Recognition: 2 theorem links
· Lean TheoremReasoning Compression with Mixed-Policy Distillation
Pith reviewed 2026-05-12 01:24 UTC · model grok-4.3
The pith
Mixed-Policy Distillation enables smaller reasoning models to produce concise trajectories by aligning with teacher-compressed versions of their own outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By distilling teacher-compressed student trajectories rather than raw teacher outputs or on-policy distributions, MPD combines exploration from the student policy with compression guidance from the teacher, leading to more efficient small-model reasoning.
What carries the argument
Mixed-Policy Distillation (MPD), a framework where a teacher rewrites student-sampled reasoning trajectories into concise forms and the student aligns to them via KL divergence.
Load-bearing premise
The teacher's rewritten concise trajectories must preserve the correctness and logical validity of the original student reasoning without introducing errors or omissions.
What would settle it
If applying MPD to a benchmark results in lower accuracy than the baseline student model on problems where the original trajectories were correct, that would indicate the compression introduces invalid reasoning.
Figures


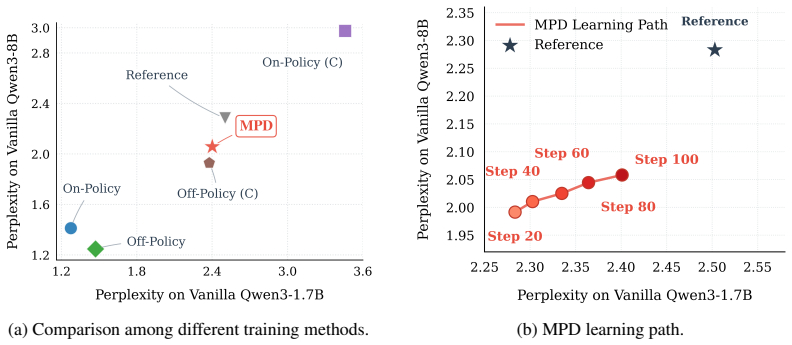
read the original abstract
Reasoning-centric large language models (LLMs) achieve strong performance by generating intermediate reasoning trajectories, but often incur excessive token usage and high inference-time decoding cost. We observe that, when solving the same problems, larger reasoning models can often produce more concise traces, whereas smaller reasoning models tend to generate longer and more redundant trajectories. This is especially problematic in real-world deployment, where memory, latency, and serving-cost constraints often favor smaller models. Our observations suggest that reasoning compression can be transferred from large models to small ones rather than enforced through explicit length constraints. Based on this insight, we propose Mixed-Policy Distillation (MPD), a reasoning compression framework that transfers concise reasoning behavior from a larger-sized teacher to a smaller student by distilling teacher-compressed student trajectories. Unlike on-policy distillation, which aligns the student with teacher distributions over verbose student trajectories, or off-policy distillation, which relies on teacher-generated trajectories and may suffer from distribution mismatch, MPD combines the strengths of both. Given a student-sampled trajectory, the teacher rewrites it into a more concise reasoning trace, and the student is trained via KL-based alignment on the compressed trajectory. This preserves student-policy exploration while injecting teacher-guided compression. Experiments on Qwen3-1.7B show that MPD reduces token usage by up to 27.1% while improving performance across multiple reasoning benchmarks, demonstrating an effective approach to efficient small-model reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mixed-Policy Distillation (MPD) to compress reasoning trajectories in smaller LLMs. It observes that larger models generate more concise traces than smaller ones on the same problems. MPD works by having the student sample a trajectory, the teacher rewrite it concisely, and then aligning the student to the compressed trace via KL divergence. This is positioned as combining strengths of on-policy and off-policy distillation. Experiments on Qwen3-1.7B are reported to achieve up to 27.1% token reduction while improving performance on multiple reasoning benchmarks.
Significance. If the empirical claims hold after proper validation, MPD could provide a useful mechanism for transferring concise reasoning behavior to resource-constrained models without explicit length regularization, addressing inference costs in deployment. The mixed-policy framing may also contribute to distillation literature by preserving student exploration while injecting teacher compression signals.
major comments (2)
- [Abstract] Abstract: The headline result of 27.1% token reduction plus performance lift on Qwen3-1.7B is presented without any experimental details, baselines, benchmarks, variance, controls, or statistical tests. This is load-bearing for the central performance claim and prevents verification of the result.
- [Method] Method description: The MPD procedure (student samples trajectory, teacher rewrites concisely, KL alignment) contains no explicit measurement or safeguard for rewrite fidelity, answer preservation, or logical validity. Without such checks or an ablation against plain off-policy teacher trajectories, the gains cannot be attributed specifically to compression transfer rather than incidental quality improvement in the rewrites.
minor comments (1)
- [Abstract] The abstract could benefit from a short pseudocode or diagram clarifying the three distillation variants (on-policy, off-policy, mixed) to make the positioning clearer.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, proposing revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result of 27.1% token reduction plus performance lift on Qwen3-1.7B is presented without any experimental details, baselines, benchmarks, variance, controls, or statistical tests. This is load-bearing for the central performance claim and prevents verification of the result.
Authors: We agree that the abstract summarizes the headline result at a high level without including experimental specifics such as the exact benchmarks, variance, or controls. The body of the manuscript (Section 4) provides these details, including results on GSM8K, MATH, and other reasoning tasks with reported means and standard deviations. To directly address verifiability from the abstract itself, we will revise it to concisely reference the student model, primary benchmarks, and the presence of variance reporting. revision: partial
-
Referee: [Method] Method description: The MPD procedure (student samples trajectory, teacher rewrites concisely, KL alignment) contains no explicit measurement or safeguard for rewrite fidelity, answer preservation, or logical validity. Without such checks or an ablation against plain off-policy teacher trajectories, the gains cannot be attributed specifically to compression transfer rather than incidental quality improvement in the rewrites.
Authors: The referee is correct that the method description does not include explicit fidelity safeguards or an ablation against standard off-policy teacher trajectories. While improved benchmark performance in our experiments is consistent with preserved answer correctness, we did not report quantitative fidelity metrics (e.g., answer preservation rates between original and rewritten trajectories) or the requested ablation. We will incorporate these measurements and the ablation study in the revised manuscript to better isolate the contribution of compression transfer. revision: yes
Circularity Check
No significant circularity; purely empirical procedure
full rationale
The paper advances an empirical training procedure (student samples trajectory, teacher rewrites concisely, KL alignment on the rewrite) motivated by an observational claim about model-size differences in trace length. No mathematical derivation, uniqueness theorem, fitted parameter, or first-principles prediction is presented that could reduce to its own inputs by construction. All reported gains (token reduction, benchmark scores) are experimental outcomes on held-out data rather than tautological restatements of the training objective. No self-citation chain is invoked to justify the core mechanism, and the method remains self-contained against external benchmarks without requiring the target result to be presupposed.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Given a student-sampled trajectory, the teacher rewrites it into a more concise reasoning trace, and the student is trained via KL-based alignment on the compressed trajectory.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MPD reduces token usage by up to 27.1% while improving performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neura...
work page 2022
-
[2]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orl...
work page 2022
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.CoRR, abs/2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Stop overthinking: A survey on efficient reasoning for large language models.Trans
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, Hanjie Chen, and Xia Hu. Stop overthinking: A survey on efficient reasoning for large language models.Trans. Mach. Learn. Res., 2025, 2025
work page 2025
-
[5]
Wait, we don’t need to "wait"! removing thinking tokens improves reasoning efficiency
Chenlong Wang, Yuanning Feng, Dongping Chen, Zhaoyang Chu, Ranjay Krishna, and Tianyi Zhou. Wait, we don’t need to "wait"! removing thinking tokens improves reasoning efficiency. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, N...
work page 2025
-
[6]
The benefits of a concise chain of thought on problem-solving in large language models
Matthew Renze and Erhan Guven. The benefits of a concise chain of thought on problem-solving in large language models. In2nd International Conference on Foundation and Large Language Models, FLLM 2024, Dubai, United Arab Emirates, November 26-29, 2024, pages 476–483. IEEE, 2024
work page 2024
-
[7]
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. Chain of draft: Thinking faster by writing less. CoRR, abs/2502.18600, 2025
-
[8]
C3ot: Generating shorter chain-of-thought without compromising effectiveness
Yu Kang, Xianghui Sun, Liangyu Chen, and Wei Zou. C3ot: Generating shorter chain-of-thought without compromising effectiveness. In Toby Walsh, Julie Shah, and Zico Kolter, editors,Thirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence, Fifteenth Symposium on Educational Adva...
work page 2025
-
[9]
Tokenskip: Controllable chain-of-thought compression in llms
Heming Xia, Chak Tou Leong, Wenjie Wang, Yongqi Li, and Wenjie Li. Tokenskip: Controllable chain-of-thought compression in llms. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, pa...
work page 2025
-
[10]
Yifan Wu, Jingze Shi, Bingheng Wu, Jiayi Zhang, Xiaotian Lin, Nan Tang, and Yuyu Luo. Concise reasoning, big gains: Pruning long reasoning trace with difficulty-aware prompting.CoRR, abs/2505.19716, 2025. 5https://ominoproject.eu/ 10
-
[11]
Zhensheng Jin, Xinze Li, Yifan Ji, Chunyi Peng, Zhenghao Liu, Qi Shi, Yukun Yan, Shuo Wang, Furong Peng, and Ge Yu. Recut: Balancing reasoning length and accuracy in llms via stepwise trails and preference optimization. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational ...
work page 2025
-
[12]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. CoRR, abs/2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Pranjal Aggarwal and Sean Welleck. L1: controlling how long A reasoning model thinks with reinforcement learning.CoRR, abs/2503.04697, 2025
-
[14]
Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning.Trans
Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning.Trans. Mach. Learn. Res., 2026, 2026
work page 2026
-
[15]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. CRISP: Compressed reasoning via iterative self-policy distillation.arXiv preprint arXiv:2603.05433, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Openmathinstruct-2: Accelerating AI for math with massive open-source instruction data
Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. Openmathinstruct-2: Accelerating AI for math with massive open-source instruction data. InThe Thir- teenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
work page 2025
-
[17]
Qwen Team. Qwen3 technical report.CoRR, abs/2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
OpenAI. Openai o1 system card.CoRR, abs/2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.CoRR, abs/2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Nguyen, Quang Pham, and Nghi D
Dung Manh Nguyen, Thang Chau Phan, Nam Le Hai, Tien-Thong Doan, Nam V . Nguyen, Quang Pham, and Nghi D. Q. Bui. Codemmlu: A multi-task benchmark for assessing code understanding & reasoning capabilities of codellms. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
work page 2025
-
[21]
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual ...
work page 2025
-
[22]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Do NOT think that much for 2+3=? on the overthinking of o1-like llms.CoRR, abs/2412.21187, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
arXiv preprint arXiv:2603.09906 , year=
Zorik Gekhman, Roee Aharoni, Eran Ofek, Mor Geva, Roi Reichart, and Jonathan Herzig. Thinking to recall: How reasoning unlocks parametric knowledge in llms.CoRR, abs/2603.09906, 2026
-
[24]
How well do llms compress their own chain-of- thought? a token complexity approach
Ayeong Lee, Ethan Che, and Tianyi Peng. How well do llms compress their own chain-of-thought? A token complexity approach.CoRR, abs/2503.01141, 2025
-
[25]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
work page 2024
-
[26]
OpenReview.net, 2024
work page 2024
-
[27]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
work page 2024
-
[28]
Kevin Lu and Thinking Machines Lab. On-policy distillation. https://thinkingmachines.ai/blog/ on-policy-distillation/, 2025
work page 2025
-
[29]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.CoRR, abs/2602.12275, 2026. 11
work page internal anchor Pith review arXiv 2026
-
[30]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, Ch...
work page 2019
-
[31]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
work page 2024
-
[32]
American invitational mathematics examination (aime) 2025, 2025
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025, 2025
work page 2025
-
[33]
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. Overconfident errors need stronger correction: Asymmetric confidence penalties for reinforcement learning.CoRR, abs/2602.21420, 2026
-
[34]
Protect our environment from information overload.Nature Human Behaviour, 8(3):402–403, 2024
Janusz A Hołyst, Philipp Mayr, Michael Thelwall, Ingo Frommholz, Shlomo Havlin, Alon Sela, Yoed N Kenett, Denis Helic, Aljoša Rehar, Sebastijan R Maˇcek, et al. Protect our environment from information overload.Nature Human Behaviour, 8(3):402–403, 2024
work page 2024
-
[35]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Z. Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-pe...
work page 2019
-
[36]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. Huggingface’s transformers: State-of- the-art natural language processing.CoRR, abs/1910.03771, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[37]
Woosuk Kwon.vLLM: An Efficient Inference Engine for Large Language Models. PhD thesis, UC Berkeley, 2025
work page 2025
-
[38]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self- distilled reasoner: On-policy self-distillation for large language models.CoRR, abs/2601.18734, 2026. 12 Table 6: Hyper-parameter configurations for MPD. Training & Loss Sampling (Distillation) Dataset OpenMathInstruct-2 Max Completion (Student) 27,000 Studen...
work page internal anchor Pith review arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.