Recognition: 1 theorem link
· Lean TheoremEvidenT: An Evidence-Preserving Framework for Iterative System-Level Package Repair
Pith reviewed 2026-05-12 01:35 UTC · model grok-4.3
The pith
EvidenT repairs over half of real-world system-level package build failures by preserving evidence across iterations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
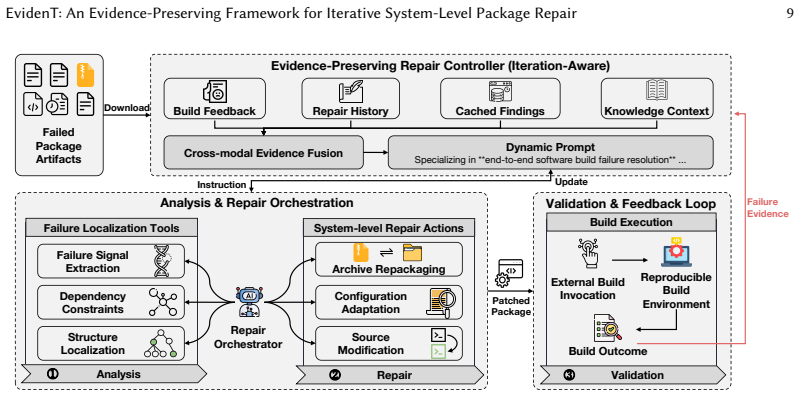
EvidenT decouples iteration-aware evidence management from tool execution through three parts: an external Build Service that supplies reproducible feedback, an Evidence-Preserving Repair Controller that fuses repair history, knowledge context, and build artifacts, and an automated Repair Orchestrator that invokes modular tools inside a closed validation loop. This design repairs 118 of 219 real RISC-V package failures (53.88 percent), outperforming state-of-the-art agentic baselines (20.55 percent) and direct LLM-based repair (1.83 percent). Updating only the ISA-specific knowledge context extends the approach to aarch64 and x86_64 with success rates of 41.77 percent and 46.99 percent.
What carries the argument
The Evidence-Preserving Repair Controller, which maintains and fuses repair history, knowledge context, and build artifacts to guide each iteration.
If this is right
- Repair success on system-level failures rises above 50 percent when evidence is retained across iterations instead of being discarded.
- Dependency and environment fixes become the primary target rather than isolated code changes.
- Adapting the framework to new processor architectures requires updating only the knowledge context.
- Closed-loop validation through an external build service produces reliable repair outcomes.
- Modular tools for localization and repair can be swapped while preserving the evidence loop.
Where Pith is reading between the lines
- Package maintainers could integrate the controller into continuous-integration pipelines to reduce manual triage time.
- The same evidence-preservation pattern may apply to runtime or configuration failures beyond build steps.
- Scaling the approach to larger ecosystems would require only architecture-specific knowledge modules rather than full retraining.
- Comparing repair logs across many packages could reveal recurring misconfiguration patterns that warrant upstream fixes.
Load-bearing premise
The 219 RISC-V build failures examined are representative of typical system-level issues and the observed 72 percent rate of dependency misconfigurations generalizes.
What would settle it
Measuring success rates below 20 percent on a new, independent collection of system-level build failures drawn from a different processor architecture or package set, without any changes to the knowledge context.
Figures


read the original abstract
Frequent toolchain updates and growing ISA diversity have made system-level software package repair increasingly important. Diagnosing and repairing build failures remains challenging because failures involve heterogeneous evidence, dependency constraints, and architecture-specific build conventions. While recent LLM-based repair methods show promise for project-level source fixes, they struggle with system-level repair, where failures span multi-language artifacts such as build recipes, scripts, and source archives, and require iterative validation through external build services. In this paper, we first conduct a systematic empirical study of real-world system-level build failures. We find that 72% of failures stem from dependency and environment misconfigurations rather than isolated code defects, suggesting that effective repair must prioritize packaging logic and iterative feedback. Motivated by these insights, we propose EvidenT, an evidence-preserving repair framework that decouples iteration-aware evidence management from tool execution. EvidenT includes: (1) an external Build Service for reproducible execution and feedback; (2) an Evidence-Preserving Repair Controller that fuses repair history, knowledge context, and build artifacts; and (3) an automated Repair Orchestrator that invokes modular tools for failure localization and system-level repair in a closed-loop validation environment. We evaluate EvidenT on 219 real-world RISC-V package build failures. EvidenT repairs 118 packages (53.88%), outperforming state-of-the-art agentic baselines (20.55%) and direct LLM-based repair (1.83%). To assess architectural generality, we extend EvidenT to legacy ISAs by updating only ISA-specific knowledge context. Preliminary experiments achieve success rates of 41.77% on aarch64 and 46.99% on x86_64, demonstrating robustness across diverse hardware ecosystems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical study of 219 real-world RISC-V package build failures, finding that 72% arise from dependency and environment misconfigurations. Motivated by this, it introduces EvidenT, a framework that separates iteration-aware evidence management from tool execution via (1) an external Build Service for reproducible builds, (2) an Evidence-Preserving Repair Controller that fuses repair history, knowledge context, and artifacts, and (3) a Repair Orchestrator that invokes modular tools in a closed loop. On the same 219 failures, EvidenT repairs 118 packages (53.88%), compared with 20.55% for agentic baselines and 1.83% for direct LLM repair; preliminary results on aarch64 and x86_64 are also reported after updating only ISA-specific context.
Significance. If the empirical claims and controlled comparisons hold, the work supplies concrete evidence that dependency misconfigurations dominate system-level build failures and demonstrates that an evidence-preserving controller plus external build service can materially improve repair rates over current LLM and agentic methods. The real-world failure corpus and the low-effort ISA extension are strengths that could influence future tool design for heterogeneous build environments.
major comments (2)
- [Evaluation] Evaluation section: the central performance claim (53.88% vs. 20.55% and 1.83%) rests on a comparison whose fairness is not established. The manuscript does not state whether the agentic baselines and direct LLM repair were granted equivalent access to the external Build Service for reproducible, iterative execution and closed-loop feedback. Because the Build Service is presented as a core enabling component, the reported delta cannot yet be attributed specifically to the Evidence-Preserving Repair Controller rather than to infrastructure differences.
- [Empirical study] Empirical study / abstract: the claim that 72% of failures stem from dependency misconfigurations is load-bearing for the motivation and design, yet the manuscript provides no description of how the 219 RISC-V failures were collected, what exclusion criteria were applied, or how the 72% figure was computed (e.g., manual labeling protocol, inter-rater agreement). Without these details the generalizability of the finding and the representativeness of the corpus remain unverifiable.
minor comments (2)
- [Abstract] Abstract: the terms 'state-of-the-art agentic baselines' and 'direct LLM-based repair' are used without citation or brief characterization; a short parenthetical description or reference would improve clarity.
- [Threats to validity] The manuscript would benefit from an explicit statement of the threat to validity regarding the RISC-V-specific corpus and any plans for broader validation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below and will revise the manuscript to improve transparency and verifiability.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central performance claim (53.88% vs. 20.55% and 1.83%) rests on a comparison whose fairness is not established. The manuscript does not state whether the agentic baselines and direct LLM repair were granted equivalent access to the external Build Service for reproducible, iterative execution and closed-loop feedback. Because the Build Service is presented as a core enabling component, the reported delta cannot yet be attributed specifically to the Evidence-Preserving Repair Controller rather than to infrastructure differences.
Authors: We agree that the current description leaves the fairness of the comparison unclear. In the revised manuscript we will add an explicit subsection under Evaluation that documents the experimental protocol for all methods. All approaches—including the agentic baselines and direct LLM repair—were granted identical access to the external Build Service for reproducible builds, iterative execution, and closed-loop feedback. The only controlled difference is the Evidence-Preserving Repair Controller itself. We will also include pseudocode and configuration details for the baselines to make the attribution of the performance delta transparent. revision: yes
-
Referee: [Empirical study] Empirical study / abstract: the claim that 72% of failures stem from dependency misconfigurations is load-bearing for the motivation and design, yet the manuscript provides no description of how the 219 RISC-V failures were collected, what exclusion criteria were applied, or how the 72% figure was computed (e.g., manual labeling protocol, inter-rater agreement). Without these details the generalizability of the finding and the representativeness of the corpus remain unverifiable.
Authors: We acknowledge that the data-collection and labeling methodology is insufficiently documented. In the revised version we will expand the Empirical Study section with: (1) the precise sources from which the 219 RISC-V build failures were obtained, (2) the exclusion criteria applied (e.g., duplicate logs, non-reproducible failures, or failures outside the target package ecosystem), (3) the categorization protocol used to label failures as dependency/environment misconfigurations versus other causes, and (4) details on the labeling process, including whether multiple authors performed independent labeling and any inter-rater agreement statistics. These additions will allow readers to assess the representativeness and generalizability of the 72% figure. revision: yes
Circularity Check
No circularity in empirical framework and evaluation
full rationale
The paper conducts an empirical study counting failure causes on 219 external RISC-V packages (72% dependency misconfigurations) and reports raw experimental success rates for EvidenT (118/219) against baselines on the same set. No mathematical derivations, fitted parameters presented as predictions, self-definitional quantities, or load-bearing self-citations appear in the chain from study to framework to results. The evaluation relies on external real-world failures and closed-loop build service execution rather than reducing to author-defined inputs or prior equations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption 72% of system-level build failures stem from dependency and environment misconfigurations rather than isolated code defects
- domain assumption Iterative validation through an external build service provides reliable feedback for repair decisions
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EvidenT comprises (1) an external Build Service for reproducible execution and feedback; (2) an Evidence-Preserving Repair Controller that fuses repair history, knowledge context, and build artifacts; and (3) an automated Repair Orchestrator...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Henri Aïdasso, Mohammed Sayagh, and Francis Bordeleau. 2025. Build Optimization: A Systematic Literature Review. Comput. Surveys58, 2 (2025), 1–38. doi:10.1145/3757912
- [2]
- [3]
-
[4]
Bihuan Chen, Hongyu Zhang, Zhenchang Zhou, Chang Xu, and Baowen Xu. 2021. BuildFast: History-Aware Build Outcome Prediction for Fast Build Triage. InProceedings of the 36th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 1025–1037
work page 2021
-
[5]
Yinfang Chen, Minghua Ma, Huaibing Xie, Yu Kang, Xin Gao, Xuchao Zhang, Liu Shi, Yunjie Cao, Xuedong Gao, Hao Fan, Ming Wen, Jun Zeng, Saravan Rajmohan, Dongmei Zhang, and Tianyin Xu. 2024. Large Language Models Can Provide Accurate and Interpretable Incident Triage. In2024 IEEE 35th International Symposium on Software Reliability Engineering (ISSRE). IEEE
work page 2024
-
[6]
Yinfang Chen, Huaibing Xie, Minghua Ma, Yu Kang, Xin Gao, Liu Shi, Yunjie Cao, Xuedong Gao, Hao Fan, Ming Wen, Jun Zeng, Supriyo Ghosh, Xuchao Zhang, Chaoyun Zhang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Tianyin Xu. 2024. Automatic Root Cause Analysis via Large Language Models for Cloud Incidents. InProceedings of the 19th European Conference o...
work page 2024
-
[7]
Jürgen Cito and H. C. Gall. 2016. Using Docker Containers to Improve Reproducibility in Software Engineering Research. Proceedings of the 38th International Conference on Software Engineering(2016), 1–10. doi:10.1145/2889160.2891057
-
[8]
Enfang Cui, Tianzheng Li, and Qian Wei. 2023. Risc-v instruction set architecture extensions: A survey.IEEE Access11 (2023), 24696–24711
work page 2023
-
[9]
Gang Fan, Chengpeng Wang, Rongxin Wu, Xiao Xiao, Qingkai Shi, and Charles Zhang. 2020. Escaping dependency hell: finding build dependency errors with the unified dependency graph. InISSTA ’20: 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual Event, USA, July 18-22, 2020, Sarfraz Khurshid and Corina S. Pasareanu (Eds.). AC...
-
[10]
Fedora Project. 2025. Koji is an RPM-based build system used by the Fedora Project and others. https://koji.build/. Accessed: 2025-09-01. , Vol. 1, No. 1, Article . Publication date: May 2026. 20 Trovato et al
work page 2025
-
[11]
Blake W Ford, Apan Qasem, Jelena Tešić, and Ziliang Zong. 2021. Migrating software from x86 to ARM Architecture: An instruction prediction approach. In2021 IEEE International Conference on Networking, Architecture and Storage (NAS). IEEE, 1–6
work page 2021
-
[12]
Apache Software Foundation. 2025. Apache Maven. https://maven.apache.org
work page 2025
-
[13]
Python Software Foundation. 2025. pip: The Python Package Installer. https://pip.pypa.io
work page 2025
-
[14]
Ryan Gibb, Patrick Ferris, David Allsopp, Michael Winston Dales, Mark Elvers, Thomas Gazagnaire, Sadiq Jaffer, Thomas Leonard, Jon Ludlam, and Anil Madhavapeddy. 2025. Solving Package Management via Hypergraph Dependency Resolution.arXiv preprint arXiv:2506.10803(2025). https://arxiv.org/abs/2506.10803
-
[15]
Foyzul Hassan, Shaikh Mostafa, Edmund S. L. Lam, and Xiaoyin Wang. 2017. Automatic Building of Java Projects in Software Repositories: A Study on Feasibility and Challenges. InProceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 379–389. doi:10.1109/ASE.2017.8115651
-
[16]
Foyzul Hassan and Xiaoyin Wang. 2018. HireBuild: an automatic approach to history-driven repair of build scripts. InProceedings of the 40th International Conference on Software Engineering, ICSE 2018, Gothenburg, Sweden, May 27 - June 03, 2018, Michel Chaudron, Ivica Crnkovic, Marsha Chechik, and Mark Harman (Eds.). ACM, 1078–1089. doi:10.1145/3180155.3180181
-
[17]
Md Hassan, Tao Wang, Shaowei Wang, and David Lo. 2019. Predicting Build Failures Using Social Network Analysis on Developer Communication. InProceedings of the 41st International Conference on Software Engineering (ICSE). ACM, 120–130
work page 2019
-
[18]
Minghua He, Tong Jia, Chiming Duan, Huaqian Cai, Ying Li, and Gang Huang. 2024. LLMeLog: An Approach for Anomaly Detection based on LLM-enriched Log Events. In2024 IEEE 35th International Symposium on Software Reliability Engineering (ISSRE). 132–143. doi:10.1109/ISSRE62328.2024.00023
-
[19]
Shilin He, Pinjia He, Zhuangbin Chen, Tianyi Yang, Yuxin Su, and Michael R. Lyu. 2021. A Survey on Automated Log Analysis for Reliability Engineering. 54, 6, Article 130 (July 2021), 37 pages. doi:10.1145/3460345
-
[20]
Jordan Henkel, Denini Silva, Leopoldo Teixeira, Marcelo d’Amorim, and Thomas W. Reps. 2021. Shipwright: A Human-in-the-Loop System for Dockerfile Repair. In43rd IEEE/ACM International Conference on Software Engineering, ICSE 2021, Madrid, Spain, 22-30 May 2021. IEEE, 1148–1160. doi:10.1109/ICSE43902.2021.00106
-
[21]
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. 2025. Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions. arXiv:2503.23278 [cs.CR] https://arxiv.org/abs/2503.23278
work page internal anchor Pith review arXiv 2025
-
[22]
Lars Huning and Elke Pulvermueller. 2021. Automatic Code Generation of Safety Mechanisms in Model-Driven Development.Electronics10, 24 (2021), 3150. https://www.mdpi.com/2079-9292/10/24/3150
work page 2021
-
[23]
IBM Research. 2023. LLM-based AI agents are what’s next. https://research.ibm.com/blog/what-are-ai-agents-llm. Accessed: 2024-09-13
work page 2023
-
[24]
Kitware. 2025. CMake: Cross-Platform Make. https://cmake.org
work page 2025
- [25]
-
[26]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. 2023. AgentBench: Evaluating LLMs as Agents.arXiv preprint arXiv:2308.03688(2023). https://arxiv.org/ abs/2308.03688
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Minghua Ma, Yinfang Chen, Huaibing Xie, Xuchao Zhang, Yu Kang, Xin Gao, Liu Shi, Yunjie Cao, Hao Fan, Ming Wen, Saravan Rajmohan, Dongmei Zhang, and Tianyin Xu. 2024. MonitorAssistant: Simplifying Cloud Service Monitoring via Large Language Models. InProceedings of the 32nd ACM SIGSOFT International Symposium on the Foundations of Software Engineering (FSE). ACM
work page 2024
-
[28]
C. Macho. 2024. DValidator: An approach for validating dependencies in build scripts.Journal of Systems and Software 195 (2024), 111916. doi:10.1016/j.jss.2023.111916
-
[29]
Ching Hang Mak and Shing-Chi Cheung. 2024. Automatic build repair for test cases using incompatible Java versions. Inf. Softw. Technol.172 (2024), 107473. doi:10.1016/J.INFSOF.2024.107473
-
[30]
Jordan Matelsky, Gregory Kiar, Erik Johnson, Corban Rivera, Michael Toma, and William Gray-Roncal. 2018. Container- Based Clinical Solutions for Portable and Reproducible Image Analysis.Journal of Digital Imaging31, 3 (2018), 315–320. doi:10.1007/s10278-018-0089-4
-
[31]
D. Moreau and K. Wiebels. 2021. Containers for Computational Reproducibility.Nature Computational Science1, 1 (2021), 1–10. doi:10.1038/s41599-020-00661-w
-
[32]
Olivier Nourry, Yutaro Kashiwa, Weiyi Shang, Honglin Shu, and Yasutaka Kamei. 2025. My Fuzzers Won’t Build: An Empirical Study of Fuzzing Build Failures.ACM Trans. Softw. Eng. Methodol.34, 2 (2025), 29:1–29:30. doi:10.1145/3688842
-
[33]
openSUSE Project. 2025. postquantumcryptoengine — openSUSE:Factory. https://build.opensuse.org/package/show/ openSUSE:Factory/postquantumcryptoengine
work page 2025
-
[34]
CMU SEI. 2025. Vessel: Reproducible Container Builds. https://www.sei.cmu.edu/documents/6315/Vessel_Fact_Sheet_ TtatchC.pdf , Vol. 1, No. 1, Article . Publication date: May 2026. EvidenT: An Evidence-Preserving Framework for Iterative System-Level Package Repair 21
work page 2025
-
[35]
Hyunsook Seo, Ahmed E. Hassan, and Michael W. Godfrey. 2021. Code Review of Build System Specifications: Prevalence, Purposes, Patterns, and Perceptions. InProceedings of the 43rd International Conference on Software Engineering (ICSE). ACM, 549–560
work page 2021
-
[36]
Hyunsook Seo, Ahmed E. Hassan, and Michael W. Godfrey. 2022. Understanding the Implications of Changes to Build Systems. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE). ACM, 1043–1054
work page 2022
-
[37]
Usman Shahid. 2025. LLM Tool Calling Series [Part 1]: Understanding Tool Calling and the Model Context Protocol (MCP). https://usmanshahid.medium.com/llm-tool-calling-series-part-1-understanding-tool-calling-and-the-model- context-protocol-mcp-911a7c422fd8. Accessed: 2025-09-01
work page 2025
-
[38]
Manish Shetty, Yinfang Chen, Gagan Somashekar, Minghua Ma, Yogesh Simmhan, Xuchao Zhang, Jonathan Mace, Dax Vandevoorde, Pedro Las-Casas, Shachee Mishra Gupta, Suman Nath, Chetan Bansal, and Saravan Rajmohan
-
[39]
InProceedings of the 15th ACM Symposium on Cloud Computing (SoCC)
Building AI Agents for Autonomous Clouds: Challenges and Design Principles. InProceedings of the 15th ACM Symposium on Cloud Computing (SoCC). ACM
-
[40]
Gengyi Sun. 2025. Intelligent Automation for Accelerating the Repair of Software Build Failures. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025 - Companion Proceedings, Ottawa, ON, Canada, April 27 - May 3, 2025. IEEE, 205–207. doi:10.1109/ICSE-COMPANION66252.2025.00062
-
[41]
Xiaojuan Tang, Zilong Zheng, Jiaqi Li, Fanxu Meng, Song-Chun Zhu, Yitao Liang, and Muhan Zhang. 2023. Large Language Models are In-Context Semantic Reasoners rather than Symbolic Reasoners. arXiv preprint arXiv:2305.14825. doi:10.48550/arXiv.2305.14825 Version v1 posted 24 May 2023; updated to v2 on 8 Jun 2023
-
[42]
Huiyan Wang, Lingyu Zhang, Yifan Wu, Xi Xu, Yinxing Liu, Tian Zhang, Lin Zhang, and Hong Mei. 2023. Automatically Resolving Dependency-Conflict Building Failures via Behavior-Consistent Loosening of Library Version Constraints. InProceedings of the 31st ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Softw...
-
[43]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. Demystifying LLM-Based Software Engineering Agents.Proc. ACM Softw. Eng.2, FSE, Article FSE037 (June 2025), 24 pages. doi:10.1145/3715754
-
[44]
Zhengmin Yu, Yuan Zhang, Ming Wen, Yinan Nie, Wenhui Zhang, and Min Yang. 2025. CXXCrafter: An LLM-Based Agent for Automated C/C++ Open Source Software Building.Proceedings of the ACM on Software Engineering2, FSE (June 2025), 2618–2640. doi:10.1145/3729386
- [45]
-
[46]
Chen Zhang, Bihuan Chen, Junhao Hu, Xin Peng, and Wenyun Zhao. 2022. BuildSonic: Detecting and Repair- ing Performance-Related Configuration Smells for Continuous Integration Builds. In37th IEEE/ACM International Conference on Automated Software Engineering, ASE 2022, Rochester, MI, USA, October 10-14, 2022. ACM, 18:1–18:13. doi:10.1145/3551349.3556923
-
[47]
Lecheng Zheng, Zhengzhang Chen, Jingrui He, and Haifeng Chen. 2024. MULAN: Multi-modal Causal Structure Learning and Root Cause Analysis for Microservice Systems. InProceedings of the ACM Web Conference 2024(Singapore, Singapore)(WWW ’24). Association for Computing Machinery, New York, NY, USA, 4107–4116. doi:10.1145/3589334. 3645442 , Vol. 1, No. 1, Arti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.