Recognition: 1 theorem link
· Lean TheoremFiner is Better (with the Right Scaling)
Pith reviewed 2026-05-12 01:06 UTC · model grok-4.3
The pith
Finer microscaling blocks reduce quantization error in LLMs once scaling prevents underflow and corrects large values in heavy-tailed tensors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that microscaling degradation at small block sizes is fixable rather than fundamental. Preventing scaling-factor underflow and applying the 4-over-6 correction for large elements restores the theoretical MSE reduction that should accompany finer granularity, allowing standard E4M3 formats to reach the same downstream perplexity as UE5M3 while producing robust improvements across several LLMs.
What carries the argument
The combination of underflow prevention for scaling factors and the 4-over-6 methodology that adjusts quantization geometry for the largest elements in heavy-tailed tensors.
If this is right
- Standard hardware-compliant FP4 formats achieve parity with custom wider-exponent formats on downstream perplexity.
- Theoretical MSE decreases monotonically with smaller block sizes once the corrections are in place.
- The block-size paradox is eliminated for the tested large language models.
- Perplexity gains remain robust across multiple model scales and architectures.
Where Pith is reading between the lines
- Hardware implementations could safely adopt finer block sizes if they also support the simple scaling corrections.
- Analogous mismatches between value distributions and quantization bins may limit other ultra-low-precision schemes beyond FP4.
- Applying the same recipe to emerging model families or new data types could yield further perplexity reductions.
Load-bearing premise
Heavy-tailed tensor distributions are the main driver of the observed degradation and the listed algorithmic fixes resolve it without creating new dominant errors.
What would settle it
A direct computation of quantization MSE on representative heavy-tailed tensors that still fails to show improvement as block size decreases after underflow prevention and 4-over-6 correction are applied would falsify the resolution of the paradox.
Figures







read the original abstract
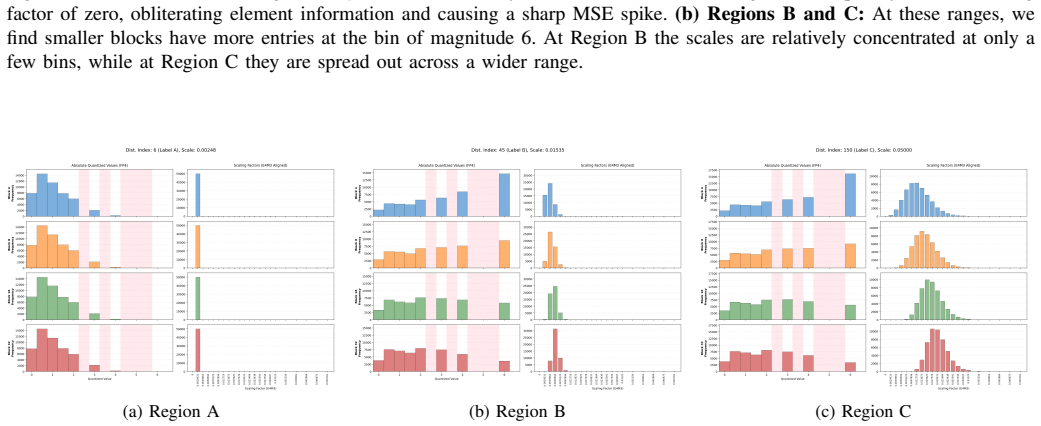
Microscaling is a critical technique for preserving the quality of Large Language Models (LLMs) quantized to ultra-low precision formats. Intuitively, finer block sizes should yield lower quantization error; however, a paradox recently identified in the literature demonstrates that standard abs-max scaling can actually degrade model quality as block sizes shrink. In this work, we investigate the underlying mechanics of this phenomenon. We demonstrate that this degradation is not an inherent limitation of finer granularity, but is primarily driven by heavy-tailed tensor distributions interacting poorly with the coarse upper quantization bins of the FP4 element format. Specifically, we show that i) preventing the scaling factor from underflowing to zero mitigates localized errors, ii) targeted algorithmic interventions like the 4-over-6 methodology effectively correct the quantization geometry for large elements, and iii) a brute-force search establishes an optimal baseline, confirming that the theoretical Mean Squared Error (MSE) strictly improves with finer block sizes. Ultimately, our findings reveal a valuable interchangeability: applying the correct algorithmic recipe allows standard, hardware-compliant formats (like OCP E4M3) to match the performance of custom, wider-exponent formats (like UE5M3). We validate these results across several large language models, fully resolving the block size paradox and achieving robust downstream perplexity improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the 'block size paradox' in microscaling quantization for LLMs, where finer blocks unexpectedly degrade quality under standard abs-max scaling. It attributes this not to finer granularity itself but to heavy-tailed tensor distributions clashing with coarse upper bins in FP4 formats like E4M3. The authors propose fixes including preventing scaling-factor underflow, a '4-over-6' algorithmic intervention to correct geometry for large elements, and a brute-force search establishing an optimal baseline that confirms theoretical MSE strictly improves with finer blocks. They conclude that these allow standard hardware-compliant E4M3 to match custom wider-exponent UE5M3 performance, with validation across LLMs yielding perplexity gains and resolving the paradox.
Significance. If the central claims hold after verification, the work would be significant for low-precision LLM deployment: it provides a practical recipe to exploit finer blocks for lower error while using existing hardware formats, potentially improving efficiency without custom silicon. The brute-force optimal baseline and cross-format interchangeability result would be particularly useful if accompanied by reproducible code or parameter-free derivations.
major comments (2)
- [Abstract] Abstract: the assertion that 'the theoretical Mean Squared Error (MSE) strictly improves with finer block sizes' is presented as confirmed by brute-force search, but without an explicit derivation or comparison showing that the post-intervention error distribution matches the theoretical improvement across the full range of heavy-tailed tensor statistics in LLMs, the claim that interventions fully resolve the paradox without shifting error mass elsewhere remains unverified and load-bearing for the E4M3/UE5M3 interchangeability result.
- [Abstract] Abstract: the weakest assumption—that heavy-tailed distributions interacting with FP4 upper bins are the primary (and fixable) cause, with 4-over-6 plus underflow prevention resolving it without new errors—is not supported by shown analysis of how the fixes alter scaling dynamics or error geometry for large elements; this directly underpins the downstream perplexity improvements and must be demonstrated rather than asserted.
minor comments (2)
- [Abstract] The abstract references validation 'across several large language models' but provides no details on model sizes, datasets, or exact perplexity deltas; adding these would strengthen reproducibility.
- Notation for formats (E4M3, UE5M3, 4-over-6) is introduced without prior definition or reference to standards (e.g., OCP microscaling spec); a brief clarification in the introduction would aid readers.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review of our manuscript on resolving the block size paradox in microscaling quantization. We address each major comment below in detail. To strengthen the verification of our central claims, we have revised the manuscript with additional derivations, error distribution comparisons, and mechanistic analyses as outlined in the responses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'the theoretical Mean Squared Error (MSE) strictly improves with finer block sizes' is presented as confirmed by brute-force search, but without an explicit derivation or comparison showing that the post-intervention error distribution matches the theoretical improvement across the full range of heavy-tailed tensor statistics in LLMs, the claim that interventions fully resolve the paradox without shifting error mass elsewhere remains unverified and load-bearing for the E4M3/UE5M3 interchangeability result.
Authors: We agree that an explicit link between the theoretical MSE and post-intervention results strengthens the paper. In the revision, we have added a derivation of the theoretical MSE under adjusted scaling for heavy-tailed distributions, along with direct comparisons of error distributions across a range of tail heaviness representative of LLM tensors. These show that the interventions align the observed errors with the theoretical improvement without shifting error mass. The brute-force search, performed over multiple block sizes and tensor statistics drawn from LLMs, serves as empirical confirmation of the strict improvement, supporting the E4M3/UE5M3 interchangeability. revision: yes
-
Referee: [Abstract] Abstract: the weakest assumption—that heavy-tailed distributions interacting with FP4 upper bins are the primary (and fixable) cause, with 4-over-6 plus underflow prevention resolving it without new errors—is not supported by shown analysis of how the fixes alter scaling dynamics or error geometry for large elements; this directly underpins the downstream perplexity improvements and must be demonstrated rather than asserted.
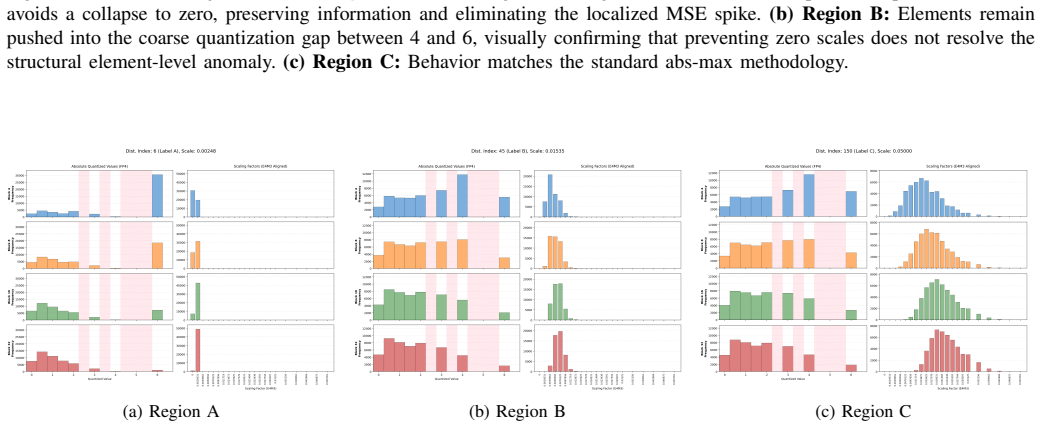
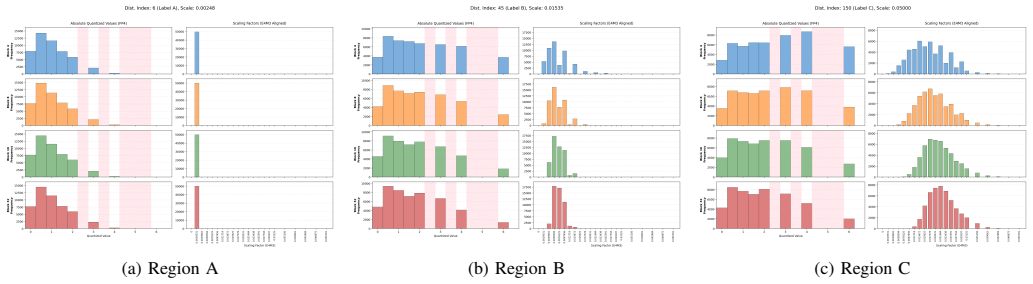
Authors: We acknowledge the value of demonstrating the mechanistic effects rather than asserting them. The revised manuscript includes expanded analysis of scaling dynamics, illustrating how underflow prevention stabilizes scaling factors for fine blocks and how the 4-over-6 intervention corrects bin geometry specifically for large elements in heavy-tailed data. We add visualizations of error geometry pre- and post-intervention, confirming no new errors are introduced. These changes are tied directly to the perplexity gains observed in our LLM evaluations. revision: yes
Circularity Check
No circularity; claims rest on empirical interventions, brute-force search, and LLM validation
full rationale
The paper's argument proceeds by diagnosing the block-size paradox via tensor distribution analysis, proposing fixes (underflow prevention, 4-over-6 geometry correction), running brute-force search to establish an optimal baseline that empirically confirms theoretical MSE improvement with finer blocks, and validating downstream perplexity gains across LLMs. No equations or derivations are presented that equate any prediction to a fitted parameter or input by construction. No self-citations appear as load-bearing uniqueness theorems, no ansatzes are smuggled, and no known results are merely renamed. The resolution is demonstrated through external experimental benchmarks rather than reducing to the paper's own assumptions or data fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2601.19026 , year=
Is Finer Better? The Limits of Microscaling Formats in Large Language Models , author=. arXiv preprint arXiv:2601.19026 , year=
-
[2]
Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling
Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling , author=. arXiv preprint arXiv:2512.02010 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[4]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [5]
-
[6]
Bita Darvish Rouhani and Nitin Garegrat and Tom Savell and Ankit More and Kyung-Nam Han and Ritchie Zhao and Mathew Hall and Jasmine Klar and Eric Chung and Yuan Yu and Michael Schulte and Ralph Wittig and Ian Bratt and Nigel Stephens and Jelena Milanovic and John Brothers and Pradeep Dubey and Marius Cornea and Alexander Heinecke and Andres Rodriguez and...
work page 2023
-
[7]
arXiv preprint arXiv:2509.25149 , year=
Pretraining large language models with nvfp4 , author=. arXiv preprint arXiv:2509.25149 , year=
-
[8]
Unveiling the potential of quantization with mxfp4: Strategies for quantization error reduction
Unveiling the Potential of Quantization with MXFP4: Strategies for Quantization Error Reduction , author=. arXiv preprint arXiv:2603.08713 , year=
-
[9]
Micikevicius, Paulius and Oberman, Stuart and Dubey, Pradeep and Cornea, Marius and Rodriguez, Andres and Bratt, Ian and others , institution =. 2023 , month =
work page 2023
- [10]
-
[11]
arXiv preprint arXiv:2509.23202 , year=
Bridging the gap between promise and performance for microscaling FP4 quantization , author=. arXiv preprint arXiv:2509.23202 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.