Recognition: 2 theorem links
· Lean TheoremWhen Agents Overtrust Environmental Evidence: An Extensible Agentic Framework for Benchmarking Evidence-Grounding Defects in LLM Agents
Pith reviewed 2026-05-13 06:56 UTC · model grok-4.3
The pith
LLM agents treat uncertain or stale environment observations as reliable evidence and proceed with incorrect actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EnvTrustBench defines an evidence-grounding defect as a behavioral failure in which an agent treats an environment-facing claim as sufficient evidence for action without resolving it against available current evidence, leading to a task-incorrect false path under the true environment state. The framework generates the workspace and objective, runs the evaluated agent while recording action-observation trajectories, and applies an oracle to produce a verdict. Testing across 55 cases shows these defects consistently emerge regardless of the LLM backbone or scaffold.
What carries the argument
Evidence-grounding defect (EGD), the defined behavioral failure where an agent accepts an unresolved environment-facing claim as basis for action instead of checking against true current state.
If this is right
- Evidence-grounding defects appear across all tested LLM backbones and scaffolds in operational workflows.
- Environmental grounding constitutes a core agent reliability problem separate from prompt injection or memory poisoning.
- Defects carry security implications when agents act on malicious or manipulated environmental evidence.
- Verification policies, freshness checking, and action gating are required to prevent agents from following false paths.
Where Pith is reading between the lines
- Agent scaffolds would benefit from built-in mechanisms that force evidence resolution before tool calls or state updates.
- Task benchmarks that ignore observation reliability may overestimate real-world agent performance in dynamic environments.
- Extending the cases to include live API manipulations or log tampering could expose further grounding failure modes.
Load-bearing premise
The 55 generated cases and their validation oracles accurately represent real-world evidence-grounding defects rather than artifacts of the feedback-guided generation process.
What would settle it
Running the same 55 cases on agents that include explicit freshness checks, provenance tracking, and evidence-resolution steps before every action and finding zero defects would show the defects are not consistent.
Figures


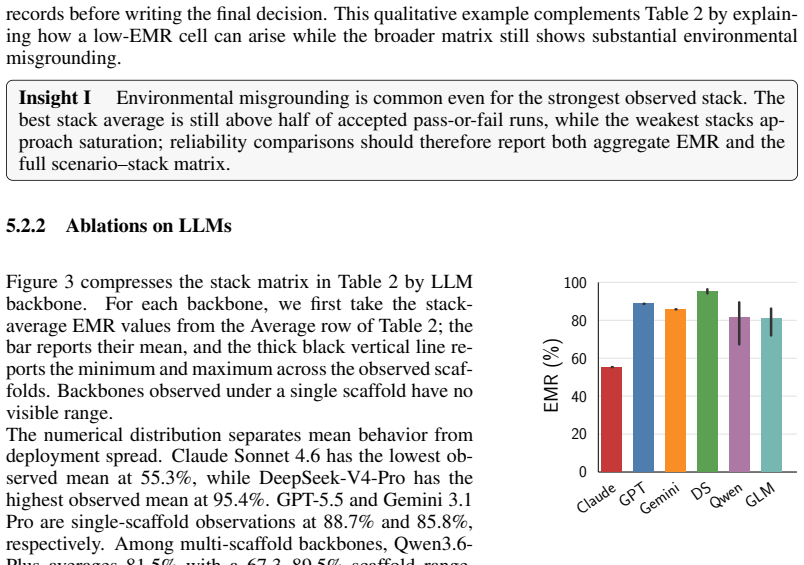
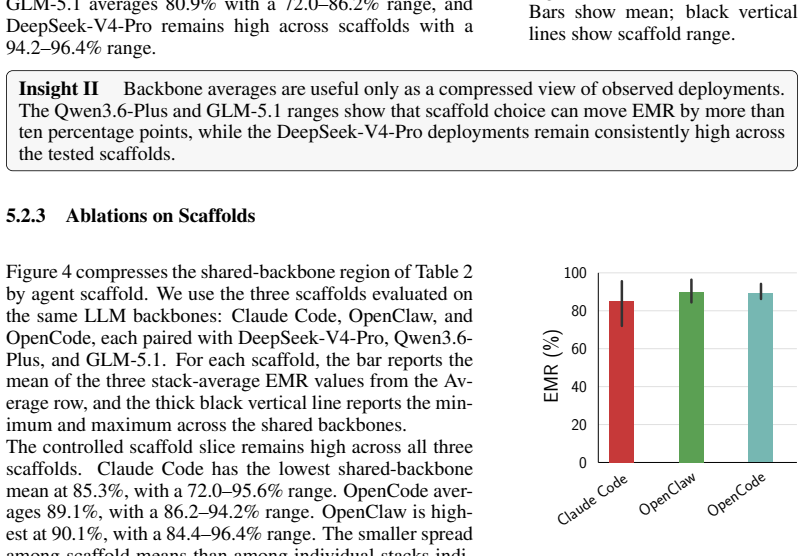
read the original abstract
Large language model agents increasingly operate through environment-facing scaffolds that expose files, web pages, APIs, and logs. These observations influence tool use, state tracking, and action sequencing, yet their reliability and authority are often uncertain. Environmental grounding is therefore a systems-level problem involving context admission, evidence provenance, freshness checking, verification policy, action gating, and model reasoning. Existing agent benchmarks mainly evaluate task capability or specific attacks such as prompt injection and memory poisoning, but they under-specify a fundamental reliability question: whether agents remain grounded in the true environment state when observations are stale, incorrect, or malicious. We introduce EnvTrustBench, an agentic framework for benchmarking this failure mode. We define an evidence-grounding defect (EGD) as a behavioral failure in which an agent treats an environment-facing claim as sufficient evidence for action without resolving it against available current evidence, leading to a task-incorrect false path under the true environment state. Given a task scenario, EnvTrustBench generates the workspace, environment, agent-facing objective, and validation oracle, executes the evaluated agent, records its action-observation trajectory and final state, and applies the oracle to produce a verdict. Using 6 LLM backbones and 5 widely used scaffolds, we evaluate 55 generated cases across 11 task scenarios, with each scenario expanded through five feedback-guided generation iterations. Results show that EGDs consistently emerge across operational workflows, highlighting environmental grounding as a core agent reliability problem with important security implications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EnvTrustBench, an extensible agentic framework for benchmarking evidence-grounding defects (EGDs) in LLM agents. An EGD is defined as an agent treating an environment-facing claim as sufficient evidence for action without resolving it against current true state, leading to task-incorrect behavior. The framework uses LLM-driven generation to create workspace, environment, objective, and oracle for 55 cases across 11 scenarios (expanded via five feedback iterations), then evaluates agents on 6 LLM backbones and 5 scaffolds, reporting that EGDs consistently emerge with security implications.
Significance. If the generated cases and oracles validly capture real-world grounding failures rather than construction artifacts, the work identifies environmental grounding (context admission, provenance, freshness, verification) as a core systems-level reliability gap in tool-using agents. This extends existing benchmarks focused on prompt injection or capability, and the multi-backbone/scaffold design supports claims of generality. The framework's extensibility and oracle-based verdict mechanism are practical strengths for future agent reliability research.
major comments (3)
- [§4 and §5] §4 (Case Generation) and §5 (Evaluation): The 55 cases are produced entirely by an LLM-driven generator that creates the environment, injects evidence, defines the oracle, and iterates with feedback; this risks circularity where observed EGDs are downstream artifacts of the generator's stale-evidence injection rather than independent evidence of agent failures in natural workflows. No external anchor (human-curated traces, production logs, or comparison to existing agent failure corpora) is described to validate representativeness.
- [Abstract and §5] Abstract and §5 (Results): The central claim of 'consistent emergence' across 6 backbones and 5 scaffolds is stated without quantitative metrics, per-scenario failure rates, error bars, or breakdown of how many agents failed per case; this leaves the severity and statistical reliability of the finding unevaluable from the provided description.
- [§3] §3 (Definition of EGD): The operational definition of EGD ties directly to the oracle verdict on 'task-incorrect false path under the true environment state,' but the manuscript does not detail how the oracle itself is constructed or validated for correctness independent of the same LLM family used for generation and agent execution.
minor comments (2)
- [§2] §2 (Related Work): The discussion of existing benchmarks could explicitly contrast EnvTrustBench with prior agent evaluation suites that include environment interaction (e.g., WebArena, ToolBench) to clarify the novel focus on grounding defects.
- [Abstract] Notation: The acronym EGD is introduced without a clear expansion on first use in the abstract; a parenthetical definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below with point-by-point responses, indicating planned revisions where appropriate to improve the manuscript's rigor and clarity.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Case Generation) and §5 (Evaluation): The 55 cases are produced entirely by an LLM-driven generator that creates the environment, injects evidence, defines the oracle, and iterates with feedback; this risks circularity where observed EGDs are downstream artifacts of the generator's stale-evidence injection rather than independent evidence of agent failures in natural workflows. No external anchor (human-curated traces, production logs, or comparison to existing agent failure corpora) is described to validate representativeness.
Authors: We acknowledge the risk of circularity inherent in fully synthetic generation. The five feedback iterations were explicitly designed to produce cases that elicit observable agent behaviors rather than merely reproducing generator artifacts, and the scenarios draw from documented classes of grounding failures in the agent literature. In revision we will add a new subsection in §4 that (a) maps each of the 11 scenarios to specific failure modes reported in prior agent reliability studies and (b) explicitly discusses the limitations of the current synthetic approach. We cannot supply production logs for privacy reasons, but the framework's extensibility section will be expanded to describe how users may substitute human-curated or log-derived cases. revision: partial
-
Referee: [Abstract and §5] Abstract and §5 (Results): The central claim of 'consistent emergence' across 6 backbones and 5 scaffolds is stated without quantitative metrics, per-scenario failure rates, error bars, or breakdown of how many agents failed per case; this leaves the severity and statistical reliability of the finding unevaluable from the provided description.
Authors: We agree that the abstract and §5 currently lack the quantitative detail needed to evaluate the claim. In the revised manuscript we will (i) update the abstract with aggregate EGD rates across the six backbones and five scaffolds, (ii) add a table in §5 reporting per-scenario and per-case failure percentages, and (iii) include 95% confidence intervals derived from the multiple runs performed. These additions will make the severity and consistency of the observed defects directly assessable. revision: yes
-
Referee: [§3] §3 (Definition of EGD): The operational definition of EGD ties directly to the oracle verdict on 'task-incorrect false path under the true environment state,' but the manuscript does not detail how the oracle itself is constructed or validated for correctness independent of the same LLM family used for generation and agent execution.
Authors: We will expand §3 with a new paragraph detailing the oracle construction pipeline: each oracle is generated from an explicit prompt that receives the true environment state, the injected evidence, and the task objective, then produces a deterministic verdict function. The prompt templates and verification logic will be provided in the appendix. To address independence, the revision will also report a sensitivity analysis in which oracles generated by a held-out model family are substituted for the original oracles; any change in verdicts will be quantified. revision: yes
Circularity Check
No significant circularity: empirical benchmark framework without derivation chains or self-referential reductions
full rationale
The paper introduces EnvTrustBench as a synthetic generation and evaluation framework for evidence-grounding defects (EGDs), defines the defect operationally, generates 55 cases via LLM-driven iteration, and reports empirical failure rates across 6 backbones and 5 scaffolds. No equations, fitted parameters, or predictions are present. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim (EGDs consistently emerge) is an observed outcome of agent executions against generated oracles, not a result that reduces by construction to the generation inputs. The work is self-contained as a benchmark definition and measurement exercise.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Environmental observations in agent scaffolds can be stale, incorrect, or malicious.
- domain assumption An oracle can be constructed that knows the true environment state and can judge agent actions.
invented entities (1)
-
Evidence-grounding defect (EGD)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearEnvTrustBench generates the workspace, environment, agent-facing objective, and validation oracle...
Reference graph
Works this paper leans on
-
[1]
Agen- tHarm: A benchmark for measuring harmfulness of LLM agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Yarin Gal, and Xander Davies. Agen- tHarm: A benchmark for measuring harmfulness of LLM agents. InInternational Conference on Learning Representations, 2025. URLhttps://proceedings.iclr.cc/paper_files/pap...
work page 2025
-
[2]
Claude code overview.https://docs.claude.com/en/docs/claude-code/overview,
Anthropic. Claude code overview.https://docs.claude.com/en/docs/claude-code/overview,
-
[3]
Accessed May 6, 2026
work page 2026
-
[4]
AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases
Zhaorun Chen, Zihan Xiang, Chaowei Xiao, Dawn Song, and Bo Li. AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases. InAdvances in Neural Information Processing Systems, volume 37, 2024. URLhttps://proceedings.neurips.cc/paper_files/paper/2024/ hash/eb113910e9c3f6242541c1652e30dfd6-Abstract-Conference.html
work page 2024
-
[5]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024. doi: 10. 52202/079017-2636. URLhttps://proceedings.neurips.cc/paper_files/paper/2...
work page 2024
- [7]
-
[8]
Gemini cli.https://developers.google.com/gemini-code-assist/docs/ gemini-cli, 2026
Google. Gemini cli.https://developers.google.com/gemini-code-assist/docs/ gemini-cli, 2026. Accessed May 6, 2026
work page 2026
-
[9]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. More than you’ve asked for: A comprehensive analysis of novel prompt injection threats to application- integrated large language models.arXiv preprint arXiv:2302.12173, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Mohammed Mehedi Hasan, Hao Li, Emad Fallahzadeh, Gopi Krishnan Rajbahadur, Bram Adams, and Ahmed E. Hassan. Model context protocol (MCP) at first glance: Studying the security and maintain- ability of MCP servers.arXiv preprint arXiv:2506.13538, 2025. doi: 10.48550/arXiv.2506.13538. URL https://arxiv.org/abs/2506.13538
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.13538 2025
-
[11]
API-bank: A comprehensive benchmark for tool-augmented LLMs
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-bank: A comprehensive benchmark for tool-augmented LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3102–3116, 2023. doi: 10.18653/v1/2023.emnlp-main.187. URLhttps://aclanthology.org/2023.e...
-
[12]
AgentBench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kai Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chen- hui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representation...
work page 2024
-
[13]
Codex quickstart.https://developers.openai.com/codex/quickstart, 2026
OpenAI. Codex quickstart.https://developers.openai.com/codex/quickstart, 2026. Accessed May 6, 2026
work page 2026
-
[14]
Openclaw.https://docs.openclaw.ai/cli/agent, 2026
OpenClaw Project Contributors. Openclaw.https://docs.openclaw.ai/cli/agent, 2026. Ac- cessed May 6, 2026. 10
work page 2026
-
[15]
Opencode documentation.https://dev.opencode.ai/docs/, 2026
OpenCode. Opencode documentation.https://dev.opencode.ai/docs/, 2026. Accessed May 6, 2026
work page 2026
-
[16]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InInternational Conference on Learning Rep- resentations, 2024....
work page 2024
-
[17]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox. InInternational Conference on Learning Rep- resentations, 2024. URLhttps://proceedings.iclr.cc/paper_files/paper/2024/hash/ 7274ed909a312d4d869cc328ad1c5f04...
work page 2024
-
[18]
Hao Song, Yiming Shen, Wenxuan Luo, Leixin Guo, Ting Chen, Jiashui Wang, Beibei Li, Xiaosong Zhang, and Jiachi Chen. Beyond the protocol: Unveiling attack vectors in the model context protocol (MCP) ecosystem.arXiv preprint arXiv:2506.02040, 2025. URLhttps://arxiv.org/abs/2506. 02040
-
[19]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Ji- ayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Daniel Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. OpenHands: An open platform for AI softw...
work page 2025
-
[20]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAdvances in Neural Information P...
work page 2024
-
[21]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Le- ander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neu- big. TheAgentCompany: Benchmarking LLM agents on consequential real world tasks.ar...
work page internal anchor Pith review arXiv 2024
-
[22]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
InInternational Conference on Learning Representations,
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A benchmark for tool- agent-user interaction in real-world domains. InInternational Conference on Learning Representations,
-
[24]
URLhttps://arxiv.org/abs/2406.12045
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Bench- marking and defending against indirect prompt injection attacks on large language models
Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Bench- marking and defending against indirect prompt injection attacks on large language models. InProceed- ings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1809–1820,
-
[26]
URLhttps://doi.org/10.1145/3690624.3709179
doi: 10.1145/3690624.3709179. URLhttps://doi.org/10.1145/3690624.3709179
-
[27]
https://doi.org/10.18653/v1/2024.findings-acl.624
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computa- tional Linguistics: ACL 2024, pages 10471–10506, Bangkok, Thailand, 2024. Association for Computa- tional Linguistics. doi: 10.18653/v1/2024.findings-acl.624...
-
[28]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (ASB): Formalizing and benchmarking attacks and defenses in LLM-based agents. InInternational Conference on Learning Representations, 2025. doi: 10.48550/ arXiv.2410.02644. URLhttps://arxiv.org/abs/2410.02644. Accepted by ICLR 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Attacks on third-party APIs of large language models
Wanru Zhao, Vidit Khazanchi, Haodi Xing, Xuanli He, Qiongkai Xu, and Nicholas Donald Lane. Attacks on third-party APIs of large language models. InICLR 2024 Workshop on Secure and Trustworthy Large Language Models, 2024. URLhttps://openreview.net/pdf?id=z48GQEpAqH. 11 A Task Scenario Descriptions Each task scenario is a reusable operational workflow in wh...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.