Recognition: no theorem link
Learning to Explore: Scaling Agentic Reasoning via Exploration-Aware Policy Optimization
Pith reviewed 2026-05-13 00:54 UTC · model grok-4.3
The pith
LLM agents learn to explore selectively by estimating how actions reduce future uncertainty via variational rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
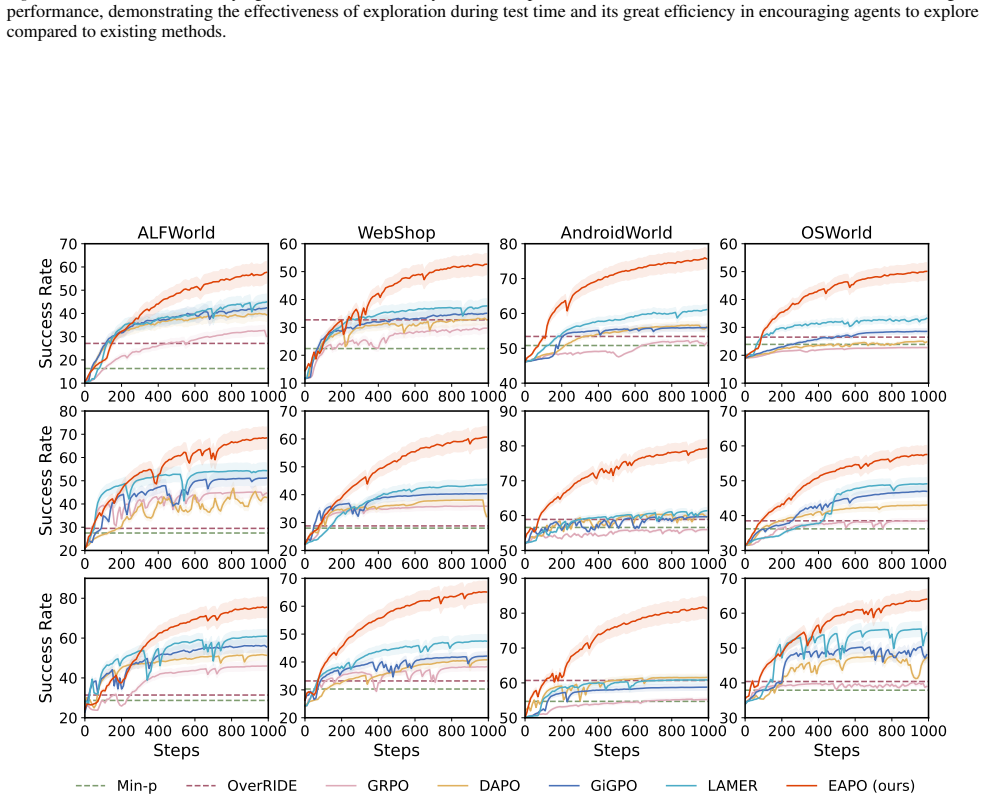
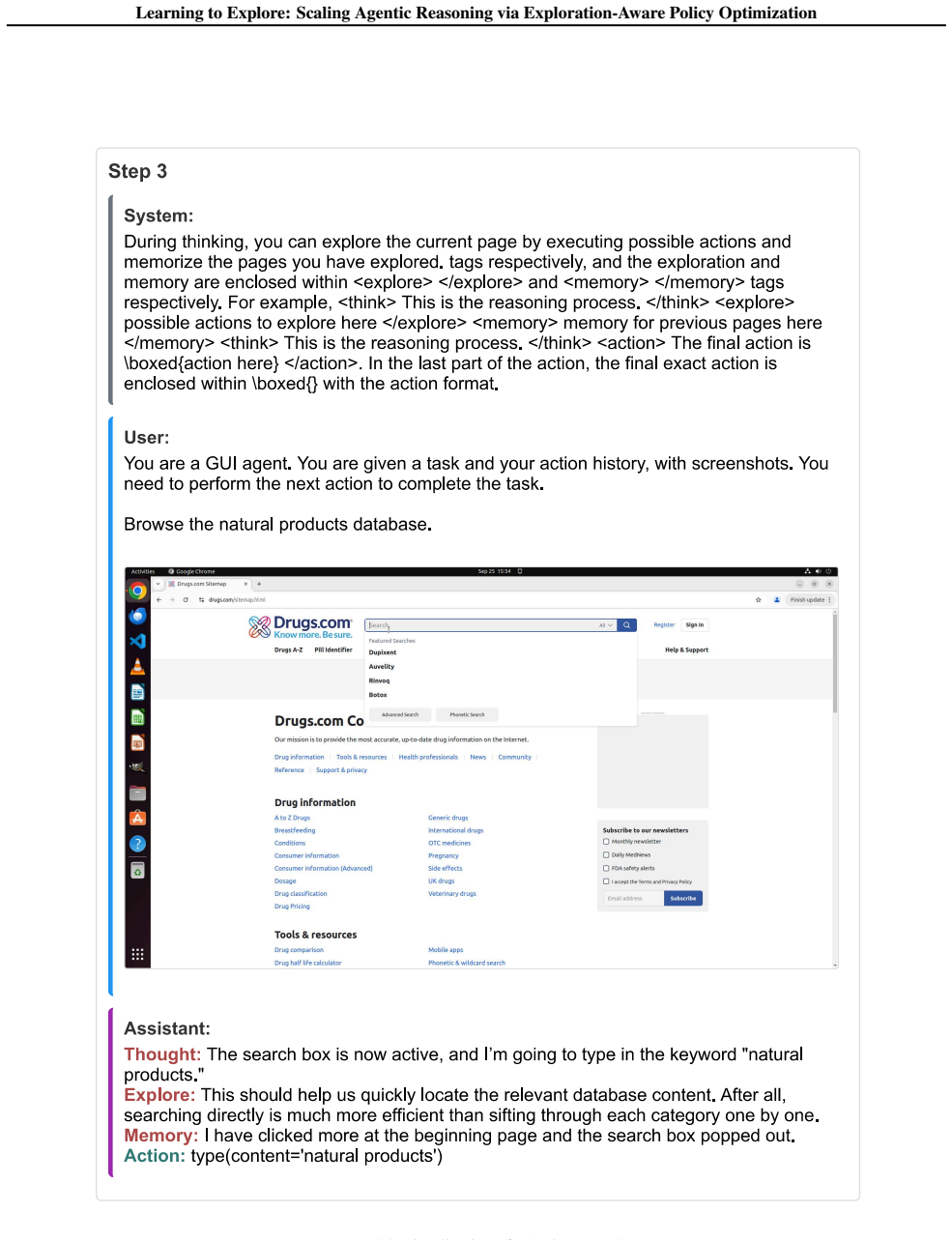
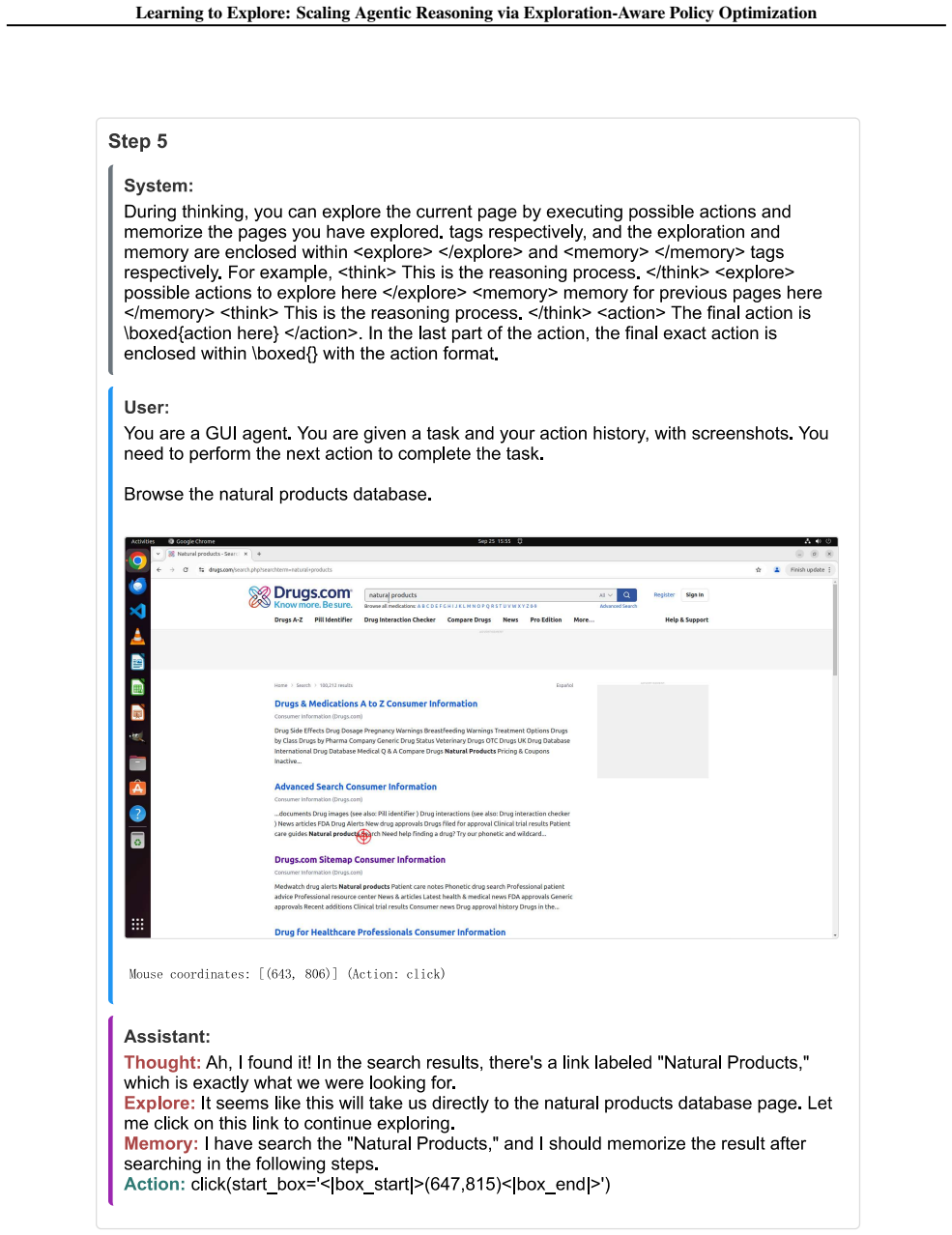
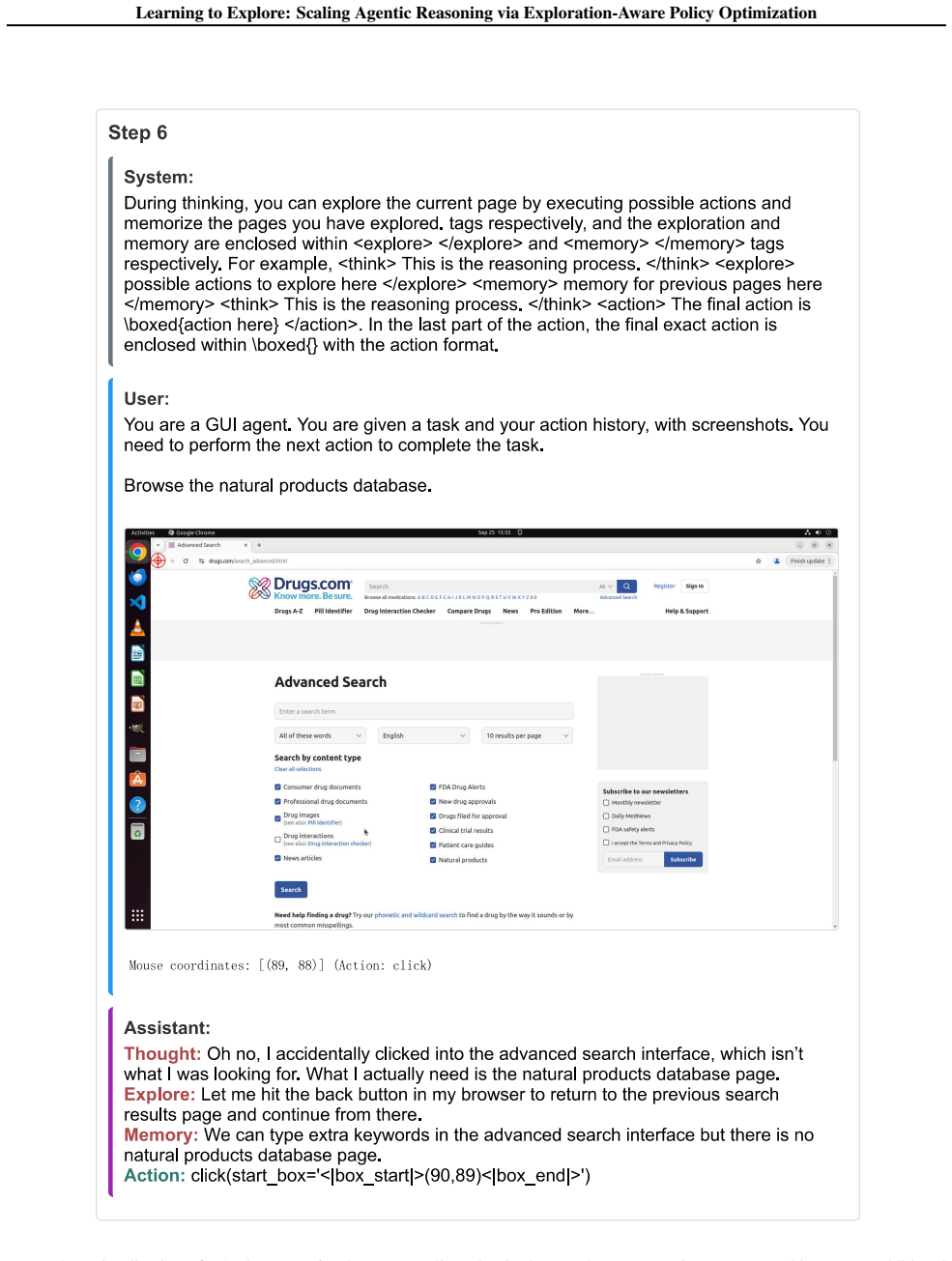
The central claim is that an exploration-aware reinforcement learning framework enables LLM agents to adaptively explore only when uncertainty is high. This is achieved through a fine-grained reward function via variational inference that explicitly evaluates exploratory actions by estimating their potential to improve future decision-making, together with an exploration-aware grouping mechanism that separates exploratory actions from task-completion actions during optimization, allowing agents to target informational gaps and transition to execution as soon as the task context is clear, with consistent empirical improvements across text-based and GUI-based agent benchmarks.
What carries the argument
The fine-grained reward function obtained via variational inference that scores exploratory actions by their estimated effect on future decision quality, used together with an exploration-aware grouping mechanism during policy optimization.
If this is right
- Agents achieve higher success rates on text-based and GUI-based benchmarks by limiting exploration to moments of genuine uncertainty.
- The policy learns to transition from information-gathering to direct execution once task context becomes sufficiently clear.
- Optimization no longer mixes exploratory and task-completion signals, allowing each type of action to be reinforced on its own terms.
- Overall agent trajectories shorten because unneeded exploratory steps are avoided once the variational estimate indicates low remaining value.
Where Pith is reading between the lines
- The same variational grouping idea could be tested in non-LLM agent settings such as robotic control or game environments where uncertainty estimation is also costly.
- If the reward estimates remain reliable at longer horizons, the method might reduce total compute spent on failed long-horizon explorations in real deployments.
- A natural next measurement is whether the learned policy generalizes to new task distributions without retraining the variational estimator.
- The separation of exploration and execution signals may interact usefully with other intrinsic-motivation techniques already used in reinforcement learning.
Load-bearing premise
The variational inference step can produce unbiased estimates of how much an exploratory action will improve later decisions without itself depending on the very exploration it is trying to regulate.
What would settle it
Run the method on a held-out set of agent tasks while ablating the variational reward term; if performance gains disappear or exploratory actions no longer correlate with measured uncertainty reduction, the central mechanism is not working as claimed.
Figures


















read the original abstract
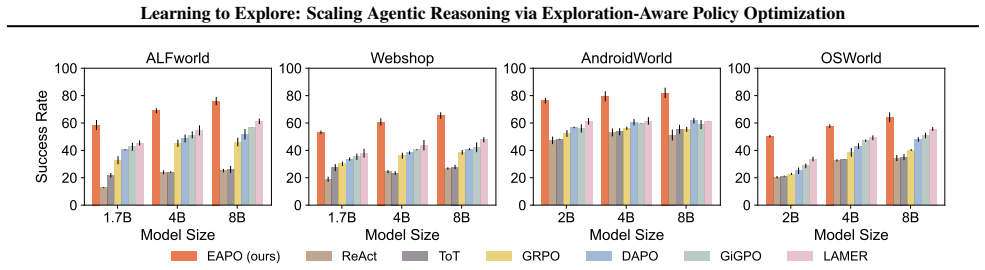
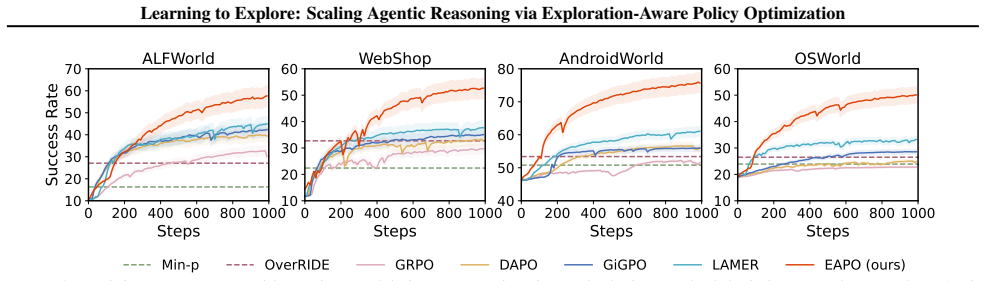
Recent advancements in agentic test-time scaling allow models to gather environmental feedback before committing to final actions. A key limitation of existing methods is that they typically employ undifferentiated exploration strategies, lacking the ability to adaptively distinguish when exploration is truly required. In this paper, we propose an exploration-aware reinforcement learning framework that enables LLM agents to adaptively explore only when uncertainty is high. Our method introduces a fine-grained reward function via variational inference that explicitly evaluates exploratory actions by estimating their potential to improve future decision-making, together with an exploration-aware grouping mechanism that separates exploratory actions from task-completion actions during optimization. By targeting informational gaps, this design allows agents to explore selectively and transition to execution as soon as the task context is clear. Empirically, we demonstrate that our approach achieves consistent improvements across a range of challenging text-based and GUI-based agent benchmarks. Code is available at https://github.com/HansenHua/EAPO-ICML26 and models are available at https://huggingface.co/hansenhua/EAPO-ICML26.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
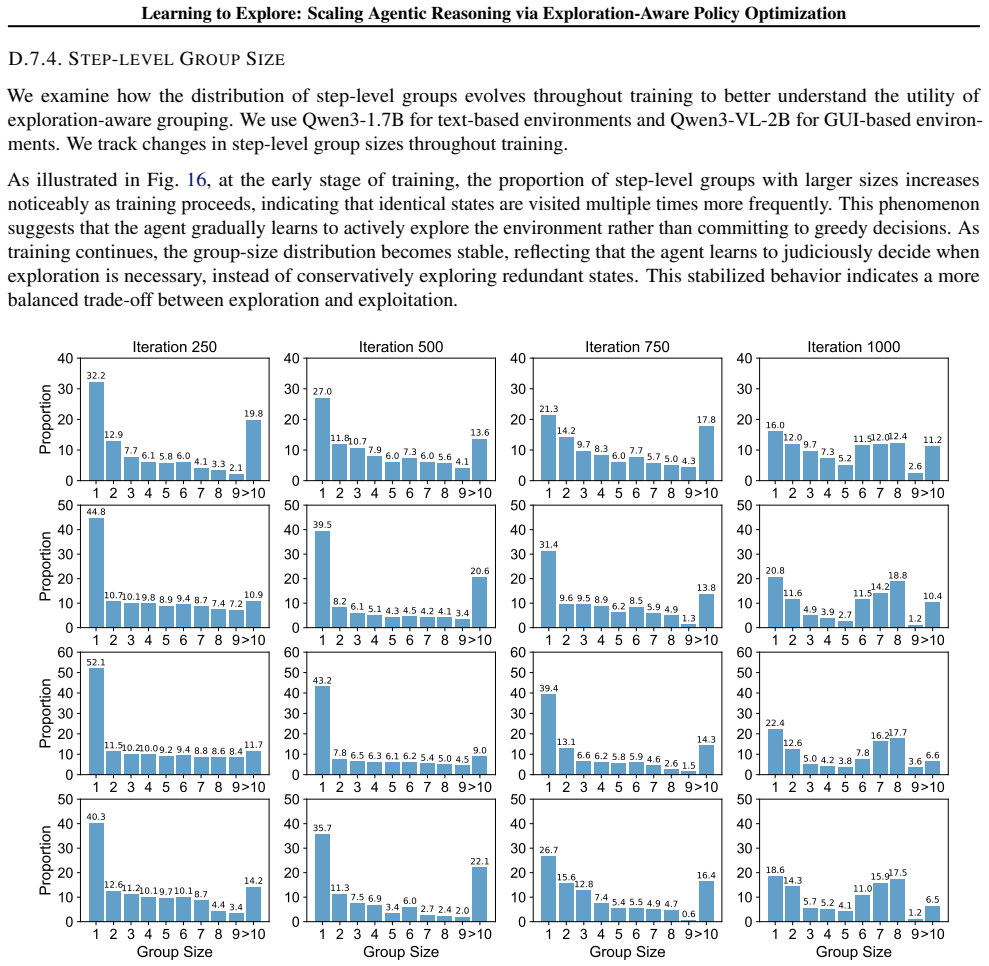
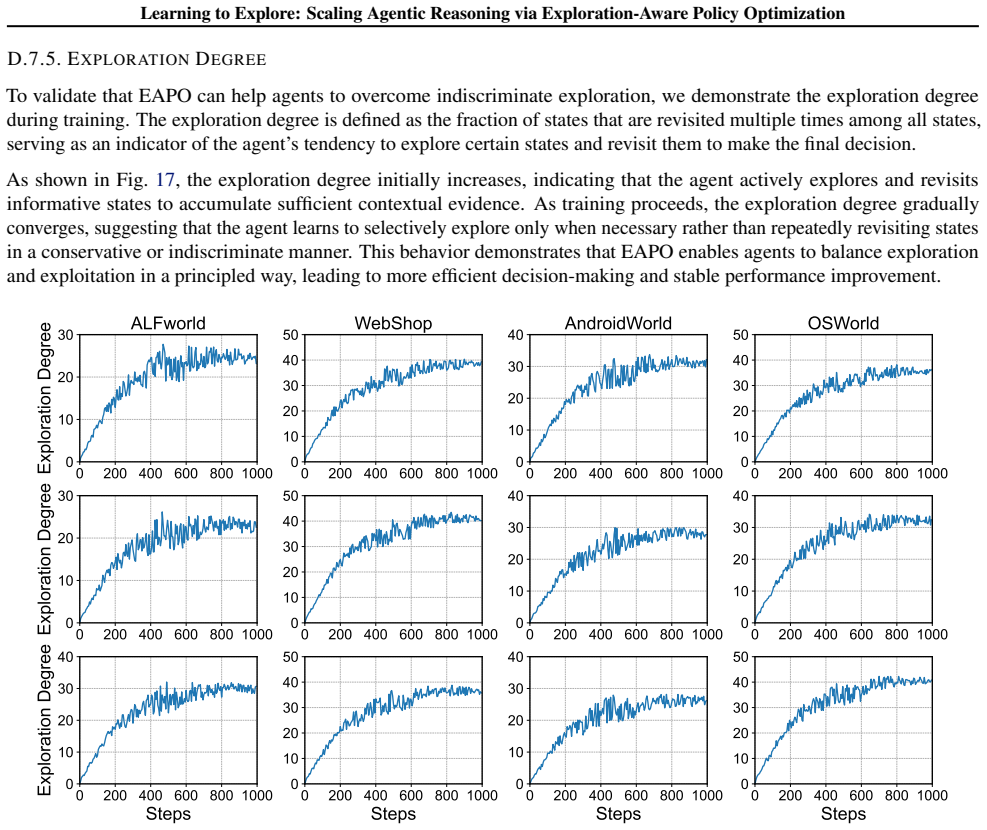
Summary. The paper proposes an exploration-aware RL framework for LLM agents that adaptively explores only under high uncertainty. It introduces a fine-grained reward defined via variational inference that scores exploratory actions by their estimated improvement to future decision-making, paired with an exploration-aware grouping mechanism that separates exploratory actions from task-completion actions during policy optimization. The method is claimed to yield consistent gains on text-based and GUI-based agent benchmarks.
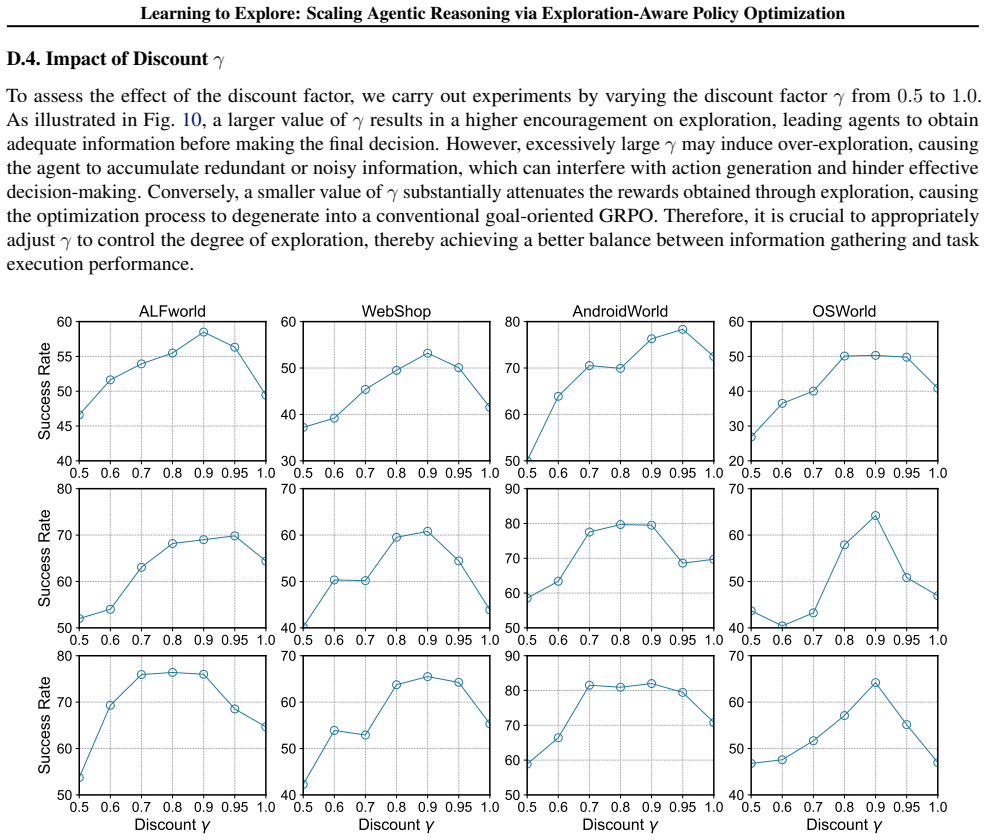
Significance. If the variational inference procedure can be shown to produce unbiased estimates of the value of information-gathering actions without circular dependence on the very exploratory trajectories it seeks to encourage, the approach would offer a principled way to scale agentic reasoning beyond undifferentiated exploration. The grouping mechanism and empirical results on challenging benchmarks would then constitute a meaningful contribution to test-time scaling for agents.
major comments (2)
- [§3 (Method)] The central construction relies on a variational inference procedure to define the exploratory reward (abstract and §3). The skeptic correctly notes that the ELBO-style objective for estimating future improvement from an exploratory action typically requires either sufficient exploratory data or strong parametric assumptions; the manuscript does not demonstrate that the chosen variational family or data-collection policy satisfies this requirement, leaving open the possibility that the reward underestimates exploration precisely in the low-uncertainty regimes the method claims to handle adaptively.
- [§4 (Optimization)] The exploration-aware grouping mechanism is presented as breaking the dependence between the VI objective and the policy being optimized (§4). However, the paper does not provide a formal argument or ablation showing that the separation prevents the variational posterior from inheriting bias from the current policy's limited exploration; without this, the claim that agents 'transition to execution as soon as the task context is clear' rests on an unverified assumption.
minor comments (2)
- The abstract states that 'models are available at https://huggingface.co/hansenhua/EAPO-ICML26', but the manuscript does not specify the exact base model, training hyperparameters, or number of seeds used for the reported benchmark improvements.
- [§3] Notation for the variational parameters and the grouping indicator variable is introduced without an explicit table or appendix listing all symbols, making it difficult to trace the reward definition through the optimization equations.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which help clarify important aspects of our variational inference and grouping mechanisms. We address each major comment below and commit to revisions that strengthen the manuscript's theoretical and empirical grounding.
read point-by-point responses
-
Referee: [§3 (Method)] The central construction relies on a variational inference procedure to define the exploratory reward (abstract and §3). The skeptic correctly notes that the ELBO-style objective for estimating future improvement from an exploratory action typically requires either sufficient exploratory data or strong parametric assumptions; the manuscript does not demonstrate that the chosen variational family or data-collection policy satisfies this requirement, leaving open the possibility that the reward underestimates exploration precisely in the low-uncertainty regimes the method claims to handle adaptively.
Authors: We appreciate the referee's observation on the requirements for reliable ELBO-based estimation. Our method uses variational inference to score exploratory actions by their estimated value of information, with data collected under the evolving policy. While empirical results on benchmarks indicate effective adaptive behavior, we acknowledge the manuscript lacks explicit validation of the variational family and policy in low-uncertainty settings. We will revise §3 to discuss the assumptions underlying our variational approximation and add an ablation in §5 that tests reward estimation accuracy across controlled uncertainty levels with alternative variational families and data policies. This will directly address the potential for underestimation. revision: yes
-
Referee: [§4 (Optimization)] The exploration-aware grouping mechanism is presented as breaking the dependence between the VI objective and the policy being optimized (§4). However, the paper does not provide a formal argument or ablation showing that the separation prevents the variational posterior from inheriting bias from the current policy's limited exploration; without this, the claim that agents 'transition to execution as soon as the task context is clear' rests on an unverified assumption.
Authors: We agree that a formal argument and supporting ablation would strengthen the decoupling claim. The grouping mechanism separates exploratory trajectories (used for the VI reward) from task-completion trajectories during policy optimization, with the VI network trained on a distinct set of exploratory rollouts. To address the concern, we will add a concise formal sketch in §4 showing that the separation conditions the variational posterior solely on exploration-specific data collected via a behavior policy independent of the current policy's exploitation bias. We will also include an ablation in §5 comparing grouped versus joint optimization, quantifying bias reduction in the estimated rewards. These additions will better substantiate the adaptive transition to execution. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The abstract describes a reward function constructed via variational inference to score exploratory actions by their estimated future value, paired with a grouping mechanism for optimization. No equations, self-citations, or derivation steps are supplied that reduce this construction to its own inputs by definition, rename a fitted parameter as a prediction, or import uniqueness via author-overlapping citations. The variational procedure is presented as an independent modeling choice whose reliability is left to empirical demonstration rather than enforced by tautology. The overall framework therefore does not collapse into a self-referential loop on inspection of the given material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. Claude 3.7 sonnet and claude code. Technical report, Anthropic, 2025a. URL https://www. anthropic.com/news/claude-3-7-sonnet . System Card. Anthropic. Claude-4 sonnet. Technical report, An- thropic, 2025b. URL https://www.anthropic. com/news/claude-4. System Card. Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., G...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Research: Learning to reason with search for llms via reinforcement learning
Chen, H., Fang, Z., Singla, Y ., and Dredze, M. Benchmark- ing large language models on answering and explaining challenging medical questions. InConference of the Nations of the Americas Chapter of the Association for Computational Linguistics, pp. 3563–3599, 2025a. Chen, M., Sun, L., Li, T., Sun, H., Zhou, Y ., Zhu, C., Wang, H., Pan, J. Z., Zhang, W., ...
-
[3]
Fu, T., Su, A., Zhao, C., Wang, H., Wu, M., Yu, Z., Hu, F., Shi, M., Dong, W., Wang, J., et al. Mano technical report. arXiv preprint arXiv:2509.17336,
-
[4]
Guo, D., Wu, F., Zhu, F., Leng, F., Shi, G., Chen, H., Fan, H., Wang, J., Jiang, J., Wang, J., et al. Seed1.5-vl technical report.arXiv preprint arXiv:2505.07062, 2025a. Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforce- ment learning.a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Kong, Q., Zhang, X., Yang, Z., Gao, N., Liu, C., Tong, P., Cai, C., Zhou, H., Zhang, J., Chen, L., et al. MobileWorld: Benchmarking autonomous mobile agents in agent-user interactive, and mcp-augmented environments.arXiv preprint arXiv:2512.19432,
-
[8]
10 Learning to Explore: Scaling Agentic Reasoning via Exploration-Aware Policy Optimization Lee, S., Ekpo, D., Liu, H., Huang, F., Shrivastava, A., and Huang, J.-B. Imagine, verify, execute: Memory-guided agentic exploration with Vision-Language Models.arXiv preprint arXiv:2505.07815,
-
[9]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Levine, S. Reinforcement learning and control as proba- bilistic inference: Tutorial and review.arXiv preprint arXiv:1805.00909,
work page internal anchor Pith review arXiv
-
[10]
Li, P., Hu, Z., Shang, Z., Wu, J., Liu, Y ., Liu, H., Gao, Z., Shi, C., Zhang, B., Zhang, Z., et al. Efficient multi-turn rl for GUI agents via decoupled training and adaptive data curation.arXiv preprint arXiv:2509.23866,
-
[11]
Lu, F., Zhong, Z., Liu, S., Fu, C.-W., and Jia, J. ARPO: End-to-end policy optimization for GUI agents with ex- perience replay.arXiv preprint arXiv:2505.16282,
-
[12]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Qin, Y ., Ye, Y ., Fang, J., Wang, H., Liang, S., Tian, S., Zhang, J., Li, J., Li, Y ., Huang, S., et al. UI-TARS: Pioneering automated GUI interaction with native agents. arXiv preprint arXiv:2501.12326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Setlur, A., Yang, M. Y ., Snell, C. V ., Greer, J., Wu, I., Smith, V ., Simchowitz, M., and Kumar, A. e3: Learning to explore enables extrapolation of test-time compute for LLMs. InThe Exploration in AI Today Workshop at ICML 2025,
work page 2025
-
[14]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. HybridFlow: A flex- ible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling llm test- time compute optimally can be more effective than scal- ing model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Vanlioglu, A. Entropy-guided sequence weighting for ef- ficient exploration in rl-based llm fine-tuning.arXiv preprint arXiv:2503.22456,
-
[18]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Wang, G., Xie, Y ., Jiang, Y ., Mandlekar, A., Xiao, C., Zhu, Y ., Fan, L., and Anandkumar, A. V oyager: An open-ended embodied agent with large language models.Transac- tions on Machine Learning Research, 2023a. 11 Learning to Explore: Scaling Agentic Reasoning via Exploration-Aware Policy Optimization Wang, H., Zou, H., Song, H., Feng, J., Fang, J., Lu,...
work page internal anchor Pith review arXiv
-
[19]
Wilson, R. C., Geana, A., White, J. M., Ludvig, E. A., and Cohen, J. D. Humans use directed and random explo- ration to solve the explore–exploit dilemma.Journal of Experimental Psychology: General, 143(6):2074,
work page 2074
- [20]
-
[21]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Yang, C., Su, S., Liu, S., Dong, X., Yu, Y ., Su, W., Wang, X., Liu, Z., Zhu, J., Li, H., et al. ZeroGUI: Automating online GUI learning at zero human cost.arXiv preprint arXiv:2505.23762, 202...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Yang, Y ., Li, D., Dai, Y ., Yang, Y ., Luo, Z., Zhao, Z., Hu, Z., Huang, J., Saha, A., Chen, Z., et al. Gta1: GUI test-time scaling agent.arXiv preprint arXiv:2507.05791, 2025c. Yao, S., Chen, H., Yang, J., and Narasimhan, K. Web- shop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Informa- tion Processing S...
-
[23]
Mobile-agent-v3: Fundamental agents for gui automation.arXiv preprint arXiv:2508.15144, 2025
Ye, J., Zhang, X., Xu, H., Liu, H., Wang, J., Zhu, Z., Zheng, Z., Gao, F., Cao, J., Lu, Z., et al. Mobile-agent-v3: Fun- damental agents for GUI automation.arXiv preprint arXiv:2508.15144,
-
[24]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. DAPO: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Momentum-based federated reinforcement learning with interaction and communication efficiency
Yue, S., Hua, X., Chen, L., and Ren, J. Momentum-based federated reinforcement learning with interaction and communication efficiency. InIEEE INFOCOM 2024- IEEE Conference on Computer Communications, pp. 1131–1140. IEEE, 2024a. Yue, S., Hua, X., Deng, Y ., Chen, L., Ren, J., and Zhang, Y . Momentum-based contextual federated reinforcement learning.IEEE Tr...
-
[26]
Entropy-based exploration conduction for multi-step reasoning.arXiv preprint arXiv:2503.15848, 2025a
Zhang, J., Wang, X., Mo, F., Zhou, Y ., Gao, W., and Liu, K. Entropy-based exploration conduction for multi-step reasoning.arXiv preprint arXiv:2503.15848, 2025a. Zhang, S., Wang, Y ., Liu, Y ., Liu, T., Grabowski, P., Ie, E., Wang, Z., and Li, Y . Beyond markovian: Reflective exploration via bayes-adaptive rl for llm reasoning.arXiv preprint arXiv:2505.2...
-
[27]
13 Learning to Explore: Scaling Agentic Reasoning via Exploration-Aware Policy Optimization A. Derivation We aim to find a memory distribution q(e, m|s), which is closest to the original distribution p(e, m|s, a). Formally, the objective is defined as: min q KL(q(e, m|s)∥p(e, m|s,success)).(15) Based on the definition of KL divergence, we can derive: KL(q...
work page 2013
-
[28]
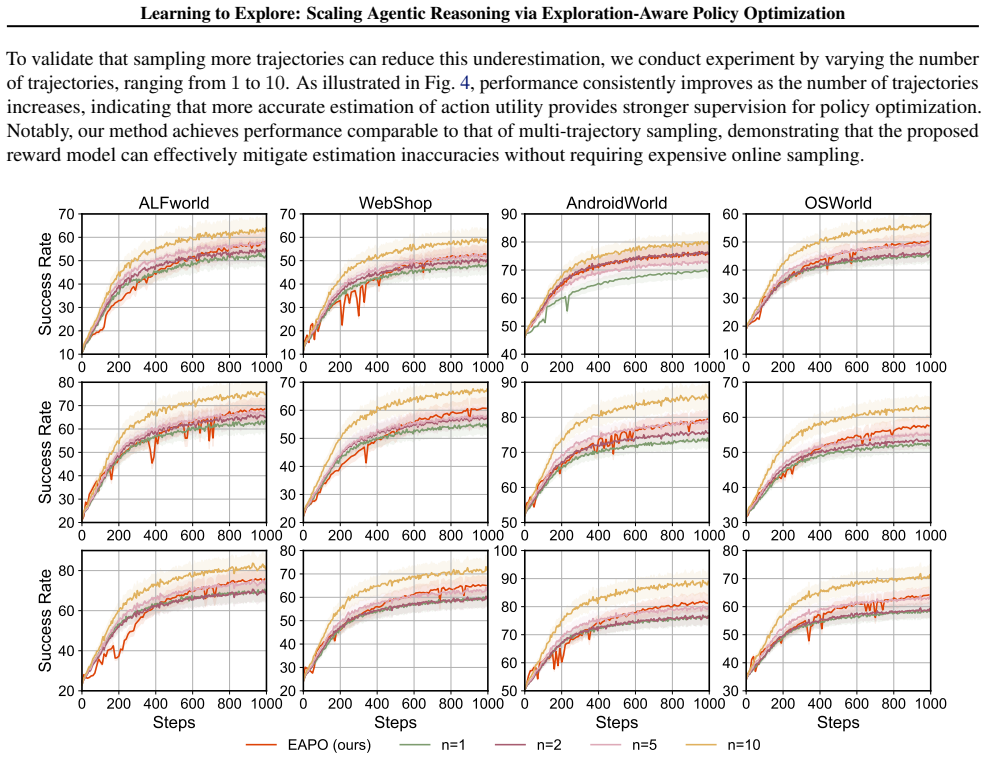
As illustrated in Fig. 4, performance consistently improves as the number of trajectories increases, indicating that more accurate estimation of action utility provides stronger supervision for policy optimization. Notably, our method achieves performance comparable to that of multi-trajectory sampling, demonstrating that the proposed reward model can eff...
work page 2021
-
[29]
Table 3.Hyperparameters (identical across datasets). Hyperparameter Value Number of RL epochs 1000 Sampling group size 16 Weight of format rewardα 1 0.5 Weight of exploratory rewardα 2 1 Weight of Discount factorγ 0.9 Learning rate of reward model 1e-4 Learning rate of policy model 1e-4 KL loss coefficencyλ 0.01 We implement our code using Pytorch 2.8.0, ...
work page 2024
-
[30]
We observe that, after ablating exploration-aware grouping, both the exploration degree and task performance exhibit a rise-then-fall trend during training. Specifically, the initial increase indicates that the agent can still benefit from short-term exploration when grouping is removed. However, as training progresses, exploratory actions and task-comple...
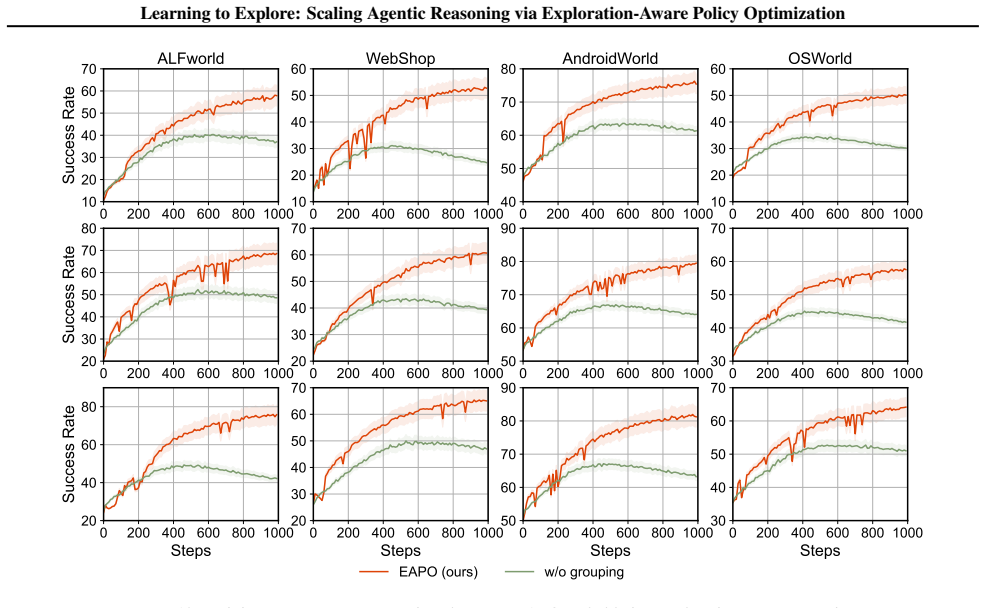
work page 2000
-
[31]
in average step. To be specific, we apply a discount to the exploratory gain since the benefit of exploration is not immediate – requiring at least one step to observe a new state and a subsequent step to synthesize the information. It guides the agent to carry out exploration only when the anticipated utility ‘outweighs’ the latency cost, which will avoi...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.