Recognition: 3 theorem links
· Lean TheoremCONTRA: Conformal Prediction Region via Normalizing Flow Transformation
Pith reviewed 2026-05-12 00:57 UTC · model grok-4.3
The pith
Normalizing flows let conformal prediction produce sharp multi-dimensional regions by using latent-space distance as the nonconformity score.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
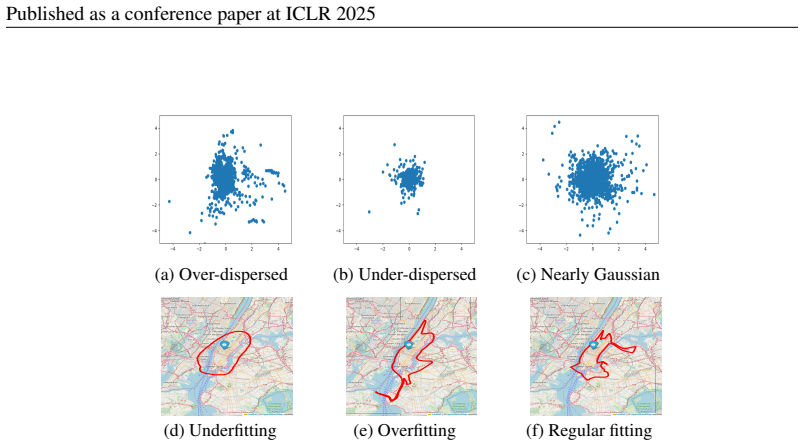
CONTRA utilizes the latent spaces of normalizing flows to define nonconformity scores based on distances from the center. This allows for the mapping of high-density regions in latent space to sharp prediction regions in the output space, surpassing traditional hyperrectangular or elliptical conformal regions. For scenarios where other predictive models are favored, a simple normalizing flow trained on residuals extends the same guarantee to any base model while preserving exact coverage probability.
What carries the argument
The invertible mapping of a normalizing flow that converts Euclidean distance from the latent-space origin into a nonconformity score, so that a fixed-radius ball in latent space becomes a high-density conformal region after the inverse transform.
If this is right
- Multi-dimensional conformal sets can take shapes that follow the actual data density instead of being forced into boxes or ellipses.
- The exact finite-sample coverage guarantee of conformal prediction carries over unchanged through the flow transform.
- Any existing point predictor can be equipped with a conformal region simply by fitting a flow to its residuals.
- The same latent-distance construction supplies both prediction regions and a form of conditional density estimate.
Where Pith is reading between the lines
- If the flow approximates the true conditional distribution closely, the resulting regions should approach the smallest possible volume among all sets that meet the coverage target.
- The approach could be applied to other invertible maps, such as certain diffeomorphisms or autoregressive transforms, without changing the core argument.
- In high-dimensional regression tasks the method may reduce the volume of uncertainty sets enough to improve downstream decision-making that depends on those sets.
Load-bearing premise
The normalizing flow must be trained well enough that the latent-space distance remains a valid nonconformity measure whose coverage guarantee survives the invertible mapping back to data space.
What would settle it
Train the flow on a held-out calibration set, form the conformal regions at target coverage 0.9, and measure the empirical fraction of test points that fall inside; if this fraction falls below 0.9 by more than sampling error, the coverage claim fails.
Figures






read the original abstract
Density estimation and reliable prediction regions for outputs are crucial in supervised and unsupervised learning. While conformal prediction effectively generates coverage-guaranteed regions, it struggles with multi-dimensional outputs due to reliance on one-dimensional nonconformity scores. To address this, we introduce CONTRA: CONformal prediction region via normalizing flow TRAnsformation. CONTRA utilizes the latent spaces of normalizing flows to define nonconformity scores based on distances from the center. This allows for the mapping of high-density regions in latent space to sharp prediction regions in the output space, surpassing traditional hyperrectangular or elliptical conformal regions. Further, for scenarios where other predictive models are favored over flow-based models, we extend CONTRA to enhance any such model with a reliable prediction region by training a simple normalizing flow on the residuals. We demonstrate that both CONTRA and its extension maintain guaranteed coverage probability and outperform existing methods in generating accurate prediction regions across various datasets. We conclude that CONTRA is an effective tool for (conditional) density estimation, addressing the under-explored challenge of delivering multi-dimensional prediction regions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CONTRA, a conformal prediction method that trains a normalizing flow and defines nonconformity scores as Euclidean distances from the origin in the resulting latent space. The (1-α) quantile of these scores on a calibration set is mapped back through the inverse flow to produce a prediction region in the original output space. An extension trains a flow on residuals of an arbitrary base predictor to obtain similar regions. The authors claim that both variants retain the standard marginal coverage guarantee of split conformal prediction while yielding sharper, density-adapted regions than hyperrectangular or elliptical baselines, and they report empirical improvements on several datasets.
Significance. If the coverage argument holds, the approach supplies a practical route to flexible, non-parametric multi-dimensional prediction regions that inherit finite-sample validity from conformal prediction while adapting shape to the learned density. This is a useful addition to the conformal toolkit for settings where rigid region shapes are overly conservative. The residual-flow extension further increases applicability to existing point predictors.
minor comments (3)
- §2 (Method): the statement that the flow is 'fixed before scoring' should be made explicit, including whether its parameters are estimated exclusively on the training split and never updated with calibration data, to make the exchangeability argument immediate to the reader.
- Experiments section: the tables reporting region volumes or coverage should include the number of random seeds or cross-validation folds and any standard errors, given that flow training introduces additional stochasticity.
- Notation: define the symbols for the latent variable z, the flow parameters θ, and the nonconformity score s clearly at first use; the current presentation mixes data-space and latent-space quantities without a dedicated notation table.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work and for recommending minor revision. The report correctly captures the core idea of CONTRA and its residual-flow extension, as well as the claimed marginal coverage guarantee inherited from split conformal prediction. We provide point-by-point responses to the major comments below.
Circularity Check
No significant circularity
full rationale
The paper's central derivation applies standard split conformal prediction to nonconformity scores defined as Euclidean distances from the origin in the latent space of a pre-trained normalizing flow (or a flow on residuals). The coverage guarantee follows directly from the exchangeability of calibration and test scores under the usual rank-based argument, which holds regardless of how well the flow approximates the data density; the flow only determines region shape and volume after the threshold is obtained. No equation reduces a claimed prediction to a fitted parameter by construction, no uniqueness theorem is imported from self-citation, and the invertible mapping preserves the marginal coverage property without introducing data-dependent circularity between flow training and calibration scores.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCONTRA utilizes the latent spaces of normalizing flows to define nonconformity scores based on distances from the center... ˆE = {z : ||z|| ≤ r_{1-α}} ... ˆC(x_{n+1}) = t_θ̂(Ê, x_{n+1})
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearthe conformal ball of size (1-α) ... mapping of high-density regions in latent space
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat ≃ Nat recovery unclearResCONTRA ... training a simple normalizing flow on the residuals
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [3]
-
[4]
Density estimation using Real NVP
Density estimation using real nvp , author=. arXiv preprint arXiv:1605.08803 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Journal of the American Statistical Association , volume=
Distribution-free predictive inference for regression , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
work page 2018
-
[6]
Advances in neural information processing systems , volume=
Conformalized quantile regression , author=. Advances in neural information processing systems , volume=
-
[7]
Conformal and Probabilistic Prediction and Applications , pages=
Conformal uncertainty sets for robust optimization , author=. Conformal and Probabilistic Prediction and Applications , pages=. 2021 , organization=
work page 2021
-
[8]
Annals of Mathematics and Artificial Intelligence , volume=
A conformal prediction approach to explore functional data , author=. Annals of Mathematics and Artificial Intelligence , volume=. 2015 , publisher=
work page 2015
-
[9]
Algorithmic learning in a random world , author=. 2005 , publisher=
work page 2005
-
[10]
Inductive confidence machines for regression , author=. Machine Learning: ECML 2002: 13th European Conference on Machine Learning Helsinki, Finland, August 19--23, 2002 Proceedings 13 , pages=. 2002 , organization=
work page 2002
-
[11]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
A gentle introduction to conformal prediction and distribution-free uncertainty quantification , author=. arXiv preprint arXiv:2107.07511 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Conformal and Probabilistic Prediction with Applications , pages=
Ellipsoidal conformal inference for multi-target regression , author=. Conformal and Probabilistic Prediction with Applications , pages=. 2022 , organization=
work page 2022
-
[13]
Learning Likelihoods with Conditional Normalizing Flows , author=. ArXiv , year=
-
[14]
Journal of Machine Learning Research , year =
George Papamakarios and Eric Nalisnick and Danilo Jimenez Rezende and Shakir Mohamed and Balaji Lakshminarayanan , title =. Journal of Machine Learning Research , year =
-
[15]
NICE: Non-linear Independent Components Estimation
Nice: Non-linear independent components estimation , author=. arXiv preprint arXiv:1410.8516 , year=
work page internal anchor Pith review arXiv
-
[16]
Flexible distribution-free conditional predictive bands using density estimators , author =. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =. 2020 , editor =
work page 2020
-
[17]
arXiv preprint arXiv:2206.06584 , year=
Probabilistic conformal prediction using conditional random samples , author=. arXiv preprint arXiv:2206.06584 , year=
-
[18]
Pubblicazioni del R Istituto Superiore di Scienze Economiche e Commericiali di Firenze , volume=
Teoria statistica delle classi e calcolo delle probabilita , author=. Pubblicazioni del R Istituto Superiore di Scienze Economiche e Commericiali di Firenze , volume=
-
[19]
Journal of the American statistical association , volume=
Multiple comparisons among means , author=. Journal of the American statistical association , volume=. 1961 , publisher=
work page 1961
-
[20]
Journal of Machine Learning Research , volume=
Cd-split and hpd-split: Efficient conformal regions in high dimensions , author=. Journal of Machine Learning Research , volume=
-
[21]
Multi-target regression via input space expansion: treating targets as inputs , volume=
Spyromitros-Xioufis, Eleftherios and Tsoumakas, Grigorios and Groves, William and Vlahavas, Ioannis , year=. Multi-target regression via input space expansion: treating targets as inputs , volume=. Machine Learning , publisher=. doi:10.1007/s10994-016-5546-z , number=
-
[22]
Athanasios Tsanas and Angeliki Xifara , keywords =. Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools , journal =. 2012 , issn =. doi:https://doi.org/10.1016/j.enbuild.2012.03.003 , url =
- [23]
-
[24]
International Conference on Machine Learning , pages=
Neural autoregressive flows , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[25]
Advances in Neural Information Processing Systems , volume=
Residual flows for invertible generative modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Glow: Generative flow with invertible 1x1 convolutions , author=. Advances in neural information processing systems , volume=
-
[27]
Prentic Hall of India Private Limited, New delhi , year=
Topology , author=. Prentic Hall of India Private Limited, New delhi , year=
-
[28]
Proceedings of the National Academy of Sciences , volume=
Distributional conformal prediction , author=. Proceedings of the National Academy of Sciences , volume=. 2021 , publisher=
work page 2021
-
[29]
Dalmasso, N. and Pospisil, T. and Lee, A.B. and Izbicki, R. and Freeman, P.E. and Malz, A.I. , year=. Conditional density estimation tools in python and R with applications to photometric redshifts and likelihood-free cosmological inference , volume=. doi:10.1016/j.ascom.2019.100362 , journal=
-
[30]
Approximating conditional distribution functions using dimension reduction , volume=
Hall, Peter and Yao, Qiwei , year=. Approximating conditional distribution functions using dimension reduction , volume=. The Annals of Statistics , publisher=. doi:10.1214/009053604000001282 , number=
-
[31]
arXiv preprint arXiv:1401.3632 , year=
Bayesian conditional density filtering , author=. arXiv preprint arXiv:1401.3632 , year=
-
[32]
Sbornik: Mathematics , volume=
Triangular transformations of measures , author=. Sbornik: Mathematics , volume=. 2005 , publisher=
work page 2005
-
[33]
Advances in neural information processing systems , volume=
Neural spline flows , author=. Advances in neural information processing systems , volume=
-
[34]
Journal of Machine Learning Research , volume=
Calibrated multiple-output quantile regression with representation learning , author=. Journal of Machine Learning Research , volume=
- [35]
- [36]
-
[37]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.