Recognition: 2 theorem links
· Lean TheoremA Learning Method for Symbolic Systems Using Large Language Models
Pith reviewed 2026-05-12 01:29 UTC · model grok-4.3
The pith
Large language models can mine reusable symbolic tactics from proofs to boost theorem provers like CoqHammer by nearly 24 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
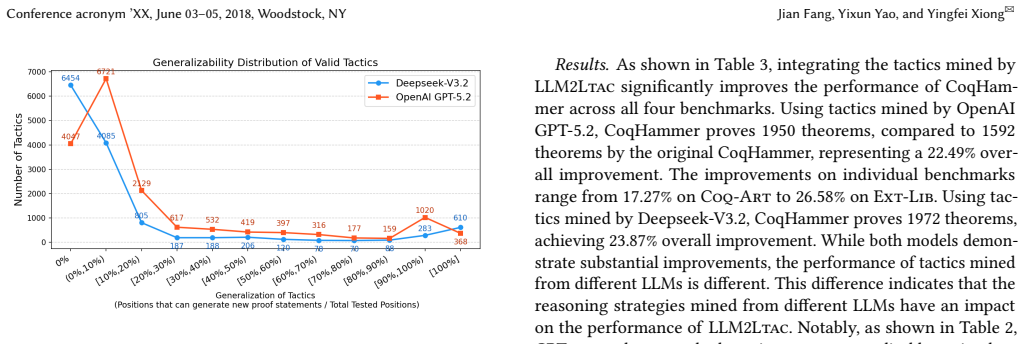
LLM2Ltac prompts an LLM to identify latent proof strategies within a corpus of 11,725 theorems drawn from the Coq standard library, then formalizes those strategies into verified, reusable tactics. When the resulting tactics are added to CoqHammer, the prover succeeds on 23.87 percent more theorems from the evaluation set of 6,199 theorems taken from CompCert, Coq-Art, Ext-Lib, and VFA. Integrating the enhanced CoqHammer with Claude Code further raises the total number of proved theorems by 9.90 percent.
What carries the argument
LLM2Ltac, which uses an LLM as a synthesizer to extract and formalize latent proof strategies from existing proofs into validated symbolic tactics for integration into provers.
Load-bearing premise
The tactics identified by the LLM are assumed to remain valid, generalizable across new theorems, and non-redundant when added to the symbolic prover, without any post-evaluation filtering that could inflate the measured gains.
What would settle it
Re-running the evaluation on the 6,199 theorems from the four projects after adding the mined tactics and finding that CoqHammer proves no additional theorems, or fewer, would falsify the central effectiveness claim.
Figures





read the original abstract
Automated theorem proving is essential for the formal verification of safety-critical systems. As the corpus of formal proofs grows, a natural paradigm is to learn from existing proofs. However, current learning-based approaches predominantly train Large Language Models (LLMs) as end-to-end provers, which yields resource-intensive, opaque systems. Conversely, while traditional symbolic provers are computationally efficient, how to automatically improve these solvers from data remains an open challenge. This paper bridges this gap by proposing LLM2Ltac, the first approach that leverages the reasoning power of LLMs not as end-to-end provers, but as intelligent synthesizers to mine purely symbolic tactics from data. Given a corpus of formal proofs, LLM2Ltac asks an LLM to identify latent proof strategies and formalize them into reusable tactics. These tactics are verified for validity and generalizability, and finally integrated into symbolic provers to enhance their automated proving capabilities without the runtime cost of LLMs. We implement LLM2Ltac on Rocq 8.20.0 and mine tactics from 11,725 theorems in the standard library. We evaluate our approach on 6,199 theorems from four large real-world verification projects, namely, compcert, Coq-Art, Ext-Lib, and VFA. Results show that the mined tactics improve CoqHammer to prove 23.87% more theorems, and when integrating the improved CoqHammer with Claude Code, the overall proved theorems increases by 9.90%, indicating the effectiveness of LLM2Ltac.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LLM2Ltac, a method that uses LLMs to identify and formalize reusable symbolic tactics from 11,725 theorems in the Coq standard library. These tactics are verified for validity and generalizability before being integrated into CoqHammer. Evaluation on 6,199 theorems from compcert, Coq-Art, Ext-Lib, and VFA reports that the enhanced CoqHammer proves 23.87% more theorems, with a further 9.90% gain when combined with Claude Code.
Significance. If the validation protocol is sound and independent of the evaluation projects, the work is significant for demonstrating how LLMs can synthesize transferable symbolic strategies to improve efficient provers without incurring LLM inference costs at runtime. The use of large real-world verification projects for evaluation adds practical relevance to automated theorem proving in safety-critical systems.
major comments (3)
- [§5] §5 (Evaluation): The headline claim of a 23.87% increase in theorems proved by CoqHammer after adding mined tactics requires a detailed protocol for tactic validation, including how validity and generalizability are checked, whether a held-out verification set separate from the 6,199 evaluation theorems is used, and any statistical significance tests or error bars. The current description leaves open the possibility that filtering or formalization steps incorporate performance signals from the evaluation projects.
- [§4] §4 (LLM2Ltac method): The description of the LLM prompt, tactic extraction, and verification steps does not specify independence guarantees between the mining corpus (standard library) and the evaluation projects. Without explicit controls against data leakage or post-hoc selection of tactics that succeed on compcert/Coq-Art/etc., the measured improvements cannot be interpreted as evidence of generalizable symbolic strategies.
- [§5.2] §5.2 (Integration results): The 9.90% overall gain when combining the improved CoqHammer with Claude Code is presented without an ablation isolating the contribution of the LLM-mined tactics versus other factors, and without reporting how many of the additional proofs are directly attributable to the new tactics versus changes in search strategy.
minor comments (2)
- [§4] The manuscript would benefit from a table listing the mined tactics with their formal definitions and the number of theorems they apply to in the evaluation set.
- [Throughout] Notation for tactic success rates and 'proved theorems' should be defined consistently in the text and figures to avoid ambiguity between unique theorems and total proof attempts.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to provide the requested clarifications, expanded protocols, and additional analyses.
read point-by-point responses
-
Referee: §5 (Evaluation): The headline claim of a 23.87% increase in theorems proved by CoqHammer after adding mined tactics requires a detailed protocol for tactic validation, including how validity and generalizability are checked, whether a held-out verification set separate from the 6,199 evaluation theorems is used, and any statistical significance tests or error bars. The current description leaves open the possibility that filtering or formalization steps incorporate performance signals from the evaluation projects.
Authors: We agree that additional detail on the validation protocol strengthens the paper. Tactic validation occurs exclusively on the standard library corpus: each candidate tactic is tested on its source theorem and on a set of other standard-library theorems to confirm generalizability. The 6,199 theorems from compcert, Coq-Art, Ext-Lib, and VFA are never accessed during mining, prompt construction, extraction, or validation; they constitute a completely held-out evaluation set. We will add a new subsection in §5 that documents the exact validation criteria, the separation of corpora, and the deterministic nature of the process. We will also report binomial proportion confidence intervals around the 23.87% figure to address the request for error bars. revision: yes
-
Referee: §4 (LLM2Ltac method): The description of the LLM prompt, tactic extraction, and verification steps does not specify independence guarantees between the mining corpus (standard library) and the evaluation projects. Without explicit controls against data leakage or post-hoc selection of tactics that succeed on compcert/Coq-Art/etc., the measured improvements cannot be interpreted as evidence of generalizable symbolic strategies.
Authors: The mining corpus consists solely of the 11,725 theorems in the Coq standard library; the four evaluation projects are external developments with no theorem or dependency overlap. LLM prompts are generated exclusively from standard-library proofs, and tactic retention decisions are made only on the basis of success within the standard library. We will revise §4 to state these independence guarantees explicitly, including a note on corpus disjointness and the absence of any evaluation-project-based filtering or post-hoc selection. revision: yes
-
Referee: §5.2 (Integration results): The 9.90% overall gain when combining the improved CoqHammer with Claude Code is presented without an ablation isolating the contribution of the LLM-mined tactics versus other factors, and without reporting how many of the additional proofs are directly attributable to the new tactics versus changes in search strategy.
Authors: We will add an ablation table in §5.2 that reports four configurations: (1) baseline CoqHammer, (2) enhanced CoqHammer with mined tactics, (3) baseline CoqHammer + Claude Code, and (4) enhanced CoqHammer + Claude Code. We will also quantify the number of proofs that become solvable only after the new tactics are added (by comparing proof-search traces with and without the mined tactics). This will isolate the contribution of the LLM-mined tactics from other factors. revision: yes
Circularity Check
No circularity; data separation and external evaluation keep claims independent
full rationale
The paper mines tactics from 11,725 standard-library theorems and evaluates improvements on a disjoint set of 6,199 theorems from compcert, Coq-Art, Ext-Lib and VFA. No equations, fitted parameters, or self-citations appear in the derivation; the reported gains (23.87% for CoqHammer, 9.90% overall) are measured after tactic extraction and verification on held-out projects. The method therefore does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearLLM2Ltac asks an LLM to identify latent proof strategies and formalize them into reusable tactics. These tactics are verified for validity and generalizability, and finally integrated into symbolic provers...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearResults show that the mined tactics improve CoqHammer to prove 23.87% more theorems...
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025. Claude Code: An agentic coding tool. https://code.claude.com/
work page 2025
-
[2]
Anthropic. 2026. Introducing Claude Sonnet 4.6. https://www.anthropic.com/ news/claude-sonnet-4-6
work page 2026
-
[3]
Andrew W. Appel. 2024.Verified Functional Algorithms. Software Foundations, Vol. 3. Electronic textbook
work page 2024
-
[4]
Haniel Barbosa, Clark W. Barrett, Martin Brain, Gereon Kremer, Hanna Lachnitt, Makai Mann, Abdalrhman Mohamed, Mudathir Mohamed, Aina Niemetz, Andres Nötzli, Alex Ozdemir, Mathias Preiner, Andrew Reynolds, Ying Sheng, Cesare Tinelli, and Yoni Zohar. 2022. cvc5: A Versatile and Industrial-Strength SMT Solver. InTools and Algorithms for the Construction and...
-
[5]
Yves Bertot and Pierre Castéran. 2013.Interactive theorem proving and program development: Coq’Art: the calculus of inductive constructions. Springer Science & Business Media
work page 2013
-
[6]
Lasse Blaauwbroek, Mirek Olsák, Jason Rute, Fidel Ivan Schaposnik Massolo, Jelle Piepenbrock, and Vasily Pestun. 2024. Graph2Tac: Online Representation Learning of Formal Math Concepts. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. https://openreview.net/forum?id=A7CtiozznN
work page 2024
-
[7]
Lasse Blaauwbroek, Josef Urban, and Herman Geuvers. 2020. Tactic Learning and Proving for the Coq Proof Assistant. InLPAR 2020: 23rd International Conference on Logic for Programming, Artificial Intelligence and Reasoning, Alicante, Spain, May 22-27, 2020 (EPiC Series in Computing, Vol. 73), Elvira Albert and Laura Kovács (Eds.). EasyChair, 138–150. doi:1...
-
[8]
Sascha Böhme and Tobias Nipkow. 2010. Sledgehammer: Judgement Day. In Automated Reasoning, 5th International Joint Conference, IJCAR 2010, Edinburgh, UK, July 16-19, 2010. Proceedings (Lecture Notes in Computer Science, Vol. 6173), Jürgen Giesl and Reiner Hähnle (Eds.). Springer, 107–121. doi:10.1007/978-3-642- 14203-1_9
-
[9]
Venanzio Capretta. 2005. General recursion via coinductive types.Log. Methods Comput. Sci.1, 2 (2005). doi:10.2168/LMCS-1(2:1)2005
-
[10]
Brigitte Chauvin, Philippe Flajolet, Danièle Gardy, and Bernhard Gittenberger
-
[11]
And/Or Trees Revisited.Comb. Probab. Comput.13, 4-5 (2004), 475–497. doi:10.1017/S0963548304006273
-
[12]
Yizhou Chen, Zeyu Sun, Guoqing Wang, and Dan Hao. 2025. Gpass: A Goal- Adaptive Neural Theorem Prover Based on Coq for Automated Formal Verifica- tion. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 29–41. doi:10.1109/ ICSE55347.2025.00116
-
[13]
Luís Cruz-Filipe, Herman Geuvers, and Freek Wiedijk. 2004. C-CoRN, the Con- structive Coq Repository at Nijmegen. InMathematical Knowledge Manage- ment, Third International Conference, MKM 2004, Bialowieza, Poland, Septem- ber 19-21, 2004, Proceedings (Lecture Notes in Computer Science, Vol. 3119), An- drea Asperti, Grzegorz Bancerek, and Andrzej Trybulec...
-
[14]
Lukasz Czajka and Cezary Kaliszyk. 2018. Hammer for Coq: Automation for Dependent Type Theory.J. Autom. Reason.61, 1-4 (2018), 423–453. doi:10.1007/ S10817-018-9458-4
work page 2018
-
[15]
Leonardo de Moura and Sebastian Ullrich. 2021. The Lean 4 Theorem Prover and Programming Language. InAutomated Deduction - CADE 28 - 28th International Conference on Automated Deduction, Virtual Event, July 12-15, 2021, Proceedings (Lecture Notes in Computer Science, Vol. 12699), André Platzer and Geoff Sutcliffe (Eds.). Springer, 625–635. doi:10.1007/978...
-
[17]
DeepSeek-AI. 2025. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
work page 2025
-
[18]
David Delahaye. 2000. A Tactic Language for the System Coq. InLogic for Pro- gramming and Automated Reasoning, 7th International Conference, LPAR 2000, Reunion Island, France, November 11-12, 2000, Proceedings (Lecture Notes in Com- puter Science, Vol. 1955), Michel Parigot and Andrei Voronkov (Eds.). Springer, 85–95. doi:10.1007/3-540-44404-1_7
- [19]
-
[20]
Emily First, Yuriy Brun, and Arjun Guha. 2020. TacTok: semantics-aware proof synthesis.Proc. ACM Program. Lang.4, OOPSLA (2020), 231:1–231:31. doi:10. 1145/3428299
work page 2020
-
[21]
Ronghui Gu, Zhong Shao, Hao Chen, Xiongnan (Newman) Wu, Jieung Kim, Vilhelm Sjöberg, and David Costanzo. 2016. CertiKOS: An Extensible Architec- ture for Building Certified Concurrent OS Kernels. In12th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2016, Savannah, GA, USA, November 2-4, 2016, Kimberly Keeton and Timothy Roscoe (Eds...
work page 2016
-
[22]
Albert Q. Jiang, Wenda Li, Szymon Tworkowski, Konrad Czechowski, Tomasz Odrzygóźdź, Piotr Miłoś, Yuhuai Wu, and Mateja Jamnik. 2022. Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers.CoRR abs/2205.10893 (2022). doi:10.48550/arXiv.2205.10893
-
[23]
Saketh Ram Kasibatla, Arpan Agarwal, Yuriy Brun, Sorin Lerner, Talia Ringer, and Emily First. 2024. Cobblestone: Iterative Automation for Formal Verification. CoRRabs/2410.19940 (2024). arXiv:2410.19940 doi:10.48550/ARXIV.2410.19940
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.19940 2024
-
[24]
Gerwin Klein, Kevin Elphinstone, Gernot Heiser, June Andronick, David A. Cock, Philip Derrin, Dhammika Elkaduwe, Kai Engelhardt, Rafal Kolanski, Michael Norrish, Thomas Sewell, Harvey Tuch, and Simon Winwood. 2009. seL4: formal verification of an OS kernel.. InProceedings of the 22nd ACM Symposium on Operating Systems Principles 2009, SOSP 2009, Big Sky, ...
- [25]
-
[26]
Robbert Krebbers, Xavier Leroy, and Freek Wiedijk. 2014. Formal C Semantics: CompCert and the C Standard. InInteractive Theorem Proving - 5th International Conference, ITP 2014, Held as Part of the Vienna Summer of Logic, VSL 2014, Vienna, Austria, July 14-17, 2014. Proceedings (Lecture Notes in Computer Science, Vol. 8558), Gerwin Klein and Ruben Gamboa ...
-
[27]
Xavier Leroy, Sandrine Blazy, Daniel Kästner, Bernhard Schommer, Markus Pister, and Christian Ferdinand. 2016. CompCert – A Formally Verified Optimizing Compiler. InERTS 2016: Embedded Real Time Software and Systems. SEE. http: //xavierleroy.org/publi/erts2016_compcert.pdf
work page 2016
-
[28]
Minghai Lu, Benjamin Delaware, and Tianyi Zhang. 2024. Proof Automation with Large Language Models. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE 2024, Sacramento, CA, USA, October 27 - November 1, 2024, Vladimir Filkov, Baishakhi Ray, and Minghui Zhou (Eds.). ACM, 1509–1520. doi:10.1145/3691620.3695521
-
[29]
Linhao Luo, Jiaxin Ju, Bo Xiong, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan
-
[30]
ChatRule: Mining Logical Rules with Large Language Models for Knowledge Graph Reasoning. InAdvances in Knowledge Discovery and Data Mining - 29th Pacific-Asia Conference on Knowledge Discovery and Data Mining, PAKDD 2025, Sydney, NSW, Australia, June 10-13, 2025, Proceedings, Part II (Lecture Notes in Computer Science, Vol. 15871), Xintao Wu, Myra Spiliop...
-
[31]
Gregory Malecha, Gregory Malecha, and Yishuai Li. 2024. coq-ext-lib. https: //github.com/rocq-community/coq-ext-lib
work page 2024
-
[32]
OpenAI. 2025. Introducing GPT-5.2
work page 2025
- [33]
-
[34]
Christine Paulin-Mohring. 2015. Introduction to the calculus of inductive con- structions.All about Proofs, Proofs for All55 (2015)
work page 2015
- [35]
-
[36]
The probabilistic relevance framework: Bm25 and beyond
Stephen E. Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (2009), 333–389. doi:10.1561/1500000019
-
[37]
Alex Sanchez-Stern, Yousef Alhessi, Lawrence K. Saul, and Sorin Lerner. 2020. Generating correctness proofs with neural networks. InProceedings of the 4th ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, MAPL@PLDI 2020, London, UK, June 15, 2020, Koushik Sen and Mayur Conference acronym ’XX, June 03–05, 2018, Woodstock, NY...
-
[38]
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K. Reddy. 2025. LLM-SR: Scientific Equation Discovery via Program- ming with Large Language Models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openreview.net/forum?id=m2nmp8P5in
work page 2025
-
[39]
Yuheng Su, Qiusong Yang, Yiwei Ci, Tianjun Bu, and Ziyu Huang. 2025. The rIC3 Hardware Model Checker. InComputer Aided Verification - 37th International Conference, CA V 2025, Zagreb, Croatia, July 23-25, 2025, Proceedings, Part I (Lecture Notes in Computer Science, Vol. 15931), Ruzica Piskac and Zvonimir Rakamaric (Eds.). Springer, 185–199. doi:10.1007/9...
-
[40]
Yuheng Su, Qiusong Yang, Yiwei Ci, Yingcheng Li, Tianjun Bu, and Ziyu Huang
-
[41]
Deeply Optimizing the SAT Solver for the IC3 Algorithm. InComputer Aided Verification - 37th International Conference, CA V 2025, Zagreb, Croatia, July 23-25, 2025, Proceedings, Part I (Lecture Notes in Computer Science, Vol. 15931), Ruzica Piskac and Zvonimir Rakamaric (Eds.). Springer, 237–257. doi:10.1007/978- 3-031-98668-0_12
-
[42]
The Coq Development Team. 2024. The Coq Reference Manual – Release 8.20.0. https://rocq-prover.org/doc/V8.20.0/refman/index.html
work page 2024
-
[43]
Ferreira, Sorin Lerner, and Emily First
Kyle Thompson, Nuno Saavedra, Pedro Carrott, Kevin Fisher, Alex Sanchez- Stern, Yuriy Brun, João F. Ferreira, Sorin Lerner, and Emily First. 2025. Rango: Adaptive Retrieval-Augmented Proving for Automated Software Verification. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 34...
-
[44]
Haiming Wang, Huajian Xin, Chuanyang Zheng, Zhengying Liu, Qingxing Cao, Yinya Huang, Jing Xiong, Han Shi, Enze Xie, Jian Yin, Zhenguo Li, and Xiaodan Liang. 2024. LEGO-Prover: Neural Theorem Proving with Growing Libraries. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https...
work page 2024
- [45]
-
[46]
Makarius Wenzel, Lawrence C. Paulson, and Tobias Nipkow. 2008. The Isabelle Framework. InTheorem Proving in Higher Order Logics, 21st International Confer- ence, TPHOLs 2008, Montreal, Canada, August 18-21, 2008. Proceedings (Lecture Notes in Computer Science, Vol. 5170), Otmane Aït Mohamed, César A. Muñoz, and Sofiène Tahar (Eds.). Springer, 33–38. doi:1...
-
[47]
Yuhuai Wu, Albert Q. Jiang, Wenda Li, Markus N. Rabe, Charles Staats, Mateja Jamnik, and Christian Szegedy. 2022. Autoformalization with Large Language Models. arXiv:2205.12615 [cs.LG] https://arxiv.org/abs/2205.12615
-
[48]
Kaiyu Yang and Jia Deng. 2019. Learning to Prove Theorems via Interacting with Proof Assistants. InProceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdi- nov (Eds.). PMLR, 6984–6994. http://pr...
work page 2019
- [49]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.