Recognition: 2 theorem links
· Lean TheoremM³: Reframing Training Measures for Discretized Physical Simulations
Pith reviewed 2026-05-12 02:15 UTC · model grok-4.3
The pith
M³ mitigates bias from uneven discretization in physical simulation training by using multi-scale Morton measures to balance supervision, leading to substantially more accurate predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the measure-induced bias in discretized training data for physical simulations can be mitigated by M³, a multi-scale Morton measure that partitions space by physical variation and allocates supervision across multiple scales. This approach consistently improves continuous-domain predictions across diverse industrial datasets, with gains that hold even when training data is reduced by orders of magnitude.
What carries the argument
Multi-scale Morton Measure (M³), which uses Morton ordering to partition and balance the training measure across scales according to physical variation.
If this is right
- Predictions in the continuous physical domain become more accurate and spatially consistent.
- M³-trained models achieve lower error than standard training even with aggressive data subsampling.
- Models can outperform those trained on higher-resolution data using only a fraction of the points.
- Data distribution emerges as a critical factor in operator learning for physics.
- M³ provides a scalable, data-efficient method for physically consistent modeling.
Where Pith is reading between the lines
- If discretization bias is the dominant issue, M³ could generalize to other surrogate modeling tasks involving geometric or volumetric data.
- Combining M³ with adaptive sampling during training might further reduce the need for dense initial datasets.
- Similar measure-reframing ideas could address biases in other machine learning applications with non-uniform data distributions.
Load-bearing premise
That partitioning space according to physical variation and allocating supervision across multiple scales via Morton ordering will reliably mitigate the measure-induced bias without introducing new spatial inconsistencies or requiring domain-specific tuning.
What would settle it
If M³ fails to reduce the physics-weighted relative L₂ error on a new industrial-scale volumetric dataset compared to standard uniform sampling, or if the improvement disappears under subsampling, the central claim would not hold.
Figures


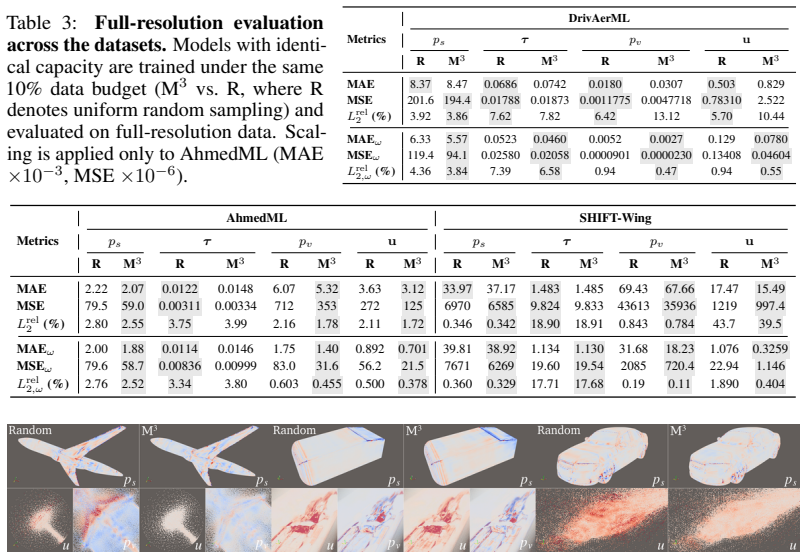
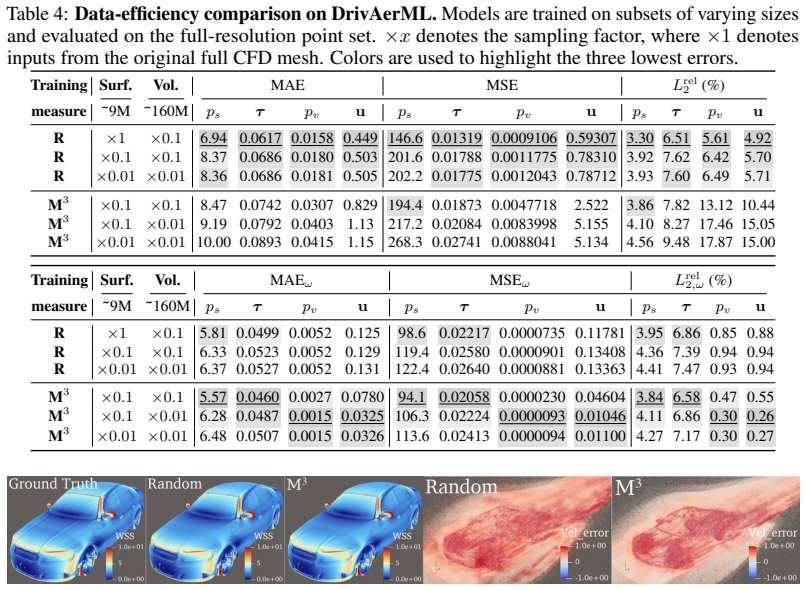














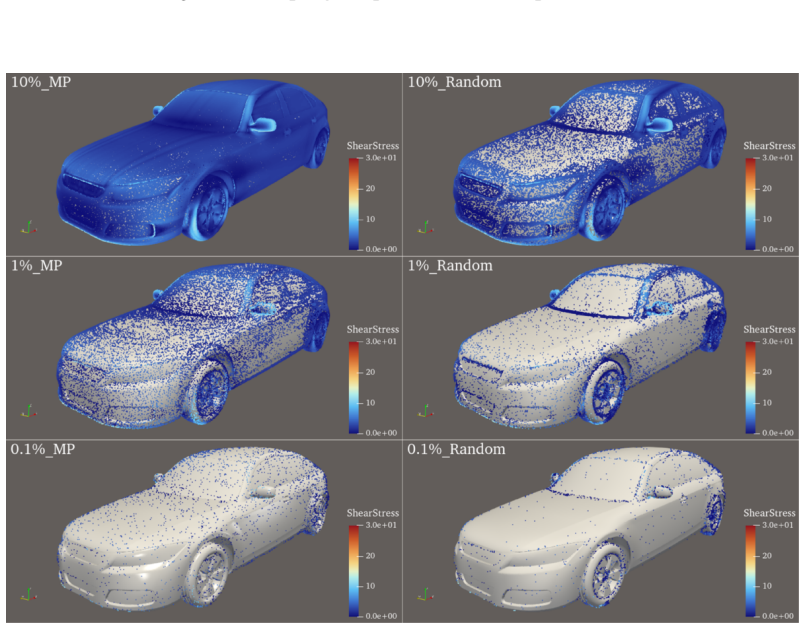








read the original abstract
Neural surrogate models for physical simulations are trained on discretized samples of continuous domains, where the induced empirical measure leads to uneven supervision, biasing optimization and causing spatial inconsistencies in physical fidelity. To mitigate this measure-induced bias, we propose M$^3$ (Multi-scale Morton Measure), a scalable framework that balances training measures by partitioning space according to physical variation and allocating supervision across multiple scales. Applied to three industrial-scale datasets with diverse discretizations, M$^3$ consistently improves predictions in the continuous physical domain, achieving up to 4.7$\times$ lower error in large-scale volumetric cases. These gains persist under aggressive subsampling (160M $\rightarrow$ 16M $\rightarrow$ 1.6M points), where M$^3$-trained models outperform those trained on higher-resolution data, reducing physics-weighted relative $L_2$ error by 3--4$\times$ and the corresponding MSE by up to 13$\times$. These results highlight data distribution as a key factor in operator learning and position M$^3$ as a scalable, data-efficient approach for physically consistent modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the empirical measure induced by discretized samples biases neural surrogate models for physical simulations, causing uneven supervision and spatial inconsistencies in physical fidelity. It proposes M³ (Multi-scale Morton Measure), a framework that mitigates this by partitioning space according to physical variation and allocating supervision across multiple scales via Morton ordering. Empirical results on three industrial-scale datasets with diverse discretizations show consistent improvements, including up to 4.7× lower error in large-scale volumetric cases; these gains persist under aggressive subsampling (160M → 16M → 1.6M points), where M³-trained models outperform those trained on higher-resolution data by reducing physics-weighted relative L₂ error 3–4× and MSE up to 13×.
Significance. If the results hold, the work is significant for demonstrating that training data distribution is a key, often overlooked factor in operator learning for physical simulations. It offers a scalable, data-efficient alternative to simply increasing resolution, with potential to improve physical consistency in surrogate models for industrial applications. The validation across multiple large datasets and subsampling regimes provides practical evidence of utility, though the absence of machine-checked proofs or parameter-free derivations means the assessment rests on empirical reproducibility.
major comments (3)
- [Abstract and §3] Abstract and §3 (Methods): The central mechanism partitions space 'according to physical variation' before applying Morton ordering, but no precise, reproducible definition or algorithm for computing this variation is given. Without specifying whether it relies on simulation-specific quantities (e.g., gradients, curvatures, or field magnitudes) or a domain-agnostic metric, it is impossible to verify that the approach avoids implicit domain tuning, which directly undermines the claim of generality across diverse discretizations.
- [Results (subsampling)] Results section (subsampling experiments): The headline claims of 3–4× reduction in physics-weighted relative L₂ error and up to 13× in MSE under 100× subsampling lack reported details on the exact partitioning algorithm, baseline implementations, error-bar reporting, or statistical significance tests. This makes it difficult to attribute the gains specifically to measure correction rather than experimental setup, which is load-bearing for the data-efficiency conclusion.
- [§4] §4 (Discussion or Experiments): No ablations are described on the contribution of the multi-scale Morton allocation versus the partitioning step alone, nor on sensitivity to the number of scales. Such controls would be necessary to confirm that the reported improvements stem from rebalancing the empirical measure without introducing new spatial inconsistencies.
minor comments (2)
- [Abstract] Abstract: The term 'physics-weighted relative L₂ error' is used without a definition or cross-reference to the relevant equation or section; a brief inline clarification would aid readability.
- [Figures/Tables] Figure and table captions: Ensure all visualizations of error metrics include explicit definitions of the weighting and any confidence intervals; current presentation leaves some notation ambiguous.
Simulated Author's Rebuttal
We thank the referee for their thorough review and positive assessment of the significance of our work on M³ for addressing training measure bias in physical simulation surrogates. We address each of the major comments below by providing clarifications and committing to revisions that enhance the manuscript's clarity, reproducibility, and completeness. We believe these changes will satisfactorily address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Methods): The central mechanism partitions space 'according to physical variation' before applying Morton ordering, but no precise, reproducible definition or algorithm for computing this variation is given. Without specifying whether it relies on simulation-specific quantities (e.g., gradients, curvatures, or field magnitudes) or a domain-agnostic metric, it is impossible to verify that the approach avoids implicit domain tuning, which directly undermines the claim of generality across diverse discretizations.
Authors: We agree that a more precise and reproducible definition of the physical variation metric is necessary for full verification of the method's generality. In the revised manuscript, we will expand the description in §3 to include a detailed, algorithmic specification of how physical variation is computed for partitioning, ensuring it is domain-agnostic and free of implicit tuning. This will directly support the generality claim demonstrated empirically across the diverse datasets. revision: yes
-
Referee: [Results (subsampling)] Results section (subsampling experiments): The headline claims of 3–4× reduction in physics-weighted relative L₂ error and up to 13× in MSE under 100× subsampling lack reported details on the exact partitioning algorithm, baseline implementations, error-bar reporting, or statistical significance tests. This makes it difficult to attribute the gains specifically to measure correction rather than experimental setup, which is load-bearing for the data-efficiency conclusion.
Authors: We concur that providing these details is essential to substantiate the subsampling results. The revised manuscript will include the exact partitioning algorithm (cross-referenced with the expanded §3), fuller descriptions of the baseline implementations, error bars from repeated experiments, and statistical significance testing to confirm the reported improvements are attributable to M³. revision: yes
-
Referee: [§4] §4 (Discussion or Experiments): No ablations are described on the contribution of the multi-scale Morton allocation versus the partitioning step alone, nor on sensitivity to the number of scales. Such controls would be necessary to confirm that the reported improvements stem from rebalancing the empirical measure without introducing new spatial inconsistencies.
Authors: We recognize the importance of these ablations for isolating the contributions of each component. In the revised version, we will add ablation studies in §4 comparing the full M³ approach to variants using only partitioning or only multi-scale allocation, along with sensitivity analysis to the number of scales. These will help verify that the gains come from measure rebalancing. revision: yes
Circularity Check
No circularity: empirical gains from defined method on external data
full rationale
The paper defines M³ as a partitioning-plus-Morton-ordering procedure to rebalance the empirical measure induced by discretization. All reported improvements (error reductions, subsampling robustness) are presented as outcomes of applying this procedure to three external industrial datasets and comparing against baselines. No equation, prediction, or first-principles claim is shown to be equivalent to a fitted quantity or self-citation by construction; the central mechanism is an explicit algorithmic choice whose effect is measured, not presupposed. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Discretized samples of continuous domains induce an empirical measure that biases optimization and causes spatial inconsistencies in physical fidelity.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
partitioning space according to physical variation and allocating supervision across multiple scales via Morton ordering
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Fourier neural operator for parametric partial differen- tial equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations. InInternational Conference on Learning Representations, 2021
work page 2021
-
[2]
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to PDEs.Journal of Machine Learning Research, 2023
work page 2023
-
[3]
Benedikt Alkin, Maurits Bleeker, Richard Kurle, Tobias Kronlachner, Reinhard Sonnleitner, Matthias Dorfer, and Johannes Brandstetter. AB-UPT: Scaling neural CFD surrogates for high-fidelity automotive aerodynamics simulations via anchored-branched universal physics transformers.Transactions on Machine Learning Research, 2025
work page 2025
-
[4]
AB-UPT for automotive and aerospace applications.arXiv preprint arXiv:2510.15808, 2025
Benedikt Alkin, Richard Kurle, Louis Serrano, Dennis Just, and Johannes Brandstetter. AB-UPT for automotive and aerospace applications.arXiv preprint arXiv:2510.15808, 2025
-
[5]
Maddix, Samuel Gundry, and Parisa Shabestari
Neil Ashton, Danielle C. Maddix, Samuel Gundry, and Parisa Shabestari. AhmedML: High- fidelity computational fluid dynamics dataset for incompressible, low-speed bluff body aerody- namics.arXiv preprint arXiv:2407.20801, 2024
-
[6]
Neil Ashton, Christopher Mockett, Matthias Fuchs, Lucas Fliessbach, Henry Hetmann, Thilo Knacke, Nils Schönwald, Vasilios Skaperdas, Georgios Fotiadis, André Walle, Bastian Hupertz, and Danielle C. Maddix. DrivAerML: High-fidelity computational fluid dynamics dataset for road-car external aerodynamics.arXiv preprint arXiv:2408.11969, 2024
-
[7]
Luminary Cloud. SHIFT-Wing: High-fidelity computational fluid dynamics dataset for transonic wing external aerodynamics. https://huggingface.co/datasets/luminary-shift/ WING/, 2025
work page 2025
-
[8]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhong, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nature Machine Intelligence, 2021
work page 2021
- [9]
- [10]
-
[11]
Johannes Brandstetter, Daniel E. Worrall, and Max Welling. Message passing neural PDE solvers. InInternational Conference on Learning Representations, 2022
work page 2022
-
[12]
Scalable transformer for PDE surrogate modeling
Zijie Li, Dule Shu, and Amir Barati Farimani. Scalable transformer for PDE surrogate modeling. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[13]
Huang, J., Yang, G., Wang, Z., and Park, J
Zhongkai Hao, Chengyang Ying, Zhengyi Wang, Su Hang, Yinpeng Dong, Songming Liu, Ze Cheng, Jun Zhu, and Jian Song. GNOT: A general neural operator transformer for operator learning.arXiv preprint arXiv:2302.14376, 2023
-
[14]
Transolver: A fast transformer solver for PDEs on general geometries
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for PDEs on general geometries. InInternational Conference on Machine Learning, 2024. 10
work page 2024
-
[15]
Shizheng Wen, Arsh Kumbhat, Levi Lingsch, Sepehr Mousavi, Yizhou Zhao, Praveen Chan- drashekar, and Siddhartha Mishra. Geometry-aware operator transformer as an efficient and accurate neural surrogate for PDEs on arbitrary domains.arXiv preprint arXiv:2505.18781, 2025
-
[16]
Transolver-3: Scaling Up Transformer Solvers to Industrial-Scale Geometries,
Hang Zhou, Haixu Wu, Haonan Shangguan, Yuezhou Ma, Huikun Weng, Jianmin Wang, and Mingsheng Long. Transolver-3: Scaling up transformer solvers to industrial-scale geometries. arXiv preprint arXiv:2602.04940, 2026
-
[17]
Chenxi Wu, Min Zhu, Qinyang Tan, Yadhu Kartha, and Lu Lu. A comprehensive study of non- adaptive and residual-based adaptive sampling for physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 2022
work page 2022
-
[18]
Zhenao Song. RL-PINNs: Reinforcement learning-driven adaptive sampling for efficient training of PINNs.arXiv preprint arXiv:2504.12949, 2025
-
[19]
Determinantal point processes for sampling minibatches in SGD
Rémi Bardenet, Subhro Ghosh, and Meixia Lin. Determinantal point processes for sampling minibatches in SGD. InAdvances in Neural Information Processing Systems, 2021
work page 2021
-
[20]
Determinantal point processes for mini-batch diversification.arXiv preprint arXiv:1705.00607, 2017
Cheng Zhang, Hedvig Kjellström, and Stephan Mandt. Determinantal point processes for mini-batch diversification.arXiv preprint arXiv:1705.00607, 2017
-
[21]
Accelerating stratified sampling SGD by reconstructing strata
Weijie Liu, Hui Qian, Chao Zhang, Zebang Shen, Jiahao Xie, and Nenggan Zheng. Accelerating stratified sampling SGD by reconstructing strata. InInternational Joint Conference on Artificial Intelligence, 2020
work page 2020
-
[22]
Adaptive sampling for SGD by exploiting side information
Siddharth Gopal. Adaptive sampling for SGD by exploiting side information. InInternational Conference on Machine Learning, 2016
work page 2016
-
[23]
Marsha J. Berger and Phillip Colella. Local adaptive mesh refinement for shock hydrodynamics. Journal of Computational Physics, 1984
work page 1984
-
[24]
A short survey on importance weighting for machine learning.arXiv preprint arXiv:2403.10175, 2024
Masanari Kimura and Hideitsu Hino. A short survey on importance weighting for machine learning.arXiv preprint arXiv:2403.10175, 2024
-
[25]
Hisashi Shimodaira. Improving predictive inference under covariate shift by weighting the log-likelihood function.Journal of Statistical Planning and Inference, 2000
work page 2000
-
[26]
Coresets for data-efficient training of machine learning models
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning models. InInternational Conference on Machine Learning, 2020
work page 2020
-
[27]
Active learning for convolutional neural networks: A core-set approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. InInternational Conference on Learning Representations, 2018
work page 2018
-
[28]
Dongyuan Li, Zhen Wang, Yankai Chen, Renhe Jiang, Weiping Ding, and Manabu Oku- mura. A survey on deep active learning: Recent advances and new frontiers.arXiv preprint arXiv:2405.00334, 2024
-
[29]
Guy M. Morton. A computer-oriented geodetic data base and a new technique in file sequencing. Technical report, IBM Research, 1966
work page 1966
-
[30]
Geometric modeling using octree encoding.Computer Graphics and Image Processing, 1982
Donald Meagher. Geometric modeling using octree encoding.Computer Graphics and Image Processing, 1982
work page 1982
-
[31]
Über die stetige abbildung einer linie auf ein flächenstück.Mathematische Annalen, 1891
David Hilbert. Über die stetige abbildung einer linie auf ein flächenstück.Mathematische Annalen, 1891
-
[32]
Bongki Moon, H. V . Jagadish, Christos Faloutsos, and Joel H. Saltz. Analysis of the clustering properties of the Hilbert space-filling curve.IEEE Transactions on Knowledge and Data Engineering, 2001
work page 2001
-
[33]
Symbolic discovery of optimization algorithms
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and Quoc V Le. Symbolic discovery of optimization algorithms. InAdvances in Neural Information Processing Systems, 2023. 11 A Measure-Theoretic Formulation of Subsampled Learning A.1 Training Measures under Subsampling Subsampli...
work page 2023
-
[34]
The model’s latent representation computation must remain consistent between training and inference, ensuring that observed performance differences arise from the input data rather than changes in the model or its processing behavior
-
[35]
We therefore use AB-UPT [ 3] as the main backbone
The entire domain can be evaluated at full resolution under the same target distribution to ensure a fair comparison. We therefore use AB-UPT [ 3] as the main backbone. This choice is motivated by its decoupled structure of latent anchor tokens and query tokens: anchors provide stable latent references, while queries retrieve representations via attention...
work page 2048
-
[36]
Raw data distributions of the simulation datasets
-
[37]
Partitioning results from Step 1
-
[38]
Grouping results from Step 2
-
[39]
Sampling results from Step 3
-
[40]
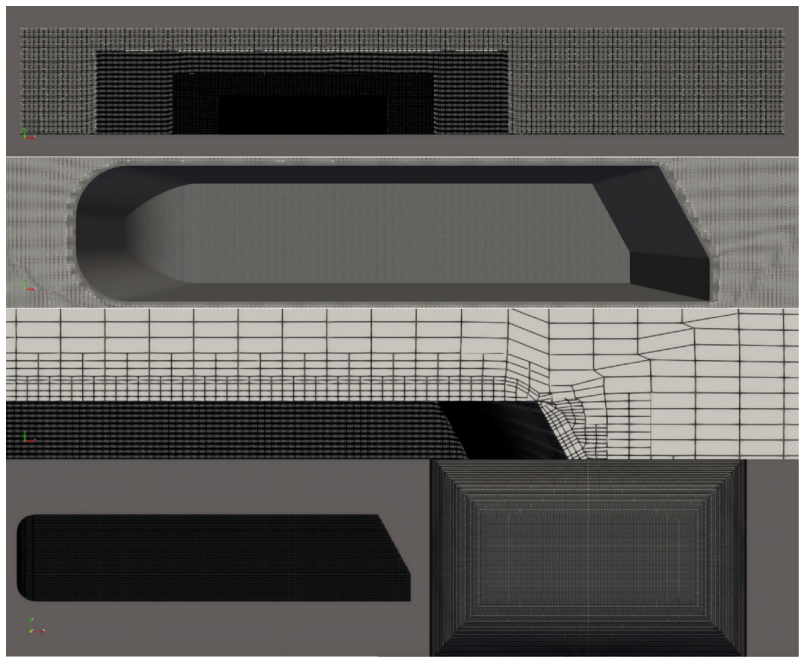
Inference results include predicted surface coefficients and full-resolution visualizations for each dataset. E.1 Discretization Structure of the Experimental Datasets: surface mesh and volume mesh Figure 6:Mesh of SHIFT-Wing.The mesh exhibits strong anisotropy, originating from AMR, where high-gradient regions are densely resolved. 21 Figure 7:Mesh of Ah...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.