Recognition: 2 theorem links
· Lean TheoremReducing Linguistic Hallucination in LM-Based Speech Enhancement via Noise-Invariant Acoustic-Semantic Distillation
Pith reviewed 2026-05-12 01:06 UTC · model grok-4.3
The pith
A distillation framework creates noise-invariant representations that reduce linguistic hallucination in language-model speech enhancement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a noise-invariant acoustic-semantic conditioning encoder, obtained by distilling both reconstruction fidelity and linguistic consistency from clean speech, allows a decoder-only autoregressive language model to predict accurate clean acoustic tokens from noisy inputs, substantially reducing hallucination while a learnable WavLM-based codec ensures high perceptual quality.
What carries the argument
The noise-invariant acoustic-semantic conditioning encoder learned via joint distillation of acoustic and semantic clean-speech targets.
If this is right
- The proposed method improves linguistic consistency metrics over prior LM-based speech enhancement approaches.
- Performance gains are especially evident under low-SNR and reverberant conditions.
- Perceptual quality stays competitive with baseline systems.
- The framework supports high-quality generation through its WavLM-derived codec.
Where Pith is reading between the lines
- If the distillation succeeds in creating invariant features, the same approach could help stabilize other generative models that rely on degraded conditioning signals.
- Semantic distillation may prove more critical than acoustic alone for preventing content drift in audio generation tasks.
- Applying the method to real recorded noise rather than simulated mixtures would test whether the invariance holds outside controlled experiments.
Load-bearing premise
That the joint distillation of acoustic and semantic targets from clean speech will result in conditioning representations that stay effective and noise-invariant when the input speech is severely degraded, stopping the language model from generating linguistically incorrect outputs.
What would settle it
Observing no reduction in linguistic hallucination rates, measured by content faithfulness metrics, when the method is evaluated on speech inputs with signal-to-noise ratios below 0 dB would falsify the claim that the distilled representations prevent unreliable conditioning.
Figures
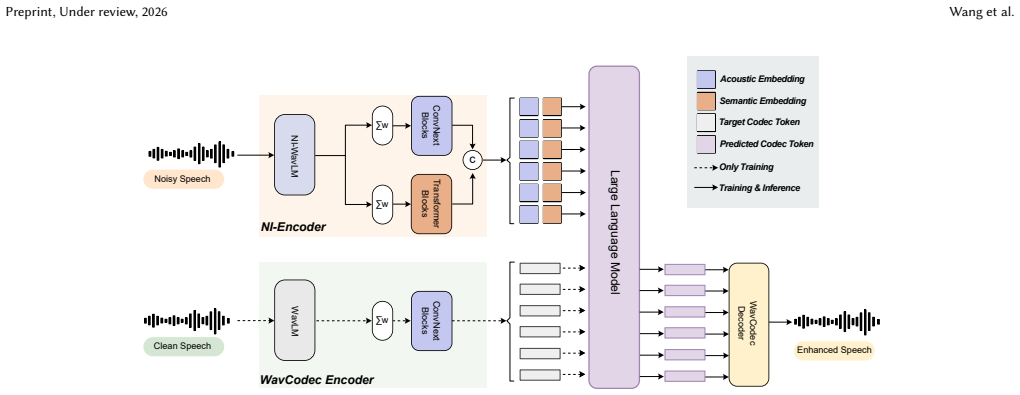



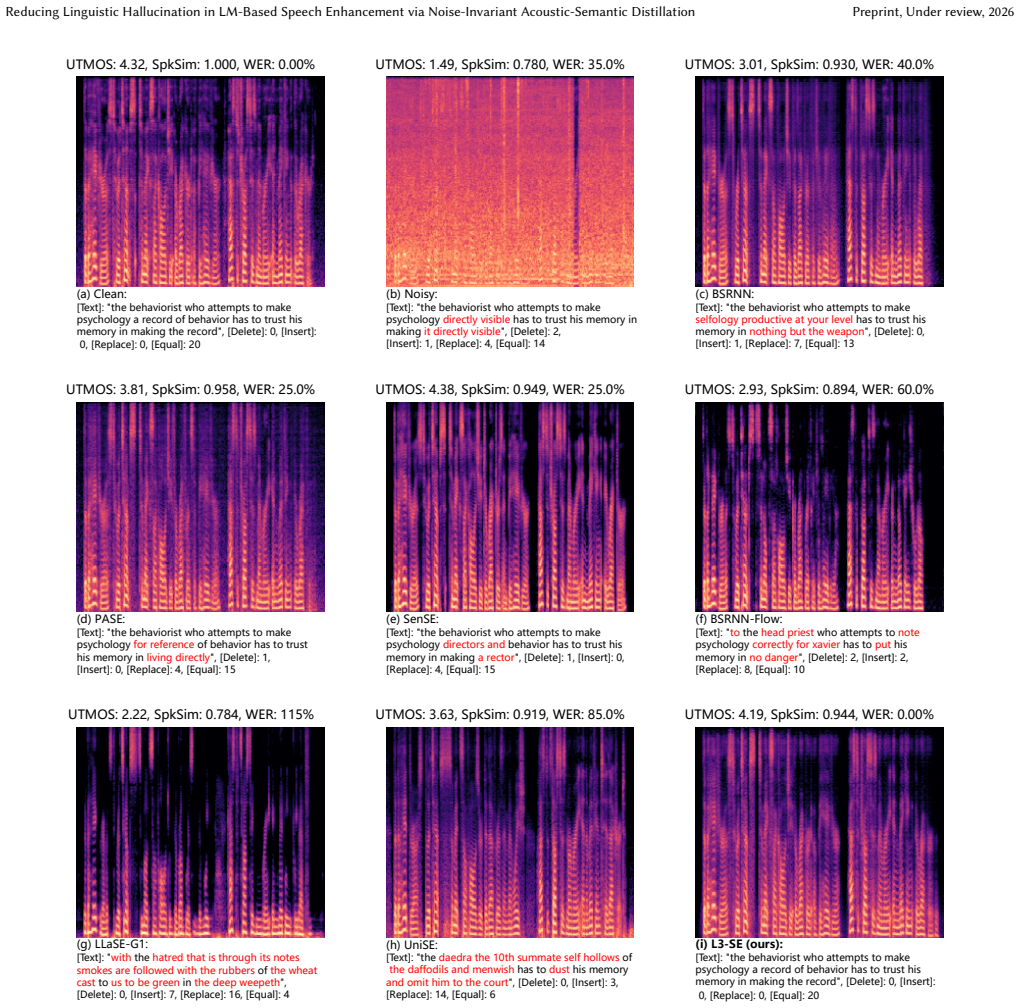
read the original abstract
Language model (LM)-based speech enhancement (SE) can generate natural-sounding speech, but under severe noise it often suffers from unreliable conditioning, leading to perceptually plausible yet linguistically incorrect outputs. To address this issue, we propose L3-SE, a noise-invariant acoustic-semantic distillation framework for reducing linguistic hallucination in LM-based SE. The proposed method learns a noise-invariant conditioning encoder from noisy speech by jointly distilling two complementary clean-speech targets: an acoustic target for reconstruction fidelity and a semantic target for linguistic consistency. The resulting noise-invariant acoustic-semantic representations are used to condition a decoder-only autoregressive language model, which predicts clean acoustic tokens that are decoded into enhanced speech. To support high-quality generation, we further employ a high-fidelity codec built on learnable weighted WavLM layer representations as the discrete acoustic interface. By improving the reliability of conditioning under adverse conditions, the proposed framework substantially reduces hallucination and improves content faithfulness. Experiments show that the proposed method consistently outperforms prior LM-based speech enhancement baselines on linguistic consistency metrics, with especially clear gains under low-SNR and reverberant conditions, while maintaining competitive perceptual quality. Audio samples are available at https://max1wz.github.io/L3-SE-Demo-Page/. The complete source code will be released after the manuscript is accepted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes L3-SE, a noise-invariant acoustic-semantic distillation framework for LM-based speech enhancement. It trains a conditioning encoder on noisy inputs by jointly distilling acoustic reconstruction and semantic consistency targets from clean speech, then feeds the resulting representations into a decoder-only autoregressive LM that predicts clean acoustic tokens decoded via a high-fidelity WavLM-based codec. The central claim is that this yields reliable conditioning under adverse conditions, substantially reducing linguistic hallucination while improving content faithfulness, with experiments showing consistent gains on linguistic consistency metrics especially in low-SNR and reverberant settings.
Significance. If the distilled representations prove noise-invariant and causally reduce hallucinations, the work would address a key failure mode in LM-based SE, offering a principled way to improve linguistic reliability without sacrificing perceptual quality. The joint distillation approach and planned code release are positive contributions that could support reproducibility and further research in robust speech generation.
major comments (3)
- [§3] §3 (Method, conditioning encoder): The noise-invariance property is load-bearing for the central claim that reliable conditioning prevents linguistically incorrect tokens, yet the manuscript provides no direct diagnostics such as representation cosine similarity, Euclidean distances, or alignment metrics between clean and noisy versions of the same utterance across SNR levels or reverberation conditions.
- [§4] §4 (Experiments): Downstream gains on linguistic consistency metrics are reported, but without ablations that isolate the contribution of the noise-invariance mechanism (e.g., comparing against a non-distilled encoder or semantic-only distillation), it remains unclear whether observed improvements stem from the claimed invariance or from other training effects.
- [§4.2] §4.2 (Results under low-SNR): The abstract and results claim especially clear gains under low-SNR and reverberant conditions, but the absence of error bars, statistical significance tests, or detailed dataset/SNR breakdown tables makes it difficult to assess the robustness and magnitude of the reported outperformance.
minor comments (2)
- [§3.3] The high-fidelity codec description references learnable weighted WavLM layers but does not specify the exact weighting scheme or layer selection criterion in the main text.
- [Figure 1] Figure captions for the overall architecture could more explicitly label the distillation targets and the interface to the decoder-only LM.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that additional direct evidence and ablations would strengthen the manuscript's claims regarding noise-invariance and its causal role in reducing hallucinations. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Method, conditioning encoder): The noise-invariance property is load-bearing for the central claim that reliable conditioning prevents linguistically incorrect tokens, yet the manuscript provides no direct diagnostics such as representation cosine similarity, Euclidean distances, or alignment metrics between clean and noisy versions of the same utterance across SNR levels or reverberation conditions.
Authors: We agree that explicit diagnostics are valuable to directly substantiate the noise-invariance of the distilled representations. In the revised manuscript, we will add quantitative analyses including cosine similarity, Euclidean distances, and alignment metrics (e.g., CCA) computed between clean and noisy utterance pairs at multiple SNR levels and under reverberation. These will be presented in a new subsection or figure in §3 to complement the existing downstream results. revision: yes
-
Referee: [§4] §4 (Experiments): Downstream gains on linguistic consistency metrics are reported, but without ablations that isolate the contribution of the noise-invariance mechanism (e.g., comparing against a non-distilled encoder or semantic-only distillation), it remains unclear whether observed improvements stem from the claimed invariance or from other training effects.
Authors: We acknowledge that isolating the noise-invariance mechanism via targeted ablations would clarify its specific contribution. We will add these ablations in the revised §4, including variants with a non-distilled encoder (trained only on noisy inputs without clean targets) and semantic-only distillation (omitting the acoustic reconstruction loss). Results will be reported on the same linguistic consistency metrics to demonstrate the benefit of the joint acoustic-semantic approach. revision: yes
-
Referee: [§4.2] §4.2 (Results under low-SNR): The abstract and results claim especially clear gains under low-SNR and reverberant conditions, but the absence of error bars, statistical significance tests, or detailed dataset/SNR breakdown tables makes it difficult to assess the robustness and magnitude of the reported outperformance.
Authors: We agree that error bars, statistical tests, and finer-grained breakdowns are necessary to rigorously support the claims of outperformance in challenging conditions. In the revision, we will include standard deviation error bars (computed over multiple random seeds), paired statistical significance tests (e.g., t-tests or Wilcoxon), and expanded tables with per-SNR and per-dataset breakdowns for all key metrics in §4.2 and the supplementary material. revision: yes
Circularity Check
No circularity: new distillation framework with independent experimental validation
full rationale
The paper introduces L3-SE as a methodological proposal that jointly distills acoustic reconstruction and semantic consistency targets from clean speech to produce a conditioning encoder for a decoder-only LM. No equations, parameter fits, or derivations are described that would reduce the claimed noise-invariance or hallucination reduction to a quantity defined by the method's own inputs. The central claim rests on the architectural design and downstream empirical gains on linguistic consistency metrics under low-SNR conditions, without self-citations, ansatzes smuggled via prior work, or renaming of known results. The derivation chain is self-contained as an engineering contribution rather than a closed loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Joint distillation of acoustic reconstruction and semantic consistency targets from clean speech produces noise-invariant conditioning representations usable by an autoregressive LM
invented entities (1)
-
L3-SE noise-invariant conditioning encoder
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearlearns a noise-invariant conditioning encoder from noisy speech by jointly distilling two complementary clean-speech targets: an acoustic target for reconstruction fidelity and a semantic target for linguistic consistency
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearNI-Encoder follows the same overall architectural form as the teachers, namely a shared WavLM backbone followed by acoustic and semantic heads
Reference graph
Works this paper leans on
-
[1]
Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, An- toine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. 2023. MusicLM: Generating music from text.arXiv preprint arXiv:2301.11325 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems33 (2020), 12449–12460
work page 2020
-
[3]
Xuankai Chang, Takashi Maekaku, Yuya Fujita, and Shinji Watanabe. 2022. End-to-End Integration of Speech Recognition, Speech Enhancement, and Self- Supervised Learning Representation. InInterspeech 2022. 3819–3823
work page 2022
-
[4]
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al . 2022. WavLM: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing16, 6 (2022), 1505–1518
work page 2022
- [5]
-
[6]
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2023. High fidelity neural audio compression.Transactions on Machine Learning Research (2023)
work page 2023
-
[7]
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. 2024. Moshi: a speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037(2024)
work page internal anchor Pith review arXiv 2024
-
[8]
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al . 2024. Cosyvoice 2: Scal- able streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117(2024)
work page internal anchor Pith review arXiv 2024
-
[9]
Harishchandra Dubey, Ashkan Aazami, Vishak Gopal, Babak Naderi, Sebastian Braun, Ross Cutler, Alex Ju, Mehdi Zohourian, Min Tang, Mehrsa Golestaneh, et al. 2024. ICASSP 2023 deep noise suppression challenge.IEEE Open Journal of Signal Processing5 (2024), 725–737
work page 2024
-
[10]
Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12873–12883
work page 2021
-
[11]
Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra. 2021. FSD50K: an open dataset of human-labeled sound events.IEEE/ACM Transactions on Audio, Speech, and Language Processing30 (2021), 829–852
work page 2021
- [12]
-
[13]
Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber
-
[14]
InProceedings of the 23rd international conference on Machine learning
Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. InProceedings of the 23rd international conference on Machine learning. 369–376
-
[15]
Heitor R Guimarães, Arthur Pimentel, Anderson R Avila, Mehdi Rezagholizadeh, Boxing Chen, and Tiago H Falk. 2023. Robustdistiller: Compressing universal speech representations for enhanced environment robustness. InICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
work page 2023
-
[16]
Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, et al . 2024. Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation. In 2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 885–890
work page 2024
-
[17]
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM transactions on audio, speech, and language processing29 (2021), 3451–3460
work page 2021
-
[18]
Bryce Irvin, Marko Stamenovic, Mikolaj Kegler, and Li-Chia Yang. 2023. Self- supervised learning for speech enhancement through synthesis. InICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
work page 2023
-
[19]
Jesper Jensen and Cees H Taal. 2016. An algorithm for predicting the intelligibility of speech masked by modulated noise maskers.IEEE/ACM Transactions on Audio, Speech, and Language Processing24, 11 (2016), 2009–2022
work page 2016
-
[20]
Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Xize Cheng, Zehan Wang, Ruiqi Li, et al. 2024. WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling. In The Thirteenth International Conference on Learning Representations
work page 2024
-
[21]
Boyi Kang, Xinfa Zhu, Zihan Zhang, Zhen Ye, Mingshuai Liu, Ziqian Wang, Yike Zhu, Guobin Ma, Jun Chen, Longshuai Xiao, Chao Weng, Wei Xue, and Lei Xie. 2025. LLaSE-G1: Incentivizing Generalization Capability for LLaMA- based Speech Enhancement. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
work page 2025
-
[22]
Adam Katav, Yair Moshe, and Israel Cohen. 2025. A Framework for Robust Speaker Verification in Highly Noisy Environments Leveraging Both Noisy and Preprint, Under review, 2026 Wang et al. Enhanced Audio. In2025 33rd European Signal Processing Conference (EUSIPCO). IEEE, 41–45
work page 2025
-
[23]
Tom Ko, Vijayaditya Peddinti, Daniel Povey, Michael L Seltzer, and Sanjeev Khudanpur. 2017. A study on data augmentation of reverberant speech for robust speech recognition. In2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 5220–5224
work page 2017
-
[24]
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. 2020. HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis.Advances in neural information processing systems33 (2020), 17022–17033
work page 2020
-
[25]
Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar. 2023. High-fidelity audio compression with improved RVQGAN.Advances in Neural Information Processing Systems36 (2023), 27980–27993
work page 2023
-
[26]
Jean-Marie Lemercier, Julius Richter, Simon Welker, and Timo Gerkmann. 2023. StoRM: A diffusion-based stochastic regeneration model for speech enhancement and dereverberation.IEEE/ACM Transactions on Audio, Speech, and Language Processing31 (2023), 2724–2737
work page 2023
- [27]
-
[28]
Fengjin Li, Jie Wang, Yadong Niu, Yongqing Wang, Meng Meng, Jian Luan, and Zhiyong Wu. 2025. StarVC: A Unified Auto-Regressive Framework for Joint Text and Speech Generation in Voice Conversion. InInterspeech 2025. 4593–4597
work page 2025
-
[29]
Xu Li, Qirui Wang, and Xiaoyu Liu. 2024. MaskSR: Masked Language Model for Full-band Speech Restoration. InProc. Interspeech 2024. 2275–2279
work page 2024
-
[30]
Xingchen Li, Hanke Xie, Ziqian Wang, Zihan Zhang, Longshuai Xiao, and Lei Xie. 2025. SenSE: Semantic-Aware High-Fidelity Universal Speech Enhancement. arXiv preprint arXiv:2509.24708(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11976–11986
work page 2022
-
[32]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Yen-Ju Lu, Zhong-Qiu Wang, Shinji Watanabe, Alexander Richard, Cheng Yu, and Yu Tsao. 2022. Conditional diffusion probabilistic model for speech enhancement. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 7402–7406
work page 2022
-
[34]
Zhaoxi Mu, Rilin Chen, Andong Li, Meng Yu, Xinyu Yang, and Dong Yu. 2025. From Continuous to Discrete: Cross-Domain Collaborative General Speech En- hancement via Hierarchical Language Models. InProceedings of the 33rd ACM International Conference on Multimedia. 219–228
work page 2025
-
[35]
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. LibriSpeech: an ASR corpus based on public domain audio books. In2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 5206–5210
work page 2015
-
[36]
Ankita Pasad, Bowen Shi, and Karen Livescu. 2023. Comparative layer-wise analysis of self-supervised speech models. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
work page 2023
-
[37]
Jan Pirklbauer, Marvin Sach, Kristoff Fluyt, Wouter Tirry, Wafaa Wardah, Sebas- tian Moeller, and Tim Fingscheidt. 2023. Evaluation metrics for generative speech enhancement methods: Issues and perspectives. InSpeech Communication; 15th ITG Conference. VDE, 265–269
work page 2023
-
[38]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning. PMLR, 28492–28518
work page 2023
-
[39]
ITU-T Recommendation. 2001. Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs.Rec. ITU-T P. 862(2001)
work page 2001
-
[40]
Chandan KA Reddy, Vishak Gopal, and Ross Cutler. 2022. DNSMOS P. 835: A non- intrusive perceptual objective speech quality metric to evaluate noise suppressors. InICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 886–890
work page 2022
-
[41]
Chandan K.A. Reddy, Vishak Gopal, Ross Cutler, Ebrahim Beyrami, Roger Cheng, Harishchandra Dubey, Sergiy Matusevych, Robert Aichner, Ashkan Aazami, Sebastian Braun, Puneet Rana, Sriram Srinivasan, and Johannes Gehrke. 2020. The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results. InInterspeech 2...
work page 2020
-
[42]
Xiaobin Rong, Qinwen Hu, Mansur Yesilbursa, Kamil Wojcicki, and Jing Lu. 2026. PASE: Leveraging the Phonological Prior of WavLM for Low-Hallucination Gen- erative Speech Enhancement. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 32826–32834
work page 2026
-
[43]
Takaaki Saeki, Soumi Maiti, Shinnosuke Takamichi, Shinji Watanabe, and Hiroshi Saruwatari. 2024. SpeechBERTScore: Reference-Aware Automatic Evaluation of Speech Generation Leveraging NLP Evaluation Metrics. InInterspeech 2024. 4943–4947
work page 2024
-
[44]
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2022. UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022. InInterspeech 2022. 4521–4525
work page 2022
-
[45]
Kohei Saijo, Wangyou Zhang, Samuele Cornell, Robin Scheibler, Chenda Li, Zhaoheng Ni, Anurag Kumar, Marvin Sach, Yihui Fu, Wei Wang, Tim Fingscheidt, and Shinji Watanabe. 2025. Interspeech 2025 URGENT Speech Enhancement Challenge. InInterspeech 2025. 858–862
work page 2025
-
[46]
Hubert Siuzdak. 2024. Vocos: Closing the gap between time-domain and Fourier- based neural vocoders for high-quality audio synthesis. InThe Twelfth Interna- tional Conference on Learning Representations
work page 2024
-
[47]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
- [48]
-
[49]
Yiming Wang, Jinyu Li, Heming Wang, Yao Qian, Chengyi Wang, and Yu Wu. 2022. Wav2vec-Switch: Contrastive Learning from Original-Noisy Speech Pairs for Robust Speech Recognition. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 7097–7101
work page 2022
-
[50]
Yuanyuan Wang, Dongchao Yang, Yiwen Shao, Hangting Chen, Jiankun Zhao, Zhiyong Wu, Helen Meng, and Xixin Wu. 2026. DualSpeechLM: Towards Unified Speech Understanding and Generation via Dual Speech Token Modeling with Large Language Models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 33728–33736
work page 2026
-
[51]
Ziqian Wang, Zikai Liu, Xinfa Zhu, Yike Zhu, Mingshuai Liu, Jun Chen, Longshuai Xiao, Chao Weng, and Lei Xie. 2025. FlowSE: Efficient and High-Quality Speech Enhancement via Flow Matching. InInterspeech 2025. 4858–4862
work page 2025
-
[52]
Ziqian Wang, Xinfa Zhu, Zihan Zhang, YuanJun Lv, Ning Jiang, Guoqing Zhao, and Lei Xie. 2024. SELM: Speech enhancement using discrete tokens and language models. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 11561–11565
work page 2024
-
[53]
Zhong-Qiu Wang, Samuele Cornell, Shukjae Choi, Younglo Lee, Byeong-Yeol Kim, and Shinji Watanabe. 2023. TF-GridNet: Integrating full-and sub-band modeling for speech separation.IEEE/ACM Transactions on Audio, Speech, and Language Processing31 (2023), 3221–3236
work page 2023
-
[54]
Dan Wells, Hao Tang, and Korin Richmond. 2022. Phonetic Analysis of Self- supervised Representations of English Speech. InInterspeech 2022. 3583–3587
work page 2022
-
[55]
Gordon Wichern, Joe Antognini, Michael Flynn, Licheng Richard Zhu, Emmett McQuinn, Dwight Crow, Ethan Manilow, and Jonathan Le Roux. 2019. WHAM!: Extending Speech Separation to Noisy Environments. InInterspeech 2019. 1368– 1372
work page 2019
-
[56]
Ronald J Williams and David Zipser. 1989. A learning algorithm for continually running fully recurrent neural networks.Neural computation1, 2 (1989), 270–280
work page 1989
- [57]
- [58]
-
[59]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Haici Yang, Jiaqi Su, Minje Kim, and Zeyu Jin. 2024. Genhancer: High-Fidelity Speech Enhancement via Generative Modeling on Discrete Codec Tokens. In Interspeech 2024. 1170–1174
work page 2024
-
[61]
Jixun Yao, Hexin Liu, Chen Chen, Yuchen Hu, EngSiong Chng, and Lei Xie. 2025. GenSE: Generative Speech Enhancement via Language Models using Hierarchical Modeling. InThe Thirteenth International Conference on Learning Representations
work page 2025
- [62]
-
[63]
Jianwei Yu and Yi Luo. 2023. Efficient monaural speech enhancement with universal sample rate band-split RNN. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
work page 2023
- [64]
-
[65]
Junan Zhang, Jing Yang, Zihao Fang, Yuancheng Wang, Zehua Zhang, Zhuo Wang, Fan Fan, and Zhizheng Wu. 2025. AnyEnhance: A Unified Generative Model With Prompt-Guidance and Self-Critic for Voice Enhancement.IEEE Transactions on Audio, Speech and Language Processing33 (2025), 3085–3098
work page 2025
-
[66]
Qiu-Shi Zhu, Jie Zhang, Zi-Qiang Zhang, Ming-Hui Wu, Xin Fang, and Li-Rong Dai. 2022. A noise-robust self-supervised pre-training model based speech repre- sentation learning for automatic speech recognition. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 3174–3178. Reducing Linguistic Hallucina...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.