Recognition: 2 theorem links
· Lean TheoremAgentic AI Scientists Are Not Built For Autonomous Scientific Discovery
Pith reviewed 2026-05-12 02:46 UTC · model grok-4.3
The pith
Agentic AI scientists function as co-scientists but are not designed for autonomous scientific discovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Agentic AI scientists already function as co-scientists but are not built for autonomous scientific discovery. The authors identify four challenges that prevent autonomy: problem selection is influenced by the McNamara fallacy, agents rest on language models whose training data lack tacit procedural and failure knowledge from laboratory practice, preference optimization compresses output diversity toward consensus, and most scientific benchmarks assess single-turn prediction accuracy without feedback from physical experiments to the model. These issues are not resolved by scale or scaffolding and instead require revisiting fundamental design choices, including the use of scientific simu
What carries the argument
Four structural challenges that block the shift from co-scientist to autonomous discoverer: McNamara fallacy in problem selection, omission of tacit lab knowledge in LLM training data, consensus bias from preference optimization, and single-turn benchmarks lacking physical experiment feedback.
If this is right
- Scaling language models will not by itself produce autonomous discovery.
- Training agents with scientific simulations as verifiers can supply the missing closed-loop feedback.
- Persistent world models are required to track shifting objectives during real investigations.
- A centralized preregistration repository for AI-generated hypotheses would improve transparency.
- Development must be driven by scientific questions rather than tool capabilities.
Where Pith is reading between the lines
- Hybrid human-AI teams are likely to remain necessary until the four challenges receive targeted fixes.
- New benchmarks that simulate full cycles of hypothesis, experiment, and model update could accelerate progress.
- Specialized datasets capturing laboratory failures and procedures may be needed to fill training gaps.
- Preregistration practices for AI hypotheses could set standards for how the wider research community credits machine contributions.
Load-bearing premise
The four listed challenges are fundamental design flaws that cannot be resolved through scale, better scaffolding, or incremental improvements and instead require revisiting core architectural and training choices.
What would settle it
An agentic AI system that reaches autonomous scientific discovery solely through larger models and improved scaffolding, without changes that address problem-selection bias, missing tacit knowledge, output diversity compression, or the absence of physical-experiment feedback in benchmarks.
Figures


read the original abstract
A growing body of work pursues AI scientists capable of end-to-end autonomous scientific discovery. This position paper argues that although they already function as co-scientists, agentic AI scientists are not built for autonomous scientific discovery. We identify the following challenges in building and deploying autonomous AI scientists: (1) Problem selection is influenced by the McNamara fallacy; (2) Agents are built on large language models (LLMs) whose training corpora omit tacit procedural and failure knowledge of laboratory practice; (3) Preference optimisation during post-training compresses output diversity toward consensus; and (4) Most scientific benchmarks measure single-turn prediction accuracy and lack feedback from physical experiments back to the computational model. These challenges are not just questions of scale and scaffolding; they require revisiting fundamental design choices. To build truly autonomous AI scientists, we recommend the use of scientific simulations as verifiers for training, the design of persistent world models that represent the shifting objectives governing real investigations, the establishment of a centralized preregistration repository for all AI-generated hypotheses, and application driven by scientific need rather than tool affordance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a position paper arguing that agentic AI scientists, while already functioning as co-scientists, are not built for autonomous scientific discovery. It identifies four challenges: (1) problem selection influenced by the McNamara fallacy, (2) LLMs omitting tacit procedural and failure knowledge from laboratory practice in their training corpora, (3) preference optimization compressing output diversity toward consensus, and (4) scientific benchmarks focusing on single-turn prediction without feedback from physical experiments. The paper asserts these are not merely issues of scale or scaffolding but require revisiting fundamental design choices, and recommends scientific simulations as verifiers, persistent world models for shifting objectives, a centralized preregistration repository for AI-generated hypotheses, and development driven by scientific need rather than tool affordance.
Significance. If the central argument holds, the paper could usefully steer research in AI for science by emphasizing structural limitations in current LLM-based agentic systems and proposing concrete architectural and procedural shifts. The synthesis of challenges and the forward-looking recommendations provide a useful framing for the field. As a position paper without empirical data, formal derivations, or controlled comparisons, its significance rests on the logical strength of the claims rather than new evidence.
major comments (2)
- [Abstract] Abstract and the section outlining the four challenges: the core claim that the challenges 'are not just questions of scale and scaffolding' and instead 'require revisiting fundamental design choices' is load-bearing for the title and thesis but is asserted without analysis demonstrating why incremental mitigations (e.g., curated datasets or retrieval for tacit knowledge, or hybrid human-AI loops for benchmarks) must fail. No case analysis of existing attempts or structural reasons for insufficiency is provided.
- [Recommendations] The recommendations section: the proposals (simulations as verifiers, persistent world models, preregistration) are offered as solutions but without explicit mapping showing how each directly resolves the four listed challenges or why they necessitate changes beyond post-training and scaffolding.
minor comments (2)
- The manuscript would be strengthened by adding one or two concrete examples from existing agentic AI scientist systems (e.g., specific failures in problem selection or diversity) to illustrate each challenge.
- Consider adding references to related position papers or empirical studies on AI in scientific discovery to situate the argument within the broader literature.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our position paper. The feedback highlights opportunities to strengthen the logical support for our claims. We address each major comment below and commit to revisions that enhance clarity without altering the core thesis.
read point-by-point responses
-
Referee: [Abstract] Abstract and the section outlining the four challenges: the core claim that the challenges 'are not just questions of scale and scaffolding' and instead 'require revisiting fundamental design choices' is load-bearing for the title and thesis but is asserted without analysis demonstrating why incremental mitigations (e.g., curated datasets or retrieval for tacit knowledge, or hybrid human-AI loops for benchmarks) must fail. No case analysis of existing attempts or structural reasons for insufficiency is provided.
Authors: We agree that the manuscript would be strengthened by more explicit reasoning on why incremental mitigations are structurally insufficient. As a position paper, the argument draws from the inherent properties of each challenge—for example, tacit laboratory knowledge is experiential and non-textual, limiting the effectiveness of curation or retrieval alone. To address this, we will revise the challenges section to include targeted case analyses of recent efforts (such as retrieval-augmented agents in experimental domains) and articulate the structural barriers, including the absence of closed-loop physical feedback. This addition will better substantiate the need for fundamental design changes. revision: yes
-
Referee: [Recommendations] The recommendations section: the proposals (simulations as verifiers, persistent world models, preregistration) are offered as solutions but without explicit mapping showing how each directly resolves the four listed challenges or why they necessitate changes beyond post-training and scaffolding.
Authors: We concur that clearer mappings are needed to connect the proposals directly to the challenges. In the revised manuscript, we will expand the recommendations section with structured paragraphs (or a summary table) explicitly linking each proposal: simulations as verifiers target the single-turn benchmark limitation and lack of physical feedback; persistent world models address shifting objectives and the McNamara fallacy through dynamic representation; preregistration counters diversity compression from preference optimization and biased problem selection. We will also explain why these require architectural and procedural redesigns beyond post-training, as they involve new infrastructure and interaction paradigms not achievable through scaling or scaffolding alone. revision: yes
Circularity Check
No circularity: position paper relies on external observations, not self-referential reductions
full rationale
The paper is a position statement that identifies four challenges in agentic AI scientists and asserts they require fundamental redesign rather than scale or scaffolding. No equations, fitted parameters, predictions, uniqueness theorems, or ansatzes appear in the provided text or abstract. The argument chain consists of general observations about LLMs, benchmarks, and scientific practice, none of which reduce to the paper's own inputs by construction. Self-citations are not load-bearing here, and the central claim is presented as an opinion rather than a derived result equivalent to its premises.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs' training corpora omit tacit procedural and failure knowledge of laboratory practice
- domain assumption Preference optimisation during post-training compresses output diversity toward consensus
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify the following challenges... (1) Problem selection is influenced by the McNamara fallacy; (2) Agents are built on large language models (LLMs) whose training corpora omit tacit procedural and failure knowledge...
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Preference optimisation during post-training compresses output diversity toward consensus
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ISSN 0935-9648, 1521-4095. doi: 10.1002/adma.202413523. Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J. Szostkiewicz, Jon M. Laurent, Muhammed T. Razzak, Andrew D. White, Michaela M. Hinks, and Samuel G. Rodriques. Robin: A multi-agent system for automating scientific discovery, May 2025. Juraj Gottweis, Wei-Hung Weng, Alexan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1002/adma.202413523 2025
-
[2]
ISSN 1476-4687. doi: 10.1038/s41586-024-07566-y. Joseph P. Simmons, Leif D. Nelson, and Uri Simonsohn. False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant.Psychological Science, 22(11):1359–1366, 2011. ISSN 1467-9280. doi: 10.1177/0956797611417632. Leonid Teytelman, Alexei Stoliartch...
-
[3]
doi: 10.1371/journal.pbio.1002538
ISSN 1545-7885. doi: 10.1371/journal.pbio.1002538. Savannah Thais, Roberto Trotta, Nathan Suri, Emily Sullivan, Viyan Poonamallee, Tanaporn Na Narong, Rupert Croft, and Nicole Hartman. AI for Science Needs Scientific Alignment. https://philsci-archive.pitt.edu/28994/, March 2026. Emanuel Todorov, Tom Erez, and Yuval Tassa. MuJoCo: A physics engine for mod...
-
[4]
Kai Yuanqing Xiao, Logan Engstrom, Andrew Ilyas, and Aleksander Madry
doi: 10.1007/s11192-020-03488-4. Kai Yuanqing Xiao, Logan Engstrom, Andrew Ilyas, and Aleksander Madry. Noise or Signal: The Role of Image Backgrounds in Object Recognition. InInternational Conference on Learning Representations, October 2020. Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The...
-
[5]
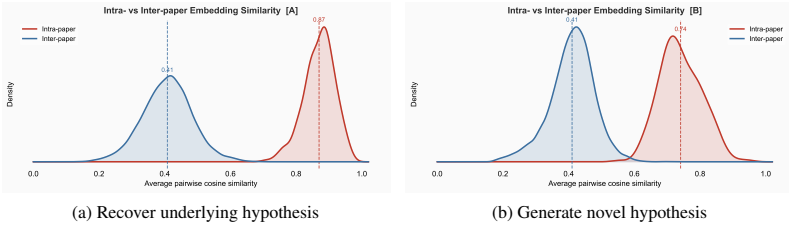
GPT-5 We considered a dataset of 50 publications from the 2025 NeurIPS AI4Mat track (full list in A.1) of shared interest to the AI and materials science communities. We define 2 tasks:
work page 2025
-
[6]
Recovering the underlying hypothesis given a summary of the experiments in a publication
-
[7]
Proposing novel hypotheses to extend the core findings given the full text of a publication. In the first task, models received a summary of experiments for each paper and were asked to recover the underlying hypothesis, an interpretive task with a determinate answer serving as a convergence baseline. In the second, models received the full paper text and...
work page 2025
-
[8]
Data-driven prediction of polymer surface adhesion using high-throughput MD and hybrid network models https://openreview.net/pdf?id=0SPoKR8Xrk
-
[9]
STR-Bamba: Multimodal Molecular Textual Representation Encoder-Decoder Foundation Model https://openreview.net/pdf?id=0uWNuJ1xtz
-
[10]
Universally Converging Representations of Matter Across Scientific Foundation Models https://openreview.net/pdf?id=12ZCZVKm7r
-
[11]
Preference Learning from Physics-Based Feedback: Tuning Language Models to Design BCC/B2 Superalloys https://openreview.net/pdf?id=24lzMGlvnq
-
[12]
Pharmacophore-Guided Generative Design of Novel Drug-Like Molecules https://openreview.net/pdf?id=35aDuh7ndX
-
[13]
Cross Modal Predictive Architecture for Material Property Prediction https://openreview.net/pdf?id=3WZkuWlzmN
-
[14]
Language Model Enabled Structure Prediction from Infrared Spectra of Mixtures https://openreview.net/pdf?id=3pAVbjWMXW
-
[15]
ML-Driven Discovery of Metastable States https://openreview.net/pdf?id=4U2k4uw43B
-
[16]
Universal Machine Learning Interatomic Potentials Enable Accurate Metal-Organic Frame- work Molecular Modeling https://openreview.net/pdf?id=4Xh9oL5rH0
-
[17]
GEOM-Drugs Revisited: Toward More Chemically Accurate Benchmarks for 3D Molecule Generation https://openreview.net/pdf?id=57YLCp7n2V
-
[18]
Generalizable Prediction of Mixture Etching Rates Using Graph Neural Networks https://openreview.net/pdf?id=5OsnDm1CdX
-
[19]
Foundation Models Enabling Multi-Scale Battery Materials Discovery: From Molecules to Devices https://openreview.net/pdf?id=6pjxodugzO
-
[20]
GAP: Guided Diffusion for A Priori Transition State Sampling https://openreview.net/pdf?id=7brF4sMQq3
-
[21]
Task Alignment Outweighs Framework Choice in Scientific LLM Agents https://openreview.net/pdf?id=7cbwuA5k0T
-
[22]
A Computational Workflow for Cost-Effective Synthesis of Inorganic Materials: Integrating Thermodynamics, Cellular Automata, Machine Learning, and Commercial Databases https://openreview.net/pdf?id=7l75CbxtmC
-
[23]
MatPROV: A Provenance Graph Dataset of Material Synthesis Extracted from Scientific Literature https://openreview.net/pdf?id=8JFITrNy3K
-
[24]
Accelerated Inorganic Materials Design with Generative AI Agents https://openreview.net/pdf?id=9JSO4qf1RQ
-
[25]
The Loss Landscape of XRD-Based Structure Optimization Is Too Rough for Gradient Descent https://openreview.net/pdf?id=A21WF9M1Um
-
[26]
AI-Guided Design and Discovery of Silicon-Based Anode Materials for Lithium-Ion Batter- ies https://openreview.net/pdf?id=AQkGpEMGWA 18
-
[27]
LLM Agents for Knowledge Discovery in Atomic Layer Processing https://openreview.net/pdf?id=Bg4Hn9Qq3w
-
[28]
Towards Dynamic Benchmarks for Autonomous Materials Discovery https://openreview.net/pdf?id=Cfj7uBu5dy
-
[29]
Surrogate Modeling for the Design of Optimal Lattice Structures using Tensor Completion https://openreview.net/pdf?id=Ciw6DbDa4U
-
[30]
Scalable Low-Energy Molecular Conformer Generation with Quantum Mechanical Accuracy https://openreview.net/pdf?id=Ei3eF8B8XH
-
[31]
Towards End-to-End Learning of Protein Structure Prediction and Structure-based Sequence Design https://openreview.net/pdf?id=EuACaJblk4
-
[32]
Training Speedups via Batching for Geometric Learning: An Analysis of Static and Dynamic Algorithms https://openreview.net/pdf?id=Gzf8k2wPdF
-
[33]
Closed-loop, Machine Learning-Driven Optimization of Reactor Yields in Reactive Carbon Electrolyzers https://openreview.net/pdf?id=InZczCC8X1
-
[34]
Benchmarking Agentic Systems in Automated Scientific Information Extraction with ChemX https://openreview.net/pdf?id=YKxwBMK8Nl
-
[35]
Accurate Band Gap Prediction in Porous Materials using∆-Learning https://openreview.net/pdf?id=a3LKICpDO2
-
[36]
Accelerated Discovery of High-Performance Polyamines for Solid-State Direct CO2 Capture via Efficient Simulations and Bayesian Optimization https://openreview.net/pdf?id=aECXy5Jgm4
-
[37]
Efficient Nudged Elastic Band Method using Neural Network Bayesian Algorithm Execution https://openreview.net/pdf?id=acfR6umMJt
-
[38]
A Chemically Grounded Evaluation Framework for Generative Models in Materials Discov- ery https://openreview.net/pdf?id=amn6lBDjXm
-
[39]
NaviDiv: A Comprehensive Tool for Monitoring Chemical Diversity in Generative Molecu- lar Design https://openreview.net/pdf?id=auRe7zr32I
-
[40]
When Forces Disagree: A Data-Free Fast Uncertainty Estimate for Direct-Force Pre-trained Neural Network Potentials https://openreview.net/pdf?id=bmgU7yWBeC
-
[41]
AMDEN: Amorphous Materials DEnoising Network https://openreview.net/pdf?id=cEgjPFdLvl
-
[42]
CHROMA: Conversational Human-Readable Optical Multilayer Assembly for Natural Language-Driven Inverse Design of Structural Coloration https://openreview.net/pdf?id=cFTvHHXvt6
-
[43]
Coupling Language Models with Physics-based Simulation for Synthesis of Inorganic Materials https://openreview.net/pdf?id=ctyy8EJYQj
-
[44]
An Effective Machine Learning Frame for Materials Discovery Structured by a Chemical Concept https://openreview.net/pdf?id=dEtRvi7G5i
-
[45]
Accelerating Material Discovery for Metal Organic Frameworks using Large Language Models https://openreview.net/pdf?id=dmeAH1hVR8
-
[46]
Concept-based Steering of Large Language Models for Conditional Molecular Generation https://openreview.net/pdf?id=e8bcQehZ15 19
-
[47]
An Exploration of Dataset Bias in Single-Step Retrosynthesis Prediction https://openreview.net/pdf?id=eUiZg9uUt4
-
[48]
Benchmarking Knowledge Transfer Methods in De Novo Materials Discovery https://openreview.net/pdf?id=egi8g2U0ZX
-
[49]
Towards Fully Automated Molecular Simulations: Multi-Agent Framework for Simulation Setup and Force Field Extraction https://openreview.net/pdf?id=enQdbinvNd
-
[50]
SAM-EM: Real-Time Segmentation for Automated Liquid Phase Transmission Electron Microscopy https://openreview.net/pdf?id=farKrjdsIH
-
[51]
CompGen: A Conditional Generation Framework for Inverse Composition Design of Catalytic Surfaces https://openreview.net/pdf?id=g6Sj1OFjAu
-
[52]
Physics-Constrained Diffusion for Lightweight Composite Material Design https://openreview.net/pdf?id=gifMFKvAl5
-
[53]
XDIP: A Curated X-ray Absorption Spectrum Dataset for Iron-Containing Proteins https://openreview.net/pdf?id=hFzjgQzoVU
-
[54]
Machine Learning Interatomic Potentials: Library for Efficient Training, Model Develop- ment and Simulation of Molecular Systems https://openreview.net/pdf?id=hQCdhenqre
-
[55]
Semi-Supervised Learning for Molecular Graphs via Ensemble Consensus https://openreview.net/pdf?id=hk6iX4mg3B
-
[56]
Emergent Pose-Invariance in 3D Molecular Representations via Multimodal Learning https://openreview.net/pdf?id=iFHaZzs6Kz
-
[57]
Bridging Data-Rich and Data-Poor Domains on Lithium-Ion Battery via Scanning Electron Microscopic Data Through Convolutional Neural Network Transfer Learning https://openreview.net/pdf?id=j3aOU8Ahue 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.