Recognition: 2 theorem links
· Lean TheoremBEACON: Cross-Domain Co-Training of Generative Robot Policies via Best-Effort Adaptation
Pith reviewed 2026-05-13 07:48 UTC · model grok-4.3
The pith
BEACON jointly learns a diffusion robot policy and source-sample weights by minimizing a target-generalization objective that reweights data according to instance-level discrepancy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BEACON casts cross-domain co-training as a discrepancy-aware importance-reweighting problem, jointly learning a diffusion-based visuomotor policy and per-sample source weights that minimize an objective informed by target-domain generalization guarantees. Scalable instance-level discrepancy estimators, stochastic alternating updates, and a multi-source balancing extension make the approach practical for high-dimensional sequence policies.
What carries the argument
Discrepancy-aware importance reweighting that couples a diffusion policy with learned source-sample weights inside a generalization-bound objective, optimized by stochastic alternation and instance-level estimators.
If this is right
- The policy trained with learned weights generalizes better to the target domain than policies trained with uniform or fixed-ratio source mixing.
- Feature alignment between source and target domains emerges automatically from the discrepancy minimization without an added alignment loss.
- The same framework extends to multiple heterogeneous source domains by adding a balancing term that prevents any single source from dominating the weights.
- Data efficiency improves because the method extracts useful signal from abundant source trajectories without being harmed by domain mismatch.
Where Pith is reading between the lines
- If the discrepancy estimator scales to longer-horizon tasks, the same weighting idea could be applied to language-conditioned robot policies that mix web-scale video with small robot datasets.
- The implicit alignment result suggests that explicit domain-adversarial losses may be unnecessary once importance weights are optimized against a generalization bound.
- A practical test would be to measure whether the learned weights correlate with human judgments of demonstration quality in the target domain.
Load-bearing premise
That accurate per-sample discrepancy values can be estimated reliably for high-dimensional robot trajectories and that the alternating optimization between policy and weights will converge without instability.
What would settle it
Run the learned policy on the target domain after training; if performance does not exceed the target-only baseline or the fixed-ratio co-training baseline by a statistically significant margin, the reweighting mechanism has not delivered the claimed benefit.
Figures



read the original abstract
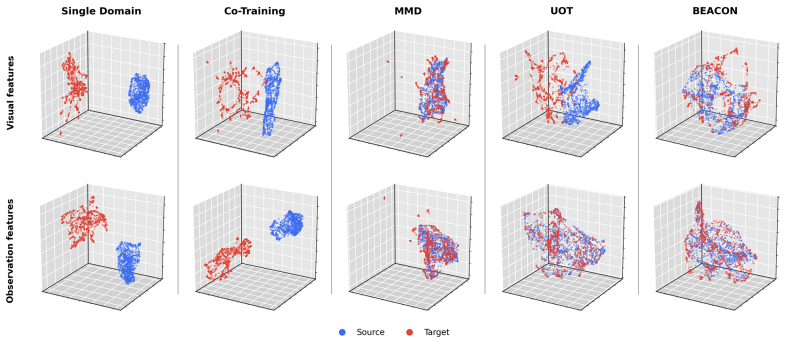
We introduce BEACON--Best-Effort Adaptation for Cross-Domain Co-Training--a theory-driven framework for training generative robot policies with abundant source demonstrations and limited target demonstrations. BEACON casts cross-domain co-training as a discrepancy-aware importance-reweighting problem, jointly learning a diffusion-based visuomotor policy and per-sample source weights that minimize an objective informed by target-domain generalization guarantees. To make best-effort adaptation practical for high-dimensional sequence policies, we develop scalable instance-level discrepancy estimators, stochastic alternating updates for policy and weights, and a multi-source extension that balances heterogeneous source domains. Across sim-to-sim, sim-to-real, and multi-source manipulation settings, BEACON improves robustness and data efficiency over target-only, fixed-ratio co-training, and feature-alignment baselines. Importantly, even without an explicit alignment objective, BEACON achieves feature alignment as an implicit result of discrepancy-aware cross-domain co-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BEACON, a theory-driven framework for cross-domain co-training of diffusion-based visuomotor policies. It formulates the problem as discrepancy-aware importance reweighting, jointly optimizing a generative policy and per-sample source weights to minimize an objective derived from target-domain generalization bounds. The approach includes scalable instance-level discrepancy estimators, stochastic alternating updates, and a multi-source extension. Experiments across sim-to-sim, sim-to-real, and multi-source manipulation tasks show improved robustness and data efficiency over target-only training, fixed-ratio co-training, and feature-alignment baselines, with implicit feature alignment emerging from the reweighting process.
Significance. If the discrepancy estimators and alternating optimization prove stable and unbiased, BEACON would provide a principled, bound-informed alternative to ad-hoc domain adaptation in robot policy learning, potentially improving data efficiency when target demonstrations are scarce. The implicit alignment result and multi-source handling are notable strengths if empirically robust.
major comments (2)
- [Scalable instance-level discrepancy estimators] The scalability claim for instance-level discrepancy estimators on high-dimensional visuomotor trajectories (long sequences of images and actions) lacks explicit bias or variance bounds under the diffusion training distribution. Any approximation error directly affects the importance weights and thus the target generalization guarantee the objective is designed to minimize.
- [Stochastic alternating updates] The stochastic alternating updates between policy parameters and source weights are presented as reliably minimizing the generalization-informed objective, but no analysis or empirical diagnostics address potential instability, collapse, or oscillation in the joint optimization loop.
minor comments (1)
- The abstract states improvements over baselines but does not specify the exact metrics, number of trials, or statistical significance; these details should be summarized early for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications on the design choices and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Scalable instance-level discrepancy estimators] The scalability claim for instance-level discrepancy estimators on high-dimensional visuomotor trajectories (long sequences of images and actions) lacks explicit bias or variance bounds under the diffusion training distribution. Any approximation error directly affects the importance weights and thus the target generalization guarantee the objective is designed to minimize.
Authors: We acknowledge that the manuscript does not derive explicit bias or variance bounds for the instance-level discrepancy estimators under the diffusion training distribution. The estimators rely on scalable approximations (e.g., embedded trajectory kernels) chosen for computational feasibility with long image-action sequences, and their practical reliability is supported by consistent empirical gains across sim-to-sim, sim-to-real, and multi-source tasks. We agree that a more formal characterization of approximation error would better connect the estimators to the target generalization bound. In the revision we will add a dedicated subsection discussing the estimator construction, potential bias sources, and empirical variance measurements obtained from repeated training runs. revision: yes
-
Referee: [Stochastic alternating updates] The stochastic alternating updates between policy parameters and source weights are presented as reliably minimizing the generalization-informed objective, but no analysis or empirical diagnostics address potential instability, collapse, or oscillation in the joint optimization loop.
Authors: The alternating optimization is presented as a practical procedure that jointly minimizes the discrepancy-aware objective, with stability observed through the reported performance metrics and training curves. We recognize that the manuscript lacks explicit analysis or diagnostics for instability, collapse, or oscillation. In the revised version we will include additional empirical diagnostics (loss trajectories for both policy and weights, ablation on alternation frequency, and checks for weight collapse) in the main text or supplementary material to substantiate the reliability of the updates. revision: yes
Circularity Check
No significant circularity detected in BEACON derivation
full rationale
The paper introduces a new framework casting cross-domain co-training as discrepancy-aware importance reweighting for diffusion policies, jointly optimizing policy parameters and source weights via an objective informed by target generalization bounds. It develops new scalable instance-level discrepancy estimators and stochastic alternating updates as part of the contribution. No equations or steps in the provided abstract reduce a claimed prediction or result to a fitted input by construction, nor do they rely on load-bearing self-citations, imported uniqueness theorems, or smuggled ansatzes. The central construction appears self-contained with independent content from the new estimators and multi-source extension. Scalability of the estimators is a practical concern but does not constitute circularity in the derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Discrepancy-based generalization bound [23]) … L(P,h) ≤ ∑ qi ℓ(hi) + qsrc dis(P,Q) + dis(q,p0) + …
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Instance-level discrepancy … k-nearest neighbors in policy embedding space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Robot programming by demonstration
Aude Billard, Sylvain Calinon, Rüdiger Dillmann, and Stefan Schaal. Robot programming by demonstration. InSpringer Handbook of Robotics, pages 1371–1394. Springer, 2008
work page 2008
-
[3]
Compose by focus: Scene graph-based atomic skills
Han Qi, Changhe Chen, and Heng Yang. Compose by focus: Scene graph-based atomic skills. InIEEE International Conference on Robotics and Automation (ICRA), 2026
work page 2026
-
[4]
Inference-time enhancement of generative robot policies via predictive world modeling
Han Qi, Haocheng Yin, Aris Zhu, Yilun Du, and Heng Yang. Inference-time enhancement of generative robot policies via predictive world modeling. InIEEE Robotics and Automation Letters (RAL), 2026
work page 2026
-
[5]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, 2023
work page 2023
-
[6]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems, 2023. doi: 10.15607/RSS.2023.XIX.026
-
[7]
Rusu, Mel Vecerik, Thomas Rothörl, Nicolas Heess, Razvan Pascanu, and Raia Hadsell
Andrei A. Rusu, Mel Vecerik, Thomas Rothörl, Nicolas Heess, Razvan Pascanu, and Raia Hadsell. Sim-to-real robot learning from pixels with progressive nets. InConference on Robot Learning, pages 262–270. PMLR, 2017
work page 2017
-
[8]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 23–30, 2017
work page 2017
-
[9]
Sim-to-real transfer of robotic control with dynamics randomization
Xue Bin Peng, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. InIEEE International Conference on Robotics and Automation, pages 1–8, 2018
work page 2018
-
[10]
Human-to-robot imitation in the wild
Shikhar Bahl, Abhinav Gupta, and Deepak Pathak. Human-to-robot imitation in the wild.arXiv preprint arXiv:2207.09450, 2022
-
[11]
Egomimic: Scaling imitation learning via egocentric video
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Danfei Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13226–13233. IEEE, 2025
work page 2025
-
[12]
EgoScale: Scaling Dexterous Manipulation with Diverse Ego- centric Human Data,
Ruijie Zheng, Dantong Niu, Yuqi Xie, Jing Wang, Mengda Xu, Yunfan Jiang, Fernando Castañeda, Fengyuan Hu, You Liang Tan, Letian Fu, et al. Egoscale: Scaling dexterous manipulation with diverse egocentric human data.arXiv preprint arXiv:2602.16710, 2026
-
[13]
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, and Sergey Levine. Bridge data: Boosting generalization of robotic skills with cross-domain datasets.arXiv preprint arXiv:2109.13396, 2021
work page internal anchor Pith review arXiv 2021
-
[14]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J. Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla,...
work page 2023
-
[15]
MimicGen: A data generation system for scalable robot learning using human demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. MimicGen: A data generation system for scalable robot learning using human demonstrations. InConference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 1820–1864. PMLR, 2023
work page 2023
-
[16]
CAD2RL: Real single-image flight without a single real image
Fereshteh Sadeghi and Sergey Levine. CAD2RL: Real single-image flight without a single real image. InRobotics: Science and Systems, 2017
work page 2017
-
[17]
Unsupervised pixel-level domain adaptation with generative adversarial networks
Konstantinos Bousmalis, Nathan Silberman, David Dohan, Dumitru Erhan, and Dilip Krishnan. Unsupervised pixel-level domain adaptation with generative adversarial networks. InIEEE Conference on Computer Vision and Pattern Recognition, pages 3722–3731, 2017
work page 2017
-
[18]
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks.Journal of Machine Learning Research, 17(59):1–35, 2016
work page 2016
-
[19]
Mingsheng Long, Yue Cao, Jianmin Wang, and Michael I. Jordan. Learning transferable features with deep adaptation networks. InInternational Conference on Machine Learning, pages 97–105. PMLR, 2015
work page 2015
-
[20]
Nicolas Courty, Rémi Flamary, Devis Tuia, and Alain Rakotomamonjy. Optimal transport for domain adaptation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(9): 1853–1865, 2017
work page 2017
-
[21]
Abhiram Maddukuri, Zhenyu Jiang, Lawrence Yunliang Chen, Soroush Nasiriany, Yuqi Xie, Yu Fang, Wenqi Huang, Zu Wang, Zhenjia Xu, Nikita Chernyadev, Scott Reed, Ken Goldberg, Ajay Mandlekar, Linxi Fan, and Yuke Zhu. Sim-and-real co-training: A simple recipe for vision-based robotic manipulation.Robotics: Science and Systems, 2025
work page 2025
-
[22]
Generalizable domain adaptation for sim-and-real policy co-training
Shuo Cheng, Liqian Ma, Zhenyang Chen, Ajay Mandlekar, Caelan Garrett, and Danfei Xu. Generalizable domain adaptation for sim-and-real policy co-training. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[23]
Best-effort adaptation.arXiv preprint arXiv:2305.05816, 2023
Pranjal Awasthi, Corinna Cortes, and Mehryar Mohri. Best-effort adaptation.arXiv preprint arXiv:2305.05816, 2023
-
[24]
Adaptation based on generalized discrepancy.Journal of Machine Learning Research, 20(1):1–30, 2019
Corinna Cortes, Mehryar Mohri, and Andrés Muñoz Medina. Adaptation based on generalized discrepancy.Journal of Machine Learning Research, 20(1):1–30, 2019
work page 2019
- [25]
-
[26]
Thomas M. Cover and Peter E. Hart. Nearest neighbor pattern classification.IEEE Transactions on Information Theory, 13(1):21–27, 1967
work page 1967
-
[27]
Domain adaptation with multiple sources
Yishay Mansour, Mehryar Mohri, and Afshin Rostamizadeh. Domain adaptation with multiple sources. InAdvances in Neural Information Processing Systems, volume 21, 2009
work page 2009
-
[28]
Han Zhao, Shanghang Zhang, Guanhang Wu, José M. F. Moura, João P. Costeira, and Geoffrey J. Gordon. Adversarial multiple source domain adaptation. InAdvances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[29]
Domain aggregation networks for multi-source domain adaptation
Junfeng Wen, Russell Greiner, and Dale Schuurmans. Domain aggregation networks for multi-source domain adaptation. InInternational Conference on Machine Learning, pages 10214–10224. PMLR, 2020
work page 2020
-
[30]
More is better: Deep domain adaptation with multiple sources
Sicheng Zhao, Hui Chen, Hu Huang, Pengfei Xu, and Guiguang Ding. More is better: Deep domain adaptation with multiple sources. InInternational Joint Conference on Artificial Intelligence, pages 8359–8367, 2024
work page 2024
-
[31]
Control-oriented clustering of visual latent representa- tion
Han Qi, Haocheng Yin, and Heng Yang. Control-oriented clustering of visual latent representa- tion. InInternational Conference on Learning Representations (ICLR), 2025. 11
work page 2025
-
[32]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
RoboCasa: Large-scale simulation of everyday tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. RoboCasa: Large-scale simulation of everyday tasks for generalist robots. InRobotics: Science and Systems, 2024
work page 2024
-
[34]
Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei A. Efros, and Trevor Darrell. CyCADA: Cycle-consistent adversarial domain adaptation. In International Conference on Machine Learning, pages 1989–1998. PMLR, 2018
work page 1989
-
[35]
Sim2val: Leveraging correlation across test platforms for variance-reduced metric estimation
Rachel Luo, Heng Yang, Michael Watson, Apoorva Sharma, Sushant Veer, Edward Schmerling, and Marco Pavone. Sim2val: Leveraging correlation across test platforms for variance-reduced metric estimation. InConference on Robot Learning (CoRL), 2025
work page 2025
-
[36]
Detecting change in data streams
Daniel Kifer, Shai Ben-David, and Johannes Gehrke. Detecting change in data streams. In International Conference on Very Large Data Bases, pages 180–191, 2004
work page 2004
-
[37]
A theory of learning from different domains.Machine Learning, 79 (1–2):151–175, 2010
Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jen- nifer Wortman Vaughan. A theory of learning from different domains.Machine Learning, 79 (1–2):151–175, 2010
work page 2010
-
[38]
Corinna Cortes and Mehryar Mohri. Domain adaptation and sample bias correction theory and algorithm for regression.Theoretical Computer Science, 519:103–126, 2014
work page 2014
-
[39]
Borgwardt, Bernhard Schölkopf, and Alex J
Jiayuan Huang, Arthur Gretton, Karsten M. Borgwardt, Bernhard Schölkopf, and Alex J. Smola. Correcting sample selection bias by unlabeled data. InAdvances in Neural Information Processing Systems, volume 19, 2007
work page 2007
-
[40]
Direct importance estimation with model selection and its application to covariate shift adaptation
Masashi Sugiyama, Shinichi Nakajima, Hisashi Kashima, Paul von Bünau, and Motoaki Kawanabe. Direct importance estimation with model selection and its application to covariate shift adaptation. InAdvances in Neural Information Processing Systems, volume 20, 2007
work page 2007
-
[41]
Learning bounds for importance weighting
Corinna Cortes, Yishay Mansour, and Mehryar Mohri. Learning bounds for importance weighting. InAdvances in Neural Information Processing Systems, volume 23, 2010
work page 2010
-
[42]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. InIEEE/CVF International Conference on Computer Vision, pages 1406–1415, 2019
work page 2019
-
[43]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Martín-Martín, Abhishek Joshi, Kevin Lin, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation framework and benchmark for robot learning.arXiv preprint arXiv:2009.12293, 2020. 12 Figure A1: Object placement range for OOD evaluation. The green region shows the placement range for source demonstr...
work page internal anchor Pith review Pith/arXiv arXiv 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.