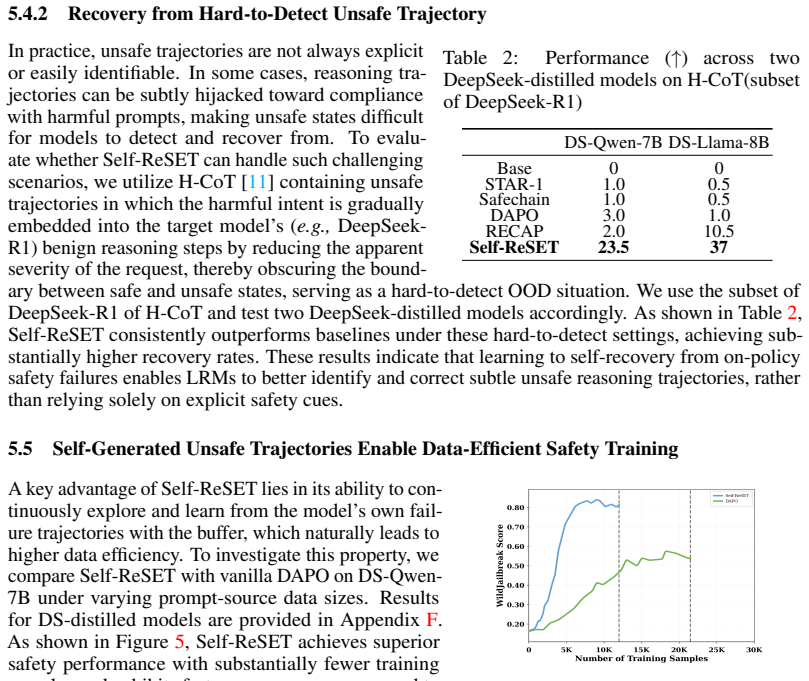
Recognition: 2 theorem links
· Lean TheoremSelf-ReSET: Learning to Self-Recover from Unsafe Reasoning Trajectories
Pith reviewed 2026-05-12 02:01 UTC · model grok-4.3
The pith
A reinforcement learning method lets large reasoning models recover from the unsafe paths they generate themselves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
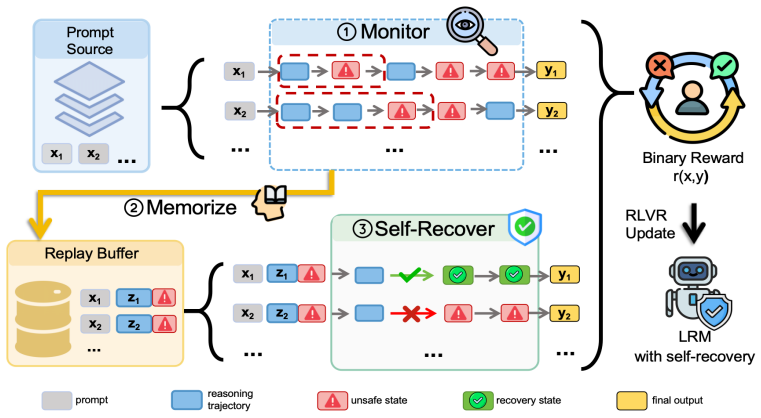
Self-ReSET is a pure reinforcement learning framework that equips large reasoning models with the intrinsic capacity to recover from their own safety error trajectories, which are subsequently reused as an initial state for reinforcement learning.
What carries the argument
Self-ReSET: a reinforcement learning loop that takes dynamically generated unsafe reasoning trajectories from the model itself and uses them as initial states to train recovery to benign outputs.
If this is right
- Stronger defense against out-of-distribution jailbreak prompts while general capabilities stay intact.
- More efficient use of training data since no large static expert sets are required.
- Emergence of self-recovery patterns that spot unsafe intermediate states and steer back to safe paths.
- Better coverage of the model's actual generation space during safety training.
Where Pith is reading between the lines
- The same self-generated trajectory approach could extend to other safety issues such as bias or factual errors.
- It reduces reliance on human-curated safety datasets for alignment work.
- Testing the method on even larger models would show whether the gains scale.
- Combining Self-ReSET with other reinforcement learning safety techniques could create stronger hybrid training.
Load-bearing premise
That the unsafe trajectories the model produces on its own will cover enough of its possible failure modes for reinforcement learning to learn reliable recovery.
What would settle it
Running the trained model on a fresh set of out-of-distribution jailbreak prompts and finding no gain in successful recovery rates compared with models trained on static expert data.
Figures







read the original abstract
Large Reasoning Models possess remarkable capabilities for self-correction in general domain; however, they frequently struggle to recover from unsafe reasoning trajectories under adversarial attacks. Existing alignment methods attempt to mitigate this vulnerability by fine-tuning the model on expert data including reflection traces or adversarial prefixes. Crucially, these approaches are often hindered by static training data which inevitably deviate from model's dynamic, on-policy reasoning traces, resulting in model hardly covering its vast generation space and learning to recover from its own failures. To bridge this gap, we propose Self-ReSET, a pure reinforcement learning framework designed to equip LRMs with the intrinsic capacity to recover from their own safety error trajectories, which are subsequently reused as an initial state for reinforcement learning. Extensive experiments across various LRMs and benchmarks demonstrate that Self-ReSET significantly enhances robustness against adversarial attacks especially out-of-distribution (OOD) jailbreak prompts while maintaining general utility, along with efficient data utilization. Further analysis reveals that our method effectively fosters self-recovery patterns, enabling models to better identify and recover from unsafe intermediate error states back to benign paths. Our codes and data are available at https://github.com/Ing1024/Self-ReSET.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Self-ReSET, a reinforcement learning framework for large reasoning models (LRMs) that reuses the model's own dynamically generated unsafe reasoning trajectories as initial states to train the model to recover from safety errors. The authors claim this approach enhances robustness to adversarial attacks, particularly out-of-distribution (OOD) jailbreak prompts, maintains general utility, and utilizes data efficiently compared to methods relying on static expert data.
Significance. If the empirical results hold, this work could be significant for AI safety by providing a method to improve self-correction in reasoning models without relying on potentially mismatched static datasets. It highlights the potential of on-policy RL for learning recovery behaviors, which might generalize better to novel threats. The availability of code and data is a positive for reproducibility.
major comments (3)
- [Abstract] Abstract: The abstract asserts 'extensive experiments across various LRMs and benchmarks' that demonstrate significant OOD robustness gains, but provides no metrics, baselines, ablation details, statistical controls, or effect sizes. This prevents assessment of whether the central claim of superior OOD performance over static-data methods is supported.
- [Method] Method section: The core claim that self-generated unsafe trajectories enable recovery across a 'vast generation space' including OOD jailbreaks rests on the unverified assumption that on-policy sampling will cover distributions beyond the current policy's reachable error manifold. No explicit coverage metric, diversity injection, or comparison to external OOD prompts is described, raising the risk that reported OOD gains reflect test-set overlap rather than genuine generalization.
- [Experiments] Experiments section: Without details on how OOD prompts are constructed and whether they lie outside the distribution of trajectories generated during training, the headline OOD improvement cannot be distinguished from in-distribution recovery. The paper should report separate in-distribution vs. OOD metrics and ablations isolating the effect of dynamic vs. static initial states.
minor comments (2)
- [Abstract] Abstract: Clarify the reward function and policy update rule used in the 'pure reinforcement learning framework,' as these are central to understanding how recovery is incentivized.
- The GitHub link is welcome, but the manuscript should include a reproducibility checklist covering random seeds, hyperparameter ranges, and exact prompt templates for the adversarial attacks.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, providing clarifications from the manuscript where available and indicating revisions to strengthen the presentation of results and methodology.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts 'extensive experiments across various LRMs and benchmarks' that demonstrate significant OOD robustness gains, but provides no metrics, baselines, ablation details, statistical controls, or effect sizes. This prevents assessment of whether the central claim of superior OOD performance over static-data methods is supported.
Authors: The abstract is intentionally concise as a high-level overview. The Experiments section (and associated tables/figures) provides the requested details, including quantitative OOD robustness improvements, baseline comparisons (e.g., against static expert-data methods), ablation studies, and effect sizes across multiple LRMs and benchmarks. To improve accessibility, we will revise the abstract to incorporate key numerical results and effect sizes supporting the OOD gains. revision: yes
-
Referee: [Method] Method section: The core claim that self-generated unsafe trajectories enable recovery across a 'vast generation space' including OOD jailbreaks rests on the unverified assumption that on-policy sampling will cover distributions beyond the current policy's reachable error manifold. No explicit coverage metric, diversity injection, or comparison to external OOD prompts is described, raising the risk that reported OOD gains reflect test-set overlap rather than genuine generalization.
Authors: Self-ReSET generates unsafe trajectories on-policy from the current model during RL training, directly sampling from the policy's reachable error states rather than relying on a fixed external distribution. This design inherently targets the model's own generation manifold. OOD evaluation uses separately constructed prompts held out from training data generation. While an explicit coverage metric was not reported, the consistent OOD gains over static baselines provide empirical support for generalization. We will add a discussion of trajectory diversity and a direct comparison to external OOD prompt sets in the revised Method section. revision: partial
-
Referee: [Experiments] Experiments section: Without details on how OOD prompts are constructed and whether they lie outside the distribution of trajectories generated during training, the headline OOD improvement cannot be distinguished from in-distribution recovery. The paper should report separate in-distribution vs. OOD metrics and ablations isolating the effect of dynamic vs. static initial states.
Authors: The Experiments section describes OOD prompt construction via adversarial templates and topics distinct from the training trajectory distribution, with results showing gains on these held-out sets. To address the concern directly, we will expand the section with explicit construction details, separate in-distribution versus OOD performance tables, and new ablations contrasting dynamic self-generated initial states against static expert data. These additions will isolate the contribution of on-policy recovery learning. revision: yes
Circularity Check
No circularity: method and claims are independently defined and empirically validated
full rationale
The paper defines Self-ReSET as a reinforcement learning procedure that generates unsafe trajectories on-policy from the current model and reuses them as RL starting states to train recovery. This construction is stated directly in the abstract and does not reduce any claimed performance gain (robustness on OOD jailbreaks, utility preservation) to a fitted parameter or self-citation by definition. No equations are presented that equate the output metric to the input distribution; the reported improvements rest on external benchmark experiments rather than tautological renaming or load-bearing self-citations. The derivation chain therefore remains self-contained against the stated inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning on self-generated unsafe trajectories will produce recovery behaviors that generalize to unseen adversarial prompts.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearSelf-ReSET follows a “monitor, memorize, then self-recover during reasoning” paradigm... experience replay buffer... verifiable binary safety rewards... DAPO Optimization
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorem unclearlearning from self-generated failures... expands coverage of the safety error space
Reference graph
Works this paper leans on
-
[1]
Vicky Zhao, Conghui He, and Lijun Wu
Zhuoshi Pan, Yu Li, Honglin Lin, Qizhi Pei, Zinan Tang, Wei Wu, Chenlin Ming, H. Vicky Zhao, Conghui He, and Lijun Wu. LEMMA: learning from errors for mathematical advancement in llms. InACL (Findings), pages 11615–11639. Association for Computational Linguistics, 2025
work page 2025
-
[2]
arXiv preprint arXiv:2409.12917 , year=
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D. Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M. Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal M. P. Behbahani, and Aleksandra Faust. Training language models to self-correct via reinforcement learning.CoRR, ab...
-
[3]
Shu Yang, Junchao Wu, Xin Chen, Yunze Xiao, Xinyi Yang, Derek F. Wong, and Di Wang. Understanding aha moments: from external observations to internal mechanisms.CoRR, abs/2504.02956, 2025
-
[4]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
work page 2025
-
[5]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, Xiaohan Zhang, Xuancheng Huang, Yao Wei, Yean Cheng, Yifan An, Yilin Niu, Yuanhao Wen, Yushi Bai, Zhengxiao Du, Zihan Wang, Zilin Zhu, Bohan Zhang, Bosi Wen, Bowen Wu, Bowen Xu, Ca...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondrich, Andrey ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InNeurIPS, 2022
work page 2022
-
[8]
the most powerful open-source model to date
Kaiwen Zhou, Chengzhi Liu, Xuandong Zhao, Shreedhar Jangam, Jayanth Srinivasa, Gaowen Liu, Dawn Song, and Xin Eric Wang. The hidden risks of large reasoning models: A safety assessment of R1.CoRR, abs/2502.12659, 2025
-
[9]
Zheng-Xin Yong and Stephen H. Bach. Self-jailbreaking: Language models can reason them- selves out of safety alignment after benign reasoning training.CoRR, abs/2510.20956, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Safechain: Safety of language models with long chain-of-thought reasoning capabilities
Fengqing Jiang, Zhangchen Xu, Yuetai Li, Luyao Niu, Zhen Xiang, Bo Li, Bill Yuchen Lin, and Radha Poovendran. Safechain: Safety of language models with long chain-of-thought reasoning capabilities. InACL (Findings), pages 23303–23320. Association for Computational Linguistics, 2025
work page 2025
-
[11]
Martin Kuo, Jianyi Zhang, Aolin Ding, Qinsi Wang, Louis DiValentin, Yujia Bao, Wei Wei, Hai Li, and Yiran Chen. H-cot: Hijacking the chain-of-thought safety reasoning mechanism to jailbreak large reasoning models, including openai o1/o3, deepseek-r1, and gemini 2.0 flash thinking.CoRR, abs/2502.12893, 2025
-
[12]
Yiming Zhang, Jianfeng Chi, Hailey Nguyen, Kartikeya Upasani, Daniel M. Bikel, Jason E. Weston, and Eric Michael Smith. Backtracking improves generation safety. InICLR. OpenRe- view.net, 2025
work page 2025
-
[13]
STAIR: improving safety alignment with introspective reasoning
Yichi Zhang, Siyuan Zhang, Yao Huang, Zeyu Xia, Zhengwei Fang, Xiao Yang, Ranjie Duan, Dong Yan, Yinpeng Dong, and Jun Zhu. STAIR: improving safety alignment with introspective reasoning. InICML. OpenReview.net, 2025
work page 2025
-
[14]
Unsafechain: Enhancing reasoning model safety via hard cases.CoRR, abs/2507.21652, 2025
Raj Vardhan Tomar, Preslav Nakov, and Yuxia Wang. Unsafechain: Enhancing reasoning model safety via hard cases.CoRR, abs/2507.21652, 2025
-
[15]
Yichi Zhang, Zihao Zeng, Dongbai Li, Yao Huang, Zhijie Deng, and Yinpeng Dong. Realsafe-r1: Safety-aligned deepseek-r1 without compromising reasoning capability.CoRR, abs/2504.10081, 2025
-
[16]
Safekey: Amplifying aha-moment insights for safety reasoning.CoRR, abs/2505.16186, 2025
Kaiwen Zhou, Xuandong Zhao, Gaowen Liu, Jayanth Srinivasa, Aosong Feng, Dawn Song, and Xin Eric Wang. Safekey: Amplifying aha-moment insights for safety reasoning.CoRR, abs/2505.16186, 2025
-
[17]
Zihao Zhu, Xinyu Wu, Gehan Hu, Siwei Lyu, Ke Xu, and Baoyuan Wu. Advchain: Adver- sarial chain-of-thought tuning for robust safety alignment of large reasoning models.CoRR, abs/2509.24269, 2025. 11
-
[18]
When Models Outthink Their Safety: Unveiling and Mitigating Self-Jailbreak in Large Reasoning Models
Yingzhi Mao, Chunkang Zhang, Junxiang Wang, Xinyan Guan, Boxi Cao, Yaojie Lu, Hongyu Lin, Xianpei Han, and Le Sun. When models outthink their safety: Mitigating self-jailbreak in large reasoning models with chain-of-guardrails.CoRR, abs/2510.21285, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Junda Zhu, Lingyong Yan, Shuaiqiang Wang, Dawei Yin, and Lei Sha. Reasoning-to- defend: Safety-aware reasoning can defend large language models from jailbreaking.CoRR, abs/2502.12970, 2025
-
[20]
Saro: Enhancing LLM safety through reasoning-based alignment.CoRR, abs/2504.09420, 2025
Yutao Mou, Yuxiao Luo, Shikun Zhang, and Wei Ye. Saro: Enhancing LLM safety through reasoning-based alignment.CoRR, abs/2504.09420, 2025
-
[21]
Yichi Zhang, Yue Ding, Jingwen Yang, Tianwei Luo, Dongbai Li, Ranjie Duan, Qiang Liu, Hang Su, Yinpeng Dong, and Jun Zhu. Towards safe reasoning in large reasoning models via corrective intervention.CoRR, abs/2509.24393, 2025
-
[22]
Large Reasoning Models Learn Better Alignment from Flawed Thinking
Shengyun Peng, Eric Smith, Ivan Evtimov, Song Jiang, Pin-Yu Chen, Hongyuan Zhan, Haozhu Wang, Duen Horng Chau, Mahesh Pasupuleti, and Jianfeng Chi. Large reasoning models learn better alignment from flawed thinking.CoRR, abs/2510.00938, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
InvThink: Premortem Reasoning for Safer Language Models
Yubin Kim, Taehan Kim, Eugene Park, Chunjong Park, Cynthia Breazeal, Daniel McDuff, and Hae Won Park. Invthink: Towards AI safety via inverse reasoning.CoRR, abs/2510.01569, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
A mousetrap: Fooling large reasoning models for jailbreak with chain of iterative chaos
Yang Yao, Xuan Tong, Ruofan Wang, Yixu Wang, Lujundong Li, Liang Liu, Yan Teng, and Yingchun Wang. A mousetrap: Fooling large reasoning models for jailbreak with chain of iterative chaos. InACL (Findings), pages 7837–7855. Association for Computational Linguistics, 2025
work page 2025
-
[25]
Haiquan Zhao, Chenhan Yuan, Fei Huang, Xiaomeng Hu, Yichang Zhang, An Yang, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin, Baosong Yang, Chen Cheng, Jialong Tang, Jiandong Jiang, Jianwei Zhang, Jijie Xu, Ming Yan, Minmin Sun, Pei Zhang, Pengjun Xie, Qiaoyu Tang, Qin Zhu, Rong Zhang, Shibin Wu, Shuo Zhang, Tao He, Tianyi Tang, Tingyu Xia, Wei Liao, Wei...
work page internal anchor Pith review arXiv 2025
-
[26]
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy P. Lillicrap, and Gregory Wayne. Experience replay for continual learning. InNeurIPS, pages 348–358, 2019
work page 2019
-
[27]
Marcin Andrychowicz, Dwight Crow, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay. InNIPS, pages 5048–5058, 2017
work page 2017
-
[28]
Bartoldson, Bhavya Kailkhura, and Cihang Xie
Zijun Wang, Haoqin Tu, Yuhan Wang, Juncheng Wu, Jieru Mei, Brian R. Bartoldson, Bhavya Kailkhura, and Cihang Xie. STAR-1: safer alignment of reasoning llms with 1k data.CoRR, abs/2504.01903, 2025
-
[29]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David A. Forsyth, and Dan Hendrycks. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. InICML. OpenReview.net, 2024
work page 2024
-
[30]
Weiyang Guo, Zesheng Shi, Zhuo Li, Yequan Wang, Xuebo Liu, Wenya Wang, Fangming Liu, Min Zhang, and Jing Li. Jailbreak-r1: Exploring the jailbreak capabilities of llms via reinforcement learning.CoRR, abs/2506.00782, 2025
-
[31]
Kehua Feng, Keyan Ding, Jing Yu, Menghan Li, Yuhao Wang, Tong Xu, Xinda Wang, Qiang Zhang, and Huajun Chen. ERPO: advancing safety alignment via ex-ante reasoning preference optimization.CoRR, abs/2504.02725, 2025
-
[32]
Reasoning as an adaptive defense for safety.CoRR, abs/2507.00971, 2025
Taeyoun Kim, Fahim Tajwar, Aditi Raghunathan, and Aviral Kumar. Reasoning as an adaptive defense for safety.CoRR, abs/2507.00971, 2025. 12
-
[33]
Yi Zhang, An Zhang, XiuYu Zhang, Leheng Sheng, Yuxin Chen, Zhenkai Liang, and Xiang Wang. Alphaalign: Incentivizing safety alignment with extremely simplified reinforcement learning.CoRR, abs/2507.14987, 2025
-
[34]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InNAACL-HLT, pages 5377–5400. Association for Computational Linguistics, 2024
work page 2024
-
[35]
Or-bench: An over-refusal benchmark for large language models
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. Or-bench: An over-refusal benchmark for large language models. InICML. OpenReview.net, 2025
work page 2025
-
[36]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.CoRR, abs/2503.24290, 2025
work page internal anchor Pith review arXiv 2025
-
[37]
Safety tax: Safety alignment makes your large reasoning models less reasonable
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, Zachary Yahn, Yichang Xu, and Ling Liu. Safety tax: Safety alignment makes your large reasoning models less reasonable. CoRR, abs/2503.00555, 2025
-
[38]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Liangha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, and Nouha Dziri. Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models. InNeurIPS, 2024
work page 2024
-
[41]
A strongreject for empty jailbreaks
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, and Sam Toyer. A strongreject for empty jailbreaks. InNeurIPS, 2024
work page 2024
-
[42]
Zhexin Zhang, Junxiao Yang, Pei Ke, Shiyao Cui, Chujie Zheng, Hongning Wang, and Minlie Huang. Safe unlearning: A surprisingly effective and generalizable solution to defend against jailbreak attacks.CoRR, abs/2407.02855, 2024
-
[43]
Fortress: Frontier risk evaluation for national security and public safety
Christina Q. Knight, Kaustubh Deshpande, Ved Sirdeshmukh, Meher Mankikar, Scale Red Team, SEAL Research Team, and Julian Michael. FORTRESS: frontier risk evaluation for national security and public safety.CoRR, abs/2506.14922, 2025
-
[44]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InICLR. OpenReview.net, 2024
work page 2024
-
[45]
American invitational mathematics ex- amination (aime), February 2024
Mathematical Association of America. American invitational mathematics ex- amination (aime), February 2024. URL https://maa.org/math-competitions/ american-invitational-mathematics-examination-aime
work page 2024
- [46]
-
[47]
Are sparse autoencoders useful? a case study in sparse probing.arXiv preprint arXiv:2502.16681, 2025
Subhash Kantamneni, Joshua Engels, Senthooran Rajamanoharan, Max Tegmark, and Neel Nanda. Are sparse autoencoders useful? a case study in sparse probing.arXiv preprint arXiv:2502.16681, 2025
-
[48]
Next-guard: Training-free streaming safeguard without token-level labels, 2026
Junfeng Fang, Nachuan Chen, Houcheng Jiang, Dan Zhang, Fei Shen, Xiang Wang, Xiangnan He, and Tat-Seng Chua. Next-guard: Training-free streaming safeguard without token-level labels, 2026. URLhttps://arxiv.org/abs/2603.02219
-
[49]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: Llm-based input-output safeguard for human-ai conversations.CoRR, abs/2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Zilin Zhu, Chengxing Xie, Xin Lv, and slime Contributors. slime: An llm post-training framework for rl scaling. https://github.com/THUDM/slime, 2025. GitHub repository. Corresponding author: Xin Lv. A Experimental Setup A.1 Benchmarks A.1.1 Direct Harmful Benchmarks We conducted our experiments on direct harmful benchmarks to test the models’ defense capa...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.