Recognition: no theorem link
Accelerating Multi-Condition T2I Generation via Adaptive Condition Offloading and Pruning
Pith reviewed 2026-05-12 01:16 UTC · model grok-4.3
The pith
An end-edge system accelerates multi-condition text-to-image generation by offloading subtasks and pruning low-impact conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
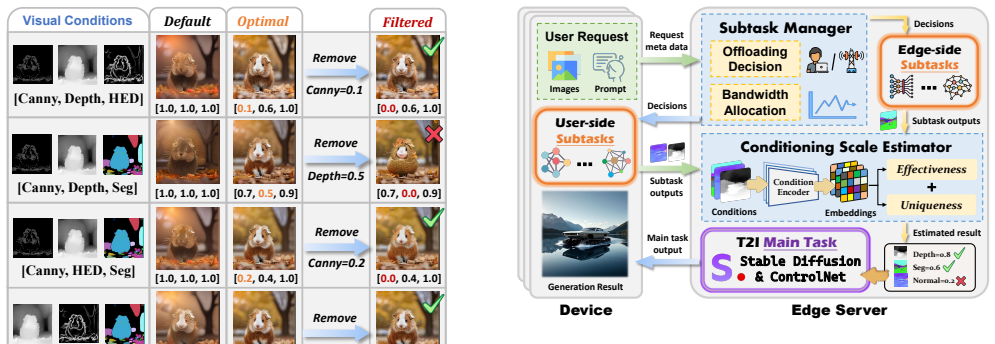
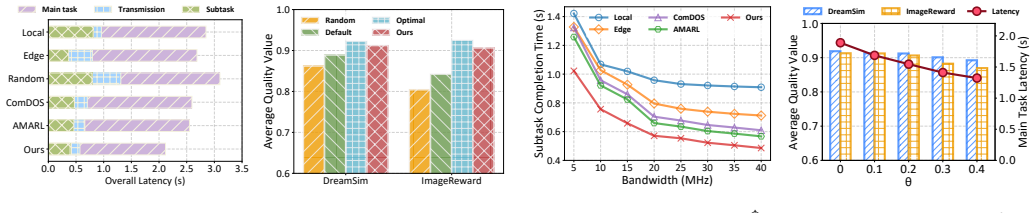
The central claim is that multi-condition T2I generation latency can be reduced by nearly 25 percent with a 6 percent average quality gain by combining a Subtask Manager that heuristically optimizes condition offloading and bandwidth allocation to balance local and edge delays, with a Conditioning Scale Estimator that prunes insignificant conditions after evaluating their feature activation strength and overlap with other inputs.
What carries the argument
The Subtask Manager for joint offloading and bandwidth decisions, and the Conditioning Scale Estimator that measures feature activation strength and overlap to enable adaptive scale selection and pruning.
If this is right
- Preprocessing subtasks finish faster when offloading decisions and bandwidth allocation are jointly optimized by the heuristic.
- The denoising phase completes more quickly once low-contribution conditions are pruned based on feature analysis.
- Overall generation latency drops by nearly 25 percent while average output quality rises by 6 percent relative to benchmarks.
- The combined offloading-plus-pruning approach outperforms alternative acceleration methods tested in the experiments.
Where Pith is reading between the lines
- The same cost-profiling and feature-based pruning logic could transfer to other generative models that accept multiple input modalities.
- Real-time apps could use the estimator to adjust active conditions on the fly as network conditions or user prompts change.
- Device makers might embed similar offline profiles to tailor the system for their specific hardware and typical workloads.
Load-bearing premise
Offline profiling of condition costs together with the lightweight estimator will correctly identify insignificant conditions for any new model, prompt, or network condition without introducing extra errors or overhead.
What would settle it
Run the full system on an unseen diffusion model with novel condition combinations under varied network bandwidths, then measure whether the observed latency reduction stays near 25 percent and whether quality gains persist or degrade from incorrect pruning decisions.
Figures



read the original abstract
Text-to-image (T2I) generation using multiple conditions enables fine-grained user control on the generated image. Yet, incorporating multi-condition inputs incurs substantial computation and communication overhead, due to additional preprocessing subtasks and control optimizations. It hence leads to unacceptable generation latency. In this paper, we propose an end-edge collaborative system design to accelerate multi-condition T2I generation through adaptive condition offloading and pruning. Extensive offline profiling reveal that, different conditions exhibit significant diversity in computation and communication costs. To this end, we propose a \textit{Subtask Manager} that jointly optimizes condition inference offloading and bandwidth allocation using a heuristic algorithm, balancing local and edge execution delays to minimize overall preprocessing latency. Then, we design a lightweight feature-driven \textit{Conditioning Scale Estimator} that evaluates the contribution of each condition by analyzing its feature activation strength and overlap with other conditions. This allows adaptive conditioning scale selection and pruning of insignificant conditions, thereby accelerating the denoising process. Extensive experimental results show that our system reduces latency by nearly 25\% and improves 6\% average generation quality, outperforming other benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an end-edge collaborative system for multi-condition text-to-image (T2I) generation. It introduces a Subtask Manager that uses a heuristic algorithm to jointly optimize condition inference offloading and bandwidth allocation, and a lightweight Conditioning Scale Estimator that prunes insignificant conditions by analyzing feature activation strength and pairwise overlap. The central claims are that the system reduces preprocessing and denoising latency by nearly 25% while improving average generation quality by 6%, outperforming other benchmarks.
Significance. If the reported gains are reproducible and generalizable, the work addresses a practical bottleneck in deploying controllable T2I models under edge-cloud constraints. The combination of adaptive offloading and condition pruning is a relevant direction for multimedia systems. However, the absence of detailed validation for the core assumptions limits the current assessment of impact.
major comments (2)
- [Abstract] Abstract: the claims of 'nearly 25% latency reduction' and '6% average generation quality' improvement are presented without any description of the experimental setup, baselines, number of trials, statistical tests, or human validation of pruning decisions. This directly affects the ability to assess whether the gains are load-bearing or reproducible.
- [Conditioning Scale Estimator] Conditioning Scale Estimator and offline profiling sections: the central assumption that offline condition-cost profiles and the feature-driven estimator (thresholding on activation strength and overlap) generalize to unseen models, prompts, and network conditions is untested. No precision/recall metrics for the estimator, ablation on pruning thresholds, or cross-model transfer results are reported, leaving the 25% latency and 6% quality claims dependent on an unverified extrapolation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our experimental claims and the validation of the Conditioning Scale Estimator. We address each major comment below and indicate where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of 'nearly 25% latency reduction' and '6% average generation quality' improvement are presented without any description of the experimental setup, baselines, number of trials, statistical tests, or human validation of pruning decisions. This directly affects the ability to assess whether the gains are load-bearing or reproducible.
Authors: We agree that the abstract would benefit from additional context on the evaluation. In the revised manuscript we will expand the abstract to briefly note the experimental setup (standard T2I benchmarks, multiple baselines, and repeated trials) while retaining the quantitative claims. Full details on statistical tests, human validation of pruning decisions, and reproducibility information remain in Section 5; we will add an explicit cross-reference from the abstract to that section. revision: yes
-
Referee: [Conditioning Scale Estimator] Conditioning Scale Estimator and offline profiling sections: the central assumption that offline condition-cost profiles and the feature-driven estimator (thresholding on activation strength and overlap) generalize to unseen models, prompts, and network conditions is untested. No precision/recall metrics for the estimator, ablation on pruning thresholds, or cross-model transfer results are reported, leaving the 25% latency and 6% quality claims dependent on an unverified extrapolation.
Authors: The referee is correct that we do not report precision/recall metrics or cross-model transfer results; the Conditioning Scale Estimator is a lightweight heuristic based on feature activation and overlap rather than a trained classifier, so those metrics are not applicable. Our experiments (Sections 4 and 5) already cover a range of prompts, condition combinations, and network conditions within the evaluated model family and demonstrate consistent latency and quality gains. We will add an ablation study on pruning thresholds in the revision to quantify sensitivity. Comprehensive cross-model generalization testing lies outside the current scope and is noted as future work; the reported improvements are grounded in the offline profiling and in-distribution experiments described in the manuscript. revision: partial
Circularity Check
No circularity: empirical system with heuristic offloading and feature-based estimator, claims rest on experiments not self-referential derivations.
full rationale
The paper describes an end-edge system using offline profiling to observe condition cost diversity, a heuristic algorithm in the Subtask Manager for joint offloading and bandwidth allocation, and a lightweight Conditioning Scale Estimator based on feature activation strength and pairwise overlap for pruning. No equations, first-principles derivations, or predictions are presented that reduce to fitted inputs or self-definitions by construction. Performance numbers (25% latency, 6% quality) are reported from experiments rather than tautological outputs of the same profiling data. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The design is heuristic and empirical, with the central claims externally falsifiable via held-out runs; this is a standard non-circular engineering paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- heuristic parameters in Subtask Manager
- activation strength thresholds in Conditioning Scale Estimator
axioms (1)
- domain assumption Different conditions exhibit significant diversity in computation and communication costs
invented entities (2)
-
Subtask Manager
no independent evidence
-
Conditioning Scale Estimator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Diffusion models in vision: A survey,
F.-A. Croitoru, V . Hondru, R. T. Ionescu, and M. Shah, “Diffusion models in vision: A survey,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 9, pp. 10 850–10 869, 2023
work page 2023
-
[2]
Dreambooth: Fine tuning text-to- image diffusion models for subject-driven generation,
N. Ruiz, Y . Li, V . Jampaniet al., “Dreambooth: Fine tuning text-to- image diffusion models for subject-driven generation,” inProc. of IEEE CVPR, 2023, pp. 22 500–22 510
work page 2023
-
[3]
Cocktail: Mixing multi-modality control for text-conditional image generation,
M. Hu, J. Zheng, D. Liuet al., “Cocktail: Mixing multi-modality control for text-conditional image generation,” inin Proc. of NeurIPS, vol. 36, 2023, pp. 32 424–32 444
work page 2023
-
[4]
Scheduling generative-ai job dags with model serving in data centers,
Y . Zheng, L. Jiao, Y . Xuet al., “Scheduling generative-ai job dags with model serving in data centers,” inProc. of IEEE IWQoS, 2024, pp. 1–6
work page 2024
-
[5]
Characterizing and scheduling of diffusion process for text-to-image generation in edge networks,
S. Gao, P. Yang, Y . Konget al., “Characterizing and scheduling of diffusion process for text-to-image generation in edge networks,”IEEE Trans. Mobile Comput., vol. 24, no. 10, pp. 11 137–11 150, 2025
work page 2025
-
[6]
Enabling haptic-integrated interactive holographic video streaming powered by 5g edge computing,
P. Qian, N. Wang, C. Udoraet al., “Enabling haptic-integrated interactive holographic video streaming powered by 5g edge computing,” inProc. of IEEE ICME, 2025, pp. 1–6
work page 2025
-
[7]
Distributed and controllable mobile text-to-image generation with user preference guarantee,
Y . Kong, P. Yang, X. Qinet al., “Distributed and controllable mobile text-to-image generation with user preference guarantee,”IEEE Trans. Mobile Comput., vol. 25, no. 3, pp. 3712–3727, 2026
work page 2026
-
[8]
Adding conditional control to text- to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text- to-image diffusion models,” inProc. of IEEE ICCV, 2023, pp. 3836– 3847
work page 2023
-
[9]
Ominicontrol: Minimal and universal control for diffusion transformer,
Z. Tan, S. Liu, X. Yang, Q. Xue, and X. Wang, “Ominicontrol: Minimal and universal control for diffusion transformer,” inProc. of IEEE ICCV, 2025, pp. 14 940–14 950
work page 2025
-
[10]
Networked edge resource orchestration for mobile ai-generated content services,
Y . Liang, P. Yanget al., “Networked edge resource orchestration for mobile ai-generated content services,”IEEE Trans. Cognit. Commun. Networking, vol. 12, pp. 5063–5076, 2026
work page 2026
-
[11]
Imagereward: Learning and evaluating human preferences for text-to-image generation,
J. Xu, X. Liu, Y . Wuet al., “Imagereward: Learning and evaluating human preferences for text-to-image generation,” inProc. of NeurIPS, vol. 36, 2023, pp. 15 903–15 935
work page 2023
-
[12]
Dreamsim: Learning new di- mensions of human visual similarity using synthetic data,
S. Fu, N. Tamir, S. Sundaramet al., “Dreamsim: Learning new di- mensions of human visual similarity using synthetic data,” inProc. of NeurIPS, vol. 36, 2023, pp. 50 742–50 768
work page 2023
-
[13]
Resource allocation for multiuser edge inference with batching and early exiting,
Z. Liu, Q. Lan, and K. Huang, “Resource allocation for multiuser edge inference with batching and early exiting,”IEEE J. Sel. Areas Commun., vol. 41, no. 4, pp. 1186–1200, 2023
work page 2023
-
[14]
Adaptive on-device model update for responsive video analytics in adverse environments,
Y . Kong, P. Yang, and Y . Cheng, “Adaptive on-device model update for responsive video analytics in adverse environments,”IEEE Trans. Circuits Syst. Video Technol., vol. 35, no. 1, pp. 857–873, 2025
work page 2025
-
[15]
Multi-agent rl-based industrial aigc service offloading over wireless edge networks,
S. Li, X. Lin, H. Xu, K. Hua, X. Jin, G. Li, and J. Li, “Multi-agent rl-based industrial aigc service offloading over wireless edge networks,” inProc. of IEEE INFOCOM WKSHPS, 2024, pp. 1–6
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.