Recognition: 2 theorem links
· Lean TheoremMBP-KT: Learning Global Collaborative Information from Meta-Behavioral Pattern for Enhanced Knowledge Tracing
Pith reviewed 2026-05-12 01:18 UTC · model grok-4.3
The pith
Transforming raw learner interactions into meta-behavioral pattern combinations lets a parameter-free module extract global collaborative signals that improve many knowledge tracing models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
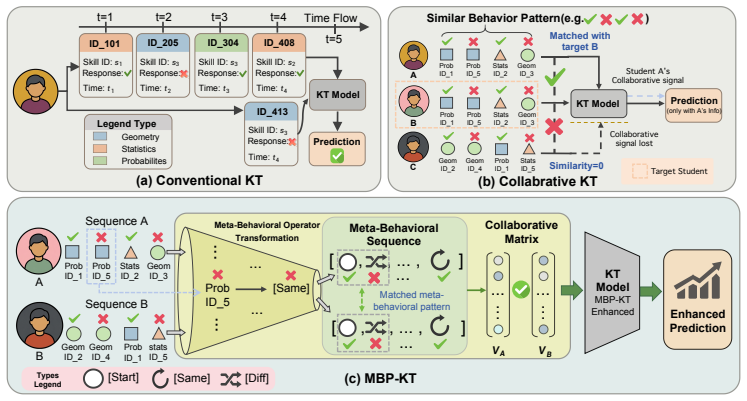
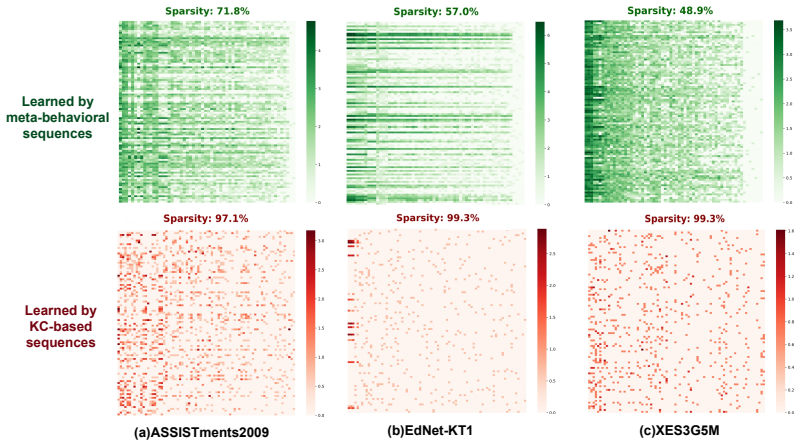
MBP-KT transforms raw interaction sequences into meta-behavioral pattern combinations to preserve learning behavioral patterns, then applies a parameter-free module to derive global collaborative representations that are injected via general strategies into various KT models, yielding consistent performance improvements on real-world datasets.
What carries the argument
The meta-behavioral sequence construction that converts raw interactions into combinations of different meta-behavioral patterns, paired with the parameter-free module that extracts global collaborative representations from those sequences.
If this is right
- Existing KT models can incorporate global collaborative information without custom redesigns or extra parameters.
- Learning behavioral patterns become more accessible for prediction when represented as meta-pattern combinations rather than raw data.
- The same framework applies across a wide range of KT models and produces measurable gains on real educational datasets.
- Collaborative signals from other learners become a reusable resource rather than something rebuilt for each new model.
Where Pith is reading between the lines
- Similar pattern-based transformations could simplify collaborative modeling in other user-behavior sequence tasks such as recommendation or health tracking.
- Defining meta-patterns at different levels of granularity might further reduce reliance on large model-specific architectures in sequential prediction.
- The separation of pattern construction from the extraction module opens the door to testing whether the gains come mainly from the representation change or from the shared signals.
Load-bearing premise
That converting raw interaction sequences into meta-behavioral pattern combinations preserves essential learning behaviors and lets the parameter-free module capture useful global collaborative information without adding noise or losing individual learner signals.
What would settle it
A test on held-out datasets where KT models augmented with MBP-KT show no improvement or lower accuracy than the same models trained on raw sequences alone.
Figures






read the original abstract
The emerging collaborative information-based knowledge tracing (KT) has been a promising way to enhance modeling of learners' knowledge states. The core idea is to extract the collaborative information from interaction sequences of other learners to assist the prediction on the target one. Despite effectiveness, existing methods are built on the raw interaction sequences with tailored modules, which inevitably limits their capacity in deeply capturing learning behavioral patterns and generalization. To this end, we propose a general meta-behavioral pattern-aware framework (MBP-KT) for KT. Specifically, MBP-KT introduces a novel meta-behavioral sequence construction to transform the raw interaction sequences into the combinations of different meta-behavioral patterns. In this way, the learning behavioral patterns of learners can be effectively preserved. Then, MBP-KT develops a parameter-free module to extract the global collaborative representations from the constructed meta-behavioral sequences. Moreover, MBP-KT provides general injection strategies to introduce the extracted global collaborative information into various downstream KT models, ensuring the universality of the collaborative information. Extensive results on real-world datasets demonstrate that MBP-KT can consistently boosts the performance of a wide range of KT models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MBP-KT, a general framework for knowledge tracing (KT) that transforms raw learner interaction sequences into combinations of meta-behavioral patterns to preserve behavioral patterns, employs a parameter-free module to extract global collaborative representations from these sequences, and provides injection strategies to integrate the extracted information into various downstream KT models. It claims that this approach consistently improves performance across a wide range of KT models on real-world datasets.
Significance. If the central empirical claims hold after addressing the noted gaps, the work would provide a modular, parameter-free mechanism for incorporating collaborative signals into existing KT architectures, potentially increasing their robustness without requiring model-specific redesigns. The emphasis on universality via injection strategies is a constructive contribution if supported by rigorous ablations.
major comments (3)
- [Abstract] Abstract: The claim that the meta-behavioral sequence construction 'effectively preserves' learning behavioral patterns lacks any formal definition of the patterns, proof of invertibility, or information-theoretic argument that the transformation retains fine-grained temporal, response-time, and per-learner signals; this is load-bearing because the skeptic correctly identifies it as the weakest link, and any downstream gains could be artifacts of the encoding rather than genuine collaborative information.
- [Abstract] Abstract: No equations, ablation studies, error bars, data-split protocols, or baseline implementation details are referenced, so it is impossible to verify whether the reported consistent boosts are robust to post-hoc choices or fairly compared; this directly undermines the soundness assessment of the headline empirical claim.
- [Abstract] Abstract: The parameter-free module is asserted to extract 'useful global collaborative representations' without introducing noise, yet the text supplies neither a derivation showing why the module is parameter-free nor an external benchmark separating its contribution from dataset-specific tuning; this creates the circularity risk flagged in the reader's report.
minor comments (1)
- [Abstract] Abstract: Grammatical error in the final sentence ('consistently boosts' should read 'consistently boost').
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the meta-behavioral sequence construction 'effectively preserves' learning behavioral patterns lacks any formal definition of the patterns, proof of invertibility, or information-theoretic argument that the transformation retains fine-grained temporal, response-time, and per-learner signals; this is load-bearing because the skeptic correctly identifies it as the weakest link, and any downstream gains could be artifacts of the encoding rather than genuine collaborative information.
Authors: We agree the abstract phrasing is concise and does not include formal proofs. Section 3.1 of the manuscript defines meta-behavioral patterns explicitly as combinations of interaction attributes (correctness labels, discretized response times, and attempt counts). Preservation is demonstrated empirically through reconstruction examples and ablations showing retention of temporal and per-learner signals. We will revise the abstract to reference Section 3.1 and briefly note the pattern construction process. A formal invertibility proof is not feasible as the mapping is intentionally many-to-one for abstraction; we will clarify this design choice and its empirical validation in the revision. revision: partial
-
Referee: [Abstract] Abstract: No equations, ablation studies, error bars, data-split protocols, or baseline implementation details are referenced, so it is impossible to verify whether the reported consistent boosts are robust to post-hoc choices or fairly compared; this directly undermines the soundness assessment of the headline empirical claim.
Authors: The abstract is a high-level summary and omits technical details for brevity. The full manuscript includes: equations for the meta-sequence construction and extractor in Section 3; ablation studies and error bars in Section 4.3 and associated figures; data-split protocols (e.g., 5-fold cross-validation) in Section 4.1; and baseline implementations with hyperparameters in Section 4.2. We will update the abstract to reference these elements and add cross-references to ensure verifiability. revision: yes
-
Referee: [Abstract] Abstract: The parameter-free module is asserted to extract 'useful global collaborative representations' without introducing noise, yet the text supplies neither a derivation showing why the module is parameter-free nor an external benchmark separating its contribution from dataset-specific tuning; this creates the circularity risk flagged in the reader's report.
Authors: Section 3.2 details the module as relying on fixed, non-learnable operations (mean aggregation over meta-patterns and similarity computations without trainable weights), which inherently makes it parameter-free. Ablations in Section 4.4 isolate its contribution from other components. We will add a concise derivation of the parameter-free property and additional benchmarks against tuned variants in the revised methods and experiments sections. revision: yes
Circularity Check
No significant circularity; empirical framework with independent experimental validation.
full rationale
The paper presents MBP-KT as a methodological framework that transforms raw interaction sequences into meta-behavioral pattern combinations, extracts global collaborative representations via a parameter-free module, and injects them into downstream KT models. All central claims rest on empirical performance gains demonstrated across real-world datasets rather than any closed mathematical derivation, uniqueness theorem, or self-referential prediction. No equations or steps reduce by construction to fitted inputs or prior self-citations; the preservation claim is stated as a design goal and evaluated experimentally, leaving the argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Meta-behavioral sequence construction preserves essential learning behavioral patterns from raw interactions
- domain assumption Global collaborative representations extracted from meta-sequences are beneficial for individual knowledge state prediction
invented entities (1)
-
meta-behavioral patterns
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearMBP-KT introduces a novel meta-behavioral sequence construction to transform the raw interaction sequences into the combinations of different meta-behavioral patterns... parameter-free module to extract the global collaborative representations
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and orbit embedding uncleara sliding window strategy is adopted to analyze the combination patterns of different states: M=φ(Z, N, τ)
Reference graph
Works this paper leans on
-
[1]
Ghassan Abdelrahman and Qing Wang. 2019. Knowledge tracing with sequential key-value memory networks. InProceedings of the 42nd International ACM SIGIR Conference on Re- search and Development in Information Retrieval. 175–184
work page 2019
-
[2]
Ghassan Abdelrahman, Qing Wang, and Bernardo Nunes. 2023. Knowledge tracing: A survey. Comput. Surveys55, 11 (2023), 1–37
work page 2023
-
[3]
Ryan SJd Baker, Albert T Corbett, and Vincent Aleven. 2008. More accurate student modeling through contextual estimation of slip and guess probabilities in bayesian knowledge tracing. In International Conference on Intelligent Tutoring Systems. Springer, 406–415
work page 2008
- [4]
-
[5]
Weihua Cheng, Hanwen Du, Chunxiao Li, Ersheng Ni, Liangdi Tan, Tianqi Xu, and Yongxin Ni. 2025. Uncertainty-aware Knowledge Tracing.Proceedings of the AAAI Conference on Artificial Intelligence39, 27 (2025), 27905–27913
work page 2025
-
[6]
Zhiyong Cheng, Sai Han, Fan Liu, Lei Zhu, Zan Gao, and Yuxin Peng. 2023. Multi-Behavior Recommendation with Cascading Graph Convolution Networks. InProceedings of the ACM Web Conference 2023. 1181–1189
work page 2023
-
[7]
Benoît Choffin, Fabrice Popineau, Yolaine Bourda, and Jill-Jênn Vie. 2019. DAS3H: Model- ing student learning and forgetting for optimally scheduling distributed practice of skills. In Proceedings of the 12th International Conference on Educational Data Mining. 29–38
work page 2019
-
[8]
Youngduck Choi, Youngnam Lee, Dongmin Cho, Jineon Baek, Byungsoo Kim, Yeongmin Jeon, Seungwhan Moon, and Jungyeul Heo. 2020. Towards an appropriate query, key, and value computation for knowledge tracing. InProceedings of the Seventh ACM Conference on Learning @ Scale. 341–344
work page 2020
-
[9]
Youngduck Choi, Youngnam Lee, Junghyun Shin, Dongmin Cho, Seoyon Park, Seewoo Lee, Jineon Baek, Chan Kim, Youngmin Lee, and Jaewook Heo. 2020. Ednet: A large-scale hierarchical dataset in education. InInternational Conference on Artificial Intelligence in Education. Springer, 69–73
work page 2020
-
[10]
Albert T Corbett and John R Anderson. 1994. Knowledge tracing: Modeling the acquisition of procedural knowledge.User Modeling and User-Adapted Interaction4, 4 (1994), 253–278
work page 1994
-
[11]
Jimmy de la Torre. 2009. DINA model and parameter estimation: A didactic.Journal of Educational and Behavioral Statistics34, 1 (2009), 115–130
work page 2009
-
[12]
Mingyu Feng, Neil Heffernan, and Kenneth Koedinger. 2009. Addressing the assessment challenge with an online system that tutors as it assesses.User modeling and user-adapted interaction19, 3 (2009), 243–266
work page 2009
-
[13]
Weibo Gao, Qi Liu, Linan Yue, Fangzhou Yao, Hao Wang, Yin Gu, and Zheng Zhang. 2024. Collaborative cognitive diagnosis with disentangled representation learning for learner modeling. Advances in Neural Information Processing Systems37 (2024), 562–588
work page 2024
-
[14]
Aritra Ghosh, Neil Heffernan, and Andrew S Lan. 2020. Context-aware attentive knowledge tracing. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2330–2339
work page 2020
-
[15]
Aritra Ghosh and Andrew Lan. 2021. BOBCAT: Bilevel optimization-based computerized adaptive testing. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence. 2410–2417
work page 2021
-
[16]
Albert Gu and Tri Dao. 2023. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752(2023). 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Xiaopeng Guo, Zhijie Huang, Jie Gao, Mingyu Shang, Maojing Shu, and Jun Sun. 2021. Enhanc- ing knowledge tracing via adversarial training. InProceedings of the 29th ACM International Conference on Multimedia. 36–44
work page 2021
-
[18]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 391–400
work page 2020
-
[19]
Wonsung Lee, Jaeyoon Chun, Youngmin Lee, Kyoungsoo Park, and Sungrae Park. 2022. Contrastive learning for knowledge tracing. InProceedings of the ACM Web Conference 2022. 2330–2338
work page 2022
-
[20]
Qi Liu, Zhenya Huang, Yu Yin, Enhong Chen, Hui Xiong, Yu Su, and Guoping Hu. 2019. EKT: Exercise-aware knowledge tracing for student performance prediction. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1936–1944
work page 2019
-
[21]
Yunfei Liu, Yang Yang, Xianyu Chen, Jian Shen, Haifeng Zhang, and Yong Yu. 2021. Im- proving knowledge tracing via pre-training question embeddings. InProceedings of the 30th International Joint Conference on Artificial Intelligence. 1–7
work page 2021
-
[22]
Zitao Liu, Qiongqiong Liu, Teng Guo, Jiahao Chen, Shuyan Huang, Xiangyu Zhao, Jiliang Tang, Weiqi Luo, and Jian Weng. 2023. XES3G5M: A Knowledge Tracing Benchmark Dataset with Auxiliary Information. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track
work page 2023
-
[23]
Ting Long, Yunfei Liu, Jian Shen, Weinan Zhang, and Yong Yu. 2021. Tracing knowledge state with individual cognition and acquisition effectiveness. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 173–182
work page 2021
-
[24]
Ting Long, Yunfei Liu, Jian Shen, Weinan Zhang, and Yong Yu. 2022. Improving knowledge tracing with collaborative information. InProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. 599–607
work page 2022
-
[25]
2012.Recommender systems for learning
Nikos Manouselis, Hendrik Drachsler, Katrien Verbert, and Erik Duval. 2012.Recommender systems for learning. Springer
work page 2012
-
[26]
Sein Minn, Yongfeng Yu, Michel C Desmarais, Feida Zhu, and Jianping Wang. 2018. Deep knowledge tracing and dynamic student classification for knowledge tracing. In2018 IEEE International Conference on Data Mining (ICDM). IEEE, 1182–1187
work page 2018
-
[27]
Hiromi Nakagawa, Yusuke Iwasawa, and Yutaka Matsuo. 2019. Graph-based knowledge tracing: modeling student proficiency using graph neural network. InIEEE/WIC/ACM International Conference on Web Intelligence. 156–163
work page 2019
-
[28]
Shalini Pandey and George Karypis. 2019. A self-attentive model for knowledge tracing. In Proceedings of the 12th International Conference on Educational Data Mining
work page 2019
-
[29]
Shalini Pandey and Jaideep Srivastava. 2020. RKT: Relation-aware self-attention for knowledge tracing. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 1205–1214
work page 2020
-
[30]
Philip I Pavlik Jr, Hao Cen, and Kenneth R Koedinger. 2009. Performance Factors Analysis– A New Alternative to Knowledge Tracing. In14th International Conference on Artificial Intelligence in Education. 531–538
work page 2009
-
[31]
Chris Piech, Jonathan Bassen, Jimmy Huang, Surya Ganguli, Mehran Sahami, Leonidas J Guibas, and Jascha Sohl-Dickstein. 2015. Deep knowledge tracing. InAdvances in Neural Information Processing Systems, V ol. 28
work page 2015
-
[32]
Shi Pu, Michael Yudelson, Lu Ou, and Ryo Yasui. 2020. Deep knowledge tracing with transformers. InInternational Conference on Artificial Intelligence in Education. Springer, 252–256. 11
work page 2020
-
[33]
1993.Probabilistic models for some intelligence and attainment tests.MESA Press
Georg Rasch. 1993.Probabilistic models for some intelligence and attainment tests.MESA Press
work page 1993
-
[34]
Steven P. Reise and Niels G. Waller. 2009. Item response theory and clinical measurement. Annual Review of Clinical Psychology5, V olume 5, 2009 (2009), 27–48
work page 2009
-
[35]
Cristóbal Romero and Sebastián Ventura. 2020. Educational data mining and learning analytics: An updated survey.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 10, 3 (2020), e1355
work page 2020
-
[36]
Shuanghong Shen, Zhenya Huang, Qi Liu, Yu Su, Shijin Wang, and Enhong Chen. 2022. Assessing student’s dynamic knowledge state by exploring the question difficulty effect. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 427–437
work page 2022
-
[37]
Xiaoxuan Shen, Fenghua Yu, Yaqi Liu, Ruxia Liang, Qian Wan, Kai Yang, and Jianwen Sun
-
[38]
InProceedings of the 32nd ACM international conference on multimedia
Revisiting knowledge tracing: A simple and powerful model. InProceedings of the 32nd ACM international conference on multimedia. 263–272
-
[39]
Dongmin Shin, Yujin Shim, Hangyeol Yu, Seewoo Lee, Byungsoo Kim, and Youngduck Choi
-
[40]
InLAK21: 11th International Learning Analytics and Knowledge Conference
SAINT+: Integrating temporal features for ednet correctness prediction. InLAK21: 11th International Learning Analytics and Knowledge Conference. 490–496
-
[41]
Shiwei Tong, Qi Liu, Wei Huang, Zhenya Hunag, Enhong Chen, Chuanren Liu, Haiping Ma, and Shijin Wang. 2020. Structure-based knowledge tracing: An influence propagation view. In 2020 IEEE International Conference on Data Mining (ICDM). IEEE, 541–550
work page 2020
-
[42]
Jill-Jênn Vie and Hisashi Kashima. 2019. Knowledge tracing machines: Factorization machines for knowledge tracing. InProceedings of the AAAI Conference on Artificial Intelligence, V ol. 33. 750–757
work page 2019
-
[43]
Chenyang Wang, Weizhi Ma, Min Zhang, Chuancheng Lv, Fengyuan Wan, Huijie Lin, Taoran Tang, Yiqun Liu, and Shaoping Ma. 2021. Temporal cross-effects in knowledge tracing. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining. 517–525
work page 2021
-
[44]
Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 165–174
work page 2019
-
[45]
Chun-Kit Yeung and Dit-Yan Yeung. 2018. Addressing two problems in deep knowledge tracing via prediction-consistent regularization. InProceedings of the Fifth Annual ACM Conference on Learning at Scale. 1–10
work page 2018
-
[46]
Yu Yin, Qi Liu, Zhenya Huang, Enhong Chen, Wei Tong, Shijin Wang, and Yu Su. 2019. QuesNet: A unified representation for heterogeneous test questions. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1328–1336
work page 2019
-
[47]
Chunyun Zhang, Hebo Ma, Chaoran Cui, Yumo Yao, Weiran Xu, Yunfeng Zhang, and Yuling Ma. 2024. CoSKT: A Collaborative Self-Supervised Learning Method for Knowledge Tracing. IEEE Trans. Learn. Technol.17 (2024), 1502–1514
work page 2024
-
[48]
Jiani Zhang, Xingjian Shi, Irwin King, and Dit-Yan Yeung. 2017. Dynamic key-value memory networks for knowledge tracing. InProceedings of the 26th International Conference on World Wide Web. 765–774. 12 A Experimental Setup Details A.1 Dataset Statistics To evaluate the framework across different data scales and sparsity levels, we utilize three real-worl...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.