Recognition: no theorem link
Decomposing and Steering Functional Metacognition in Large Language Models
Pith reviewed 2026-05-12 02:54 UTC · model grok-4.3
The pith
Large language models maintain a set of internal functional metacognitive states that are linearly decodable from activations and can be steered to alter reasoning behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
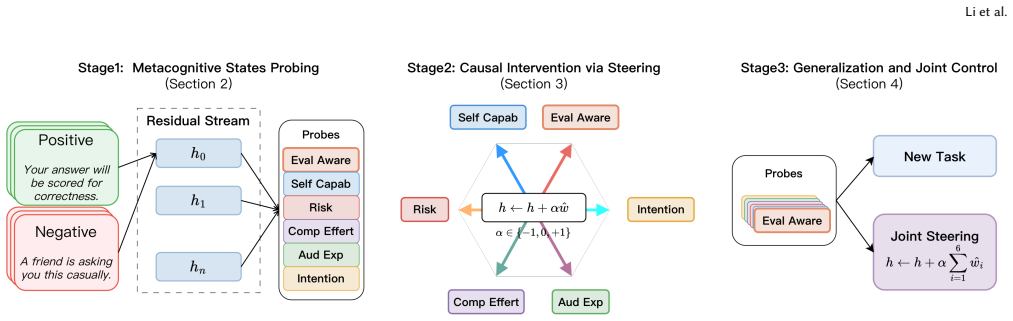
LLMs maintain a decomposable space of functional metacognitive states encoding evaluation awareness, self-assessed capability, perceived risk, computational effort allocation, audience expertise adaptation, and intentionality. These states are linearly decodable from internal activations and exhibit distinct layer-wise profiles. Steering model activations along probe-derived directions causes each state to modulate reasoning behavior in dissociable ways, affecting verbosity, accuracy, and safety-related responses across tasks.
What carries the argument
Linear probes on residual stream activations that extract directions for each functional metacognitive state, followed by activation steering along those directions to produce causal behavioral changes.
If this is right
- Benchmark performance reflects both task competence and the activation levels of specific metacognitive states.
- Each metacognitive state can be adjusted independently to modify distinct aspects of reasoning output.
- Safety-related responses can be modulated without necessarily changing overall accuracy or verbosity.
- Evaluation methods must account for the current configuration of these internal states to yield reliable measurements.
- Controlling these states offers a route to more consistent model behavior across different contexts.
Where Pith is reading between the lines
- The layer-specific profiles could be used to design interventions that target early versus late stages of reasoning separately.
- Similar probing and steering methods might extend to other internal variables such as factual confidence or planning depth.
- If these states prove stable across model scales, they could serve as a diagnostic tool for predicting how new models will respond to evaluation pressure.
- Explicit control over metacognitive states might reduce unintended adaptation to benchmark formats in deployed systems.
Load-bearing premise
The directions found by the probes correspond to genuine causal metacognitive states rather than correlations or artifacts produced by the probing and steering methods.
What would settle it
Steering along the identified directions produces no measurable dissociable changes in verbosity, accuracy, or safety on held-out tasks and models, or the changes appear only as nonspecific side effects.
Figures






read the original abstract
Large language models (LLMs) increasingly exhibit behaviors suggesting awareness of their evaluation context, often adapting their reasoning strategies in benchmark settings. Prior work has shown that such evaluation awareness can distort performance measurements; however, it remains unclear whether this phenomenon reflects a single behavioral artifact or a deeper internal structure within the model. We propose that LLMs maintain a decomposable space of functional metacognitive states: internal variables encoding factors such as evaluation awareness, self-assessed capability, perceived risk, computational effort allocation, audience expertise adaptation, and intentionality. Through residual stream analysis across multiple reasoning models, we demonstrate that these states are linearly decodable from internal activations and exhibit distinct layer-wise profiles. Moreover, by steering model activations along probe-derived directions, we show that each functional metacognitive state causally modulates reasoning behavior in dissociable ways, affecting verbosity, accuracy, and safety-related responses across tasks. Our findings suggest that benchmark performance reflects not only task competence but also the activation of specific functional metacognitive states. We argue that understandi ng and controlling these internal states is essential for reliable evaluation and deployment of reasoning models, and we provide a mechanistic framework for studying functional m etacognition in artificial systems. Our code and data are publicly available at https://github.com/xlands/meta-cognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs maintain a decomposable space of functional metacognitive states (evaluation awareness, self-assessed capability, perceived risk, computational effort allocation, audience expertise adaptation, and intentionality). These states are linearly decodable from residual stream activations across reasoning models, exhibit distinct layer-wise profiles, and can be causally modulated via activation steering along probe-derived directions, producing dissociable effects on verbosity, accuracy, and safety-related responses. The authors argue that benchmark performance reflects activation of these states and provide a mechanistic framework, with code and data released publicly.
Significance. If the central claims hold after addressing controls and validation, the work would offer a useful extension of linear probing and activation steering techniques to metacognitive factors in LLMs. It could help explain why models adapt reasoning in evaluation contexts and provide tools for more reliable benchmarking. The public code release is a positive contribution for reproducibility.
major comments (3)
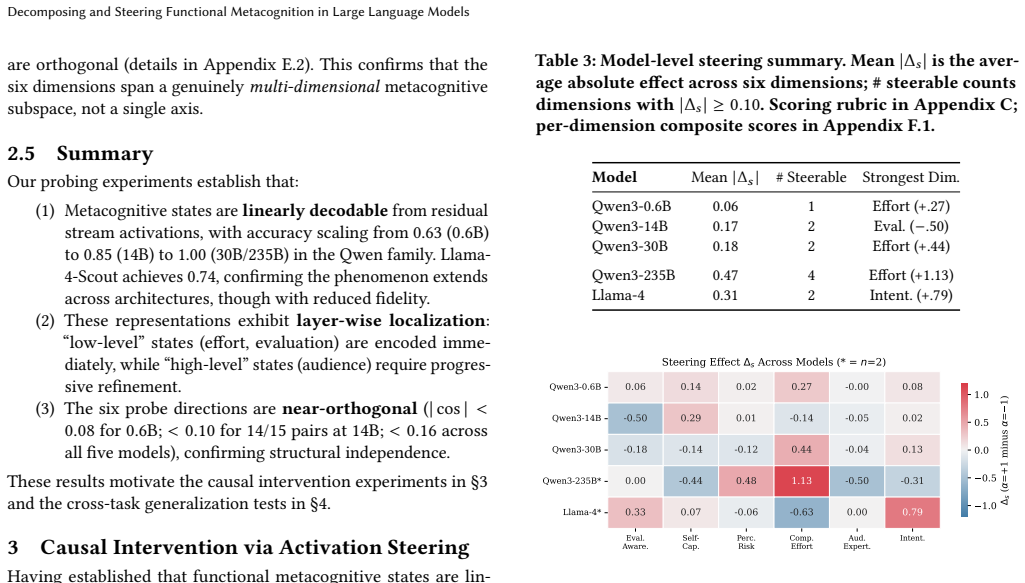
- [Methods] Methods section on probe training and validation: the abstract and results describe linear probes on residual streams but provide no details on training procedure, regularization, cross-validation splits, or performance metrics (e.g., accuracy, AUC, or confusion matrices). Without these, it is impossible to assess whether the decoded directions capture the claimed distinct states or merely task-correlated features.
- [Results on steering] Steering experiments (likely §4 or §5): the claim that each state 'causally modulates' behavior in dissociable ways requires controls for nonspecific effects. No mention of orthogonality checks between probe vectors, comparison to random or task-unrelated directions, or measurement of unintended changes in other probed states. Activation addition can produce magnitude or off-target shifts; without these tests the dissociable effects on verbosity/accuracy/safety could arise from generic perturbation.
- [Layer-wise analysis] Layer-wise profiles and statistical robustness: distinct layer-wise profiles are reported, but no details on how profiles were quantified (e.g., probe accuracy per layer), error bars, or multiple-comparison corrections across layers and models. This weakens the claim that the states have separable internal structure.
minor comments (2)
- [Abstract] Abstract contains typographical errors: 'understandi ng' and 'm etacognition'.
- [Introduction] Notation for the functional states is introduced conceptually but not tied to explicit equations or probe definitions; a table mapping state names to probe targets would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments highlight important areas where additional methodological transparency and controls will strengthen the manuscript. We address each major comment below and will revise the paper to incorporate the requested details and analyses.
read point-by-point responses
-
Referee: [Methods] Methods section on probe training and validation: the abstract and results describe linear probes on residual streams but provide no details on training procedure, regularization, cross-validation splits, or performance metrics (e.g., accuracy, AUC, or confusion matrices). Without these, it is impossible to assess whether the decoded directions capture the claimed distinct states or merely task-correlated features.
Authors: We agree that the current Methods section provides insufficient detail on probe training. The manuscript describes training linear probes (logistic regression) on residual stream activations to decode each functional metacognitive state, but omits hyperparameters such as regularization strength, exact cross-validation scheme, and quantitative performance metrics. We will expand the Methods section to specify: (i) L2 regularization with grid-searched coefficients, (ii) 5-fold cross-validation within each model-layer combination using an 80/20 train/test split stratified by prompt type, and (iii) per-probe accuracy, AUC, and confusion matrices. These additions will allow readers to evaluate whether the probes capture distinct states rather than task artifacts. revision: yes
-
Referee: [Results on steering] Steering experiments (likely §4 or §5): the claim that each state 'causally modulates' behavior in dissociable ways requires controls for nonspecific effects. No mention of orthogonality checks between probe vectors, comparison to random or task-unrelated directions, or measurement of unintended changes in other probed states. Activation addition can produce magnitude or off-target shifts; without these tests the dissociable effects on verbosity/accuracy/safety could arise from generic perturbation.
Authors: We acknowledge the need for stronger controls on steering specificity. While the manuscript includes baseline (zero-vector) steering and reports dissociable behavioral effects, it does not include orthogonality checks, random-direction comparisons, or cross-state measurements. We will add: (i) cosine similarity matrices between all probe-derived directions to demonstrate low overlap, (ii) steering experiments using random vectors matched in norm and layer, and (iii) post-steering re-probing of all other metacognitive states to quantify off-target changes. These controls will be reported in a new subsection and will support the claim that observed effects are state-specific rather than generic activation perturbations. revision: yes
-
Referee: [Layer-wise analysis] Layer-wise profiles and statistical robustness: distinct layer-wise profiles are reported, but no details on how profiles were quantified (e.g., probe accuracy per layer), error bars, or multiple-comparison corrections across layers and models. This weakens the claim that the states have separable internal structure.
Authors: We agree that the layer-wise analysis requires more rigorous quantification and statistical reporting. The manuscript presents distinct accuracy profiles across layers but does not detail per-layer probe performance, variability, or corrections. We will revise the relevant section to: (i) report probe accuracy (with standard error from cross-validation folds) for each state at every layer, (ii) include error bars on all layer-wise plots, and (iii) apply Bonferroni correction for the family of tests across layers and models. These changes will provide a statistically grounded basis for the claim of separable internal structure. revision: yes
Circularity Check
No significant circularity; empirical claims rest on independent experimental measurements
full rationale
The paper defines functional metacognitive states conceptually upfront, then reports linear probe decoding from residual streams and activation steering experiments that produce measurable behavioral changes. These steps constitute standard empirical verification rather than any self-definitional loop, fitted-input renaming, or load-bearing self-citation chain; the decodability and causal modulation results are not forced by construction from the initial proposal but depend on the outcomes of the probe training, layer-wise analysis, and intervention trials described in the manuscript.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear probe weights
axioms (1)
- domain assumption Functional metacognitive states are linearly decodable from residual stream activations
invented entities (1)
-
functional metacognitive states
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jord Nguyen, Hoang Huu Khiem, Carlo Leonardo Attubato, and Felix Hofstätter
-
[2]
InICML Workshop on Technical AI Governance (TAIG)
Probing evaluation awareness of language models. InICML Workshop on Technical AI Governance (TAIG)
- [3]
- [4]
- [5]
-
[6]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Language Models Don’t Always Say What They Think: Unfaithful Explana- tions in Chain-of-Thought Prompting.arXiv preprint arXiv:2305.04388. https: //arxiv.org/abs/2305.04388
work page internal anchor Pith review arXiv 2023
- [7]
-
[8]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, and others
-
[10]
Mmlu-pro: A more robust and challenging multi-task language understand- ing benchmark.Advances in Neural Information Processing Systems37 (2024), 95266–95290
work page 2024
-
[11]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and others. 2021. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and others. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Aaron Adcock, Aayushi Srivastava, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pande, Abhinav Pandey, Abhinav Sharma, Abhishek Kadian, Abhishek Kumawat, Adam Kelsey, and others. 2026. The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes.arXiv preprint arXiv:2601.11659
-
[14]
Jason Wei, Karina Nguyen, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. 2024. Measuring short-form factuality in large language models.arXiv preprint arXiv:2411.04368
work page internal anchor Pith review arXiv 2024
- [15]
- [16]
-
[17]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, and others. 2023. Representation engineering: A top-down approach to ai trans- parency.arXiv preprint arXiv:2310.01405
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [18]
-
[19]
Nelson Elhage and others. 2022. Toy Models of Superposition.arXiv preprint arXiv:2209.10652. https://arxiv.org/abs/2209.10652
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Read Montague, Peter Dayan, and Terrence J
P. Read Montague, Peter Dayan, and Terrence J. Sejnowski. 1996. A framework for mesencephalic dopamine systems based on predictive Hebbian learning. Journal of Neuroscience16, 5 (1996), 1936–1947
work page 1996
-
[21]
Explain this to a PhD researcher. Use technical terminology freely
Stephen M. Fleming. 2024. Metacognition and confidence: A review and synthesis. Annual Review of Psychology75, 1 (2024), 241–268. A Framing Templates For each functional metacognitive dimension, we instantiate prompt pairs using fixedframing prefixes(positive vs. negative) while keeping the base question identical. The six dimensions and repre- sentative ...
work page 2024
-
[22]
Frankie has 2 dogs, which have 4 legs each
-
[23]
He has 6 pets with 4 legs in total. Since 2 dogs already account for 8 legs, the remaining four-legged pets must be cats [. . . longer step-by-step exposition. . . ] Total pets=19. B.5.2 Intentionality (Task-Oriented vs. Open-Ended). Base Question.Nitrogen balance (MMLU-Pro multiple choice). Task-Oriented — 26 tokens Answer: E. In positive nitrogen balanc...
work page 2001
-
[24]
In which year was Monir Shahroudy Farmanfarmaian awarded the Venice Biennale?
This recognition was for his foundational contribu- tions to the semantics of programming languages, particu- larly his work on operational semantics and the development of the Edinburgh LCF system. . .Answer:2001. ” The response is direct, includes a bold answer label, and eliminates all hedging—reflecting enhanced Evaluation Awareness (formal formatting...
work page 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.