Recognition: no theorem link
FedGMI: Generative Model-Driven Federated Learning for Probabilistic Mixture Inference
Pith reviewed 2026-05-12 03:05 UTC · model grok-4.3
The pith
FedGMI models each client's data as a convex combination of shared distributions using VAEs to enable structured personalization in federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the probabilistic mixture scenario each client's local data distribution is a convex combination of several shared inherent distributions. FedGMI employs variational autoencoders as generative density estimators to represent those inherent distributions and to infer the mixture components of every client's local data, thereby achieving structured personalization without sacrificing the benefits of collaborative learning.
What carries the argument
Variational autoencoders used as generative density estimators that learn shared inherent distributions and compute client-specific mixture proportions.
If this is right
- Clients sharing similar mixture proportions can leverage more effective joint models.
- The framework estimates mixture proportions accurately from decentralized data alone.
- Performance stays robust under explicit communication-cost limits.
- Inherent distributions are discriminated without exchanging raw client data.
Where Pith is reading between the lines
- The same mixture view could be paired with other generative models when VAEs underfit complex modalities.
- Over time the inferred proportions might serve as a lightweight signal for detecting distribution drift across clients.
- Hybrid schemes could first cluster on the learned mixture weights and then run FedGMI inside each cluster.
Load-bearing premise
Each client's local data distribution is a convex combination of several shared inherent distributions that variational autoencoders can faithfully represent and infer.
What would settle it
Synthetic data in which client distributions are drawn from entirely non-overlapping, non-mixture sources would test whether the VAE-based inference still recovers useful structure or collapses to standard personalized federated learning performance.
Figures


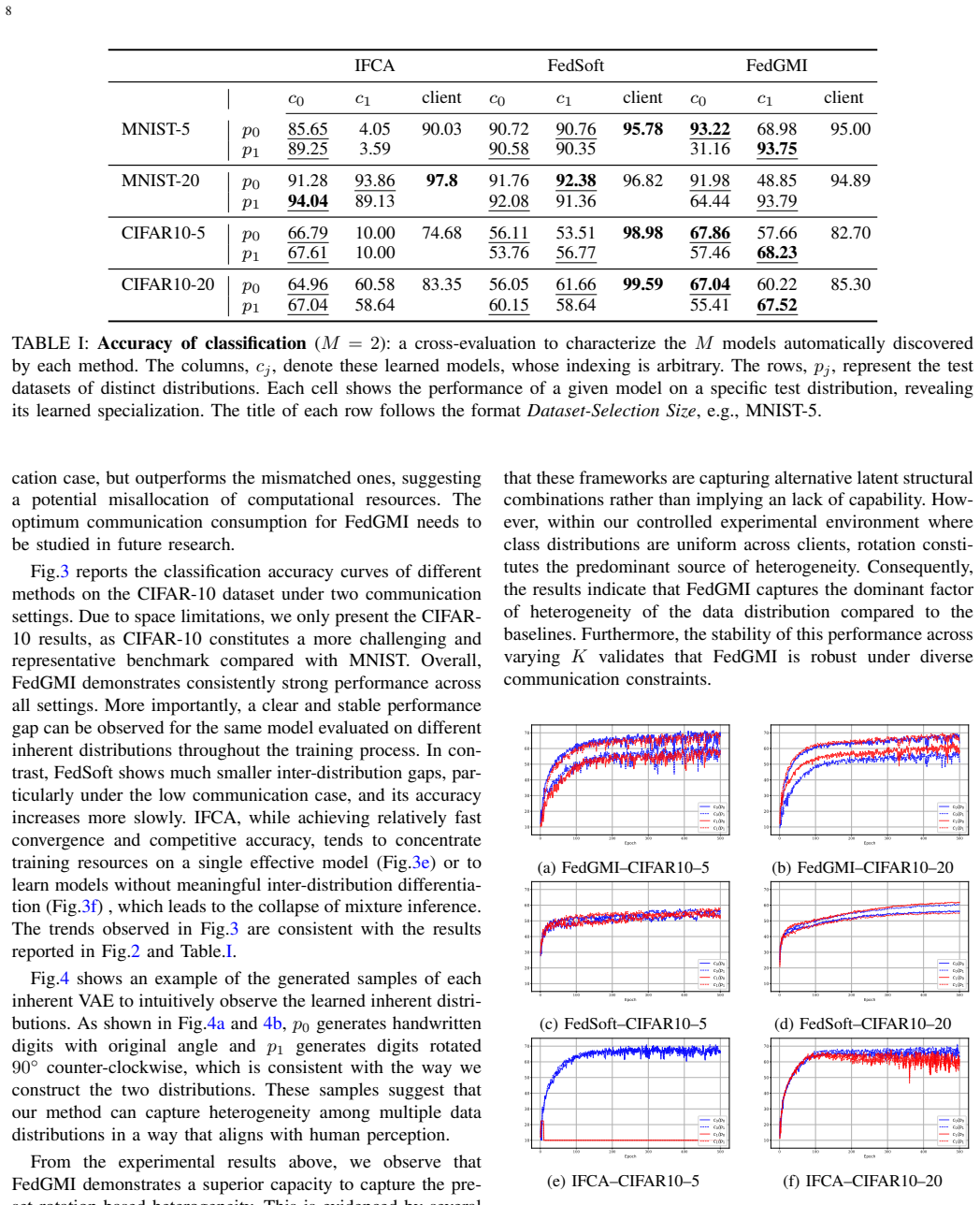


read the original abstract
Federated Learning (FL) facilitates collaborative model training across decentralized clients while preserving data privacy by avoiding raw data exchange. Despite its potential, FL performance is often compromised by data heterogeneity across clients. To address this, Clustered Federated Learning (CFL) groups clients with similar data distributions to improve model performance, but constrained by intra-cluster heterogeneity. Conversely, Personalized Federated Learning (PFL) tailors models to individual clients, but usually neglects the underlying structural similarities among clients. In this work, we investigate a probabilistic mixture (PM) scenario, where each client's local data distribution is modeled as a convex combination of several shared inherent distributions. To effectively model this structure, we propose FedGMI, a framework that utilizes Variational Autoencoders (VAEs) as generative density estimators to represent these inherent distributions and infer the mixture components of clients' local data distributions. This approach enables structured personalization without sacrificing the benefits of collaborative learning. Extensive experiments demonstrate that FedGMI effectively characterizes and discriminate the inherent distributions, as well as accurately estimates mixture proportions. Furthermore, FedGMI maintains robust performance even under communication cost constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedGMI, a federated learning framework for probabilistic mixture (PM) scenarios in which each client's local data distribution is modeled as a convex combination of several shared inherent distributions. It uses VAEs as generative density estimators to represent these components, infer per-client mixture proportions, and enable structured personalization while preserving collaborative benefits under FL constraints. The abstract states that extensive experiments show effective characterization of distributions, accurate proportion estimation, and robustness to communication constraints.
Significance. If the central claims hold, FedGMI would provide a principled middle path between clustered and personalized FL by exploiting a low-rank mixture structure via generative models, potentially improving performance on structured non-IID data without raw data exchange. The VAE-based density estimation and local weight inference are technically interesting, but significance is currently limited by the absence of quantitative metrics, baselines, or ablation results in the abstract and by the lack of explicit validation that real data conform to the assumed mixture structure.
major comments (3)
- [Abstract and model description] The central modeling assumption (each client's distribution is a convex combination of a modest number of shared components faithfully captured by VAEs) is load-bearing for all claimed advantages over standard CFL or PFL. No derivation or synthetic-data experiment is provided showing that the federated VAE training plus local inference procedure recovers both the component densities and the mixing coefficients under the FL communication constraints (see the probabilistic mixture scenario description and the FedGMI framework section).
- [Abstract and experimental section] The abstract asserts that 'extensive experiments demonstrate that FedGMI effectively characterizes and discriminates the inherent distributions, as well as accurately estimates mixture proportions,' yet supplies no quantitative metrics, baselines, ablation studies, or tables reporting e.g. KL divergence, proportion estimation error, or downstream task accuracy. This absence prevents verification that the empirical results actually support the central claims.
- [Method and discussion sections] No discussion of identifiability, sensitivity to the choice of component count K, or failure modes when the data-generating process deviates from the low-rank convex-combination assumption appears in the manuscript. If either the VAE density estimates are inaccurate or the mixture structure does not hold, the claimed structured personalization benefits disappear.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a concise statement of the precise aggregation rule used for VAE parameters across clients and the exact local procedure for inferring mixture weights.
- [Method] Notation for the mixture weights, VAE latent variables, and federated aggregation steps should be introduced consistently and defined before first use.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve clarity, add missing validations, and strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract and model description] The central modeling assumption (each client's distribution is a convex combination of a modest number of shared components faithfully captured by VAEs) is load-bearing for all claimed advantages over standard CFL or PFL. No derivation or synthetic-data experiment is provided showing that the federated VAE training plus local inference procedure recovers both the component densities and the mixing coefficients under the FL communication constraints (see the probabilistic mixture scenario description and the FedGMI framework section).
Authors: We appreciate the referee's emphasis on validating the core modeling assumption. While the FedGMI framework section describes the procedure, we acknowledge the need for explicit validation. In the revised manuscript, we will include a derivation of the recovery properties and a synthetic-data experiment demonstrating that the federated VAE training and local inference recover the component densities and mixing coefficients under communication constraints. revision: yes
-
Referee: [Abstract and experimental section] The abstract asserts that 'extensive experiments demonstrate that FedGMI effectively characterizes and discriminates the inherent distributions, as well as accurately estimates mixture proportions,' yet supplies no quantitative metrics, baselines, ablation studies, or tables reporting e.g. KL divergence, proportion estimation error, or downstream task accuracy. This absence prevents verification that the empirical results actually support the central claims.
Authors: We agree that the abstract would benefit from quantitative details to support the claims. The experimental section of the manuscript includes results with metrics such as distribution characterization accuracy and proportion estimation errors, along with comparisons to baselines. To address the concern, we will revise the abstract to include specific quantitative highlights and ensure all experimental results are presented with clear tables, baselines, and ablations in the revised version. revision: yes
-
Referee: [Method and discussion sections] No discussion of identifiability, sensitivity to the choice of component count K, or failure modes when the data-generating process deviates from the low-rank convex-combination assumption appears in the manuscript. If either the VAE density estimates are inaccurate or the mixture structure does not hold, the claimed structured personalization benefits disappear.
Authors: This comment is well-taken. The manuscript includes some analysis of the component count K in the experiments, but a comprehensive discussion of identifiability, sensitivity, and failure modes is lacking. We will add a new paragraph in the discussion section addressing identifiability of the mixture components under the VAE model, sensitivity to K, and potential failure modes when the data deviates from the assumed structure, including how performance may degrade. revision: yes
Circularity Check
No significant circularity in the derivation chain.
full rationale
The paper models client data as convex combinations of shared inherent distributions and proposes FedGMI to use VAEs for density estimation and mixture inference under federated constraints. No equations, self-citations, or steps in the abstract or described framework reduce the claimed inferences or performance to quantities defined by their own fitted parameters by construction. The approach applies standard VAE training and FL aggregation to the probabilistic mixture scenario without self-definitional loops, fitted inputs renamed as predictions, or load-bearing uniqueness theorems imported from the authors' prior work. Claims rest on experimental validation of characterization and proportion estimation rather than tautological reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Each client's local data distribution is a convex combination of several shared inherent distributions
Reference graph
Works this paper leans on
-
[1]
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from 10 IFCA FedSoft FedGMI c0 c1 c2 clientc 0 c1 c2 clientc 0 c1 c2 client MNIST-5 p0 91.18 84.68 87.59 92.50 84.22 85.64 85.02 93.11 34.15 39.18 93.36 91.77p1 88.63 92.33 88.99 83.17 82.56 83.24 93.9928.47 23.66 p2 88.28 88.54 91.10 91.65 ...
-
[2]
F. Sattler, K.-R. Müller, and W. Samek, “Clustered federated learning: Model-agnostic distributed multitask optimization under privacy con- straints,”IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 8, pp. 3710–3722, 2021
work page 2021
-
[3]
An Efficient Framework for Clustered Federated Learning,
A. Ghosh, J. Chung, D. Yin, and K. Ramchandran, “An Efficient Framework for Clustered Federated Learning,”IEEE Transactions on Information Theory, vol. 68, no. 12, pp. 8076–8091, Dec. 2022. [Online]. Available: https://ieeexplore.ieee.org/document/ 9832954/?arnumber=9832954
work page 2022
-
[4]
H. Ge, S. R. Pokhrel, Z. Liu, J. Wang, and G. Li, “PFL-DKD: Modeling decoupled knowledge fusion with distillation for improving personalized federated learning,”Computer Networks, p. 110758, Aug
-
[5]
Available: https://linkinghub.elsevier.com/retrieve/pii/ S1389128624005905
[Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/ S1389128624005905
-
[6]
Federated Multi-Task Learning under a Mixture of Distributions,
O. Marfoq, G. Neglia, A. Bellet, L. Kameni, and R. Vidal, “Federated Multi-Task Learning under a Mixture of Distributions,” Nov. 2022. [Online]. Available: http://arxiv.org/abs/2108.10252
-
[7]
FedCE: Personalized Federated Learning Method based on Clustering Ensembles,
L. Cai, N. Chen, Y . Cao, J. He, and Y . Li, “FedCE: Personalized Federated Learning Method based on Clustering Ensembles,” in Proceedings of the 31st ACM International Conference on Multimedia. Ottawa ON Canada: ACM, Oct. 2023, pp. 1625–1633. [Online]. Available: https://dl.acm.org/doi/10.1145/3581783.3612217
-
[8]
FedSoft: Soft Clustered Federated Learning with Proximal Local Updating,
Y . Ruan and C. Joe-Wong, “FedSoft: Soft Clustered Federated Learning with Proximal Local Updating,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 7, pp. 8124–8131, Jun. 2022. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/20785
work page 2022
-
[9]
Personalized federated learning under mixture of distribu- tions,
Y . Wu, S. Zhang, W. Yu, Y . Liu, Q. Gu, D. Zhou, H. Chen, and W. Cheng, “Personalized federated learning under mixture of distribu- tions,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 37 860–37 879
work page 2023
-
[10]
International Conference on Learning Representations , year =
X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the Convergence of FedAvg on Non-IID Data,” Jun. 2020, arXiv:1907.02189 [stat]. [Online]. Available: http://arxiv.org/abs/1907.02189
-
[11]
Optimizing federated learning on non-iid data with reinforcement learning,
H. Wang, Z. Kaplan, D. Niu, and B. Li, “Optimizing federated learning on non-iid data with reinforcement learning,” inIEEE INFOCOM 2020 - IEEE Conference on Computer Communications, 2020, pp. 1698–1707
work page 2020
-
[12]
S. Wan, J. Lu, P. Fan, Y . Shao, C. Peng, K. B. Letaief, and J. Chuai, “How global observation works in federated learning: Integrating vertical training into horizontal federated learning,”IEEE Internet of Things Journal, vol. 10, no. 11, pp. 9482–9497, 2023
work page 2023
-
[13]
Isfl: Federated learning for non-i.i.d. data with local importance sampling,
Z. Zhu, Y . Shi, P. Fan, C. Peng, and K. B. Letaief, “Isfl: Federated learning for non-i.i.d. data with local importance sampling,”IEEE Internet of Things Journal, vol. 11, no. 16, pp. 27 448–27 462, 2024
work page 2024
-
[14]
Sam: An efficient approach with selective aggregation of models in federated learning,
Y . Shi, P. Fan, Z. Zhu, C. Peng, F. Wang, and K. B. Letaief, “Sam: An efficient approach with selective aggregation of models in federated learning,”IEEE Internet of Things Journal, vol. 11, no. 11, pp. 20 769– 20 783, 2024
work page 2024
-
[15]
Fedlp: Layer-wise pruning mechanism for communication-computation efficient federated learning,
Z. Zhu, Y . Shi, J. Luo, F. Wang, C. Peng, P. Fan, and K. B. Letaief, “Fedlp: Layer-wise pruning mechanism for communication-computation efficient federated learning,” inICC 2023 - IEEE International Confer- ence on Communications, 2023, pp. 1250–1255
work page 2023
-
[16]
Fednc: A secure and efficient federated learning method with network coding,
Y . Shi, Z. Zhu, P. Fan, K. B. Letaief, and C. Peng, “Fednc: A secure and efficient federated learning method with network coding,” in2024 IEEE Wireless Communications and Networking Conference (WCNC), 2024, pp. 1–6
work page 2024
-
[17]
An expectation- maximization perspective on federated learning,
C. Louizos, M. Reisser, J. Soriaga, and M. Welling, “An expectation- maximization perspective on federated learning,”arXiv preprint arXiv:2111.10192, 2021
-
[18]
C. Briggs, Z. Fan, and P. Andras, “Federated learning with hierarchical clustering of local updates to improve training on non-iid data,” in2020 international joint conference on neural networks (IJCNN). IEEE, 2020, pp. 1–9
work page 2020
-
[19]
Federated learning via varia- tional bayesian inference: Personalization, sparsity and clustering,
X. Zhang, W. Li, Y . Shao, and Y . Li, “Federated learning via varia- tional bayesian inference: Personalization, sparsity and clustering,”arXiv preprint arXiv:2303.04345, 2023
-
[20]
A bayesian framework for clustered federated learning,
P. Wu, T. Imbiriba, and P. Closas, “A bayesian framework for clustered federated learning,”arXiv preprint arXiv:2410.15473, 2024
-
[21]
Fedgan: Federated gen- erative adversarial networks for distributed data,
M. Rasouli, T. Sun, and R. Rajagopal, “FedGAN: Federated Generative Adversarial Networks for Distributed Data,” Jun. 2020, arXiv:2006.07228 [cs]. [Online]. Available: http://arxiv.org/abs/2006. 07228
-
[22]
Y . Wu, Y . Kang, J. Luo, Y . He, and Q. Yang, “FedCG: Leverage Conditional GAN for Protecting Privacy and Maintaining Competitive Performance in Federated Learning,” inProceedings of the Thirty- First International Joint Conference on Artificial Intelligence, Jul. 2022, pp. 2334–2340, arXiv:2111.08211 [cs]. [Online]. Available: http://arxiv.org/abs/2111.08211
-
[23]
Federated variational generative learning for heterogeneous data in distributed environments,
W. Xie, R. Xiong, J. Zhang, J. Jin, and J. Luo, “Federated variational generative learning for heterogeneous data in distributed environments,” Journal of Parallel and Distributed Computing, vol. 191, p. 104916, 11 Sep. 2024. [Online]. Available: https://linkinghub.elsevier.com/retrieve/ pii/S0743731524000807
work page 2024
-
[24]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-Encoding Variational Bayes,” Dec. 2022, arXiv:1312.6114 [stat]. [Online]. Available: http://arxiv.org/ abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
M. Rivera, “How to train your V AE,” Jun. 2024, arXiv:2309.13160 [cs] Read_Status: New Read_Status_Date: 2024-11-06T14:56:55.256Z. [Online]. Available: http://arxiv.org/abs/2309.13160
-
[26]
1 1 n Pn i=1 exp(θT g(xi)) 2 # ≤E
L. Yang, Z. Zhang, Y . Song, S. Hong, R. Xu, Y . Zhao, W. Zhang, B. Cui, and M.-H. Yang, “Diffusion models: A comprehensive survey of methods and applications,” 2024. [Online]. Available: https://arxiv.org/abs/2209.00796
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.