Recognition: 2 theorem links
· Lean TheoremS2FT: Parameter-Efficient Fine-Tuning in Sparse Spectrum Domain
Pith reviewed 2026-05-12 00:56 UTC · model grok-4.3
The pith
S2FT finds an invertible rearrangement of a coarse weight-change estimate that turns uniform-spectrum updates into sparse-spectrum ones, allowing fine-tuning with 0.08 percent of the parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
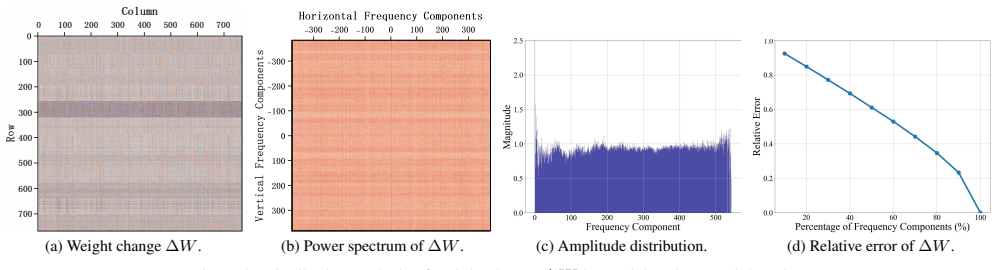
S2FT proposes an invertible transformation obtained by rearranging rows and columns of a pre-estimated coarse weight change via nearest-neighbor search, which maps a latent sparse-spectrum matrix to the observed weight change with uniform spectrum. By performing parameter-efficient updates only on the sparse spectral coefficients in this domain and applying the inverse, the method achieves superior adaptation performance using just 0.08% of the training parameters.
What carries the argument
The nearest-neighbor search for row-and-column rearrangement on the pre-estimated weight change, which enforces local spatial smoothness corresponding to sparse spectra while preserving neuron structure.
If this is right
- Only 0.08% of parameters need training to achieve better results than prior spectral PEFT methods.
- The weight update can be accurately modeled by few coefficients once rearranged into a sparse-spectrum form.
- Rearrangement is found simply without exhaustive search or additional optimization.
- Performance gains come from operating in the transformed sparse domain rather than the original uniform one.
Where Pith is reading between the lines
- Combining this rearrangement idea with low-rank methods like LoRA might further reduce parameters.
- The observation of uniform spectra could apply to other adaptation techniques beyond Fourier transforms.
- If the coarse estimate comes from a quick pass or smaller model, it could make the method even more efficient in practice.
Load-bearing premise
That rearranging a coarse pre-estimate via nearest neighbors will consistently yield a sparse enough spectrum for the actual weight change to be captured by few coefficients.
What would settle it
If the spectrum of the rearranged weight change remains power-uniform or if fine-tuning performance drops below standard PEFT baselines at the 0.08% parameter budget.
Figures




read the original abstract
Parameter Efficient Fine-Tuning (PEFT) is a key technique for adapting a large pretrained model to downstream tasks by fine-tuning only a small number of parameters. Recent methods based on Fourier transforms have further reduced the fine-tuned parameters scale by only fine-tuning a few spectral coefficients. Its basic assumption is that the weight change \delta W is a spatial-domain matrix with a sparse spectrum. However, in this paper, we observe that the spectrum of weight change is not sparse, but instead distributed like power-uniform. This fact implies that fine-tuning only a few spectral coefficients is insufficient to accurately model the weight change with uniform spectrum. To address this issue, we propose to seek an invertible transformation that can transform a latent spatial-domain matrix with sparse spectrum to the weight change, and then perform PEFT on such sparse spectrum domain with few spectral coefficients, called S2FT. To seek such transformation, we first pre-estimate a coarse weight change as a prior. Then, inspired by that sparse spectrum often correspond to locally smooth spatial structures, we regard this transformation as a row and column rearrangement operation on the pre-estimated weight change that smooth spatial structures while keep the structure information of neurons. Finally, we propose to solve the rearrangement search problem in a simple nearest neighbor search manner, thereby obtaining the invertible transformation. Extensive results show our S2FT achieves superior performance by only using 0.08% training parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper observes that weight-change matrices δW during fine-tuning exhibit power-uniform spectra rather than sparse ones, rendering direct spectral PEFT ineffective. It proposes S2FT, which first obtains a coarse pre-estimate of δW, then applies a nearest-neighbor search to find an invertible row-and-column rearrangement that induces local smoothness (hence sparsity) in the spectrum, and finally fine-tunes only a small number (0.08 %) of spectral coefficients in the transformed domain. Extensive experiments are said to demonstrate superior performance over existing PEFT methods.
Significance. If the rearrangement reliably produces a sufficiently sparse spectrum and the pre-estimate is accurate enough to locate the correct permutation, S2FT would constitute a meaningful advance in extreme parameter-efficient fine-tuning by moving the problem into a domain where a tiny fraction of coefficients suffices. The empirical observation of power-uniform spectra and the heuristic rearrangement search are potentially useful contributions, but the absence of direct measurements of achieved sparsity and pre-estimate fidelity limits the strength of the current evidence.
major comments (3)
- [Abstract / Method] Abstract and Method section: the central claim that the nearest-neighbor row/column rearrangement of the coarse pre-estimate produces a spectrum sparse enough for 0.08 % coefficients to suffice is not supported by any quantitative measurement (e.g., sorted coefficient-magnitude curves, energy concentration ratios, or sparsity metrics before versus after rearrangement). Without such evidence the parameter-efficiency argument remains unsubstantiated.
- [Method] Method section (rearrangement search): the paper provides no analysis or ablation showing that the coarse pre-estimate is sufficiently accurate to recover a permutation that sparsifies the true (unknown) δW; if the pre-estimate error is large, the nearest-neighbor search may select a transformation under which the final spectrum remains close to uniform, collapsing the efficiency gain.
- [Experiments] Experiments section: reported performance gains are presented without error bars, without an ablation isolating the contribution of the rearrangement versus the pre-estimate alone, and without direct verification that the post-rearrangement spectra are indeed sparse; these omissions make it impossible to assess whether the claimed superiority is robust or merely an artifact of the heuristic design choices.
minor comments (2)
- [Method] Notation for the rearrangement operator and the spectral coefficients should be introduced with explicit equations rather than prose descriptions.
- [Abstract] The abstract states an empirical observation about power-uniform spectra; a brief quantitative characterization (e.g., average decay exponent or Gini coefficient of the spectrum) would strengthen the motivation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that the manuscript would benefit from additional quantitative evidence on sparsity, analysis of the pre-estimate, and experimental ablations with error bars. We will incorporate these in the revised version.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and Method section: the central claim that the nearest-neighbor row/column rearrangement of the coarse pre-estimate produces a spectrum sparse enough for 0.08 % coefficients to suffice is not supported by any quantitative measurement (e.g., sorted coefficient-magnitude curves, energy concentration ratios, or sparsity metrics before versus after rearrangement). Without such evidence the parameter-efficiency argument remains unsubstantiated.
Authors: We agree that direct quantitative measurements are needed to substantiate the sparsity claim. In the revision we will add sorted coefficient-magnitude curves, energy concentration ratios, and sparsity metrics (e.g., percentage of energy in the top-k coefficients) for representative weight-change matrices, shown both before and after the nearest-neighbor rearrangement. These plots will demonstrate the improvement in spectral sparsity that enables the 0.08 % coefficient regime. revision: yes
-
Referee: [Method] Method section (rearrangement search): the paper provides no analysis or ablation showing that the coarse pre-estimate is sufficiently accurate to recover a permutation that sparsifies the true (unknown) δW; if the pre-estimate error is large, the nearest-neighbor search may select a transformation under which the final spectrum remains close to uniform, collapsing the efficiency gain.
Authors: We acknowledge the absence of explicit analysis on pre-estimate fidelity. We will add an ablation that systematically varies pre-estimate quality (by changing the number of calibration samples or injecting controlled noise) and reports the resulting post-rearrangement spectral sparsity together with downstream fine-tuning accuracy. This will quantify how robust the nearest-neighbor search remains under realistic pre-estimate error. revision: yes
-
Referee: [Experiments] Experiments section: reported performance gains are presented without error bars, without an ablation isolating the contribution of the rearrangement versus the pre-estimate alone, and without direct verification that the post-rearrangement spectra are indeed sparse; these omissions make it impossible to assess whether the claimed superiority is robust or merely an artifact of the heuristic design choices.
Authors: We will revise the experimental section to include (i) error bars from at least three independent runs with different random seeds, (ii) an ablation that applies the spectral PEFT directly to the pre-estimate without rearrangement, and (iii) additional figures that verify post-rearrangement spectral sparsity on the same layers used for the main results. These changes will allow readers to isolate the rearrangement contribution and assess robustness. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper observes that weight-change spectra are power-uniform rather than sparse, then constructs an invertible row/column rearrangement from a coarse pre-estimate via nearest-neighbor search to induce local smoothness before spectral fine-tuning. No equation or performance claim reduces by construction to a quantity defined by the method's own fitted parameters; the rearrangement is computed once from the pre-estimate and applied independently, while the 0.08% parameter claim is supported by external empirical results rather than a self-referential loop. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse spectrum often corresponds to locally smooth spatial structures
invented entities (1)
-
invertible row-column rearrangement transformation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we regard this transformation as a row and column rearrangement operation on the pre-estimated weight change that smooth spatial structures while keep the structure information of neurons... nearest neighbor search manner
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the power spectrum of weight change ΔW is not sparse, but tends to be power-uniform
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
David Brandwood.Fourier transforms in radar and signal processing. Artech House, 2012
work page 2012
-
[2]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herve Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[3]
Conv-adapter: Exploring parameter efficient transfer learning for convnets
Hao Chen, Ran Tao, Han Zhang, Yidong Wang, Xiang Li, Wei Ye, Jindong Wang, Guosheng Hu, and Marios Savvides. Conv-adapter: Exploring parameter efficient transfer learning for convnets. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1551–1561, 2024
work page 2024
-
[4]
QuanTA: Efficient high-rank fine-tuning of LLMs with quantum-informed ten- sor adaptation
Zhuo Chen, Rumen Dangovski, Charlotte Loh, Owen M Dugan, Di Luo, and Marin Soljacic. QuanTA: Efficient high-rank fine-tuning of LLMs with quantum-informed ten- sor adaptation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[5]
Vicuna: An open- source chatbot impressing gpt-4 with 90%* chatgpt quality
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhang- hao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yong- hao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open- source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3): 6, 2023
work page 2023
-
[6]
Tim OF Conrad, Martin Genzel, Nada Cvetkovic, Niklas Wulkow, Alexander Leichtle, Jan Vybiral, Gitta Kutyniok, and Christof Schütte. Sparse proteomics analysis–a com- pressed sensing-based approach for feature selection and clas- sification of high-dimensional proteomics mass spectrometry data.BMC Bioinformatics, 18:1–20, 2017
work page 2017
-
[7]
An image is worth 16x16 words: Transform- ers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Transform- ers for image recognition at scale. InInternational Conference on Learning Representations, 2020
work page 2020
-
[8]
Deep residual learning in the jpeg transform domain
Max Ehrlich and Larry S Davis. Deep residual learning in the jpeg transform domain. InProceedings of the IEEE/CVF international conference on computer vision, pages 3484– 3493, 2019
work page 2019
-
[9]
Ziqi Gao, Qichao Wang, Aochuan Chen, Zijing Liu, Bingzhe Wu, Liang Chen, and Jia Li. Parameter-efficient fine- tuning with discrete fourier transform.arXiv preprint arXiv:2405.03003, 2024
-
[10]
Fine-grained car detection for visual census estimation
Timnit Gebru, Jonathan Krause, Yilun Wang, Duyun Chen, Jia Deng, and Li Fei-Fei. Fine-grained car detection for visual census estimation. InProceedings of the AAAI Conference on Artificial Intelligence, 2017
work page 2017
-
[11]
Lionel Gueguen, Alex Sergeev, Ben Kadlec, Rosanne Liu, and Jason Yosinski. Faster neural networks straight from jpeg.Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[12]
Pela: Learning parameter-efficient models with low-rank ap- proximation
Yangyang Guo, Guangzhi Wang, and Mohan Kankanhalli. Pela: Learning parameter-efficient models with low-rank ap- proximation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15699– 15709, 2024
work page 2024
-
[13]
E 2 vpt: An effective and efficient approach for visual prompt tuning
Cheng Han, Qifan Wang, Yiming Cui, Zhiwen Cao, Wen- guan Wang, Siyuan Qi, and Dongfang Liu. E 2 vpt: An effective and efficient approach for visual prompt tuning. In 2023 IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 17445–17456. IEEE, 2023
work page 2023
-
[14]
Lora+: Efficient low rank adaptation of large models
Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models. InForty-first Interna- tional Conference on Machine Learning
-
[15]
Sensitivity-aware visual parameter-efficient fine- tuning
Haoyu He, Jianfei Cai, Jing Zhang, Dacheng Tao, and Bohan Zhuang. Sensitivity-aware visual parameter-efficient fine- tuning. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 11825–11835, 2023
work page 2023
-
[16]
SMT: Fine-tuning large language models with sparse matri- ces
Haoze He, Juncheng B Li, Xuan Jiang, and Heather Miller. SMT: Fine-tuning large language models with sparse matri- ces. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[17]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022
work page 2022
-
[18]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
work page 2019
-
[19]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
work page 2022
-
[20]
HiRA: Parameter-efficient hadamard high-rank adap- tation for large language models
Qiushi Huang, Tom Ko, Zhan Zhuang, Lilian Tang, and Yu Zhang. HiRA: Parameter-efficient hadamard high-rank adap- tation for large language models. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
work page 2025
-
[21]
Cor A.J. Hurkens and Gerhard J. Woeginger. On the nearest neighbor rule for the traveling salesman problem.Operations Research Letters, 32(1):1–4, 2004
work page 2004
-
[22]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. InEuropean Conference on Computer Vision, pages 709–727. Springer, 2022
work page 2022
-
[23]
Novel dataset for fine-grained image cat- egorization: Stanford dogs
Aditya Khosla, Nityananda Jayadevaprakash, Bangpeng Yao, and Fei-Fei Li. Novel dataset for fine-grained image cat- egorization: Stanford dogs. InProc. CVPR workshop on fine-grained visual categorization (FGVC), 2011
work page 2011
-
[24]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 4015–4026, 2023
work page 2023
-
[25]
Vera: Vector-based random matrix adaptation
Dawid Jan Kopiczko, Tijmen Blankevoort, and Yuki M Asano. Vera: Vector-based random matrix adaptation. InThe Twelfth International Conference on Learning Representations
-
[26]
Dongze Lian, Daquan Zhou, Jiashi Feng, and Xinchao Wang. Scaling & shifting your features: A new baseline for efficient model tuning.Advances in Neural Information Processing Systems, 35:109–123, 2022
work page 2022
-
[27]
HMoRA: Making LLMs more effective with hierarchical mixture of loRA experts
Mengqi Liao, Wei Chen, Junfeng Shen, Shengnan Guo, and Huaiyu Wan. HMoRA: Making LLMs more effective with hierarchical mixture of loRA experts. InThe Thirteenth Inter- national Conference on Learning Representations, 2025
work page 2025
-
[28]
Vision transformers are parameter-efficient audio-visual learners
Yan-Bo Lin, Yi-Lin Sung, Jie Lei, et al. Vision transformers are parameter-efficient audio-visual learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2299–2309, 2023
work page 2023
-
[29]
Dora: Weight-decomposed low-rank adaptation
Shih-yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. InForty-first International Conference on Ma- chine Learning
-
[30]
Time-memory-and parameter-efficient visual adaptation
Otniel-Bogdan Mercea, Alexey Gritsenko, Cordelia Schmid, and Anurag Arnab. Time-memory-and parameter-efficient visual adaptation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 5536–5545, 2024
work page 2024
-
[31]
Variational multi- phase segmentation using high-dimensional local features
Niklas Mevenkamp and Benjamin Berkels. Variational multi- phase segmentation using high-dimensional local features. In WACV, 2016
work page 2016
-
[32]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE, 2008
work page 2008
-
[33]
Parameter efficient fine-tuning via cross block orchestration for segment anything model
Zelin Peng, Zhengqin Xu, Zhilin Zeng, Lingxi Xie, Qi Tian, and Wei Shen. Parameter efficient fine-tuning via cross block orchestration for segment anything model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3743–3752, 2024
work page 2024
-
[34]
Alec Radford, JongWook Kim, Chris Hallacy, A. Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Askell Amanda, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from nat- ural language supervision.Cornell University - arXiv,Cornell University - arXiv, 2021
work page 2021
-
[35]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven gen- eration
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven gen- eration. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 22500–22510, 2023
work page 2023
-
[36]
Rethinking graph neural networks for anomaly detection
Jianheng Tang, Jiajin Li, Ziqi Gao, and Jia Li. Rethinking graph neural networks for anomaly detection. InInternational conference on machine learning, pages 21076–21089. PMLR, 2022
work page 2022
-
[37]
Hydralora: An asymmetric lora architecture for efficient fine-tuning
Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, and Chengzhong Xu. Hydralora: An asymmetric lora architecture for efficient fine-tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[38]
Cheng-Hao Tu, Zheda Mai, and Wei-Lun Chao. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7725–7735, 2023
work page 2023
-
[39]
Grant Van Horn, Steve Branson, Ryan Farrell, Scott Haber, Jessie Barry, Panos Ipeirotis, Pietro Perona, and Serge Be- longie. Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 595–604, 2015
work page 2015
-
[40]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011
work page 2011
-
[41]
Glue: A multi-task bench- mark and analysis platform for natural language understand- ing
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Glue: A multi-task bench- mark and analysis platform for natural language understand- ing. InProceedings of the 2018 EMNLP Workshop Black- boxNLP: Analyzing and Interpreting Neural Networks for NLP, 2018
work page 2018
-
[42]
Self-instruct: Aligning language models with self-generated instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023
work page 2023
-
[43]
PaCA: Partial connec- tion adaptation for efficient fine-tuning
Sunghyeon Woo, Sol Namkung, Sunwoo Lee, Inho Jeong, Beomseok Kim, and Dongsuk Jeon. PaCA: Partial connec- tion adaptation for efficient fine-tuning. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[44]
Manning, and Christo- pher Potts
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D. Manning, and Christo- pher Potts. Reft: Representation finetuning for language mod- els. InAdvances in Neural Information Processing Systems, pages 63908–63962, 2024
work page 2024
-
[45]
Learning in the frequency domain
Kai Xu, Minghai Qin, Fei Sun, Yuhao Wang, Yen-Kuang Chen, and Fengbo Ren. Learning in the frequency domain. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
work page 2020
-
[46]
1% vs 100%: Parameter-efficient low rank adapter for dense predictions
Dongshuo Yin, Yiran Yang, Zhechao Wang, Hongfeng Yu, Kaiwen Wei, and Xian Sun. 1% vs 100%: Parameter-efficient low rank adapter for dense predictions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20116–20126, 2023
work page 2023
-
[47]
Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1–9, 2022
work page 2022
-
[48]
A large-scale study of representation learning with the visual task adaptation benchmark
Xiaohua Zhai, Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, An- dre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, et al. A large-scale study of representation learning with the visual task adaptation benchmark.arXiv preprint arXiv:1910.04867, 2019
-
[49]
Code- book transfer with part-of-speech for vector-quantized image modeling
Baoquan Zhang, Huaibin Wang, Chuyao Luo, Xutao Li, Guo- tao Liang, Yunming Ye, Xiaochen Qi, and Yao He. Code- book transfer with part-of-speech for vector-quantized image modeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7757–7766, 2024
work page 2024
-
[50]
Baoquan Zhang, Bingqi Shan, Aoxue Li, Chuyao Luo, Yun- ming Ye, and Zhenguo Li. Zookt: Task-adaptive knowledge transfer of model zoo for few-shot learning.Pattern Recogni- tion, 158:110960, 2025
work page 2025
-
[51]
LoRA-FA: Efficient and Effective Low Rank Representation Fine-tuning
Longteng Zhang, Lin Zhang, Shaohuai Shi, Xiaowen Chu, and Bo Li. Lora-fa: Memory-efficient low-rank adapta- tion for large language models fine-tuning.arXiv preprint arXiv:2308.03303, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep fea- tures as a perceptual metric. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
work page 2018
-
[53]
Gradient-based parameter selection for efficient fine-tuning
Zhi Zhang, Qizhe Zhang, Zijun Gao, Renrui Zhang, Ekaterina Shutova, Shiji Zhou, and Shanghang Zhang. Gradient-based parameter selection for efficient fine-tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28566–28577, 2024
work page 2024
-
[54]
Galore: Memory- efficient llm training by gradient low-rank projection
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. Galore: Memory- efficient llm training by gradient low-rank projection. In Forty-first International Conference on Machine Learning
-
[55]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
work page 2023
-
[56]
Asymmetry in low-rank adapters of foundation models
Jiacheng Zhu, Kristjan Greenewald, Kimia Nadjahi, Haitz Saez De Ocariz Borde, Rickard Gabrielsson, Leshem Choshen, Marzyeh Ghassemi, Mikhail Yurochkin, and Justin Solomon. Asymmetry in low-rank adapters of foundation models. InInternational Conference on Learning Represen- tations, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.