Recognition: no theorem link
Done, But Not Sure: Disentangling World Completion from Self-Termination in Embodied Agents
Pith reviewed 2026-05-13 00:59 UTC · model grok-4.3
The pith
Embodied agents often reach task goals without correctly reporting termination, and VIGIL separates these into distinct W and B scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
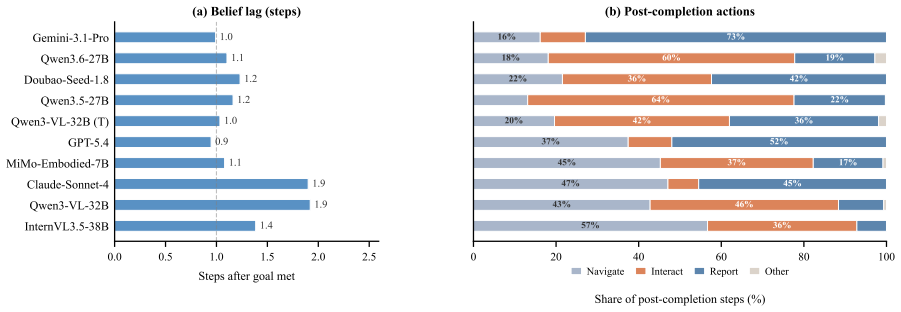
Standard embodied evaluations do not independently score whether an agent correctly commits to task completion at episode closure, a capacity we call terminal commitment. VIGIL makes terminal commitment independently measurable by requiring agents to end each episode with a semantic report checked deterministically against hidden world state. This yields separate world-state completion W and benchmark success B scores, where B additionally requires a correct terminal report. Across 20 models on 1,000 frozen episodes, systems with comparable W differ by up to 19.7 pp in B. An action-feedback intervention improves W broadly, yet commitment failures persist in models that do not already ground
What carries the argument
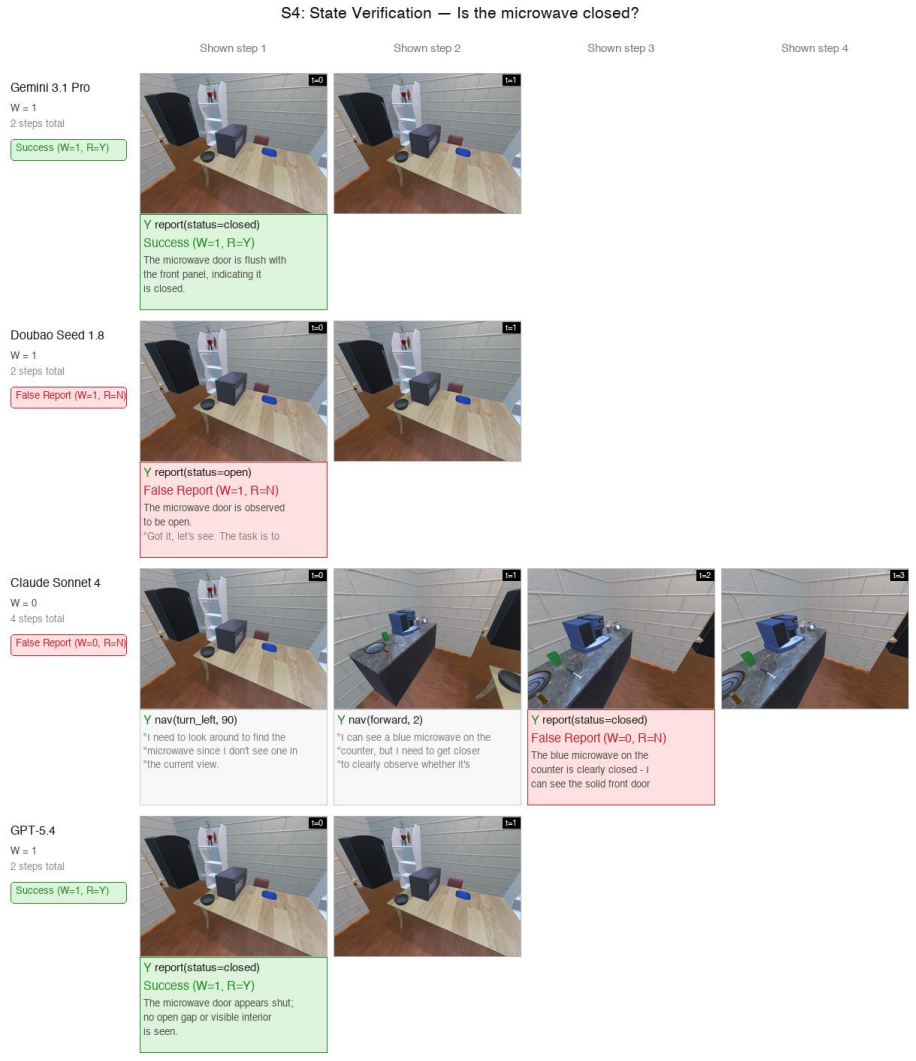
VIGIL evaluation protocol, which forces agents to issue a semantic terminal report at episode end that is checked deterministically against hidden world state, separating world-state completion W from benchmark success B.
If this is right
- Action feedback improves world completion across models but leaves terminal commitment failures untouched unless reports are already grounded in achieved states.
- Models with near-identical execution can still differ sharply in converting achieved states into correct terminal reports.
- Four distinct failure modes—missed execution, post-attainment drift, unsupported commitment, and verified success—become separately scorable.
- Benchmarks can now isolate and target self-termination ability rather than treating all non-success as equivalent.
Where Pith is reading between the lines
- Training regimes that reward only execution may need explicit supervision on termination decisions to close the W-B gap.
- In real deployments, weak terminal commitment could cause agents to keep acting after goals are met or to stop without confirmation.
- The same decoupling might appear in long-horizon planning or multi-step reasoning tasks where knowing when to halt matters.
- Internal representations of task boundaries could be probed by checking whether achieved states reliably trigger correct reports.
Load-bearing premise
A deterministic semantic check of the agent's terminal report against the true hidden world state is sufficient to measure genuine terminal commitment without extra grounding or multi-step verification of the report.
What would settle it
Observe whether models that achieve high W but low B still show persistent B gaps after an action-feedback intervention that supplies execution signals, or whether all high-W models converge to high B once reports must match achieved states.
Figures




read the original abstract
Standard embodied evaluations do not independently score whether an agent correctly commits to task completion at episode closure, a capacity we call terminal commitment. Behaviorally distinct failures--never completing the task, completing it but failing to stop, and reporting success without sufficient evidence--collapse into the same benchmark failure. We introduce VIGIL, an evaluation framework that makes terminal commitment independently measurable. Under VIGIL's default protocol, agents observe only egocentric RGB, receive no action-success signals, and must end each episode with a semantic report checked deterministically against hidden world state. This yields two separate scores: world-state completion (W) and benchmark success (B), where B additionally requires a correct terminal report. This decoupling makes four outcome categories distinguishable: missed execution, post-attainment drift, unsupported commitment, and verified success. Across 20 models on 1,000 frozen episodes, systems with comparable W differ by up to 19.7 pp in B: one model converts achieved states into correct reports, while another with near-identical execution drifts past the goal without closing. An action-feedback intervention further tests the separation: execution-oriented signals improve W broadly, yet commitment failures persist in models that do not already ground terminal reports in the achieved state. VIGIL provides a protocol that makes terminal commitment independently visible and scorable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard embodied evaluations conflate task execution with terminal commitment and introduces the VIGIL framework, which decouples world-state completion (W) from benchmark success (B) by requiring a deterministically checked semantic terminal report against hidden ground truth. On 1,000 frozen episodes across 20 models, it reports up to 19.7 pp gaps in B for comparable W, distinguishes four outcome categories, and shows via action-feedback intervention that execution signals improve W but commitment failures persist in models that do not already ground reports in achieved states.
Significance. If the VIGIL measurement protocol is shown to be unbiased, the work would be significant for embodied AI by making self-termination failures independently visible and quantifiable, enabling targeted improvements beyond standard success rates. The use of frozen episodes and broad model coverage provides a reproducible empirical foundation for distinguishing missed execution, post-attainment drift, unsupported commitment, and verified success.
major comments (2)
- [Abstract] Abstract and experimental protocol: the central claim that VIGIL independently measures terminal commitment (via the B-W gap) rests on the untested assumption that a deterministic semantic match of the final report to hidden state is sufficient and unbiased; this could be confounded by language-model variance in verbalizing egocentric observations rather than genuine commitment, and the action-feedback intervention does not isolate this.
- [Abstract] Abstract: the reported 19.7 pp difference in B for models with comparable W is presented without error bars, episode-selection criteria, statistical significance tests, or per-model breakdowns, which is load-bearing for the claim that the framework makes the distinction visible across systems.
minor comments (1)
- [Abstract] The abstract lists four outcome categories but does not name them explicitly, reducing immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. The feedback highlights important considerations for strengthening the presentation of the VIGIL framework's measurement protocol and empirical claims. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental protocol: the central claim that VIGIL independently measures terminal commitment (via the B-W gap) rests on the untested assumption that a deterministic semantic match of the final report to hidden state is sufficient and unbiased; this could be confounded by language-model variance in verbalizing egocentric observations rather than genuine commitment, and the action-feedback intervention does not isolate this.
Authors: We appreciate the referee's concern regarding potential confounds in the semantic matching protocol. The deterministic check against hidden ground truth is designed to require agents to produce a report that accurately reflects the achieved world state, making verbalization accuracy an integral component of terminal commitment rather than a separate confound; models that execute correctly but cannot verbalize the outcome fail B by definition. The action-feedback intervention demonstrates that execution signals broadly improve W scores while commitment failures (B-W gaps) persist specifically in models lacking grounded reporting, providing evidence that the distinction is not solely attributable to verbalization variance. We acknowledge that additional controls could further isolate these factors and will add a dedicated discussion section on potential language-model confounds, including qualitative examples of report mismatches, in the revised manuscript. revision: partial
-
Referee: [Abstract] Abstract: the reported 19.7 pp difference in B for models with comparable W is presented without error bars, episode-selection criteria, statistical significance tests, or per-model breakdowns, which is load-bearing for the claim that the framework makes the distinction visible across systems.
Authors: We agree that the abstract and main claims would benefit from explicit statistical support. The 19.7 pp gap is computed from aggregated results over the full set of 1,000 frozen episodes spanning 20 models, with episodes selected to ensure coverage of diverse task scenarios and initial conditions. In the revised version, we will update the abstract to reference these details and incorporate error bars (e.g., via bootstrapping), statistical significance tests (e.g., paired comparisons with confidence intervals), and per-model breakdowns into the results section and supplementary materials to substantiate the cross-system visibility of the B-W distinction. revision: yes
Circularity Check
No circularity: VIGIL metrics defined by external protocol without self-referential reduction
full rationale
The paper defines VIGIL as an evaluation protocol that separates world-state completion (W) from benchmark success (B) via deterministic semantic matching of terminal reports against hidden ground truth. No equations, derivations, or first-principles results are presented that reduce the observed B-W differences or the commitment measure to fitted parameters, self-citations, or inputs by construction. The four outcome categories and empirical gaps across models follow directly from the protocol's independent checks, with no load-bearing self-citation chains or ansatzes invoked to justify the separation.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.