Recognition: no theorem link
Fitting Multilinear Polynomials for Logic Gate Networks
Pith reviewed 2026-05-12 01:55 UTC · model grok-4.3
The pith
Logic gate networks learn by fitting four-coefficient multilinear polynomials per neuron instead of selecting from a sixteen-gate codebook.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
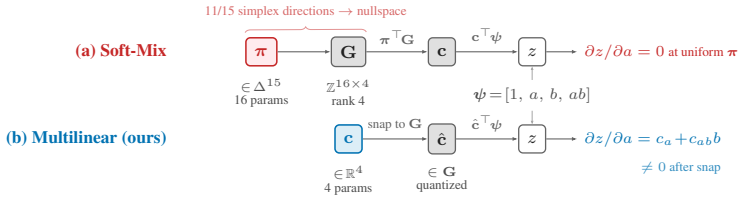
Working directly in the four-dimensional space of multilinear polynomials that span the sixteen possible 2-input Boolean gates reduces each logic neuron to four parameters. The covariance Jacobian of soft-VQ selection supplies gradients to the interaction coefficients by coupling them to the constant term, bypassing the starvation that occurs under STE with softmax or affine reparameterizations. On seven datasets this four-parameter formulation matches or exceeds the sixteen-parameter baseline, with the performance gap widening monotonically with interaction demand and remaining stable at twelve layers while the baseline drops sharply.
What carries the argument
The covariance Jacobian of soft-VQ selection in the four-dimensional multilinear polynomial space, which couples interaction coefficients to the constant channel to restore gradients.
If this is right
- Each neuron requires only four learnable parameters rather than sixteen.
- The performance advantage over softmax selection increases with the interaction demand of the task.
- Accuracy remains nearly constant when depth rises from shallow to twelve layers on CIFAR-10 and MNIST.
- No affine product reparameterization can restore the missing interaction-coefficient gradients under straight-through estimation.
- At least one four-parameter variant matches or exceeds the baseline across all seven evaluated datasets.
Where Pith is reading between the lines
- The same low-rank codebook structure may appear in other discrete selection problems inside neural networks, suggesting the covariance-Jacobian fix could transfer.
- Explicit four-parameter gate representations could enable direct mapping to hardware logic circuits without additional discretization steps.
- Testing on networks deeper than twelve layers or on tasks with still higher interaction complexity would reveal whether the gradient coupling scales without bound.
Load-bearing premise
The observed rank-four structure of the gate codebook together with the coupling supplied by the covariance Jacobian will keep providing usable gradients for arbitrary interaction demands and network depths.
What would settle it
A dataset or depth at which the covariance-Jacobian method produces vanishing gradients or collapses in accuracy while the interaction structure remains unchanged.
Figures






read the original abstract
We study learnable logic gate networks that stack layers of 2-input Boolean gates to build combinational circuits. Every 2-input gate has a unique multilinear polynomial with 4 coefficients, so the 16 Boolean gates form a codebook of prototypes in a 4-dimensional space, reducing training to a vector-quantization problem. The baseline method, Soft-Mix, learns a 16-dimensional softmax over gate identities, but the codebook has rank~4: 11 of 15 simplex directions carry nullspace gradient, and at uniform initialization the backward signal vanishes exactly. We prove that no affine product reparameterization fixes the resulting interaction-coefficient starvation under STE, and show that the covariance Jacobian of soft-VQ selection bypasses it by coupling the starved coefficient to the always-active constant channel. Working in the 4-dimensional polynomial space reduces each neuron from 16 to 4 parameters. On seven datasets, at least one 4-parameter method matches or exceeds Soft-Mix on every dataset; the CovJac advantage over STE grows monotonically with interaction demand across all seven datasets. At depth, Soft-Mix collapses ($-37.3$pp on CIFAR-10 at 12 layers) while CovJac holds ($-0.5$pp on CIFAR-10, stable on MNIST).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper studies learnable logic gate networks by representing 2-input Boolean gates as multilinear polynomials, forming a 4-dimensional codebook that reduces parameters per neuron to 4. It identifies that the Soft-Mix baseline suffers from nullspace gradients under the straight-through estimator due to the rank-4 structure of the codebook, proves that no affine product reparameterization can resolve the resulting interaction-coefficient starvation, and proposes using the covariance Jacobian from soft vector quantization to couple the starved coefficients to the constant channel. Experiments on seven datasets demonstrate that 4-parameter methods are competitive with or better than Soft-Mix, with the CovJac method showing increasing advantage as interaction demand grows and maintaining performance at greater network depths where Soft-Mix collapses.
Significance. The work provides a theoretically motivated approach to improving gradient flow in logic gate networks through polynomial reparameterization and Jacobian-based selection. If the proof holds and the empirical findings are confirmed with additional controls, it could enable more efficient and deeper combinational circuit learning models, with clear benefits in parameter efficiency and depth scalability on tasks like image classification.
major comments (3)
- Abstract: the claim that 'we prove that no affine product reparameterization fixes the resulting interaction-coefficient starvation under STE' is load-bearing for the motivation of CovJac, yet the full derivation is absent from the provided text and must be supplied with all intermediate steps to allow verification.
- Empirical results: the reported consistent gains across seven datasets and the depth-dependent divergence (e.g., -37.3pp collapse for Soft-Mix on CIFAR-10) lack error bars, run counts, and ablations isolating the covariance Jacobian contribution, which are required to substantiate robustness beyond the tested interaction demands.
- Method description: the covariance Jacobian bypass mechanism (coupling starved coefficients to the constant channel) is asserted but requires explicit matrix derivation and Jacobian form to confirm it indeed supplies usable gradients where STE nullspace gradients vanish.
minor comments (2)
- Abstract: the statement that 'at least one 4-parameter method matches or exceeds Soft-Mix on every dataset' should name the specific methods and include the corresponding quantitative margins for the depth and interaction-demand claims.
- Notation: define STE, VQ, and CovJac at first use and clarify the exact mapping from the 4D polynomial coefficients to the 16 gate prototypes with an example equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each of the major comments below and commit to revising the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: Abstract: the claim that 'we prove that no affine product reparameterization fixes the resulting interaction-coefficient starvation under STE' is load-bearing for the motivation of CovJac, yet the full derivation is absent from the provided text and must be supplied with all intermediate steps to allow verification.
Authors: We recognize that the full derivation of the proof was not provided with sufficient detail in the manuscript text. We will supply the complete proof, including all intermediate steps, in the revised version to allow full verification of the claim. revision: yes
-
Referee: Empirical results: the reported consistent gains across seven datasets and the depth-dependent divergence (e.g., -37.3pp collapse for Soft-Mix on CIFAR-10) lack error bars, run counts, and ablations isolating the covariance Jacobian contribution, which are required to substantiate robustness beyond the tested interaction demands.
Authors: We agree that error bars, run counts, and isolating ablations are important for substantiating the results. We will add these to the revised manuscript, including standard deviations from multiple runs and ablations comparing the covariance Jacobian contribution. revision: yes
-
Referee: Method description: the covariance Jacobian bypass mechanism (coupling starved coefficients to the constant channel) is asserted but requires explicit matrix derivation and Jacobian form to confirm it indeed supplies usable gradients where STE nullspace gradients vanish.
Authors: We agree that an explicit derivation is needed. In the revision, we will include the detailed matrix derivation of the covariance Jacobian and explain its form to show how it supplies gradients to the starved coefficients. revision: yes
Circularity Check
No significant circularity: mathematical derivations and reparameterizations are self-contained
full rationale
The paper's core chain consists of (1) representing 2-input gates as unique multilinear polynomials (a standard algebraic fact, not derived from data), (2) observing the rank-4 structure of the resulting 16-point codebook (direct linear-algebra consequence of the 4-coefficient basis), (3) a stated proof that no affine product reparameterization resolves STE nullspace gradients, and (4) derivation of the covariance Jacobian from the soft-VQ selection rule itself, which couples coefficients to the constant term by construction of the polynomial representation. None of these steps reduces a claimed prediction or advantage to a fitted parameter or to a self-citation whose content is unverified. The experimental results on seven datasets are presented as empirical validation of the bypass mechanism rather than as the source of the mechanism. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep differentiable logic gate networks
Felix Petersen, Christian Borgelt, Hilde Kuehne, and Oliver Deussen. Deep differentiable logic gate networks. InAdvances in Neural Information Processing Systems, volume 35, 2022
work page 2022
-
[2]
Convo- lutional differentiable logic gate networks
Felix Petersen, Hilde Kuehne, Christian Borgelt, Julian Welzel, and Stefano Ermon. Convo- lutional differentiable logic gate networks. InAdvances in Neural Information Processing Systems, 2024. arXiv:2411.04732
-
[3]
Marta Andronic and George A. Constantinides. PolyLUT: Learning piecewise polynomials for ultra-low latency FPGA LUT-based inference. InInternational Conference on Field Programmable Technology (ICFPT), pages 60–68, 2023
work page 2023
-
[4]
Alan T. L. Bacellar, Zachary Susskind, Mauricio Breternitz Jr, Eugene John, Lizy Kurian John, Priscila Machado Vieira Lima, and Felipe M. G. França. Differentiable weightless neural networks. InInternational Conference on Machine Learning (ICML), 2024. Differentiable training ofk-input weightless lookup tables on FPGA-targeted classifiers
work page 2024
-
[5]
Stasys Jukna.Boolean Function Complexity: Advances and Frontiers, volume 27 ofAlgorithms and Combinatorics. Springer, 2012. doi: 10.1007/978-3-642-24508-4
-
[6]
Hammer and Sergiu Rudeanu.Boolean Methods in Operations Research and Related Areas
Peter L. Hammer and Sergiu Rudeanu.Boolean Methods in Operations Research and Related Areas. Springer, Berlin, Heidelberg, 1968. doi: 10.1007/978-3-642-85823-9
-
[7]
Multilinear extensions of games.Management Science, 18(5-Part-2):P64–P79,
Guillermo Owen. Multilinear extensions of games.Management Science, 18(5-Part-2):P64–P79,
-
[8]
doi: 10.1287/mnsc.18.5.64
-
[9]
DARTS: Differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Differentiable architecture search. InInternational Conference on Learning Representations, 2019
work page 2019
-
[10]
Youngsung Kim. Align forward, adapt backward: Closing the discretization gap in logic gate networks.arXiv preprint arXiv:2603.14157, 2026
-
[11]
Youngsung Kim. Towards narrowing the generalization gap in deep boolean networks.arXiv preprint arXiv:2409.05905, 2024
-
[12]
Categorical reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with Gumbel-Softmax. InInternational Conference on Learning Representations, 2017
work page 2017
-
[13]
Maddison, Andriy Mnih, and Yee Whye Teh
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous re- laxation of discrete random variables. InInternational Conference on Learning Representations, 2017
work page 2017
-
[14]
Estimating or propagating gradients through stochastic neurons for conditional computation, 2013
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation, 2013
work page 2013
-
[15]
Deep stochastic logic gate networks.IEEE Access, 11:122488–122501, 2023
Youngsung Kim. Deep stochastic logic gate networks.IEEE Access, 11:122488–122501, 2023. doi: 10.1109/ACCESS.2023.3328622. 10
-
[16]
Mind the gap: Removing the discretization gap in differentiable logic gate networks
Shakir Yousefi, Andreas Plesner, Till Aczel, and Roger Wattenhofer. Mind the gap: Removing the discretization gap in differentiable logic gate networks. InAdvances in Neural Information Processing Systems, 2025. arXiv:2506.07500
-
[17]
Light differentiable logic gate networks
Lukas Rüttgers, Till Aczel, Andreas Plesner, and Roger Wattenhofer. Light differentiable logic gate networks. InInternational Conference on Learning Representations, 2026. arXiv:2510.03250
-
[18]
Cambridge University Press, Cambridge, UK,
Ryan O’Donnell.Analysis of Boolean Functions. Cambridge University Press, Cambridge, UK,
-
[19]
doi: 10.1017/CBO9781139814782
-
[20]
Ilya M. Sobol’. Sensitivity estimates for nonlinear mathematical models.Mathematical Modelling and Computational Experiments, 1(4):407–414, 1993
work page 1993
-
[21]
Art B. Owen. Variance components and generalized Sobol’ indices.SIAM/ASA Journal on Uncertainty Quantification, 1(1):19–41, 2013. doi: 10.1137/120876782
-
[22]
Neural discrete representation learning
Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[23]
Soft-to-hard vector quantization for end-to-end learning compressible representations
Eirikur Agustsson, Fabian Mentzer, Michael Tschannen, Lukas Cavigelli, Radu Timofte, Luca Benini, and Luc Van Gool. Soft-to-hard vector quantization for end-to-end learning compressible representations. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[24]
Minyoung Huh, Brian Cheung, Pulkit Agrawal, and Phillip Isola. Straightening out the straight- through estimator: Overcoming optimization challenges in vector quantized networks. In International Conference on Machine Learning, 2023
work page 2023
-
[25]
Yves Crama and Peter L. Hammer.Boolean Functions: Theory, Algorithms, and Applications, volume 142 ofEncyclopedia of Mathematics and its Applications. Cambridge University Press,
-
[26]
doi: 10.1017/CBO9780511852008
-
[27]
Bishop.Pattern Recognition and Machine Learning
Christopher M. Bishop.Pattern Recognition and Machine Learning. Springer, 2006
work page 2006
-
[28]
UCI machine learning repository, 2019
Dheeru Dua and Casey Graff. UCI machine learning repository, 2019
work page 2019
-
[29]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
work page 1998
-
[30]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y . Ng. Reading digits in natural images with unsupervised feature learning. InNIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011
work page 2011
-
[31]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[32]
Sebastian B. Thrun et al. The MONK’s problems: A performance comparison of different learning algorithms. Technical Report CMU-CS-91-197, Carnegie Mellon University, 1991
work page 1991
-
[33]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations, 2015
work page 2015
-
[34]
Kluwer Academic Publishers, Dordrecht, 2000
Erich Peter Klement, Radko Mesiar, and Endre Pap.Triangular Norms, volume 8 ofTrends in Logic. Kluwer Academic Publishers, Dordrecht, 2000. doi: 10.1007/978-94-015-9540-7
-
[35]
Emile van Krieken, Erman Acar, and Frank van Harmelen. Analyzing differentiable fuzzy logic operators.Artificial Intelligence, 302:103602, 2022. doi: 10.1016/j.artint.2021.103602
-
[36]
ProbLog: A probabilistic Prolog and its application in link discovery
Luc De Raedt, Angelika Kimmig, and Hannu Toivonen. ProbLog: A probabilistic Prolog and its application in link discovery. InInternational Joint Conference on Artificial Intelligence (IJCAI), pages 2462–2467, 2007
work page 2007
-
[37]
Probabilistic circuits: A unifying framework for tractable probabilistic models
YooJung Choi, Antonio Vergari, and Guy Van den Broeck. Probabilistic circuits: A unifying framework for tractable probabilistic models. 2020. 11
work page 2020
-
[38]
Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks. InAdvances in Neural Information Processing Systems, volume 29, 2016
work page 2016
-
[39]
XNOR-Net: Ima- geNet classification using binary convolutional neural networks
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. XNOR-Net: Ima- geNet classification using binary convolutional neural networks. InEuropean Conference on Computer Vision (ECCV), pages 525–542, 2016
work page 2016
-
[40]
Tiny ImageNet visual recognition challenge
Ya Le and Xuan Yang. Tiny ImageNet visual recognition challenge. 2015. CS231N Course Report, Stanford University. A Full Proofs Notation.For each of the 16 Boolean functions gj :{0,1} 2 → {0,1} (indexed j= 0, . . . ,15 by the truth-table bit pattern), we write its unique multilinear representation gj(a, b) =c 0,j +c a,j a+c b,j b+c ab,j ab, with coefficie...
work page 2015
-
[41]
At initialization, every neuron has π(l) near uniform, so by the near-uniform bound after Proposition 2, its input Jacobian∂z (l)/∂(a(l), b(l))has small norm
-
[42]
, L to already have non-trivial input Jacobians
A layer l can commit (move its π(l) away from uniform) only if it receives a non-trivial π- gradient, which requires ∂L/∂z (l) to be non-trivial, which in turn requires layersl+1, . . . , L to already have non-trivial input Jacobians
-
[43]
all intermediate layers are simultaneously near-uniform throughout training
Hence commitment proceeds greedily from the output layer toward the input layer. At sufficient depth, early layers may never commit within a finite training budget. Assumptions used.(a) No residual/skip connections; (b) near-uniform initialization of gate logits; (c) the analysis is dynamical, not a static worst-case bound; (d) the gradient path of intere...
work page 1928
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.