Recognition: no theorem link
Illusion-Aware Visual Preprocessing and Anti-Illusion Prompting for Classic Illusion Understanding in Vision-Language Models
Pith reviewed 2026-05-12 01:35 UTC · model grok-4.3
The pith
A training-free preprocessing and prompting strategy enables vision-language models to correctly perceive visual illusions rather than defaulting to memorized knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
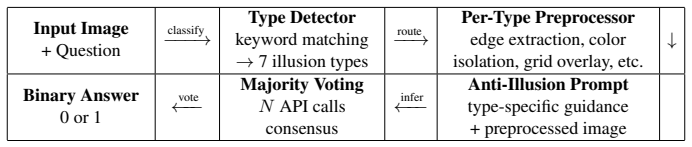
Our method applies type-specific image transformations such as edge extraction, color isolation, morphological processing, and reference-line overlay to weaken illusion-inducing context, combined with anti-illusion prompts and majority voting, to resolve the perception-versus-memory conflict in VLMs and achieve high accuracy on illusion understanding tasks.
What carries the argument
Illusion-aware visual preprocessing using type-specific transformations to weaken illusion context while preserving task-relevant information, paired with anti-illusion prompting that directs the model to qualitative visual comparison.
If this is right
- The framework improves VLM performance on illusion tasks to over 90% without requiring model fine-tuning.
- It demonstrates that visual manipulation and prompt design can mitigate reliance on memorized facts.
- The approach generalizes across different VLMs as shown by results with Claude.
- Ensemble voting further enhances robustness to individual model errors.
Where Pith is reading between the lines
- Similar techniques could address other cases where VLMs hallucinate or ignore visual input in favor of language priors.
- The success suggests that illusion understanding is more about input preparation than inherent model limitations.
- Extending this to dynamic video or real-world scenes might reveal how well the transformations hold up outside the challenge dataset.
- It opens the possibility of developing general visual debiasing methods for other perceptual biases.
Load-bearing premise
The selected type-specific transformations weaken illusion-inducing elements without removing or altering information essential for determining the correct answer on the test images.
What would settle it
A new set of illusion images where the preprocessing transformations either fail to reduce the illusion effect or cause the model to misinterpret non-illusion aspects, leading to accuracy below random guessing or significantly lower than baseline.
Figures



read the original abstract
Vision-Language Models (VLMs) exhibit systematic bias toward visual illusions, recalling memorized facts rather than perceiving actual visual differences. This paper presents a training-free framework for the 5th DataCV Challenge Task 1 at CVPR 2026, addressing this perception-versus-memory conflict through three complementary strategies:(1) illusion-aware image preprocessing that weakens illusion-inducing context via type-specific transformations (edge extraction, color isolation, morphological processing, and reference-line overlay), (2) anti-illusion prompt engineering guiding VLMs toward qualitative visual comparison, and (3) multi-vote ensemble that further improves robustness. Our method achieves 90.48% accuracy on the official 630-image test set using Claude (claude-opus-4-6) with 5-vote majority ensemble, and 98.41% on a human-verified subset. The approach requires no finetuning, relying solely on visual manipulation and prompt design. Our solution secured 2nd place in the challenge, only 0.47% behind the 1st-place solution. Code is available at https://github.com/jasminezz/sf-illusion-aware-vlm.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a training-free framework for the 5th DataCV Challenge Task 1, combining illusion-aware image preprocessing via type-specific transformations (edge extraction, color isolation, morphological processing, reference-line overlay), anti-illusion prompt engineering, and a 5-vote majority ensemble with Claude to improve VLM performance on visual illusions. It reports 90.48% accuracy on the official 630-image held-out test set and 98.41% on a human-verified subset, securing 2nd place without any fine-tuning.
Significance. If the transformations are shown to preserve task-critical cues, the work provides a practical, reproducible zero-shot approach to mitigating VLM reliance on memorized facts over visual perception in illusion tasks. The public code release and strong results on an external challenge test set add immediate utility for robust visual reasoning.
major comments (2)
- [illusion-aware image preprocessing] The central performance claim (90.48% accuracy) rests on the unverified assumption that the type-specific preprocessing transformations weaken only illusion-inducing context while retaining every cue needed for correct answers across all illusion categories in the 630-image distribution. No ablation studies, per-type error analysis, or quantitative preservation checks (e.g., VLM accuracy with vs. without each transformation) are described.
- [Methods and experimental setup] No details are provided on the process for selecting or tuning the transformation parameters, nor any sensitivity analysis, which is required to substantiate that the reported accuracy is attributable to the claimed mechanism rather than ad-hoc choices.
minor comments (2)
- [Abstract] Clarify the exact Claude model version referenced as 'claude-opus-4-6' and ensure consistency with standard naming conventions.
- [Results] Consider adding a table or figure showing component-wise contributions (preprocessing, prompting, ensemble) to the final accuracy for improved clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional evidence and methodological detail would strengthen the manuscript. We address each major comment below and will incorporate revisions to improve the rigor of the presentation.
read point-by-point responses
-
Referee: [illusion-aware image preprocessing] The central performance claim (90.48% accuracy) rests on the unverified assumption that the type-specific preprocessing transformations weaken only illusion-inducing context while retaining every cue needed for correct answers across all illusion categories in the 630-image distribution. No ablation studies, per-type error analysis, or quantitative preservation checks (e.g., VLM accuracy with vs. without each transformation) are described.
Authors: We agree that the current manuscript lacks ablation studies, per-type error analysis, and quantitative checks demonstrating that the transformations preserve task-critical cues while disrupting illusion-inducing context. Although the transformations were selected based on established perceptual mechanisms for each illusion category, the absence of these empirical validations is a genuine limitation. In the revised manuscript we will add (i) ablation results comparing accuracy with and without each individual transformation, (ii) per-illusion-category error breakdowns on the 630-image test set, and (iii) qualitative examples showing retained visual information for representative images from each category. These additions will directly address the concern and substantiate the central performance claim. revision: yes
-
Referee: [Methods and experimental setup] No details are provided on the process for selecting or tuning the transformation parameters, nor any sensitivity analysis, which is required to substantiate that the reported accuracy is attributable to the claimed mechanism rather than ad-hoc choices.
Authors: We acknowledge that the manuscript does not describe the parameter selection process or include sensitivity analysis. The parameters were chosen through visual inspection to target illusion-specific features while preserving recognizability, informed by the illusion taxonomy in the challenge data. To resolve this, the revision will include a new subsection detailing the exact parameter values for each transformation, the rationale and iterative selection procedure, and a sensitivity study showing how small perturbations in key parameters affect overall accuracy on the test set. This will clarify that the reported results stem from the intended mechanisms rather than arbitrary choices. revision: yes
Circularity Check
No circularity: empirical method evaluated on external held-out test set
full rationale
The paper describes a training-free pipeline of type-specific preprocessing transformations, prompt engineering, and majority-vote ensembling, with accuracy reported on the official 630-image challenge test set that was not used for any fitting or tuning. No equations, parameter estimation steps, self-citations, or uniqueness theorems appear in the provided text; the performance numbers are direct empirical measurements rather than quantities derived from the same inputs by construction. This matches the expected non-finding for a purely empirical challenge submission whose central claims do not reduce to self-definition or fitted-input renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs exhibit systematic bias toward visual illusions by recalling memorized facts rather than perceiving actual visual differences
Reference graph
Works this paper leans on
-
[1]
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Has- son, K. Lenc, A. Mensch, K. Millican, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Saman- gooei, M. Monteiro, J. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Binkowski, R. Barreira, O. Vinyals, A. Zisserman, and K. Simonyan. Flamingo: A vi- sual languag...
work page 2022
-
[2]
The Claude model family: Opus, Sonnet, Haiku
Anthropic. The Claude model family: Opus, Sonnet, Haiku. Technical report, Anthropic, 2025. 2, 3, 6
work page 2025
-
[3]
Y . Chen, R. K. Sikka, A. Cober, S. Ji, and S. Divvala. Mea- suring and improving chain-of-thought reasoning in vision- language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Compu- tational Linguistics (NAACL), 2024. 2
work page 2024
-
[4]
T. N. Cornsweet.Visual Perception. Academic Press, New York, 1970. 4
work page 1970
-
[5]
The 5th DataCV challenge task 1: Classic illusion understanding
DataCV Workshop Organizers. The 5th DataCV challenge task 1: Classic illusion understanding. InCVPR 2026 Work- shop, 2026.https://sites.google.com/view/ datacv-2026-cvpr/challenge. 1, 8
work page 2026
-
[6]
Gemini 3.1 pro: A smarter model for your most complex tasks.https : / / blog
Google. Gemini 3.1 pro: A smarter model for your most complex tasks.https : / / blog . google / innovation - and - ai / models - and - research / gemini-models/gemini-3-1-pro/, 2026. 3
work page 2026
-
[7]
R. L. Gregory. Knowledge in perception and illusion.Philo- sophical Transactions of the Royal Society of London. Series B: Biological Sciences, 352(1358):1121–1127, 1997. 1, 2
work page 1997
-
[8]
T. Guan, F. Liu, X. Wu, R. Xian, Z. Li, X. Liu, X. Wang, L. Chen, F. Huang, Y . Yacoob, D. Manocha, and T. Zhou. HallusionBench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision- language models. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
- [9]
-
[10]
Wenjin Hou, Wei Liu, Han Hu, Xiaoxiao Sun, Serena Yeung- Levy, and Hehe Fan. Seeing is believing? a benchmark for multimodal large language models on visual illusions and anomalies, 2026. 2
work page 2026
-
[11]
G. Kanizsa. Subjective contours.Scientific American, 234 (4):48–52, 1976. 3
work page 1976
-
[12]
S. Leng, H. Zhang, G. Chen, X. Li, S. Lu, C. Miao, and L. Bing. Mitigating object hallucinations in large vision- language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2024. 2, 7
work page 2024
-
[13]
H. Liu, W. Xue, Y . Chen, D. Chen, X. Zhao, K. Wang, L. Hou, R. Li, and W. Peng. A survey on hallucination in large vision-language models.arXiv preprint arXiv:2402.00253,
work page internal anchor Pith review arXiv
-
[14]
Chan, Shir Goldfinger, Emily Mackay, Brian Anthony, and Alison Pouch
Aparna Nair-Kanneganti, Trevor J. Chan, Shir Goldfinger, Emily Mackay, Brian Anthony, and Alison Pouch. Increas- ing LLM response trustworthiness using voting ensembles. arXiv preprint, arXiv:2510.04048, 2025. 5
-
[15]
Qwen Team. Qwen3-vl technical report: Advanced vi- sual reasoning and agent capabilities.arXiv preprint arXiv:2511.21631, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
S. Rostamkhani, M. Ansari, A. Sahzevari, S. Rahmani, and S. Eetemadi. Illusory VQA: Benchmarking and enhancing multimodal models on visual illusions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2025. 2
work page 2025
- [17]
- [18]
-
[19]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. InICLR,
-
[20]
M. Zhang, S. Yin, L. Li, J. Zhang, Z. He, and G. Wan. Il- lusionBench+: A large-scale and comprehensive benchmark for visual illusion understanding in vision-language models. arXiv preprint arXiv:2501.00848, 2025. 2, 8
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.