Recognition: no theorem link
Kinematics-Driven Gaussian Shape Deformation for Blurry Monocular Dynamic Scenes
Pith reviewed 2026-05-12 00:50 UTC · model grok-4.3
The pith
Kinematics-GS reconstructs dynamic 3D scenes from blurry monocular videos by reparameterizing Gaussian shapes along motion trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Kinematics-GS models blur as motion-aligned deformation and introduces a kinematic prior to reparameterize Gaussian shapes along motion trajectories, thereby mitigating degenerate shape collapse without auxiliary motion supervision. Scenes are decomposed into dynamic and static components using temporal deformation variance, and a coarse-to-fine deformation strategy captures both global motion and fine-grained details.
What carries the argument
The kinematic prior that reparameterizes Gaussian shapes along motion trajectories to treat blur as aligned deformation.
If this is right
- Enables reconstruction of non-rigid dynamic scenes from monocular videos without auxiliary motion supervision.
- Handles complex motions with spatially non-uniform blur while maintaining geometric consistency.
- Decomposes scenes into dynamic and static parts based on temporal deformation variance to stabilize training.
- Captures both large-scale motion and fine details through a coarse-to-fine deformation process.
- Provides a new real-world benchmark dataset of deformable objects with motion blur for future comparisons.
Where Pith is reading between the lines
- Everyday smartphone videos could become usable sources for 3D models of moving objects if the kinematic reparameterization generalizes beyond the tested cases.
- The static-dynamic split based on deformation variance might apply to other time-varying reconstruction problems where motion is uneven.
- Elastic and deformable objects in the new dataset point toward possible use in simulation or robotics tasks involving soft-body motion from blurry input.
Load-bearing premise
That blur arises only from motion-aligned deformation of the Gaussians and that a kinematic prior is enough to stop shape collapse when no other motion information is given.
What would settle it
Running the method on videos where blur does not match actual object trajectories and checking whether Gaussian shapes still collapse or reconstruction accuracy drops sharply compared to methods that use explicit motion labels.
Figures








read the original abstract
Reconstructing dynamic 3D scenes from blurry monocular videos is challenging as motion-induced blur entangles object motion and geometry, hindering geometric consistency. We present Kinematics-GS, a kinematics-aware framework that models blur as motion-aligned deformation and introduces a kinematic prior to reparameterize Gaussian shapes along motion trajectories, thereby mitigating degenerate shape collapse without auxiliary motion supervision. To stabilize optimization, we decompose scenes into dynamic and static components using temporal deformation variance and employ a coarse-to-fine deformation strategy to capture both global motion and fine-grained details. We also introduce a challenging real-world dataset of deformable and elastic objects exhibiting non-rigid motion with spatially non-uniform motion blur that obscures geometric cues. Extensive experiments on real-world benchmarks with realistic motion blur demonstrate that Kinematics-GS outperforms prior methods by a clear margin in monocular dynamic scene reconstruction, highlighting its effectiveness in handling complex and non-rigid motion scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Kinematics-GS, a kinematics-aware framework for 3D reconstruction of dynamic scenes from blurry monocular videos. It models motion blur as motion-aligned deformation of 3D Gaussians and introduces a kinematic prior that reparameterizes Gaussian shapes along estimated motion trajectories to mitigate degenerate shape collapse without auxiliary motion supervision. Scenes are decomposed into dynamic and static components using temporal deformation variance, optimized via a coarse-to-fine deformation schedule. A new real-world dataset of deformable/elastic objects with non-rigid motion and spatially varying blur is introduced, and the method is claimed to outperform prior approaches on real-world benchmarks with realistic motion blur.
Significance. If the central claims hold after addressing the decomposition stability, the work would contribute a supervision-light approach to a difficult inverse problem in dynamic neural rendering. The kinematic reparameterization idea and the new dataset of non-rigid objects with non-uniform blur are positive elements that could support future research on blur-aware reconstruction. The absence of any quantitative metrics, ablation tables, or error analysis in the abstract, however, makes it impossible to gauge whether the performance margin is meaningful or whether the kinematic prior actually delivers the claimed robustness.
major comments (2)
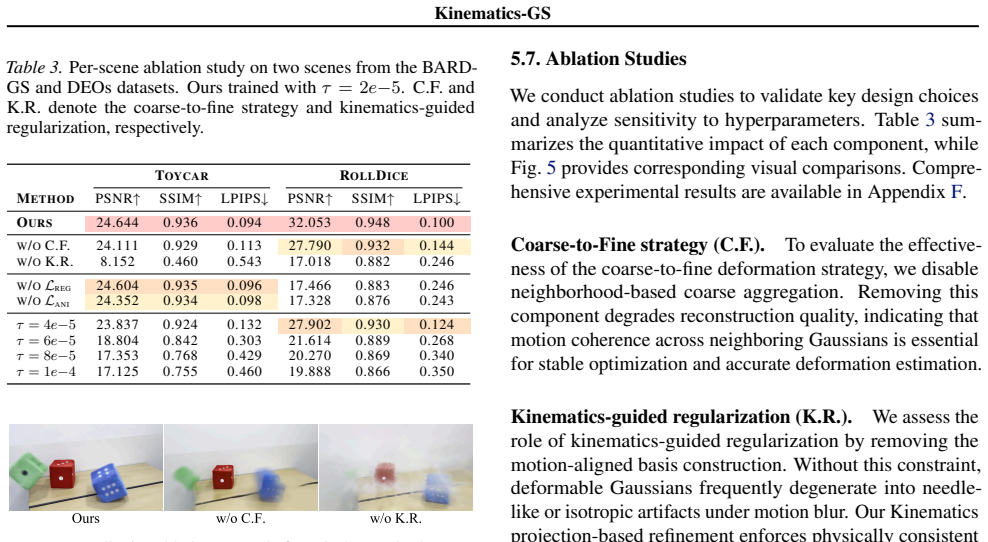
- [Method section on scene decomposition and temporal deformation variance] The scene decomposition step (described after the kinematic prior) computes temporal deformation variance directly from the Gaussian deformation field that is being jointly optimized. This creates a potential circular dependency: an early shape collapse or poor initialization can produce unreliable variance values, misclassifying regions and depriving the kinematic prior of the trajectories it requires. The coarse-to-fine schedule is mentioned but no analysis or ablation is supplied to show that the dependency is broken. This issue is load-bearing for the central claim of operating without auxiliary motion supervision.
- [Abstract and Experiments section] The abstract asserts that Kinematics-GS 'outperforms prior methods by a clear margin,' yet the provided text contains no quantitative results, PSNR/SSIM tables, error analysis, or ablation studies. Without these, the central performance claim cannot be evaluated. The full manuscript must include detailed comparisons on both existing benchmarks and the new dataset, together with ablations isolating the kinematic prior and the decomposition step.
minor comments (2)
- [Method] The notation for the kinematic reparameterization (motion trajectory alignment of Gaussian covariances) should be presented with an explicit equation in the main text rather than deferred to the appendix.
- [Dataset section] The description of the new dataset would benefit from a table summarizing scene count, motion types, blur characteristics, and ground-truth availability.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our manuscript. We address the two major comments point by point below and will make the necessary revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Method section on scene decomposition and temporal deformation variance] The scene decomposition step (described after the kinematic prior) computes temporal deformation variance directly from the Gaussian deformation field that is being jointly optimized. This creates a potential circular dependency: an early shape collapse or poor initialization can produce unreliable variance values, misclassifying regions and depriving the kinematic prior of the trajectories it requires. The coarse-to-fine schedule is mentioned but no analysis or ablation is supplied to show that the dependency is broken. This issue is load-bearing for the central claim of operating without auxiliary motion supervision.
Authors: We acknowledge the referee's concern regarding the potential circular dependency in the scene decomposition. To clarify, our coarse-to-fine deformation strategy begins with a global motion optimization phase that uses a uniform kinematic prior across all Gaussians, establishing initial motion trajectories independently of the variance computation. The temporal deformation variance is then calculated based on these initial deformations to classify dynamic and static regions. This sequential process is intended to prevent early misclassifications from affecting the kinematic prior. We will add a detailed analysis and ablation study in the revised manuscript to empirically demonstrate the stability and effectiveness of this approach in breaking any potential dependency. revision: yes
-
Referee: [Abstract and Experiments section] The abstract asserts that Kinematics-GS 'outperforms prior methods by a clear margin,' yet the provided text contains no quantitative results, PSNR/SSIM tables, error analysis, or ablation studies. Without these, the central performance claim cannot be evaluated. The full manuscript must include detailed comparisons on both existing benchmarks and the new dataset, together with ablations isolating the kinematic prior and the decomposition step.
Authors: We agree that the abstract's performance claim would benefit from supporting quantitative evidence to allow proper evaluation. We will revise the manuscript to include a summary of key quantitative results (such as PSNR and SSIM improvements) directly in the abstract. Additionally, we will ensure the Experiments section provides detailed tables with comparisons to prior methods on existing benchmarks and the new dataset, along with comprehensive ablations isolating the contributions of the kinematic prior and the decomposition step, including error analysis. revision: yes
Circularity Check
No significant circularity; decomposition uses computed variance but does not reduce claims to self-fit by construction
full rationale
The abstract describes decomposing scenes into dynamic/static components using temporal deformation variance computed from the Gaussian deformation field, followed by coarse-to-fine strategy and kinematic reparameterization. This creates an optimization dependency where the split relies on the field being optimized, but the paper does not present the variance computation or split as a fitted parameter renamed as prediction, nor does it reduce the kinematic prior or blur modeling to a self-definition. No self-citation chains, uniqueness theorems, or ansatz smuggling are evident in the given text. The central claim of mitigating shape collapse without auxiliary supervision rests on the kinematic prior itself, which draws from external motion concepts rather than closing on its own outputs. This matches the default expectation of non-circular papers with only minor optimization interdependence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[7]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
- [8]
-
[9]
ACM Transactions on Graphics (TOG) , volume=
3D Gaussian splatting for real-time radiance field rendering , author=. ACM Transactions on Graphics (TOG) , volume=
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[11]
ACM Transactions on Computer Graphics and Interactive Techniques , volume=
Deblur-GS: 3D Gaussian Splatting from Camera Motion Blurred Images , author=. ACM Transactions on Computer Graphics and Interactive Techniques , volume=. 2024 , publisher=
work page 2024
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Deblur-nerf: Neural radiance fields from blurry images , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Dp-nerf: Deblurred neural radiance field with physical scene priors , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Bad-nerf: Bundle adjusted deblur neural radiance fields , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[15]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Exblurf: Efficient radiance fields for extreme motion blurred images , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[16]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Deblurring 3d gaussian splatting , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=. 2024 , organization=
work page 2024
-
[17]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Blind image deconvolution using variational deep image prior , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[18]
Knowledge-Based Systems , volume=
A deep variational Bayesian framework for blind image deblurring , author=. Knowledge-Based Systems , volume=. 2022 , publisher=
work page 2022
-
[19]
Communications of the ACM , volume=
Nerf: Representing scenes as neural radiance fields for view synthesis , author=. Communications of the ACM , volume=. 2021 , publisher=
work page 2021
-
[20]
ACM Transactions on Graphics (TOG) , volume =
Embedded Deformation for Shape Manipulation , author =. ACM Transactions on Graphics (TOG) , volume =
-
[21]
Symposium on Geometry processing , volume=
As-rigid-as-possible surface modeling , author=. Symposium on Geometry processing , volume=. 2007 , organization=
work page 2007
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
4d visualization of dynamic events from unconstrained multi-view videos , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Neural 3d video synthesis from multi-view video , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Neural radiance flow for 4d view synthesis and video processing , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[25]
IEEE Transactions on Visualization and Computer Graphics (TVCG) , year=
Decoupling dynamic monocular videos for dynamic view synthesis , author=. IEEE Transactions on Visualization and Computer Graphics (TVCG) , year=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Novel view synthesis of dynamic scenes with globally coherent depths from a monocular camera , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[27]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
Deblur-NSFF: Neural Scene Flow Fields for Blurry Dynamic Scenes , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Spacetime gaussian feature splatting for real-time dynamic view synthesis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Dynpoint: Dynamic neural point for view synthesis , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Neural scene flow fields for space-time view synthesis of dynamic scenes , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[31]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
Point-dynrf: Point-based dynamic radiance fields from a monocular video , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
-
[32]
arXiv preprint arXiv:2402.03307 , year=
4d gaussian splatting: Towards efficient novel view synthesis for dynamic scenes , author=. arXiv preprint arXiv:2402.03307 , year=
-
[33]
arXiv preprint arXiv:2308.09713 , year=
Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis , author=. arXiv preprint arXiv:2308.09713 , year=
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
4d gaussian splatting for real-time dynamic scene rendering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[35]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Real-time photorealistic dynamic scene representation and rendering with 4D gaussian splatting , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Colmap-free 3d gaussian splatting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Structure-from-motion revisited , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[38]
arXiv preprint arXiv:2401.05055 , year=
Application of Deep Learning in Blind Motion Deblurring: Current Status and Future Prospects , author=. arXiv preprint arXiv:2401.05055 , year=
-
[39]
Peterson, Leif , year =. K-nearest neighbor , volume =. Scholarpedia , doi =
-
[40]
and Szeliski, Richard , title =
Snavely, Noah and Seitz, Steven M. and Szeliski, Richard , title =. 2006 , issue_date =. doi:10.1145/1141911.1141964 , journal =
-
[41]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Non-rigid neural radiance fields: Reconstruction and novel view synthesis of a dynamic scene from monocular video , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[42]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Neo 360: Neural fields for sparse view synthesis of outdoor scenes , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Nope-nerf: Optimising neural radiance field with no pose prior , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[44]
IEEE Transactions on Image Processing , volume=
Image quality assessment: from error visibility to structural similarity , author=. IEEE Transactions on Image Processing , volume=. 2004 , publisher=
work page 2004
-
[45]
Scope of validity of PSNR in image/video quality assessment , author=. Electronics letters , volume=. 2008 , publisher=
work page 2008
-
[46]
Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR) , pages=
The unreasonable effectiveness of deep features as a perceptual metric , author=. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[47]
Understanding the difficulty of training deep feedforward neural networks , author =. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =. 2010 , editor =
work page 2010
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Restormer: Efficient Transformer for High-Resolution Image Restoration , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[49]
Knapitsch, Arno and Park, Jaesik and Zhou, Qian-Yi and Koltun, Vladlen , title =. ACM Trans. Graph. , month = jul, articleno =. 2017 , issue_date =. doi:10.1145/3072959.3073599 , abstract =
-
[50]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Gaussian splatting on the move: Blur and rolling shutter compensation for natural camera motion , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=. 2024 , organization=
work page 2024
-
[51]
arXiv preprint arXiv:2404.12547 , year=
Evaluating alternatives to sfm point cloud initialization for gaussian splatting , author=. arXiv preprint arXiv:2404.12547 , year=
-
[52]
ACM Transactions on Graphics , volume =
View Interpolation for Image Synthesis , author =. ACM Transactions on Graphics , volume =
-
[53]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Extreme view synthesis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[54]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Gao, Chen and Saraf, Ayush and Kopf, Johannes and Huang, Jia-Bin , Title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[55]
arXiv preprint arXiv:2312.13528 , year=
DyBluRF: Dynamic Deblurring Neural Radiance Fields for Blurry Monocular Video , author=. arXiv preprint arXiv:2312.13528 , year=
- [56]
-
[57]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
3d-aware image generation using 2d diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[58]
arXiv preprint arXiv:2210.04628 , year=
Novel view synthesis with diffusion models , author=. arXiv preprint arXiv:2210.04628 , year=
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
MultiDiff: Consistent Novel View Synthesis from a Single Image , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
3d geometry-aware deformable gaussian splatting for dynamic view synthesis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[61]
Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Bard-gs: Blur-aware reconstruction of dynamic scenes via gaussian splatting , author=. Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[62]
Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction , author=. Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Hexplane: A fast representation for dynamic scenes , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[64]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Per-gaussian embedding-based deformation for deformable 3d gaussian splatting , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=. 2024 , organization=
work page 2024
-
[65]
Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , pages=
LITA-GS: Illumination-Agnostic Novel View Synthesis via Reference-Free 3D Gaussian Splatting and Physical Priors , author=. Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[66]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Dynamic 3d scene analysis by point cloud accumulation , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=. 2022 , organization=
work page 2022
-
[67]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Pumarola, Albert and Corona, Enric and Pons-Moll, Gerard and Moreno-Noguer, Francesc , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2021 , pages =
work page 2021
-
[68]
Deblur4DGS: 4D Gaussian splatting from blurry monocular video.arXiv preprint arXiv:2412.06424,
Deblur4DGS: 4D gaussian splatting from blurry monocular video , author=. arXiv preprint arXiv:2412.06424 , year=
-
[69]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Motiongs: Exploring explicit motion guidance for deformable 3d gaussian splatting , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[70]
arXiv preprint arXiv:2504.15122 , year=
MoBGS: Motion Deblurring Dynamic 3D Gaussian Splatting for Blurry Monocular Video , author=. arXiv preprint arXiv:2504.15122 , year=
-
[71]
Modgs: Dynamic gaussian splatting from causually-captured monocular videos , author=. arXiv e-prints , pages=
- [72]
-
[73]
Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Mip-splatting: Alias-free 3d gaussian splatting , author=. Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[74]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[75]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Zip-nerf: Anti-aliased grid-based neural radiance fields , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[76]
Octree-gs: Towards consistent real-time rendering with lod-structured 3d gaussians , author=. arXiv preprint arXiv:2403.17898 , year=
-
[77]
arXiv preprint arXiv:2507.00554 , year=
LOD-GS: Level-of-detail-sensitive 3D gaussian splatting for detail conserved anti-aliasing , author=. arXiv preprint arXiv:2507.00554 , year=
-
[78]
arXiv preprint arXiv:2505.23158 (2025) 4
LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering , author=. arXiv preprint arXiv:2505.23158 , year=
-
[79]
ACM Transactions on Graphics (TOG) , number =
FLoD: Integrating Flexible Level of Detail into 3D Gaussian Splatting for Customizable Rendering , author=. ACM Transactions on Graphics (TOG) , number =
-
[80]
Computer Graphics Forum , pages=
Learning fast 3D gaussian splatting rendering using continuous level of detail , author=. Computer Graphics Forum , pages=. 2025 , organization=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.