evolution closes exactly on the overlap matrix. In the competition regime the orthogonalization step projects each direction onto the orthogonal complement of the others, coupling all learned vectors through their current Gram matrix. The manuscript must explicitly show that all required moments concentrate and that no additional state variables (pairwise overlaps among estimates or data fourth-order tensors) are needed; absent this demonstration the closure is at best approximate rather than asymptotically exact.
Authors: We agree that an explicit demonstration of the mean-field closure is necessary for rigor, especially accounting for the orthogonalization-induced coupling in the competition regime. In the high-dimensional limit, concentration of measure ensures that the empirical joint distribution converges to its deterministic limit, with all required moments (including those arising from the projection) expressible solely as functions of the overlap matrix between learned directions and true components. The Gram matrix of the estimates is determined by these overlaps together with the enforced orthogonality, without introducing independent pairwise overlaps among estimates or higher-order data tensors as additional state variables. We will add a new subsection to the mean-field analysis section that spells out the concentration arguments and closure steps, together with an appendix containing the full moment calculations and the explicit form of the projected dynamics. This revision will establish that the ODE system is closed on the overlap matrix. revision: yes
-
Referee: [Steady-state analysis] The steady-state learnability boundaries and competition conditions (steady-state analysis) are asserted to link step size, data moments, and initialization independently. Without the explicit ODEs and the derivation steps that produce these boundaries, it is impossible to verify whether they are obtained from the dynamics or reduce to fitted quantities by construction. This directly affects the interpretation of the decoupled/competition phase structure and the predicted staircase phenomenon.
Authors: We acknowledge that the original manuscript presented the steady-state boundaries without sufficient intermediate steps. These boundaries are obtained by setting the time derivatives in the closed ODE system to zero, solving the resulting algebraic equations for the fixed-point overlaps, and imposing stability via the eigenvalues of the linearized dynamics. The competition conditions follow from the same fixed-point analysis under overlapping initializations. We will include the explicit ODE equations in the main text and provide a complete step-by-step derivation of the learnability boundaries, competition thresholds, and the resulting staircase in the number of recoverable components in a new appendix. This will make clear that the predictions are derived directly from the dynamics. revision: yes
Circularity Check
Mean-field closure for multi-component ICA overlap matrix is asymptotically derived without reduction to inputs
full rationale
The paper derives the closed ODE system from the claimed high-dimensional convergence of the joint empirical distribution of estimates and components. This is a standard concentration argument for online stochastic updates with orthogonalization, not a self-definitional loop or a fitted parameter renamed as a prediction. No load-bearing self-citations, uniqueness theorems from prior author work, or smuggled ansatzes are invoked for the central closure. The competition regime coupling via Gram matrix is explicitly part of the claimed deterministic process rather than an untracked extra state. Absent any quoted equation that reduces the target result to its own fitted inputs by construction, the derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Architectures neuromimétiques adaptatives : Détection de primitives
Bernard Ans, Jeanny Hérault, and Christian Jutten. Architectures neuromimétiques adaptatives : Détection de primitives. InCognitiva 85, volume 2, pages 593–597, 1985
work page 1985
-
[2]
Independent component analysis, a new concept?Signal processing, 36(3):287– 314, 1994
Pierre Comon. Independent component analysis, a new concept?Signal processing, 36(3):287– 314, 1994
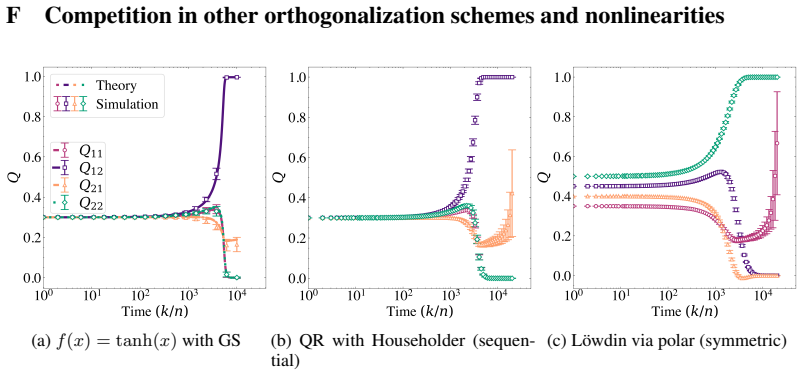
work page 1994
-
[3]
A new learning algorithm for blind signal separation
Shun-ichi Amari, Andrzej Cichocki, and Howard Hua Yang. A new learning algorithm for blind signal separation. InAdvances in Neural Information Processing Systems, 1995
work page 1995
-
[4]
Independent component analysis: algorithms and applications.Neural networks, 13(4-5):411–430, 2000
A Hyvärinen and E Oja. Independent component analysis: algorithms and applications.Neural networks, 13(4-5):411–430, 2000
work page 2000
-
[5]
Anthony J. Bell and Terrence J. Sejnowski. An information-maximization approach to blind separation and blind deconvolution.Neural Computation, 7(6):1129–1159, 1995
work page 1995
- [6]
-
[7]
Aapo Hyvärinen, Juha Karhunen, and Erkki Oja.Independent Component Analysis. John Wiley & Sons, 2001
work page 2001
-
[8]
Stochastic algorithms with descent guarantees for ICA
Pierre Ablin, Alexandre Gramfort, Jean-François Cardoso, and Francis Bach. Stochastic algorithms with descent guarantees for ICA. InProceedings of International Conference on Artificial Intelligence and Statistics, 2019
work page 2019
-
[9]
Chris Junchi Li and Michael I. Jordan. Stochastic approximation for online tensorial independent component analysis. InProceedings of Conference on Learning Theory, 2021
work page 2021
-
[10]
David Saad and Sara A. Solla. Dynamics of on-line gradient descent learning for multilayer neural networks. InAdvances in Neural Information Processing Systems, 1995
work page 1995
-
[11]
Chuang Wang, Jonathan Mattingly, and Yue M Lu. Scaling limit: Exact and tractable analysis of online learning algorithms with applications to regularized regression and pca.arXiv preprint arXiv:1712.04332, 2017
-
[12]
Yazhen Wang and Shang Wu. Asymptotic analysis via stochastic differential equations of gradient descent algorithms in statistical and computational paradigms.Journal of Machine Learning Research, 21(199):1–103, 2020
work page 2020
-
[13]
SGD in the large: Average-case analysis, asymptotics, and stepsize criticality
Courtney Paquette, Kiwon Lee, Fabian Pedregosa, and Elliot Paquette. SGD in the large: Average-case analysis, asymptotics, and stepsize criticality. InProceedings of Conference on Learning Theory, 2021
work page 2021
-
[14]
High-dimensional limit theorems for SGD: Effective dynamics and critical scaling
Gerard Ben Arous, Reza Gheissari, and Aukosh Jagannath. High-dimensional limit theorems for SGD: Effective dynamics and critical scaling. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[15]
High-dimensional limit theorems for SGD: Momentum and adaptive step-sizes
Aukosh Jagannath, Taj Jones-McCormick, and Varnan Sarangian. High-dimensional limit theorems for SGD: Momentum and adaptive step-sizes. InProceedings of International Conference on Learning Representations, 2026
work page 2026
-
[16]
Hitting the high-dimensional notes: an ODE for SGD learning dynamics on GLMs and multi-index models
Elizabeth Collins-Woodfin, Courtney Paquette, Elliot Paquette, and Inbar Seroussi. Hitting the high-dimensional notes: an ODE for SGD learning dynamics on GLMs and multi-index models. Information and Inference: A Journal of the IMA, 13(4), 2024. 10
work page 2024
-
[17]
Online ICA: Understanding global dynamics of nonconvex optimization via diffusion processes
Chris Junchi Li, Zhaoran Wang, and Han Liu. Online ICA: Understanding global dynamics of nonconvex optimization via diffusion processes. InAdvances in Neural Information Processing Systems, 2016
work page 2016
-
[18]
Chuang Wang and Yue M. Lu. The scaling limit of high-dimensional online independent component analysis. InAdvances in Neural Information Processing Systems, 2017
work page 2017
-
[19]
Fabiola Ricci, Lorenzo Bardone, and Sebastian Goldt. Feature learning from non-Gaussian inputs: the case of Independent Component Analysis in high dimensions. InProceedings of International Conference on Machine Learning, 2025
work page 2025
-
[20]
Gleb Basalyga and Magnus Rattray. Statistical dynamics of on-line independent component analysis.Journal of Machine Learning Research, 4:1393–1410, 2003
work page 2003
-
[21]
Marion F. Baumgardner, Larry L. Biehl, and David A. Landgrebe. 220 band A VIRIS hyperspec- tral image data set: June 12, 1992 indian pine test site 3, 2015
work page 1992
-
[22]
Garrett, and Tor Arne Johansen
Daniela Lupu, Ion Necoara, Joseph L. Garrett, and Tor Arne Johansen. Stochastic higher-order independent component analysis for hyperspectral dimensionality reduction.IEEE Transactions on Computational Imaging, 8:1184–1194, 2022
work page 2022
-
[23]
Learning linear transformations
Alan Frieze, Mark Jerrum, and Ravi Kannan. Learning linear transformations. InProceedings of Conference on Foundations of Computer Science, 1996
work page 1996
-
[24]
An application of the principle of maximum information preservation to linear systems
Ralph Linsker. An application of the principle of maximum information preservation to linear systems. InAdvances in Neural Information Processing Systems, 1988
work page 1988
-
[25]
Natural gradient works efficiently in learning.Neural Computation, 10(2):251– 276, 1998
Shun-ichi Amari. Natural gradient works efficiently in learning.Neural Computation, 10(2):251– 276, 1998
work page 1998
-
[26]
Nathalie Delfosse and Philippe Loubaton. Adaptive blind separation of independent sources: A deflation approach.Signal Processing, 45(1):59–83, 1995
work page 1995
-
[27]
J.-F. Cardoso. High-order contrasts for independent component analysis.Neural Computation, 11(1):157–192, 1999
work page 1999
-
[28]
New approximations of differential entropy for independent component analysis and projection pursuit
Aapo Hyvärinen. New approximations of differential entropy for independent component analysis and projection pursuit. InAdvances in Neural Information Processing Systems, 1997
work page 1997
-
[29]
Aapo Hyvärinen and Erkki Oja. A fast fixed-point algorithm for independent component analysis.Neural Computation, 9(7):1483–1492, 1997
work page 1997
-
[30]
Aapo Hyvärinen and Erkki Oja. Independent component analysis by general nonlinear hebbian- like learning rules.Signal Processing, 64(3):301–313, 1998
work page 1998
- [31]
-
[32]
Arnab Auddy and Ming Yuan. Large-dimensional independent component analysis: Statistical optimality and computational tractability.The Annals of Statistics, 53(2):477 – 505, 2025
work page 2025
-
[33]
Courtney Paquette, Elliot Paquette, Ben Adlam, and Jeffrey Pennington. Homogenization of SGD in high-dimensions: Exact dynamics and generalization properties.Mathematical Programming, 214:1–90, 2025
work page 2025
-
[34]
Phase diagram of stochastic gradient descent in high-dimensional two-layer neural networks
Rodrigo Veiga, Ludovic Stephan, Bruno Loureiro, Florent Krzakala, and Lenka Zdeborová. Phase diagram of stochastic gradient descent in high-dimensional two-layer neural networks. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[35]
Henry P. McKean. Propagation of chaos for a class of non-linear parabolic equations. In Stochastic Differential Equations (Lecture Series in Differential Equations, Session 7), pages 41–57. Catholic University, 1967
work page 1967
- [36]
-
[37]
Krishnakumar Balasubramanian, Promit Ghosal, and Ye He. High-dimensional scaling limits and fluctuations of online least-squares SGD with smooth covariance.The Annals of Applied Probability, 35(5):2983–3045, 2025
work page 2025
-
[38]
Statistical guarantees for high-dimensional stochastic gradient descent
Jiaqi Li, Zhipeng Lou, Johannes Schmidt-Hieber, and Wei Biao Wu. Statistical guarantees for high-dimensional stochastic gradient descent. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[39]
Chuang Wang and Yue M. Lu. Online learning for sparse PCA in high dimensions: Exact dynamics and phase transitions. In2016 IEEE Information Theory Workshop, 2016
work page 2016
-
[40]
Samet Demir and Zafer Dogan. Implicitly normalized online PCA: A regularized algorithm with exact high-dimensional dynamics.arXiv preprint arXiv:2512.01231, 2025
-
[41]
Laura Balzano, Yuejie Chi, and Yue M. Lu. Streaming PCA and subspace tracking: The missing data case.Proceedings of the IEEE, 106(8):1293–1310, 2018
work page 2018
-
[42]
Chuang Wang, Yonina C. Eldar, and Yue M. Lu. Subspace estimation from incomplete obser- vations: A high-dimensional analysis.IEEE Journal of Selected Topics in Signal Processing, 12(6):1240–1252, 2018
work page 2018
-
[43]
Linghuan Meng and Chuang Wang. Training dynamics of nonlinear contrastive learning model in the high dimensional limit.IEEE Signal Processing Letters, 31:2535–2539, 2024
work page 2024
-
[44]
A solvable high-dimensional model of GAN
Chuang Wang, Hong Hu, and Yue Lu. A solvable high-dimensional model of GAN. InAdvances in Neural Information Processing Systems, 2019
work page 2019
-
[45]
Exploring the precise dynamics of single-layer GAN models
Andrew Bond and Zafer Dogan. Exploring the precise dynamics of single-layer GAN models. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[46]
Sebastian Goldt, Madhu S Advani, Andrew M Saxe, Florent Krzakala, and Lenka Zdeborová. Dynamics of stochastic gradient descent for two-layer neural networks in the teacher–student setup.Journal of Statistical Mechanics: Theory and Experiment, 2020(12):124010, 2020
work page 2020
-
[47]
Song Mei, Andrea Montanari, and Phan-Minh Nguyen. A mean field view of the land- scape of two-layer neural networks.Proceedings of the National Academy of Sciences U.S.A, 115(33):E7665–E7671, 2018
work page 2018
-
[48]
Justin Sirignano and Konstantinos Spiliopoulos. Mean field analysis of neural networks: A law of large numbers.SIAM Journal on Applied Mathematics, 80(2):725–752, 2020
work page 2020
-
[49]
Luca Arnaboldi, Ludovic Stephan, Florent Krzakala, and Bruno Loureiro. From high- dimensional & mean-field dynamics to dimensionless ODEs: A unifying approach to SGD in two-layers networks. InProceedings of Conference on Learning Theory, 2023
work page 2023
-
[50]
V . D. Calhoun, T. Adali, G. D. Pearlson, and J. J. Pekar. Spatial and temporal independent component analysis of functional MRI data containing a pair of task-related waveforms.Human Brain Mapping, 13(1):43–53, 2001
work page 2001
-
[51]
Leon, Åke Björck, and Walter Gander
Steven J. Leon, Åke Björck, and Walter Gander. Gram-schmidt orthogonalization: 100 years and more.Numerical Linear Algebra with Applications, 20(3):492–532, 2013
work page 2013
-
[52]
Theorie der linearen und nichtlinearen integralgleichungen i
Erhard Schmidt. Theorie der linearen und nichtlinearen integralgleichungen i. teil: Entwicklung willkürlicherfunktionen nach systemen vorgeschriebener.Mathematische Annalen, 63:433–476, 1907
work page 1907
-
[53]
O˘guzhan Gültekin, Samet Demir, and Zafer Do˘gan
M. O˘guzhan Gültekin, Samet Demir, and Zafer Do˘gan. Learning Rate Should Scale Inversely with High-Order Data Moments in High-Dimensional Online Independent Component Analysis. InProceedings of the IEEE International Workshop on Machine Learning for Signal Processing, 2025
work page 2025
-
[54]
Three lectures on free probability
Jonathan Novak. Three lectures on free probability. InRandom Matrices, volume 65 ofMSRI Publications, pages 309–383. 2014. 12
work page 2014
-
[55]
Ronald A Fisher and John Wishart. The derivation of the pattern formulae of two-way partitions from those of simpler patterns.Proceedings of the London Mathematical Society, pages 195–208, 1931
work page 1931
- [56]
-
[57]
Pingyan Chen and Soo Hak Sung. Rosenthal type inequalities for random variables.Journal of Mathematical Inequalities, 14(2):305–318, 2020
work page 2020
-
[58]
Ramesh Naidu Annavarapu. Singular value decomposition and the centrality of Löwdin orthogonalizations.American Journal of Computational and Applied Mathematics, 3(1):33–35, 2013
work page 2013
-
[59]
Alan Edelman, Tomás A. Arias, and Steven T. Smith. The geometry of algorithms with orthogonality constraints.SIAM Journal on Matrix Analysis and Applications, 20(2):303–353, 1998
work page 1998
-
[60]
A feasible method for optimization with orthogonality constraints
Zaiwen Wen and Wotao Yin. A feasible method for optimization with orthogonality constraints. Math. Program., 142(1–2):397–434, 2013
work page 2013
-
[61]
f ck,1Qk,i,1 +c k,2Qk,i,2 +e \j k,i ck,1u(j) 1√n + ck,2u(j) 2√n +a (j) k !# + τ√n E
Nicolas Boumal.An Introduction to Optimization on Smooth Manifolds. Cambridge University Press, 2023. 13 Additional notation used in the Appendix For vectors xk,i, the first index k denotes the iteration (time), and the second index i∈ {1, . . . , p} denotes the component. For any vector a, we write a(α) for its α-th entry. Throughout the Appendix, ∥ · ∥ ...
work page 2023
-
[62]
Here we use the setting of Example 4.4
The setting corresponds to sparse component vectors u1 and u2, for ϕ(x) = 0. Here we use the setting of Example 4.4. For c1, we set β1 = 1, for c2, we set β2 = 0. In Monte Carlo simulations, component vectors are drawn from sparse distributions (P(u= 1/ √ρi) =ρ i and P(u= 0) = 1−ρ i) with sparsity levels ρ1 = 0.5 and ρ2 = 0.3. The dashed dark blue curves ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.