Recognition: 2 theorem links
· Lean TheoremHairGPT: Strand-as-Language Autoregressive Modeling for Realistic 3D Hairstyle Synthesis
Pith reviewed 2026-05-12 01:34 UTC · model grok-4.3
The pith
HairGPT models 3D hairstyles as autoregressive sequences of strands using spatial and structural decoupling for semantic control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
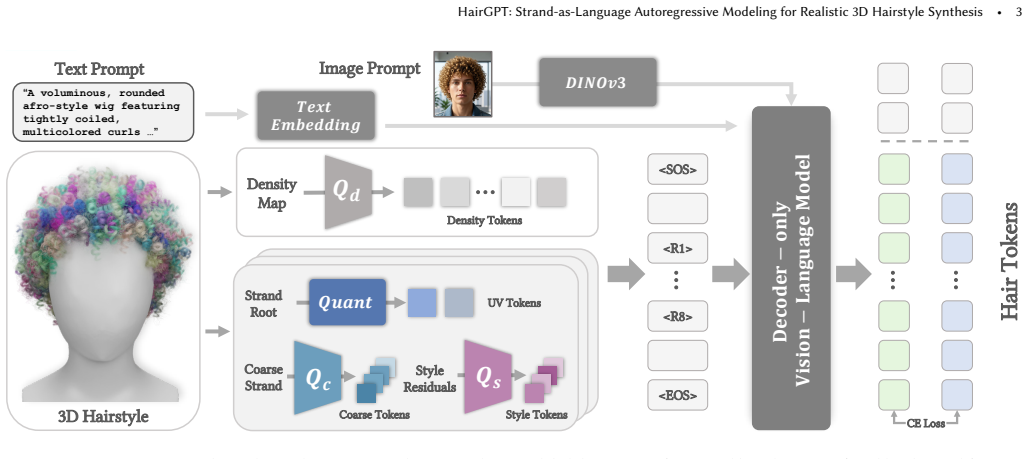
HairGPT formulates realistic 3D hairstyle synthesis as a dual-decoupled autoregressive sequence modeling problem that treats strands as generative primitives, applies spatial decoupling across semantic scalp regions and structural decoupling along a hierarchical strand representation progressing from global layout to fine-grained style, and uses a geometric tokenizer together with region-aware semantic annotations to guide generation.
What carries the argument
Dual-decoupled autoregressive strand sequence model that separates spatial regions on the scalp from hierarchical levels along each strand.
If this is right
- Enables compositional editing by changing specific scalp regions or strand hierarchy levels independently.
- Supports synthesis of rare and complex hairstyles through targeted semantic guidance.
- Adapts the same model to stylized domains while preserving high visual fidelity.
- Provides robust semantic conditioning that aligns generation with artist-specified regions and styles.
Where Pith is reading between the lines
- The strand-sequence formulation could be tested on other linear fibrous structures such as fur or grass to check whether the same decoupling yields comparable control.
- Integration with existing digital grooming software would let artists combine the autoregressive generator with manual adjustments in a single workflow.
- Adding temporal tokens to the sequence might allow the same architecture to produce animated hair motion without separate simulation steps.
Load-bearing premise
That separating hair strands into independent spatial regions and hierarchical structure levels will produce coherent overall styles without breaking natural connections between neighboring strands.
What would settle it
Generate hairstyles and check whether adjacent scalp regions show visible discontinuities in strand density, direction, or curl pattern, or whether editing one region introduces artifacts in distant areas.
Figures












read the original abstract
Hair is a rich medium of visual and cultural expression, yet its digital modeling remains challenging due to the duality of fluidity and structure. Many existing generative approaches rely primarily on continuous diffusion fields, which entangle global topology with local texture and obscure the semantic and structural organization of hairstyles. To address this, we propose HairGPT, a strand-centric framework that treats strands as generative primitives and formulates realistic 3D hairstyle synthesis as a dual-decoupled autoregressive sequence modeling problem. Our method applies spatial decoupling across semantic scalp regions and structural decoupling along a hierarchical strand representation, progressing from global layout to fine-grained style. We further introduce a geometric tokenizer and region-aware semantic annotations to guide strand-level generation, enabling compositional editing, synthesis of rare and complex hairstyles, and adaptation to stylized domains. By aligning generative modeling with the workflow of digital grooming, HairGPT turns hair generation from opaque texture synthesis into a structured and semantically controllable authoring process, supporting robust semantic conditioning and high-fidelity results across realistic and stylized domains. Project Page: https://haiminluo.github.io/hairgpt/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HairGPT, a strand-centric autoregressive framework for 3D hairstyle synthesis that models strands as generative primitives. It applies spatial decoupling across semantic scalp regions and structural decoupling via a hierarchical strand representation progressing from global layout to fine-grained details. A geometric tokenizer and region-aware semantic annotations are proposed to enable compositional editing, synthesis of rare hairstyles, and adaptation to stylized domains, with the overall approach aligned to digital grooming workflows for semantic controllability and high-fidelity output. The manuscript includes the hierarchical formulation, tokenizer details, quantitative metrics such as FID and perceptual scores, qualitative results across domains, and ablations validating the decoupling components.
Significance. If the reported metrics, ablations, and qualitative results hold, this represents a solid contribution to computer graphics by reframing hair generation as structured sequence modeling rather than entangled field synthesis. The explicit dual decoupling and grooming-workflow alignment provide a practical path to semantic control and domain adaptation that prior diffusion approaches lack. The presence of quantitative evaluations, ablations showing degradation when decoupling is removed, and coverage of both realistic and stylized cases adds credibility and potential impact for digital content creation tools.
minor comments (3)
- [Abstract] Abstract: While the high-level claims are clear, the abstract does not reference the specific quantitative metrics (FID, perceptual scores) or ablation outcomes that appear in the full manuscript; adding a brief mention would better preview the empirical support.
- [Experiments] Experiments section: The qualitative figure captions would benefit from explicit references to the semantic conditioning parameters or region annotations used in each example to aid reproducibility and interpretation of the controllability results.
- [Method] Notation: The hierarchical strand representation is described at a high level; a compact pseudocode or diagram in the method section clarifying the progression from global to local tokens would improve clarity without altering the technical content.
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment of HairGPT, as well as the recommendation for minor revision. The review accurately reflects the paper's focus on dual-decoupled autoregressive strand modeling, geometric tokenization, and alignment with grooming workflows.
Circularity Check
No significant circularity detected
full rationale
The paper introduces HairGPT as a new strand-centric autoregressive framework with explicit spatial decoupling across scalp regions and structural decoupling along a hierarchical strand representation, plus a geometric tokenizer and region-aware annotations. These elements are presented as architectural choices aligned with digital grooming workflows, not as derivations that reduce to prior fitted parameters or self-citations. No equations appear in the provided text that equate a claimed prediction to its own inputs by construction, and the central claims are supported by ablations, FID/perceptual metrics, and qualitative results across domains rather than self-referential definitions. The formulation is self-contained as a novel modeling approach without load-bearing reductions to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hair strands can be treated as generative primitives in an autoregressive sequence model without loss of structural fidelity
invented entities (1)
-
geometric tokenizer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual-decoupled autoregressive sequence modeling problem... spatial decoupling across semantic scalp regions and structural decoupling along a hierarchical strand representation
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-head product quantization... 8 discrete tokens per strand... 1024 density tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
FirstName Alpher , title =
-
[3]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[4]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[5]
FirstName Alpher and FirstName Gamow , title =
-
[6]
Optimizing WebRTC for Cloud Streaming of XR , author=
-
[7]
The 26th International Conference on 3D Web Technology , pages=
Sharing ambient objects using real-time point cloud streaming in web-based XR remote collaboration , author=. The 26th International Conference on 3D Web Technology , pages=
-
[8]
European Conference on Computer Vision , year=
R2L: Distilling Neural Radiance Field to Neural Light Field for Efficient Novel View Synthesis , author=. European Conference on Computer Vision , year=
-
[9]
Matusik, Wojciech and Pfister, Hanspeter and Ngan, Addy and Beardsley, Paul and Ziegler, Remo and McMillan, Leonard , title =. ACM Trans. Graph. , month =. 2002 , issue_date =. doi:10.1145/566654.566599 , abstract =
-
[10]
Proceedings of the 2003 Symposium on Interactive 3D Graphics , pages =
Vlasic, Daniel and Pfister, Hanspeter and Molinov, Sergey and Grzeszczuk, Radek and Matusik, Wojciech , title =. Proceedings of the 2003 Symposium on Interactive 3D Graphics , pages =. 2003 , isbn =. doi:10.1145/641480.641496 , abstract =
-
[11]
Wood, Daniel N. and Azuma, Daniel I. and Aldinger, Ken and Curless, Brian and Duchamp, Tom and Salesin, David H. and Stuetzle, Werner , title =. Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques , pages =. 2000 , isbn =. doi:10.1145/344779.344925 , abstract =
-
[12]
URL https://doi.org/10.1145/3528223
Thomas M\"uller and Alex Evans and Christoph Schied and Alexander Keller , title =. ACM Trans. Graph. , issue_date =. 2022 , pages =. doi:10.1145/3528223.3530127 , publisher =
-
[13]
Chen, Anpei and Wu, Minye and Zhang, Yingliang and Li, Nianyi and Lu, Jie and Gao, Shenghua and Yu, Jingyi , title =. Proc. ACM Comput. Graph. Interact. Tech. , month =. 2018 , issue_date =. doi:10.1145/3203192 , abstract =
-
[14]
Lefebvre, Sylvain and Hoppe, Hugues , title =. ACM Trans. Graph. , month =. 2006 , issue_date =. doi:10.1145/1141911.1141926 , abstract =
-
[15]
Communications of the ACM , volume=
Nerf: Representing scenes as neural radiance fields for view synthesis , author=. Communications of the ACM , volume=. 2021 , publisher=
work page 2021
-
[16]
Dor Verbin and Peter Hedman and Ben Mildenhall and Todd Zickler and Jonathan T. Barron and Pratul P. Srinivasan , journal=
-
[17]
H. Luo and A. Chen and Q. Zhang and B. Pang and M. Wu and L. Xu and J. Yu , booktitle =. Convolutional Neural Opacity Radiance Fields , year =. doi:10.1109/ICCP51581.2021.9466273 , publisher =
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[19]
ACM Transactions on Graphics (TOG) , volume=
Editable free-viewpoint video using a layered neural representation , author=. ACM Transactions on Graphics (TOG) , volume=. 2021 , publisher=
work page 2021
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ibrnet: Learning multi-view image-based rendering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
HumanNeRF: Efficiently Generated Human Radiance Field from Sparse Inputs , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[23]
arXiv preprint arXiv:2202.08614 , year=
Fourier PlenOctrees for Dynamic Radiance Field Rendering in Real-time , author=. arXiv preprint arXiv:2202.08614 , year=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Plenoctrees for real-time rendering of neural radiance fields , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[25]
Plenoxels: Radiance Fields without Neural Networks , author=. 2022 , booktitle=
work page 2022
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
arXiv preprint arXiv:2208.00277 , year=
Mobilenerf: Exploiting the polygon rasterization pipeline for efficient neural field rendering on mobile architectures , author=. arXiv preprint arXiv:2208.00277 , year=
-
[28]
Bian, Zhengda and Li, Shenggui and Wang, Wei and You, Yang , title =. 2021 , isbn =. doi:10.1145/3458817.3480859 , booktitle =
-
[29]
Zhang, Haoyu and Stafman, Logan and Or, Andrew and Freedman, Michael J. , title =. 2017 , isbn =. doi:10.1145/3127479.3127490 , booktitle =
-
[30]
Peng, Yanghua and Bao, Yixin and Chen, Yangrui and Wu, Chuan and Guo, Chuanxiong , title =. 2018 , isbn =. doi:10.1145/3190508.3190517 , booktitle =
-
[31]
Proceedings of the 13th USENIX Conference on Operating Systems Design and Implementation , pages =
Xiao, Wencong and Bhardwaj, Romil and Ramjee, Ramachandran and Sivathanu, Muthian and Kwatra, Nipun and Han, Zhenhua and Patel, Pratyush and Peng, Xuan and Zhao, Hanyu and Zhang, Quanlu and Yang, Fan and Zhou, Lidong , title =. Proceedings of the 13th USENIX Conference on Operating Systems Design and Implementation , pages =. 2018 , isbn =
work page 2018
-
[32]
Proceedings of the 17th Usenix Conference on Networked Systems Design and Implementation , pages =
Mahajan, Kshiteej and Balasubramanian, Arjun and Singhvi, Arjun and Venkataraman, Shivaram and Akella, Aditya and Phanishayee, Amar and Chawla, Shuchi , title =. Proceedings of the 17th Usenix Conference on Networked Systems Design and Implementation , pages =. 2020 , isbn =
work page 2020
-
[33]
and Zhu, Yibo and Jeon, Myeongjae and Qian, Junjie and Liu, Hongqiang and Guo, Chuanxiong , title =
Gu, Juncheng and Chowdhury, Mosharaf and Shin, Kang G. and Zhu, Yibo and Jeon, Myeongjae and Qian, Junjie and Liu, Hongqiang and Guo, Chuanxiong , title =. Proceedings of the 16th USENIX Conference on Networked Systems Design and Implementation , pages =. 2019 , isbn =
work page 2019
-
[34]
Bao, Yixin and Peng, Yanghua and Wu, Chuan and Li, Zongpeng , title =. 2018 , publisher =. doi:10.1109/INFOCOM.2018.8486422 , booktitle =
-
[35]
Proceedings of the 2019 USENIX Conference on Usenix Annual Technical Conference , pages =
Jeon, Myeongjae and Venkataraman, Shivaram and Phanishayee, Amar and Qian, unjie and Xiao, Wencong and Yang, Fan , title =. Proceedings of the 2019 USENIX Conference on Usenix Annual Technical Conference , pages =. 2019 , isbn =
work page 2019
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Giraffe: Representing scenes as compositional generative neural feature fields , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
arXiv preprint arXiv:2012.08503 , year=
Object-centric neural scene rendering , author=. arXiv preprint arXiv:2012.08503 , year=
-
[38]
ACM Transactions on Graphics (TOG) , volume=
Mixture of volumetric primitives for efficient neural rendering , author=. ACM Transactions on Graphics (TOG) , volume=. 2021 , publisher=
work page 2021
-
[39]
Internet Engineering Task Force, Internet Draft, draft-ietf-rtcweb-data-channel-13 , year=
WebRTC data channels , author=. Internet Engineering Task Force, Internet Draft, draft-ietf-rtcweb-data-channel-13 , year=
-
[40]
2016 GPU Technology Conference (https://goo
High performance video encoding with NVIDIA GPUs , author=. 2016 GPU Technology Conference (https://goo. gl/Bdjdgm) , year=
work page 2016
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Real-time high-resolution background matting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
Proceedings of the 28th annual conference on Computer graphics and interactive techniques , pages=
Unstructured lumigraph rendering , author=. Proceedings of the 28th annual conference on Computer graphics and interactive techniques , pages=
-
[44]
2018 IEEE international symposium on mixed and augmented reality adjunct (ISMAR-Adjunct) , pages=
Thoughts on the Future of WebXR and the Immersive Web , author=. 2018 IEEE international symposium on mixed and augmented reality adjunct (ISMAR-Adjunct) , pages=. 2018 , organization=
work page 2018
-
[45]
2020 International Conference on Intelligent Systems and Computer Vision (ISCV) , pages=
ARKit and ARCore in serve to augmented reality , author=. 2020 International Conference on Intelligent Systems and Computer Vision (ISCV) , pages=. 2020 , organization=
work page 2020
-
[46]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. arXiv e-prints , keywords =. doi:10.48550/arXiv.1801.03924 , archivePrefix =. 1801.03924 , primaryClass =
-
[47]
NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis , author=. CVPR , year=
-
[48]
ACM Transactions on Graphics (TOG) , volume=
Nerfactor: Neural factorization of shape and reflectance under an unknown illumination , author=. ACM Transactions on Graphics (TOG) , volume=. 2021 , publisher=
work page 2021
-
[49]
Advances in Neural Information Processing Systems (NeurIPS) , year =
A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[50]
IEEE International Conference on Computer Vision (ICCV) , year =
NeRD: Neural Reflectance Decomposition from Image Collections , author =. IEEE International Conference on Computer Vision (ICCV) , year =
-
[51]
Pumarola, Albert and Corona, Enric and Pons-Moll, Gerard and Moreno-Noguer, Francesc , booktitle=
-
[52]
Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Dynamic Scene From Monocular Video , author =
-
[53]
Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control , author=. 2021 , journal =
work page 2021
-
[54]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[55]
Fox, Edward A. and Heath, Lenwood S. and Chen, Qi Fan and Daoud, Amjad M. , title =. 1992 , issue_date =. doi:10.1145/129617.129623 , journal =
-
[56]
Real-time animation of human hair modeled in strips , author=. 2000 , organization=
work page 2000
-
[57]
An enhanced framework for real-time hair animation , author=. 2003 , organization=
work page 2003
-
[58]
Modelling and animating cartoon hair with nurbs surfaces , author=. 2004 , organization=
work page 2004
-
[59]
A system of 3d hair style synthesis based on the wisp model , author=. The Visual Computer , volume=. 1999 , publisher=
work page 1999
-
[60]
The cluster hair model , author=. Graphical Models , volume=. 2000 , publisher=
work page 2000
-
[61]
IEEE Computer Graphics and Applications , volume=
V-hairstudio: an interactive tool for hair design , author=. IEEE Computer Graphics and Applications , volume=. 2001 , publisher=
work page 2001
-
[62]
Modelling and rendering techniques for african hairstyles , author=
-
[63]
IEEE Transactions on Visualization and Computer Graphics , volume=
A statistical wisp model and pseudophysical approaches for interactive hairstyle generation , author=. IEEE Transactions on Visualization and Computer Graphics , volume=. 2005 , publisher=
work page 2005
-
[64]
ACM Transactions on Graphics (TOG) , volume=
Interactive multiresolution hair modeling and editing , author=. ACM Transactions on Graphics (TOG) , volume=. 2002 , publisher=
work page 2002
-
[65]
Hair design based on the hierarchical cluster hair model , author=. 2004 , publisher=
work page 2004
-
[66]
ACM Transactions on Graphics (TOG) , volume=
Hair meshes , author=. ACM Transactions on Graphics (TOG) , volume=. 2009 , publisher=
work page 2009
-
[67]
The Journal of the Institute of Image Information and Television Engineers , volume=
Generation of 3D Hair Model from Multiple Pictures , author=. The Journal of the Institute of Image Information and Television Engineers , volume=. 1998 , doi=
work page 1998
-
[68]
Image-based hair capture by inverse lighting , author=
-
[69]
ACM transactions on graphics (TOG) , volume=
Capture of hair geometry from multiple images , author=. ACM transactions on graphics (TOG) , volume=. 2004 , publisher=
work page 2004
- [70]
-
[71]
Modeling hair from multiple views , author=
-
[72]
Multi-view hair capture using orientation fields , author=. 2012 , organization=
work page 2012
-
[73]
Wide-baseline hair capture using strand-based refinement , author=
-
[74]
ACM Transactions on Graphics (TOG) , volume=
Structure-aware hair capture , author=. ACM Transactions on Graphics (TOG) , volume=. 2013 , publisher=
work page 2013
-
[75]
Realistic hair modeling from a hybrid orientation field , author=. The Visual Computer , volume=. 2016 , publisher=
work page 2016
-
[76]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Strand-accurate multi-view hair capture , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[77]
Human hair inverse rendering using multi-view photometric data , author=. 2021 , publisher=
work page 2021
-
[78]
ACM Transactions on Graphics (TOG) , volume=
Robust hair capture using simulated examples , author=. ACM Transactions on Graphics (TOG) , volume=. 2014 , publisher=
work page 2014
-
[79]
A hybrid image-cad based system for modeling realistic hairstyles , author=
- [80]
-
[81]
Deepmvshair: Deep hair modeling from sparse views , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.