Recognition: no theorem link
XPERT: Expert Knowledge Transfer for Effective Training of Language Models
Pith reviewed 2026-05-12 02:37 UTC · model grok-4.3
The pith
Reusing cross-domain expert knowledge from MoE LLMs improves training outcomes for language models of different scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
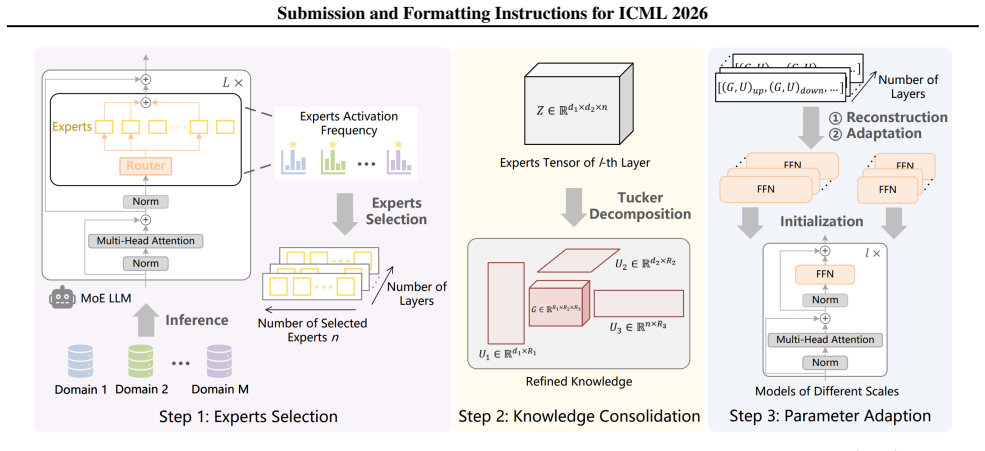
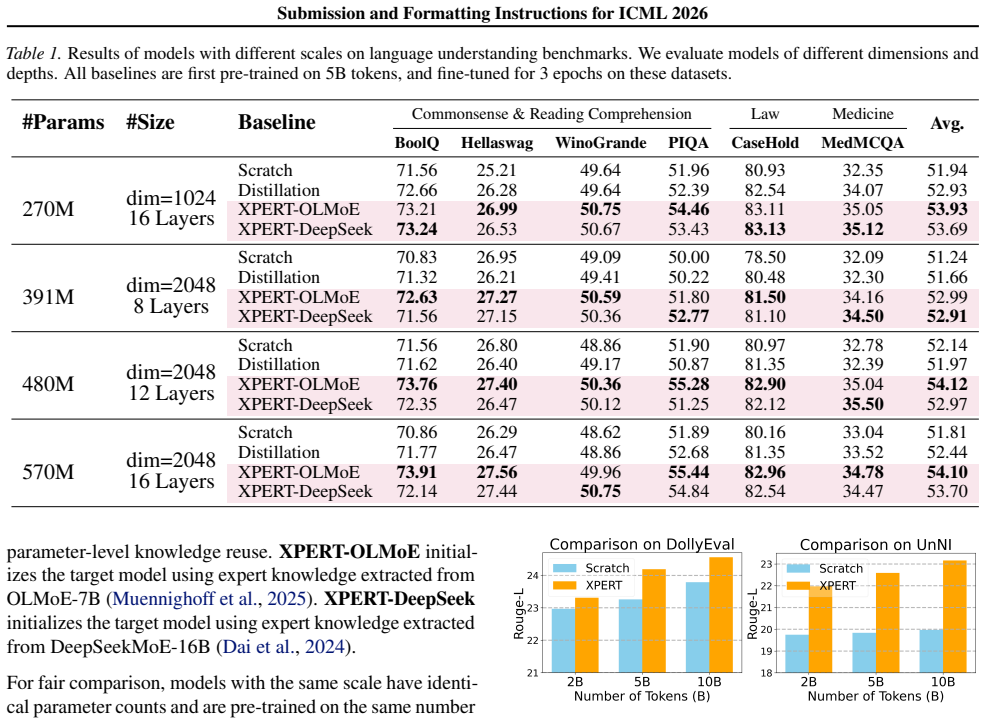
XPERT identifies a subset of consistently activated experts in pre-trained MoE LLMs that encode cross-domain generalizable knowledge. It refines their representations through tensor decomposition and adapts the extracted knowledge for reuse in the training of language models across scales. This results in models that achieve stronger performance and faster convergence on language understanding and dialogue generation benchmarks compared to strong baselines.
What carries the argument
XPERT, the framework that extracts cross-domain experts from MoE LLMs via inference-only analysis, refines them using tensor decomposition, and adapts them for reuse in downstream model training.
If this is right
- Reused expert knowledge leads to consistently stronger performance on language understanding benchmarks.
- Models trained with XPERT converge faster than those using standard methods.
- The benefits apply to language models at various scales.
- MoE LLMs function as structured and reusable knowledge sources.
Where Pith is reading between the lines
- This method could enable more efficient knowledge transfer from large MoE models to smaller ones without full retraining.
- Similar inference-based analysis might uncover reusable components in other types of modular models.
- Refining expert knowledge this way may offer a path to reduce computational costs in developing new language models.
Load-bearing premise
The subset of experts identified as consistently activated truly captures cross-domain generalizable knowledge that can be refined by tensor decomposition and transferred to improve training without introducing biases or losing important details.
What would settle it
If language models trained using the expert knowledge extracted by XPERT do not show improved performance or faster convergence on language understanding and dialogue generation benchmarks relative to baselines, the central claim would be falsified.
Figures





read the original abstract
Mixture-of-Experts (MoE) language models organize knowledge into explicitly routed expert modules, making expert-level representations traceable and analyzable. By analyzing expert activation patterns in MoE large language models (LLMs), we find that a subset of experts is consistently activated across diverse knowledge domains. These common experts encode cross-domain, generalizable knowledge that is closely related to model generalization, naturally raising the question of how such identifiable expert knowledge can be practically reused. Motivated by this observation, we propose XPERT, a framework that extracts, consolidates, and reuses expert knowledge from pre-trained MoE LLMs to support more effective training of language models across different model scales. XPERT identifies cross-domain experts via inference-only analysis, refines their representations through tensor decomposition, and adapts the extracted knowledge to reuse in downstream models. Experiments on language understanding and dialogue generation benchmarks show that models benefiting from reused expert knowledge achieve consistently stronger performance and faster convergence compared to strong baselines. These results highlight MoE LLMs as structured and reusable knowledge sources, and demonstrate the value of expert-level knowledge reuse for improving model training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes XPERT, a framework that extracts a subset of consistently activated experts from pre-trained MoE LLMs via inference-only analysis across diverse domains, refines their representations through tensor decomposition, and adapts the resulting factors for reuse during training of language models at different scales. Experiments on language understanding and dialogue generation benchmarks are reported to show consistent performance gains and faster convergence relative to strong baselines.
Significance. If the results are robust, the work is significant for demonstrating that MoE architectures can function as structured, reusable knowledge sources rather than black-box models. The inference-only identification of cross-domain experts combined with tensor decomposition offers a concrete, scalable approach to knowledge consolidation that could improve training efficiency. Credit is given for the empirical demonstration of gains across multiple benchmarks and for focusing on practical transfer rather than purely theoretical analysis.
major comments (2)
- [§3 (XPERT Framework)] The central premise that high activation frequency identifies causally generalizable cross-domain knowledge (rather than routing artifacts, initialization effects, or co-activation patterns) is load-bearing for the transfer claim, yet the manuscript provides no causal interventions, ablations against random or low-frequency expert subsets, or controls that isolate the contribution of the selected experts from the added parameters and adaptation schedule. This directly affects whether the reported gains can be attributed to the extracted knowledge.
- [§4 (Experiments)] §4 (Experiments): the abstract and results claim 'consistently stronger performance and faster convergence' but the description does not specify the exact baselines, number of random seeds, statistical tests, or ablations on the tensor decomposition step (e.g., full experts vs. decomposed factors). Without these, it is impossible to verify that the improvements exceed what would be obtained by simply increasing model capacity or altering the training schedule.
minor comments (2)
- [Abstract] The abstract states that the common experts 'encode cross-domain, generalizable knowledge' but does not define the precise activation threshold or consistency metric used to select them; this notation should be formalized in §3 with an equation.
- [§4 (Experiments)] Figure captions and tables in the experimental section would benefit from explicit reporting of standard deviations or confidence intervals alongside mean performance numbers to support the 'consistent' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to improve the manuscript. We address the two major comments point by point below, agreeing where revisions are needed to strengthen the claims and experimental rigor.
read point-by-point responses
-
Referee: [§3 (XPERT Framework)] The central premise that high activation frequency identifies causally generalizable cross-domain knowledge (rather than routing artifacts, initialization effects, or co-activation patterns) is load-bearing for the transfer claim, yet the manuscript provides no causal interventions, ablations against random or low-frequency expert subsets, or controls that isolate the contribution of the selected experts from the added parameters and adaptation schedule. This directly affects whether the reported gains can be attributed to the extracted knowledge.
Authors: We agree that the manuscript would benefit from stronger evidence isolating the role of high-frequency experts. Our selection is grounded in the empirical observation that these experts show consistent activation across diverse domains in the source MoE model, which we link to generalization. To directly address the concern, the revised manuscript will include new ablations comparing the selected experts against (i) randomly chosen expert subsets and (ii) low-frequency experts, while matching parameter count and training schedule. These controls will help demonstrate that gains are attributable to the cross-domain knowledge rather than capacity or schedule effects alone. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): the abstract and results claim 'consistently stronger performance and faster convergence' but the description does not specify the exact baselines, number of random seeds, statistical tests, or ablations on the tensor decomposition step (e.g., full experts vs. decomposed factors). Without these, it is impossible to verify that the improvements exceed what would be obtained by simply increasing model capacity or altering the training schedule.
Authors: We acknowledge that the experimental details require greater precision. In the revision we will: (1) explicitly list all baselines (standard fine-tuning, random expert initialization, and capacity-matched models without knowledge transfer); (2) report results over multiple random seeds with standard deviations; (3) include statistical significance tests (e.g., paired t-tests); and (4) add an ablation directly comparing reuse of full expert weights versus the tensor-decomposed factors. These changes will confirm that observed gains exceed those from capacity increases or schedule variations. revision: yes
Circularity Check
No circularity: empirical selection and transfer validated externally
full rationale
The paper identifies consistently activated experts via inference-only analysis on diverse domains, applies tensor decomposition to refine representations, and transfers the factors into target models. Performance gains are measured on separate language understanding and dialogue benchmarks against strong baselines. No equations or steps reduce the claimed improvement to a parameter fitted on the same data used for evaluation. The selection criterion (activation frequency) is an observable input, not defined in terms of the downstream gains. Self-citations, if present, are not load-bearing for the core transfer mechanism, which remains falsifiable by the reported experiments. This is a standard empirical pipeline with no self-definitional or fitted-input circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A subset of experts is consistently activated across diverse knowledge domains and encodes cross-domain generalizable knowledge related to model generalization.
Reference graph
Works this paper leans on
-
[1]
Radiology: Artificial Intelligence , volume=
On the opportunities and risks of foundation models for natural language processing in radiology , author=. Radiology: Artificial Intelligence , volume=. 2022 , publisher=
work page 2022
-
[2]
Journal of Machine Learning Research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , volume=
-
[3]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Palm 2 technical report , author=. arXiv preprint arXiv:2305.10403 , year=
work page internal anchor Pith review arXiv
-
[5]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Language Models are Few-Shot Learners
Language models are few-shot learners , author=. arXiv preprint arXiv:2005.14165 , volume=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[8]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
International Conference on Learning Representations , year=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. International Conference on Learning Representations , year=
-
[10]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
LLM-QAT: Data-free quantization aware training for large language models.arXiv:2305.17888, 2023
Llm-qat: Data-free quantization aware training for large language models , author=. arXiv preprint arXiv:2305.17888 , year=
-
[12]
B it D istiller: Unleashing the Potential of Sub-4-Bit LLM s via Self-Distillation
Du, DaYou and Zhang, Yijia and Cao, Shijie and Guo, Jiaqi and Cao, Ting and Chu, Xiaowen and Xu, Ningyi. B it D istiller: Unleashing the Potential of Sub-4-Bit LLM s via Self-Distillation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.7
-
[13]
A Survey on Model Compression for Large Language Models
Zhu, Xunyu and Li, Jian and Liu, Yong and Ma, Can and Wang, Weiping. A Survey on Model Compression for Large Language Models. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00704
-
[14]
MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture , pages=
Edgebert: Sentence-level energy optimizations for latency-aware multi-task nlp inference , author=. MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture , pages=
-
[15]
arXiv preprint arXiv:2002.09168 , year=
Residual knowledge distillation , author=. arXiv preprint arXiv:2002.09168 , year=
-
[16]
IEEE transactions on pattern analysis and machine intelligence , volume=
Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
work page 2021
-
[17]
Proceedings of the 29th International Conference on Computational Linguistics , pages=
Combining Compressions for Multiplicative Size Scaling on Natural Language Tasks , author=. Proceedings of the 29th International Conference on Computational Linguistics , pages=
- [18]
-
[19]
Advances in Neural Information Processing Systems , volume=
Wings: Learning multimodal llms without text-only forgetting , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Efficient Evaluation of Large Language Models via Collaborative Filtering , author=. 2025 , eprint=
work page 2025
-
[21]
Advances in Neural Information Processing Systems , volume=
Bridge the modality and capability gaps in vision-language model selection , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Learnware: small models do big , volume=
Zhou, Zhi-Hua and Tan, Zhi-Hao , year=. Learnware: small models do big , volume=. Science China Information Sciences , publisher=. doi:10.1007/s11432-023-3823-6 , number=
-
[23]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
OneBit: Towards Extremely Low-bit Large Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[24]
Gunho Park and Baeseong Park and Minsub Kim and Sungjae Lee and Jeonghoon Kim and Beomseok Kwon and Se Jung Kwon and Byeongwook Kim and Youngjoo Lee and Dongsoo Lee , title=. 2024 , cdate=
work page 2024
-
[25]
int8 (): 8-bit matrix multiplication for transformers at scale , author=
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale , author=. Advances in neural information processing systems , volume=
-
[26]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers , author=. 2023 , eprint=
work page 2023
-
[27]
Proceedings of Machine Learning and Systems , volume=
Awq: Activation-aware weight quantization for on-device llm compression and acceleration , author=. Proceedings of Machine Learning and Systems , volume=
-
[28]
In-context learning distillation: Transferring few-shot learning ability of pre-trained language models , author=. arXiv preprint arXiv:2212.10670 , year=
-
[29]
Scott: Self-consistent chain-of-thought distillation,
Scott: Self-consistent chain-of-thought distillation , author=. arXiv preprint arXiv:2305.01879 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Advances in Neural Information Processing Systems , volume=
Large language models are latent variable models: Explaining and finding good demonstrations for in-context learning , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
International Conference on Machine Learning , pages=
Sparsegpt: Massive language models can be accurately pruned in one-shot , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[33]
A simple and effective pruning approach for large language models , author=. arXiv preprint arXiv:2306.11695 , year=
-
[34]
The Twelfth International Conference on Learning Representations , year=
A Simple and Effective Pruning Approach for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[35]
Proceedings of the VLDB Endowment , volume=
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity , author=. Proceedings of the VLDB Endowment , volume=. 2023 , publisher=
work page 2023
-
[36]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[37]
Shortened LLaMA: A Simple Depth Pruning for Large Language Models , author=. CoRR , year=
-
[38]
Slicegpt: Compress large language models by deleting rows and columns,
Slicegpt: Compress large language models by deleting rows and columns , author=. arXiv preprint arXiv:2401.15024 , year=
-
[39]
Proceedings of the AAAI conference on artificial intelligence , volume=
Improved knowledge distillation via teacher assistant , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[40]
arXiv preprint arXiv:2305.02279 , year=
Learngene: Inheriting condensed knowledge from the ancestry model to descendant models , author=. arXiv preprint arXiv:2305.02279 , year=
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Transformer as Linear Expansion of Learngene , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Building Variable-Sized Models via Learngene Pool , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[43]
OLMoE: Open Mixture-of-Experts Language Models , author=. 2025 , eprint=
work page 2025
-
[44]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models , author=. 2024 , eprint=
work page 2024
-
[45]
Proceedings of NAACL-HLT , pages=
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , author=. Proceedings of NAACL-HLT , pages=
-
[46]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
-
[47]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[48]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[49]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
work page 2021
-
[50]
Yuxian Gu and Li Dong and Furu Wei and Minlie Huang , booktitle=. Mini. 2024 , url=
work page 2024
-
[51]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2022
-
[52]
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[53]
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author=. ACL , year=
-
[54]
and Stoica, Ion and Xing, Eric P
Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and Sheng, Ying and Wu, Zhanghao and Zhang, Hao and Zheng, Lianmin and Zhuang, Siyuan and Zhuang, Yonghao and Gonzalez, Joseph E. and Stoica, Ion and Xing, Eric P. , month =. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90\ url =
-
[55]
Some mathematical notes on three-mode factor analysis , author=. Psychometrika , volume=. 1966 , publisher=
work page 1966
-
[56]
Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs , author=. 2024 , eprint=
work page 2024
-
[57]
Proceedings of the eighteenth international conference on artificial intelligence and law , pages=
When does pretraining help? assessing self-supervised learning for law and the casehold dataset of 53,000+ legal holdings , author=. Proceedings of the eighteenth international conference on artificial intelligence and law , pages=
-
[58]
Proceedings of the Conference on Health, Inference, and Learning , pages =
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering , author =. Proceedings of the Conference on Health, Inference, and Learning , pages =. 2022 , editor =
work page 2022
-
[59]
International conference on machine learning , pages=
Unified scaling laws for routed language models , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[60]
Harder tasks need more experts: Dynamic routing in moe models , author=. arXiv preprint arXiv:2403.07652 , year=
-
[61]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[63]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[64]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Understanding the difficulty of training deep feedforward neural networks , author=. Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=. 2010 , organization=
work page 2010
-
[66]
Proceedings of the IEEE international conference on computer vision , pages=
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[67]
All you need is a good init , author=. arXiv preprint arXiv:1511.06422 , year=
-
[68]
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[69]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
work page 2019
-
[70]
Science China Information Sciences , volume=
Learnware: Small models do big , author=. Science China Information Sciences , volume=. 2024 , publisher=
work page 2024
-
[71]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Towards making learnware specification and market evolvable , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[72]
Importance Estimation for Neural Network Pruning , author=. 2019 , eprint=
work page 2019
-
[73]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
The lottery ticket hypothesis: Finding sparse, trainable neural networks , author=. arXiv preprint arXiv:1803.03635 , year=
-
[74]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
- [75]
-
[76]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Prefix-tuning: Optimizing continuous prompts for generation , author=. arXiv preprint arXiv:2101.00190 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
IEEE Transactions on Software Engineering , volume=
Code comment inconsistency detection based on confidence learning , author=. IEEE Transactions on Software Engineering , volume=. 2024 , publisher=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.