Recognition: 2 theorem links
· Lean TheoremPMCTS: Particle Monte Carlo Tree Search for Principled Parallelized Inference Time Scaling
Pith reviewed 2026-05-12 02:43 UTC · model grok-4.3
The pith
PMCTS is the first parallel Monte Carlo Tree Search algorithm that preserves formal policy improvement guarantees for neural network evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
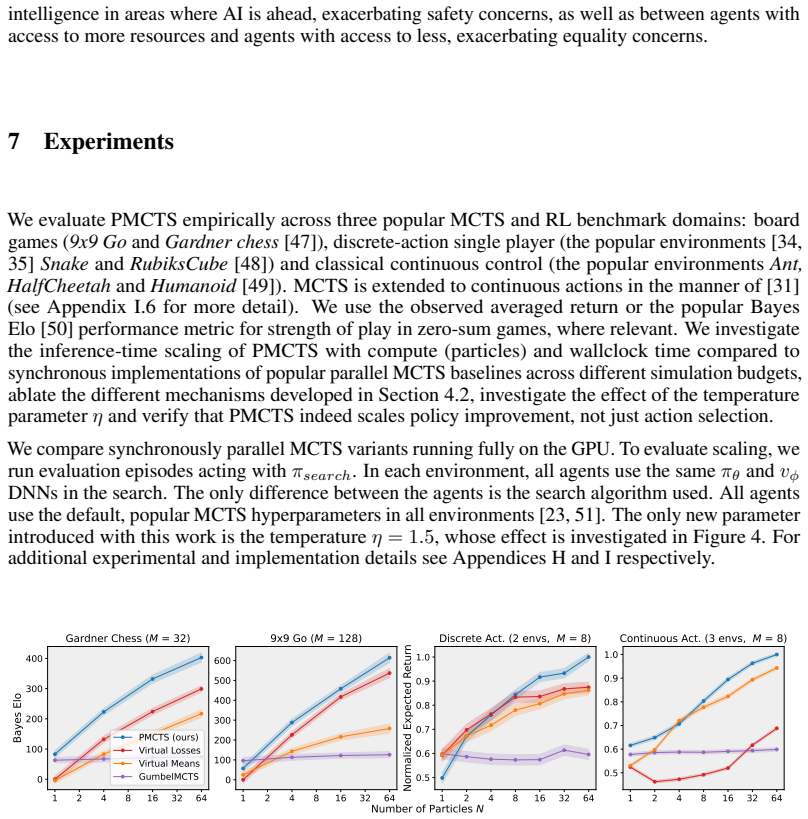
PMCTS is the first principled parallel MCTS algorithm suited for neural network evaluations that can preserve formal policy improvement guarantees. Empirically, PMCTS scales well with parallel compute and significantly outperforms the popular heuristic-based baselines across domains.
What carries the argument
The particle-based parallelization mechanism, in which multiple particles conduct simultaneous searches while maintaining the convergence and policy improvement properties of sequential MCTS.
If this is right
- MCTS runtime can scale directly with additional parallel compute resources.
- Neural network evaluations can be used inside parallel search without losing formal policy guarantees.
- Heuristic parallel MCTS variants can be replaced by a method with provable improvement properties.
- Better decision quality is observed across tested domains when parallel hardware is available.
Where Pith is reading between the lines
- The particle technique might extend to other sequential planning methods that need parallel execution.
- Integration into distributed reinforcement learning systems could improve inference-time performance at scale.
- Direct comparisons of convergence speed between PMCTS and asynchronous MCTS on larger problems would clarify its practical reach.
Load-bearing premise
The particle-based parallelization mechanism does not introduce bias or violate the original MCTS convergence properties when neural network evaluations are used.
What would settle it
An experiment in which PMCTS produces a different final policy than sequential MCTS or shows degraded performance as particle count increases on a standard benchmark domain would falsify the claim.
Figures






read the original abstract
Monte Carlo Tree Search (MCTS) is a widely used approach for policy improvement through search with increasing popularity for real world applications. Due to the sequential and deterministic nature of its search, runtime-scaling of MCTS with parallel compute remains a major challenge. We introduce Particle MCTS (PMCTS), to our knowledge the first principled parallel MCTS algorithm which is suited for neural network evaluations and can preserve formal policy improvement guarantees. Empirically, PMCTS scales well with parallel compute and significantly outperforms the popular heuristic-based baselines across domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Particle Monte Carlo Tree Search (PMCTS), a particle-based parallelization of MCTS designed to scale with parallel compute. It claims to be the first principled parallel MCTS algorithm suitable for neural network evaluations while preserving formal policy improvement guarantees from standard MCTS theory. Empirically, PMCTS is shown to scale effectively with additional parallel resources and to outperform heuristic-based parallel MCTS baselines across domains.
Significance. If the central claim holds, this would represent a meaningful advance in inference-time scaling for search-based methods in machine learning. By attempting a theoretically grounded parallelization instead of heuristic approaches, the work addresses a practical bottleneck in deploying MCTS with neural networks for planning and reinforcement learning tasks. The empirical scaling results, if robust, would support its utility for leveraging parallel hardware.
major comments (1)
- [§4] §4 (Theoretical Analysis): The central claim that PMCTS preserves formal policy improvement guarantees under neural network evaluations is load-bearing for the paper's contribution. The manuscript asserts that the particle-based parallel updates maintain the unbiasedness, exploration, and convergence properties of sequential MCTS theorems, but provides no explicit derivation or correction mechanism for the approximation error and potential bias introduced by NN value estimates. Without this, it is unclear whether the guarantees transfer from exact-oracle MCTS theory.
minor comments (2)
- [Abstract] Abstract: The statement of empirical outperformance would be strengthened by briefly indicating the domains evaluated and the scale of improvements observed.
- [Experiments] Experiments section: Scaling plots and performance tables lack error bars or details on the number of independent runs, making it harder to assess variability in the reported gains with parallel compute.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment on the theoretical analysis below.
read point-by-point responses
-
Referee: [§4] §4 (Theoretical Analysis): The central claim that PMCTS preserves formal policy improvement guarantees under neural network evaluations is load-bearing for the paper's contribution. The manuscript asserts that the particle-based parallel updates maintain the unbiasedness, exploration, and convergence properties of sequential MCTS theorems, but provides no explicit derivation or correction mechanism for the approximation error and potential bias introduced by NN value estimates. Without this, it is unclear whether the guarantees transfer from exact-oracle MCTS theory.
Authors: We agree that the transfer of guarantees under NN evaluations requires careful treatment. Section 4 establishes that the particle-based parallel updates are distributionally equivalent to sequential MCTS updates (independent particles yield unbiased value estimates and the selection rule preserves the same exploration bias as UCT). Because the NN is used only to produce the per-node estimates, any approximation error or bias is identical to that present in sequential NN-MCTS; the parallelization itself introduces no additional bias or correction requirement. We did not re-derive the full NN case because it follows immediately once equivalence is shown. In the revision we will add a short clarifying paragraph and a one-paragraph sketch in §4 that makes this conditional transfer explicit, referencing the standard treatment in the sequential NN-MCTS literature. revision: partial
Circularity Check
No circularity: PMCTS extends standard MCTS theory to particles without reducing claims to inputs by construction
full rationale
The paper presents PMCTS as a novel parallel MCTS variant using particles to enable parallelization while claiming to preserve formal policy improvement guarantees from sequential MCTS. No load-bearing steps reduce by definition or self-citation to the paper's own fitted parameters or prior results; the abstract and description indicate reliance on established MCTS convergence properties (visit counts, value backups) extended to the particle setting under NN evaluations. This is a standard theoretical extension rather than a self-referential loop. The provided text shows no self-definitional equations, renamed empirical patterns, or uniqueness theorems imported solely from overlapping authors. The derivation remains self-contained against external MCTS benchmarks, consistent with a score of 0.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PMCTS samples trajectories fully independently in parallel (lock-free), from a theoretically grounded improved policy... preserve formal policy improvement guarantees under the classical assumptions of unbiased, finite variance and uncorrelated evaluations
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We establish policy improvement theoretical guarantees for baseline MCTS and showing that PMCTS is able to preserve them
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. InThe 17th European Conference on Machine Learning, 2006. doi: 10.1007/11871842\_29
-
[2]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the...
-
[3]
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play.Science, 362(6419):1140–1144, 2018. doi: 10.1126...
-
[4]
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020. doi: 10.1038/s41586-020-03051-4
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4 2020
-
[5]
Alhussein Fawzi, Matej Balog, Aja Huang, Thomas Hubert, Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Francisco J. R. Ruiz, Julian Schrittwieser, Grzegorz Swirszcz, David Silver, Demis Hassabis, and Pushmeet Kohli. Discovering faster matrix multiplication algorithms with reinforcement learning.Nature, 610(7930):47–53, 2022. doi: 1...
-
[6]
Daniel J. Mankowitz, Andrea Michi, Anton Zhernov, Marco Gelmi, Marco Selvi, Cosmin Paduraru, Edouard Leurent, Shariq Iqbal, Jean-Baptiste Lespiau, Alex Ahern, Thomas Koppe, Kevin Millikin, Stephen Gaffney, Sophie Elster, Jackson Broshear, Chris Gamble, Kieran Milan, Robert Tung, Minjae Hwang, Taylan Cemgil, Mohammadamin Barekatain, Yujia Li, Amol Mandhane...
-
[7]
Amol Mandhane, Anton Zhernov, Maribeth Rauh, Chenjie Gu, Miaosen Wang, Flora Xue, Wendy Shang, Derek Pang, Rene Claus, Ching-Han Chiang, et al. Muzero with self-competition for rate control in vp9 video compression.arXiv preprint arXiv:2202.06626, 2022
-
[8]
Reasoning with Language Model is Planning with World Model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. doi: 10.18653/V1/2023.EMNLP-MAIN.507
-
[9]
Language agent tree search unifies reasoning, acting, and planning in language models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning, acting, and planning in language models. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[10]
Alphazero-like tree-search can guide large language model decoding and training
Ziyu Wan, Xidong Feng, Muning Wen, Stephen Marcus McAleer, Ying Wen, Weinan Zhang, and Jun Wang. Alphazero-like tree-search can guide large language model decoding and training. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Ma...
work page 2024
-
[11]
SWE-search: Enhancing software agents with monte carlo tree search and iterative refinement
Antonis Antoniades, Albert Örwall, Kexun Zhang, Yuxi Xie, Anirudh Goyal, and William Yang Wang. SWE-search: Enhancing software agents with monte carlo tree search and iterative refinement. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[12]
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search.The 37th Annual Conference on Advances in Neural Information Processing Systems, pages 64735–64772, 2024
work page 2024
-
[13]
Monte carlo planning with large language model for text- based game agents
Zijing Shi, Meng Fang, and Ling Chen. Monte carlo planning with large language model for text- based game agents. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[14]
rstar-math: Small llms can master math reasoning with self-evolved deep thinking
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small llms can master math reasoning with self-evolved deep thinking. In Forty-second International Conference on Machine Learning, 2025
work page 2025
-
[15]
Wider or deeper? scaling llm inference-time compute with adaptive branching tree search
Kou Misaki, Yuichi Inoue, Yuki Imajuku, So Kuroki, Taishi Nakamura, and Takuya Akiba. Wider or deeper? scaling LLM inference-time compute with adaptive branching tree search. arXiv preprint arXiv:2503.04412, 2025
-
[16]
Tristan Cazenave and Nicolas Jouandeau. On the parallelization of UCT. InComputer Games Workshop 207 (CGW07), 2007
work page 2007
-
[17]
Guillaume Chaslot, Mark H. M. Winands, and H. Jaap van den Herik. Parallel monte-carlo tree search. In6th International Conference on Computers and Games (CG 2008), 2008
work page 2008
-
[18]
Practical massively parallel monte- carlo tree search applied to molecular design
Xiufeng Yang, Tanuj Kr Aasawat, and Kazuki Yoshizoe. Practical massively parallel monte- carlo tree search applied to molecular design. InThe 9th International Conference on Learning Representations, 2021
work page 2021
-
[19]
PhD thesis, University of Paderborn, 2014
Lars Schäfers.Parallel Monte-Carlo tree search for HPC systems and its application to computer go. PhD thesis, University of Paderborn, 2014
work page 2014
-
[20]
On effective paralleliza- tion of monte carlo tree search.CoRR, abs/2006.08785, 2020
Anji Liu, Yitao Liang, Ji Liu, Guy Van den Broeck, and Jianshu Chen. On effective paralleliza- tion of monte carlo tree search.CoRR, abs/2006.08785, 2020. 11
-
[21]
Tristan Cazenave. Batch monte carlo tree search. InComputers and Games - International Conference, 2022. doi: 10.1007/978-3-031-34017-8\_13
-
[22]
Christopher D Rosin. Multi-armed bandits with episode context.Annals of Mathematics and Artificial Intelligence, 61(3):203–230, 2011
work page 2011
-
[23]
Policy improvement by planning with Gumbel
Ivo Danihelka, Arthur Guez, Julian Schrittwieser, and David Silver. Policy improvement by planning with Gumbel. InThe Tenth International Conference on Learning Representations, 2022
work page 2022
-
[24]
Monte-Carlo Tree Search as Regularized Policy Optimization
Jean-Bastien Grill, Florent Altché, Yunhao Tang, Thomas Hubert, Michal Valko, Ioannis Antonoglou, and Remi Munos. Monte-Carlo Tree Search as Regularized Policy Optimization. InThe 37th International Conference on Machine Learning, 2020
work page 2020
-
[25]
Nicolas Chopin and Omiros Papaspiliopoulos.An Introduction to Sequential Monte Carlo. Springer Series in Statistics. Springer, Cham, 1st edition, 2020. doi: 10.1007/ 978-3-030-47845-2
work page 2020
-
[26]
A Markovian Decision Process.Journal of Mathematics and Mechanics, 6 (5):679–684, 1957
Richard Bellman. A Markovian Decision Process.Journal of Mathematics and Mechanics, 6 (5):679–684, 1957
work page 1957
-
[27]
Thomas M. Moerland, Joost Broekens, Aske Plaat, and Catholijn M. Jonker. Model-based Reinforcement Learning: A Survey.Foundations and Trends® in Machine Learning, 16(1): 1–118, 2023. doi: 10.1561/2200000086
-
[28]
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. A Bradford Book, 2nd edition, 2018
work page 2018
-
[29]
Yaniv Oren, Viliam Vadocz, Matthijs T. J. Spaan, and Wendelin Boehmer. Epistemic Monte Carlo Tree Search. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[30]
Ioannis Antonoglou, Julian Schrittwieser, Sherjil Ozair, Thomas K. Hubert, and David Silver. Planning in stochastic environments with a learned model. InThe Tenth International Conference on Learning Representations, 2022
work page 2022
-
[31]
Learning and Planning in Complex Action Spaces
Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Mohammadamin Barekatain, Simon Schmitt, and David Silver. Learning and Planning in Complex Action Spaces. InThe 38th International Conference on Machine Learning, 2021
work page 2021
-
[32]
Efficientzero V2: mas- tering discrete and continuous control with limited data
Shengjie Wang, Shaohuai Liu, Weirui Ye, Jiacheng You, and Yang Gao. Efficientzero V2: mas- tering discrete and continuous control with limited data. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[33]
Probabilistic planning with sequential monte carlo methods
Alexandre Piché, Valentin Thomas, Cyril Ibrahim, Yoshua Bengio, and Chris Pal. Probabilistic planning with sequential monte carlo methods. InThe 7th International Conference on Learning Representations, 2019
work page 2019
-
[34]
Yaniv Oren, Joery A de Vries, Pascal R van der Vaart, Matthijs TJ Spaan, and Wendelin Böhmer. Twice sequential monte carlo for tree search.The 43 International Conference on Machine Learning, 2026
work page 2026
-
[35]
de Vries, Jinke He, Yaniv Oren, and Matthijs T
Joery A. de Vries, Jinke He, Yaniv Oren, and Matthijs T. J. Spaan. Trust-Region Twisted Policy Improvement. InThe 42 International Conference on Machine Learning, 2025
work page 2025
-
[36]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/jax-ml/jax
work page 2018
-
[37]
Monte-Carlo planning in large POMDPs
David Silver and Joel Veness. Monte-Carlo planning in large POMDPs. InThe 24th Annual Conference on Neural Information Processing Systems, 2010. 12
work page 2010
-
[38]
DESPOT: online POMDP planning with regularization
Adhiraj Somani, Nan Ye, David Hsu, and Wee Sun Lee. DESPOT: online POMDP planning with regularization. InThe 27th Annual Conference on Neural Information Processing Systems, 2013
work page 2013
-
[39]
Zachary N. Sunberg and Mykel J. Kochenderfer. Online algorithms for POMDPs with continu- ous state, action, and observation spaces. InThe 28th International Conference on Automated Planning and Scheduling, 2018
work page 2018
-
[40]
Semanti Basu, Sreshtaa Rajesh, Kaiyu Zheng, Stefanie Tellex, and R. Iris Bahar. Parallelizing POMCP to solve complex POMDPs.RSS workshop on software tools for real-time optimal control, 2021
work page 2021
-
[41]
HyP-DESPOT: A hybrid parallel algorithm for online planning under uncertainty
Panpan Cai, Yuanfu Luo, David Hsu, and Wee Sun Lee. HyP-DESPOT: A hybrid parallel algorithm for online planning under uncertainty. InRobotics: Science and Systems XIV, 2018
work page 2018
-
[42]
Joachim Hartung, Guido Knapp, and Bimal K Sinha.Statistical meta-analysis with applications. John Wiley & Sons, 2008
work page 2008
-
[43]
Temporal Difference Learning for Model Predictive Control
Nicklas A Hansen, Hao Su, and Xiaolong Wang. Temporal Difference Learning for Model Predictive Control. InThe 39th International Conference on Machine Learning, 2022
work page 2022
-
[44]
TD-MPC2: scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: scalable, robust world models for continuous control. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[45]
Bootstrapped model predictive control
Yuhang Wang, Hanwei Guo, Sizhe Wang, Long Qian, and Xuguang Lan. Bootstrapped model predictive control. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[46]
General tree evaluation for AlphaZero
Albin Jaldevik. General tree evaluation for AlphaZero. Master’s thesis, Delft University of Technology, 2024
work page 2024
-
[47]
Pgx: Hardware-accelerated parallel game simulators for reinforcement learning
Sotetsu Koyamada, Shinri Okano, Soichiro Nishimori, Yu Murata, Keigo Habara, Haruka Kita, and Shin Ishii. Pgx: Hardware-accelerated parallel game simulators for reinforcement learning. InThe 36th Annual Conference on Advances in Neural Information Processing Systems, 2023
work page 2023
-
[48]
Jumanji: a diverse suite of scalable reinforcement learning environments in JAX
Clément Bonnet, Daniel Luo, Donal John Byrne, Shikha Surana, Sasha Abramowitz, Paul Duckworth, Vincent Coyette, Laurence Illing Midgley, Elshadai Tegegn, Tristan Kalloniatis, Omayma Mahjoub, Matthew Macfarlane, Andries Petrus Smit, Nathan Grinsztajn, Raphael Boige, Cemlyn Neil Waters, Mohamed Ali Ali Mimouni, Ulrich Armel Mbou Sob, Ruan John de Kock, Sidd...
work page 2024
-
[49]
Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem
C. Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax - A Differentiable Physics Engine for Large Scale Rigid Body Simulation. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), 2021
work page 2021
-
[50]
Rémi Coulom. Bayesian Elo Rating. https://www.remi-coulom.fr/Bayesian-Elo/,
-
[51]
[Online; accessed 02-05-2024]
work page 2024
-
[52]
The DeepMind JAX Ecosystem, 2020
DeepMind, Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Kemaev, Michael King, Markus Kunesch, Lena ...
work page 2020
-
[53]
Hongbeen Kim, Juhyun Lee, Sanghyeon Lee, Kwanghoon Choi, and Jaehyuk Huh. Adap- tive parallel monte carlo tree search for efficient test-time compute scaling.arXiv preprint arXiv:2604.00510, 2026
-
[54]
Almost Optimal Exploration in Multi-Armed Bandits
Zohar Karnin, Tomer Koren, and Oren Somekh. Almost Optimal Exploration in Multi-Armed Bandits. InThe 30th International Conference on Machine Learning, 2013
work page 2013
-
[55]
Gabriel Cardoso, Sergey Samsonov, Achille Thin, Eric Moulines, and Jimmy Olsson. BR-SNIS: bias reduced self-normalized importance sampling.The 35th Annual Conference on Advances in Neural Information Processing Systems, 2022
work page 2022
-
[56]
Peter M. Kogge and Harold S. Stone. A parallel algorithm for the efficient solution of a general class of recurrence equations.IEEE Transactions on Computers, C-22(8):786–793, 1973. doi: 10.1109/TC.1973.5009159
-
[57]
G.E. Blelloch. Scans as primitive parallel operations.IEEE Transactions on Computers, 38(11): 1526–1538, 1989. doi: 10.1109/12.42122
-
[58]
Eshrat Arjomandi, Michael J. Fischer, and Nancy A. Lynch. A difference in efficiency between synchronous and asynchronous systems. InThe 13th Annual ACM Symposium on Theory of Computing, 1981. doi: 10.1145/800076.802466
-
[59]
Ali Mirsoleimani, Aske Plaat, H
S. Ali Mirsoleimani, Aske Plaat, H. Jaap van den Herik, and Jos Vermaseren. An analysis of virtual loss in parallel MCTS. InThe 9th International Conference on Agents and Artificial Intelligence, 2017. doi: 10.5220/0006205806480652
-
[60]
A lock-free multithreaded monte-carlo tree search algorithm
Markus Enzenberger and Martin Müller. A lock-free multithreaded monte-carlo tree search algorithm. InThe 12th International Conference on Advances in Computer Games, 2009. doi: 10.1007/978-3-642-12993-3\_2
-
[61]
S. Ali Mirsoleimani, H. Jaap van den Herik, Aske Plaat, and Jos Vermaseren. A lock-free algorithm for parallel MCTS. InThe 10th International Conference on Agents and Artificial Intelligence, 2018
work page 2018
-
[62]
Emil Malmsten and Wendelin Böhmer. Transzero: Parallel tree expansion in muzero using transformer networks.arXiv preprint arXiv:2509.11233, 2025
-
[63]
Scott Cheng, Mahmut T. Kandemir, and Ding-Yong Hong. Speculative monte-carlo tree search. InThe 38th Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[64]
Juhwan Kim, Byeongmin Kang, and Hyungmin Cho. Specmcts: Accelerating monte carlo tree search using speculative tree traversal.IEEE Access, 9:142195–142205, 2021. doi: 10.1109/ACCESS.2021.3120384
-
[65]
Multiple policy value monte carlo tree search
Li-Cheng Lan, Wei Li, Ting-Han Wei, and I-Chen Wu. Multiple policy value monte carlo tree search. InThe Twenty-Eighth International Joint Conference on Artificial Intelligence, 2019. doi: 10.24963/IJCAI.2019/653
-
[66]
Value Improved Actor Critic Algorithms
Yaniv Oren, Moritz A Zanger, Pascal R Van der Vaart, Mustafa Mert Çelikok, Matthijs TJ Spaan, and Wendelin Boehmer. Value Improved Actor Critic Algorithms. InThe 39th Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[67]
David R Hunter. Mm algorithms for generalized bradley-terry models.The annals of statistics, 32(1):384–406, 2004. 14 Appendix Contents A Acronym and Symbols List 17 B Pseudocode 17 C Derivations 19 C.1 Derivation of the numerically stable weighted average . . . . . . . . . . . . . . . . 19 C.2 Derivation of the particle-based backpropagation step in PMCTS...
work page 2004
-
[68]
(III) PMCTS is principled, in that it retains the same properties established for MCTS. This is supported by Section 5. (IV) That PMCTS is the first parallel and principled MCTS algorithm, to our knowledge. This is supported by Section 3 and Appendix F. Guidelines: • The answer [N/A] means that the abstract and introduction do not include the claims made ...
-
[69]
important, original, or non-standard component of the core methods
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.