Recognition: no theorem link
Machine Learning Research Has Outpaced Its Communication Norms and NeurIPS Should Act
Pith reviewed 2026-05-12 01:26 UTC · model grok-4.3
The pith
NeurIPS papers have become harder to read over decades as acronym use surged, and the conference should adopt explicit writing standards to reverse the trend.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
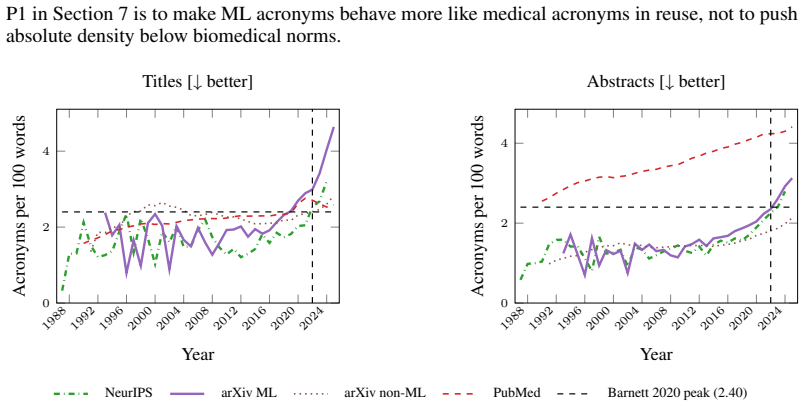
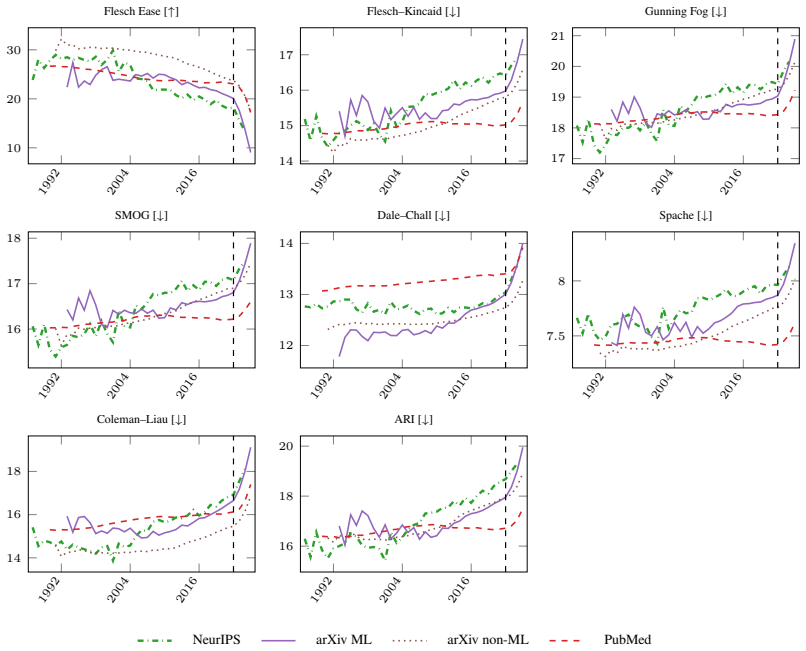
Machine learning research has grown exponentially while its communication norms have stayed the same or worsened, as shown by NeurIPS abstracts becoming harder to read on classical metrics, rising acronym density from 0.33 to 3.21 per 100 words, and increased sensational language. About 89 percent of acronyms are used fewer than ten times, and more readable papers tend to attract more citations. With volume up roughly fifty times since 1987, the authors conclude that NeurIPS should pilot seven standards starting in 2027 to prioritize human readers over surface statistics or LLM judgments.
What carries the argument
Longitudinal analysis of classical readability scores, acronym density, and citation correlations across 24,772 NeurIPS papers from 1987 to 2024, which documents the divergence from science-wide baselines and justifies enforceable standards.
Load-bearing premise
Classical readability metrics and the observed citation link accurately reflect human comprehension, and that imposing the proposed standards will improve actual understanding and impact rather than just changing surface statistics.
What would settle it
A controlled experiment measuring human readers' comprehension, retention, and ability to build on ideas from papers written under the proposed standards versus current norms, which would falsify the claim if scores improve but real understanding does not.
Figures







read the original abstract
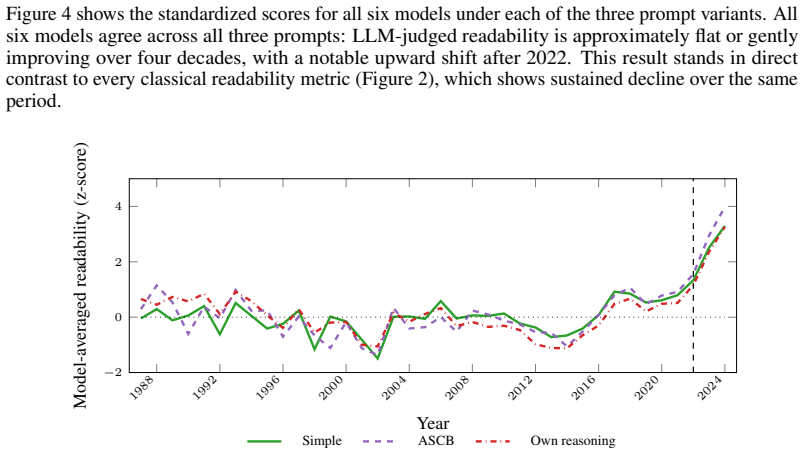
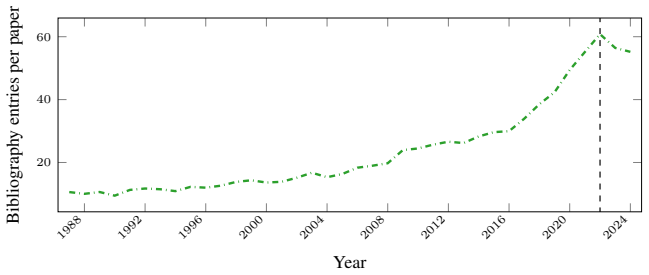
Machine learning research has grown exponentially while its communication norms have not. We argue NeurIPS should adopt explicit, measurable writing standards. We analyze 2.8 million arXiv papers (1991-2025), 24,772 NeurIPS papers (1987-2024), and 24.5 million PubMed papers (1990-2025), applying classical readability scores, the Hohmann writing style suite (including sensational language), acronym density and reuse, an LLM as judge readability protocol, and citations from OpenAlex and Semantic Scholar. Four patterns emerge. First, NeurIPS abstracts score harder to read on every classical readability metric: Flesch Reading Ease falls from about 24 in 1987 to 13 in 2024, and sensational language rises by about 50 percent in NeurIPS abstracts between 2015 and 2024. Second, acronym density in NeurIPS titles has grown from 0.33 per 100 words in 1987 to 3.21 in 2024, and about 89 percent of NeurIPS acronyms are used fewer than ten times, ten points above the science-wide baseline. Third, more readable NeurIPS papers tend to receive more citations, suggesting readability and impact are correlated and that less readable papers risk remaining fragmented. LLM as judge scores rate NeurIPS abstracts as roughly stable from 1987 to 2022, with early signs of improvement thereafter, a pattern that disagrees with every classical readability metric and raises a design question for enforcement: is the target reader a human or an LLM? Lastly, NeurIPS volume has grown roughly 50-fold between 1987 and 2024. Assuming the goal is to optimise for human readers, we propose seven standards NeurIPS could pilot at NeurIPS 2027: an acronym budget with a venue-approved term list, a human readability threshold, stricter citation standards, standalone visual elements, a plain language summary, a pre-registered acronym glossary, and open source audit tooling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes trends in 2.8M arXiv papers, 24k NeurIPS papers, and 24.5M PubMed papers using classical readability metrics (e.g., Flesch Reading Ease declining from ~24 in 1987 to 13 in 2024 for NeurIPS abstracts), acronym density (rising from 0.33 to 3.21 per 100 words in NeurIPS titles), sensationalism, LLM-as-judge protocols, and citation data. It reports that NeurIPS communication has become harder to read and more acronym-heavy than baselines, that more readable papers receive more citations, that LLM scores conflict with classical metrics, and that NeurIPS volume has grown 50-fold; it proposes seven pilot standards for NeurIPS 2027 including acronym budgets, readability thresholds, plain-language summaries, and audit tooling.
Significance. If the observed trends are robust and the metrics validly proxy human comprehension, the work provides a large-scale empirical basis for concerns about accessibility in ML research and offers concrete, measurable policy proposals that could influence conference norms. The scale of the multi-corpus analysis (millions of papers, multiple metric families, cross-domain comparisons) and the explicit contrast between classical and LLM-based scores are strengths that could stimulate further empirical work on scientific communication.
major comments (3)
- [citation correlation analysis] The citation-readability correlation (reported in the abstract and the third pattern) is presented without error bars, without details on sampling or pre-processing of the 24,772 NeurIPS papers, and without controls for confounders such as subfield, author prestige, paper length, or novelty; this leaves open whether the positive link is causal or confounded and weakens the claim that less readable papers risk remaining fragmented.
- [comparison of metric families] Classical readability metrics (Flesch, etc.) and acronym counts are applied directly to domain-dense ML abstracts containing equations and novel jargon, yet the paper notes that its own LLM-as-judge protocol shows stability or slight improvement (disagreeing with every classical metric) without human-subject validation (expert ratings or comprehension quizzes) to establish that the metric declines track actual difficulty for ML readers.
- [proposed standards] The proposal of seven standards (acronym budget, human readability threshold, etc.) rests on the assumption that enforcing them will improve human understanding or impact, but the manuscript provides no pilot data, prior evidence from other fields, or discussion of potential unintended effects (e.g., on technical precision) to support that the surface-statistic changes will translate to better comprehension.
minor comments (2)
- [methods] The abstract and text would benefit from explicit statements of the exact sampling criteria and preprocessing steps used for the NeurIPS and arXiv corpora to allow replication.
- [results figures] Figure or table captions for the trend plots should include the number of papers per year and any confidence intervals to improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. Their comments help clarify how to strengthen the statistical presentation, metric interpretation, and framing of the policy proposals. We respond to each major comment below and indicate the revisions that will be made to the manuscript.
read point-by-point responses
-
Referee: The citation-readability correlation (reported in the abstract and the third pattern) is presented without error bars, without details on sampling or pre-processing of the 24,772 NeurIPS papers, and without controls for confounders such as subfield, author prestige, paper length, or novelty; this leaves open whether the positive link is causal or confounded and weakens the claim that less readable papers risk remaining fragmented.
Authors: We agree that the correlation analysis requires greater statistical transparency. In the revised manuscript we will add error bars to the citation-readability plots, provide complete details on the sampling frame (all 24,772 NeurIPS papers 1987–2024 with citation data from OpenAlex) and pre-processing steps (abstract extraction, cleaning, and tokenization), and include multivariate regressions controlling for paper length, year, and subfield. Author prestige and novelty are difficult to operationalize at this scale, so we will explicitly discuss them as unmeasured confounders and rephrase the fragmentation claim as an observational association that motivates further investigation rather than a causal assertion. revision: yes
-
Referee: Classical readability metrics (Flesch, etc.) and acronym counts are applied directly to domain-dense ML abstracts containing equations and novel jargon, yet the paper notes that its own LLM-as-judge protocol shows stability or slight improvement (disagreeing with every classical metric) without human-subject validation (expert ratings or comprehension quizzes) to establish that the metric declines track actual difficulty for ML readers.
Authors: We deliberately juxtapose classical metrics with acronym density and the LLM protocol precisely because classical formulas were not designed for equation-laden technical text; the disagreement is presented as a substantive finding that raises the human-versus-LLM reader question. We will add an expanded limitations subsection that acknowledges the absence of direct human comprehension studies in this work, cites prior domain-specific readability research, and clarifies that classical metrics are used as established proxies while the LLM results are exploratory. This will make the metric comparison more balanced without overstating what the data demonstrate. revision: partial
-
Referee: The proposal of seven standards (acronym budget, human readability threshold, etc.) rests on the assumption that enforcing them will improve human understanding or impact, but the manuscript provides no pilot data, prior evidence from other fields, or discussion of potential unintended effects (e.g., on technical precision) to support that the surface-statistic changes will translate to better comprehension.
Authors: The seven standards are offered as concrete, measurable pilots for NeurIPS 2027 rather than as interventions already proven to raise comprehension. In revision we will insert a dedicated subsection that (a) references analogous plain-language and terminology-control efforts in biomedicine and physics, (b) explicitly discusses possible unintended consequences such as reduced technical precision or displacement of necessary jargon, and (c) frames the standards as testable hypotheses whose effects on reader understanding and citation impact should be evaluated during the pilot. This will present the proposals as an empirical invitation rather than an unexamined prescription. revision: yes
Circularity Check
No circularity: purely observational trends from external data
full rationale
The paper performs large-scale empirical analysis of readability metrics, acronym counts, and citation correlations across arXiv, NeurIPS, and PubMed corpora. No derived quantity is defined in terms of itself, no fitted parameter is relabeled as a prediction, and no load-bearing claim reduces to a self-citation or ansatz. All central patterns (Flesch decline, acronym growth, readability-citation link) are computed directly from the cited external datasets and standard formulas; the LLM-as-judge comparison is an additional measurement, not a definitional loop. The proposal of standards follows from the observations without circular justification.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Classical readability scores (Flesch, etc.) and the Hohmann sensational-language suite measure actual human comprehension difficulty in scientific abstracts.
- domain assumption The citation-readability correlation reflects a causal effect of readability on impact rather than confounding factors such as topic popularity or author reputation.
Reference graph
Works this paper leans on
-
[1]
The growth of acronyms in the scientific literature , author =. eLife , volume =. 2020 , doi =
work page 2020
-
[2]
The evolution of scientific writing: an analysis of 20 million abstracts over 70 years in health and medical science , author =. Scientometrics , volume =. 2025 , doi =
work page 2025
-
[3]
Biological Conservation , volume =
Comparing the writing styles of highly and rarely cited papers in conservation biology , author =. Biological Conservation , volume =. 2025 , doi =
work page 2025
-
[5]
Narrative Style Influences Citation Frequency in Climate Change Science , author =. PLOS ONE , volume =. 2016 , doi =
work page 2016
-
[6]
Trends in the Use of Promotional Language (Hype) in Abstracts of Successful National Institutes of Health Grant Applications, 1985--2020 , author =. JAMA Network Open , volume =. 2022 , doi =
work page 1985
-
[7]
Journal of Educational Psychology , volume =
Effects of text structure on use of cognitive capacity during reading , author =. Journal of Educational Psychology , volume =. 1982 , doi =
work page 1982
- [8]
-
[9]
The Chicago Guide to Communicating Science , author =
-
[10]
The Sense of Style: The Thinking Person's Guide to Writing in the 21st Century , author =
-
[11]
Stylish Academic Writing , author =
-
[12]
How can we boost the impact of publications?
Ryba, Ren and Doubleday, Zo. How can we boost the impact of publications?. Proceedings of the National Academy of Sciences , volume =. 2019 , doi =
work page 2019
-
[13]
Journal of Marketing , volume =
The Quest for Citations: Drivers of Article Impact , author =. Journal of Marketing , volume =. 2007 , doi =
work page 2007
-
[14]
The readability of scientific texts is decreasing over time , author =. eLife , volume =. 2017 , doi =
work page 2017
-
[15]
Proceedings of the Royal Society B , volume =
Specialized terminology reduces the number of citations of scientific papers , author =. Proceedings of the Royal Society B , volume =. 2021 , doi =
work page 2021
-
[16]
Knowledge in the dark: scientific challenges and ways forward , author =. FACETS , volume =. 2019 , doi =
work page 2019
- [17]
-
[18]
Learning and Instruction , volume =
Cognitive load theory, learning difficulty, and instructional design , author =. Learning and Instruction , volume =. 1994 , doi =
work page 1994
-
[19]
Public Understanding of Science , volume =
Jargon as a barrier to effective science communication: evidence from metacognition , author =. Public Understanding of Science , volume =. 2019 , doi =
work page 2019
-
[20]
Journal of Language and Social Psychology , volume =
The effects of jargon on processing fluency, self-perceptions, and scientific engagement , author =. Journal of Language and Social Psychology , volume =. 2020 , doi =
work page 2020
- [21]
-
[22]
Readability and citations in information science: evidence from abstracts and articles of four journals (2003--2012) , author =. Scientometrics , volume =. 2016 , doi =
work page 2003
-
[24]
The growth of acronyms in the scientific literature
Adrian Barnett and Zoe Doubleday. The growth of acronyms in the scientific literature. eLife, 9: 0 e60080, 2020. doi:10.7554/eLife.60080. URL https://doi.org/10.7554/eLife.60080. Science wide acronym baseline: 2.4 acronyms per 100 title words (2019); roughly 30 percent of acronyms used once; 1.1M unique acronyms across 24M titles and 18M abstracts (1950 to 2019)
-
[25]
Leonard Berlin. TAC : AOITROMJA ? (the acronym conundrum: advancing or impeding the readability of medical journal articles?). Radiology, 266 0 (2): 0 383--387, 2013. doi:10.1148/radiol.12121776. URL https://doi.org/10.1148/radiol.12121776
-
[26]
Bruce K. Britton, Shawn M. Glynn, Bonnie J. F. Meyer, and M. J. Penland. Effects of text structure on use of cognitive capacity during reading. Journal of Educational Psychology, 74 0 (1): 0 51--61, 1982. doi:10.1037/0022-0663.74.1.51. URL https://doi.org/10.1037/0022-0663.74.1.51
-
[27]
Isabel Cachola, Daniel Khashabi, and Mark Dredze. Evaluating the evaluators: Are readability metrics good measures of readability? arXiv preprint arXiv:2508.19221, 2025. URL https://arxiv.org/abs/2508.19221
-
[28]
Nuo Chen, Moming Duan, Andre Huikai Lin, Qian Wang, Jiaying Wu, and Bingsheng He. Position: T he current AI conference model is unsustainable! diagnosing the crisis of centralized AI conference, 2025. URL https://arxiv.org/abs/2508.04586
-
[29]
Ann Hillier, Ryan P. Kelly, and Terrie Klinger. Narrative style influences citation frequency in climate change science. PLOS ONE, 11 0 (12): 0 e0167983, 2016. doi:10.1371/journal.pone.0167983. URL https://doi.org/10.1371/journal.pone.0167983
-
[30]
Mollie Hawkes Hohmann and Sean D. Connell. Comparing the writing styles of highly and rarely cited papers in conservation biology. Biological Conservation, 307: 0 111125, 2025. doi:10.1016/j.biocon.2025.111125. URL https://doi.org/10.1016/j.biocon.2025.111125
-
[31]
Barnett, Neil King, and Sean D
Mollie Hawkes Hohmann, Adrian G. Barnett, Neil King, and Sean D. Connell. The evolution of scientific writing: an analysis of 20 million abstracts over 70 years in health and medical science. Scientometrics, 130: 0 3349--3366, 2025. doi:10.1007/s11192-025-05353-8. URL https://doi.org/10.1007/s11192-025-05353-8. Source of the Hohmann writing style metric s...
-
[32]
Jeschke, Sophie Lokatis, Isabelle Bartram, and Klement Tockner
Jonathan M. Jeschke, Sophie Lokatis, Isabelle Bartram, and Klement Tockner. Knowledge in the dark: scientific challenges and ways forward. FACETS, 4 0 (1): 0 423--441, 2019. doi:10.1139/facets-2019-0007. URL https://doi.org/10.1139/facets-2019-0007
-
[33]
Lei Lei and Su Yan. Readability and citations in information science: evidence from abstracts and articles of four journals (2003--2012). Scientometrics, 108 0 (3): 0 1155--1169, 2016. doi:10.1007/s11192-016-2036-9. URL https://doi.org/10.1007/s11192-016-2036-9
-
[34]
Scientific Writing = Thinking in Words
David Lindsay. Scientific Writing = Thinking in Words. CSIRO Publishing, 2011. doi:10.1071/9780643101579. URL https://doi.org/10.1071/9780643101579
-
[35]
Specialized terminology reduces the number of citations of scientific papers
Alejandro Mart \'i nez and Stefano Mammola. Specialized terminology reduces the number of citations of scientific papers. Proceedings of the Royal Society B, 288 0 (1947): 0 20202581, 2021. doi:10.1098/rspb.2020.2581. URL https://doi.org/10.1098/rspb.2020.2581
-
[36]
Neil Millar, Bojan Batalo, and Brian Budgell. Trends in the use of promotional language (hype) in abstracts of successful national institutes of health grant applications, 1985--2020. JAMA Network Open, 5 0 (8): 0 e2228676, 2022. doi:10.1001/jamanetworkopen.2022.28676. URL https://doi.org/10.1001/jamanetworkopen.2022.28676
-
[37]
Scott L. Montgomery. The Chicago Guide to Communicating Science. University of Chicago Press, 2003
work page 2003
-
[38]
The Sense of Style: The Thinking Person's Guide to Writing in the 21st Century
Steven Pinker. The Sense of Style: The Thinking Person's Guide to Writing in the 21st Century. Viking, 2014
work page 2014
-
[39]
The readability of scientific texts is decreasing over time
Pontus Plav \'e n-Sigray, Granville James Matheson, Bj \"o rn Christian Schiffler, and William Hedley Thompson. The readability of scientific texts is decreasing over time. eLife, 6: 0 e27725, 2017. doi:10.7554/eLife.27725. URL https://doi.org/10.7554/eLife.27725
-
[40]
Ren Ryba, Zo \"e A. Doubleday, and Sean D. Connell. How can we boost the impact of publications? T ry better writing. Proceedings of the National Academy of Sciences, 116 0 (2): 0 341--343, 2019. doi:10.1073/pnas.1819937116. URL https://doi.org/10.1073/pnas.1819937116
-
[41]
Hillary C. Shulman, Graham N. Dixon, Odalys M. Bullock, and Dolores Col \'o n Amill. The effects of jargon on processing fluency, self-perceptions, and scientific engagement. Journal of Language and Social Psychology, 39 0 (5--6): 0 579--597, 2020. doi:10.1177/0261927X20902177. URL https://doi.org/10.1177/0261927X20902177
-
[42]
Stefan Stremersch, Isabel Verniers, and Peter C. Verhoef. The quest for citations: Drivers of article impact. Journal of Marketing, 71 0 (3): 0 171--193, 2007. doi:10.1509/jmkg.71.3.171. URL https://doi.org/10.1509/jmkg.71.3.171
-
[43]
Cognitive load theory, learning difficulty, and instructional design
John Sweller. Cognitive load theory, learning difficulty, and instructional design. Learning and Instruction, 4 0 (4): 0 295--312, 1994. doi:10.1016/0959-4752(94)90003-5. URL https://doi.org/10.1016/0959-4752(94)90003-5
-
[44]
Helen Sword. Stylish Academic Writing. Harvard University Press, 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.