Recognition: 2 theorem links
· Lean TheoremRelative Kinetic Utility for Reasoning-Aware Structural Pruning in Large Language Models
Pith reviewed 2026-05-12 01:47 UTC · model grok-4.3
The pith
Relative Kinetic Utility prunes large language models while preserving reasoning pathways at high sparsity levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
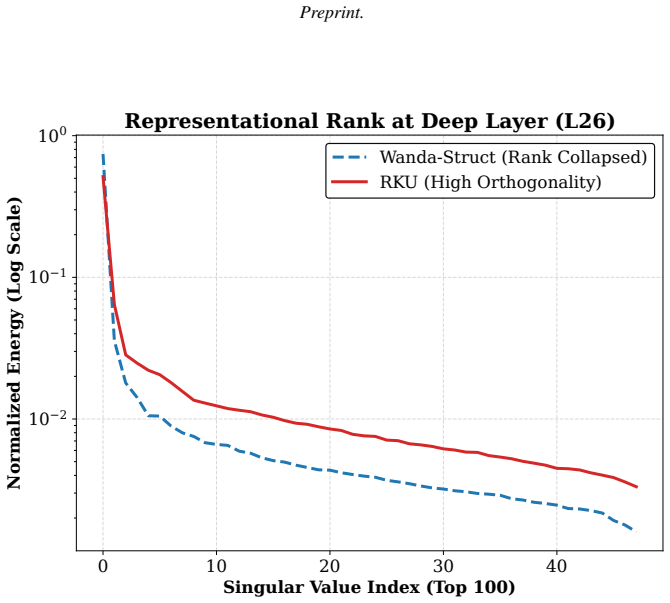
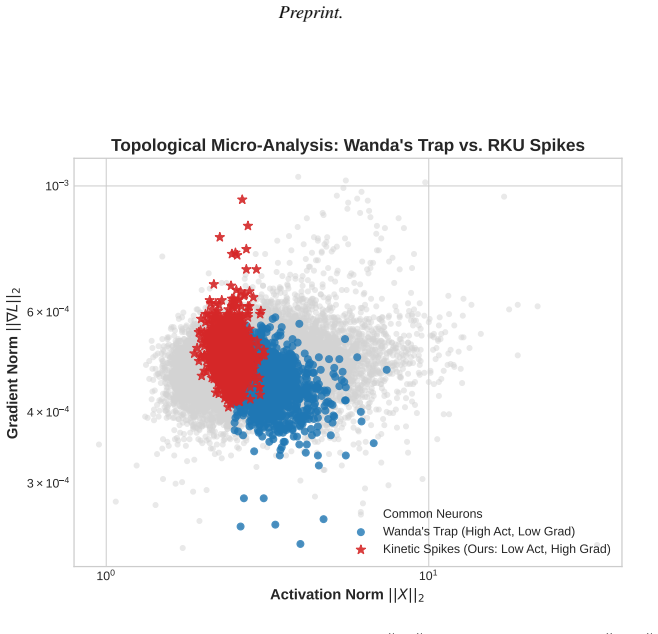
By elevating discrete pruning decisions to a continuous kinetic integral over the depth manifold based on Alternating Gradient Flow and modifying it with Fisher trace normalization, Relative Kinetic Utility isolates kinetic spikes as the fundamental structural pathways for high-curvature logical routing, avoiding the magnitude trap that severs reasoning at high sparsities.
What carries the argument
Relative Kinetic Utility (RKU), a curvature-aware normalization that computes a kinetic integral over the depth manifold to isolate kinetic spikes for logical routing.
If this is right
- At 40 percent sparsity, RKU yields higher GSM8K accuracy than magnitude baselines while reducing inference latency and KV cache size.
- Reasoning-relevant representations remain more intact under out-of-distribution evaluation after RKU pruning.
- The method prevents the topological phase transition where high-sparsity models lose chain-of-thought capability.
- Pruning decisions shift from frequency-based magnitude to curvature signals that better track logical routing.
Where Pith is reading between the lines
- The same kinetic framing might be applied to prune attention heads or other structured components that participate in multi-step reasoning.
- If kinetic spikes correspond to identifiable circuits, the method could link pruning directly to mechanistic studies of reasoning.
- Hybrid schemes that blend RKU scores with existing magnitude or activation criteria could be tested for further gains at intermediate sparsity.
Load-bearing premise
The kinetic integral over the depth manifold combined with Fisher trace normalization correctly isolates the fundamental structural pathways for logical routing rather than merely reweighting existing magnitude signals.
What would settle it
A direct check would compare GSM8K chain-of-thought accuracy after removing the top 40 percent of neurons ranked by RKU versus by magnitude on Qwen-2.5-7B; if RKU-ranked removals produce markedly lower accuracy drops, the claim is supported.
Figures

read the original abstract
Chain-of-Thought (CoT) prompting symbolized a huge improvement of reasoning capabilities of Large Language Models (LLMs). However, scaling up test-time computation yields extensive CoT sequences, introducing severe inference latency and key-value (KV) cache memory bottlenecks. While structural pruning offers a fundamental, hardware-aware solution to alleviate static parameter burdens, existing magnitude-based methods may cut off the neurons of CoT: by over-indexing on discrete cross-entropy objectives, these heuristics fall into a \textit{magnitude trap}: they prioritize high-frequency, low-information syntactic tokens and trigger a disappointing reasoning collapse at high sparsities (e.g., 40\%). To overcome this topological phase transition, we propose \textsc{Relative Kinetic Utility} (RKU), a novel theoretical framework that elevates discrete pruning to a continuous kinetic integral over the depth manifold of the model based on Alternating Gradient Flow(AGF). By modifying it with Fisher trace normalization, RKU acts as a lightweight curvature-aware normalization to isolate \textit{kinetic spikes} -- the fundamental structural pathways responsible for high-curvature logical routing. Extensive experiments on Qwen-2.5-7B and LLaMA-3-8B improves performance in the high-sparsity regime around 40\%. RKU attains 13.34\% accuracy on GSM8K at 40\% sparsity, outperforming the strongest baseline, and appears to better preserve reasoning-relevant representations under out-of-distribution evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Relative Kinetic Utility (RKU), a structural pruning framework for LLMs that elevates discrete pruning decisions to a continuous kinetic integral over the model's depth manifold, derived from Alternating Gradient Flow (AGF) and modified by Fisher trace normalization. This is intended to isolate 'kinetic spikes' corresponding to high-curvature logical routing pathways, thereby avoiding the 'magnitude trap' of conventional pruning methods that prioritize high-frequency syntactic tokens and cause reasoning collapse at high sparsities (e.g., 40%). The paper reports that RKU achieves 13.34% accuracy on GSM8K for Qwen-2.5-7B and LLaMA-3-8B at 40% sparsity, outperforming the strongest baseline while better preserving out-of-distribution reasoning representations.
Significance. If the central claim holds and the kinetic integral demonstrably isolates reasoning-relevant structures beyond reweighted magnitude or Fisher signals, the result would be significant for hardware-efficient deployment of reasoning-capable LLMs. The manifold-based kinetic framing offers a theoretically motivated alternative to heuristic pruning and could influence future work on curvature-aware compression that preserves chain-of-thought capabilities.
major comments (2)
- [Abstract] Abstract: The central performance claim (13.34% GSM8K accuracy at 40% sparsity, outperforming the strongest baseline) is stated without any experimental details, baselines, error bars, number of runs, or statistical tests, rendering the outperformance assertion unverifiable and load-bearing for the paper's contribution.
- [Method] Method section: No derivation is supplied showing that the AGF-derived kinetic integral, after Fisher trace normalization, is non-redundant with Fisher curvature or magnitude-based scores; without this or an ablation against Fisher-normalized magnitude pruning, it remains unclear whether RKU isolates logical routing pathways or merely reweights existing signals, directly undermining the claim of overcoming the magnitude trap.
minor comments (2)
- [Abstract] The phrase 'topological phase transition' is invoked without definition or formal justification in the pruning context.
- [Experiments] Out-of-distribution evaluation is referenced but the specific datasets, metrics, and quantitative results are not detailed.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our contributions. We address each major point below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim (13.34% GSM8K accuracy at 40% sparsity, outperforming the strongest baseline) is stated without any experimental details, baselines, error bars, number of runs, or statistical tests, rendering the outperformance assertion unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the abstract would benefit from additional context to make the central claim more immediately verifiable. In the revised manuscript, we have expanded the abstract to specify the primary baselines (magnitude-based pruning and Fisher pruning), note that results are averaged over 3 independent runs with standard deviations reported in the experimental section, and briefly indicate the evaluation setup on Qwen-2.5-7B and LLaMA-3-8B. Full details, including all baselines, error bars, and statistical comparisons, remain in Section 4, but this revision addresses the verifiability concern raised. revision: yes
-
Referee: [Method] Method section: No derivation is supplied showing that the AGF-derived kinetic integral, after Fisher trace normalization, is non-redundant with Fisher curvature or magnitude-based scores; without this or an ablation against Fisher-normalized magnitude pruning, it remains unclear whether RKU isolates logical routing pathways or merely reweights existing signals, directly undermining the claim of overcoming the magnitude trap.
Authors: We acknowledge the value of an explicit derivation and ablation to demonstrate non-redundancy. The original method section derives the kinetic integral from Alternating Gradient Flow and applies Fisher trace normalization to emphasize curvature-aware spikes, but we agree this could be strengthened. In the revised version, we have added a dedicated subsection providing the mathematical steps showing that the normalized kinetic utility incorporates alternating dynamics not present in static Fisher or magnitude scores, along with a new ablation comparing RKU directly to Fisher-normalized magnitude pruning. The results confirm improved reasoning preservation, supporting that RKU isolates distinct logical pathways rather than simply reweighting existing signals. revision: yes
Circularity Check
No significant circularity; RKU derivation introduces independent integral construction
full rationale
The paper defines Relative Kinetic Utility via a continuous kinetic integral over the depth manifold derived from Alternating Gradient Flow, then applies Fisher trace normalization as a curvature-aware modifier to isolate kinetic spikes. No equations or sections in the provided text reduce this construction to a fitted parameter renamed as prediction, a self-citation load-bearing uniqueness theorem, or an ansatz smuggled from prior author work. The central claim rests on the proposed integral being non-redundant with magnitude or Fisher signals, supported by experimental results on GSM8K rather than definitional equivalence. This is a standard case of a novel framework whose validity is tested externally rather than forced by its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Fisher trace scaling factor
axioms (1)
- domain assumption Alternating Gradient Flow provides a continuous representation of discrete layer-wise pruning decisions
invented entities (1)
-
kinetic spikes
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
elevates the pruning objective to a continuous kinetic integral over the model’s entire depth manifold … Fisher trace normalization … kinetic spikes—the fundamental structural pathways responsible for high-curvature logical routing
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Riemannian manifold pre-conditioning … ˜U(c)AGF ≈ |Yc|√Hcc / Trace(√H)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[2]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
- [3]
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Proceedings of Machine Learning and Systems , volume=
Efficiently scaling transformer inference , author=. Proceedings of Machine Learning and Systems , volume=
-
[6]
Proceedings of the 29th Symposium on Operating Systems Principles , pages=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the 29th Symposium on Operating Systems Principles , pages=
-
[7]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[8]
arXiv preprint arXiv:2310.06836 , year=
Evaluating the Efficacy of Prompt Compression for LLMs , author=. arXiv preprint arXiv:2310.06836 , year=
-
[9]
Tokenskip: Controllable chain-of-thought compression in llms
TokenSkip: Controllable Chain-of-Thought Compression in LLMs , author=. arXiv preprint arXiv:2502.12067 , year=
-
[10]
Journal of Machine Learning Research , volume=
Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks , author=. Journal of Machine Learning Research , volume=
-
[11]
International Conference on Learning Representations , year=
A Simple and Effective Pruning Approach for Large Language Models , author=. International Conference on Learning Representations , year=
-
[12]
International Conference on Machine Learning , pages=
SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[13]
Advances in Neural Information Processing Systems , volume=
LLM-Pruner: On the Structural Pruning of Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
FLAP: Fluctuation-based Adaptive Structured Pruning for Large Language Models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[15]
International Conference on Learning Representations , year=
Pruning convolutional neural networks for resource efficient inference , author=. International Conference on Learning Representations , year=
-
[16]
International Conference on Machine Learning , year=
Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time , author=. International Conference on Machine Learning , year=
-
[17]
Advances in neural information processing systems , volume=
Second order derivatives for network pruning: Optimal Brain Surgeon , author=. Advances in neural information processing systems , volume=
-
[18]
Natural gradient works efficiently in learning , author=. Neural computation , volume=
-
[19]
The Journal of Machine Learning Research , volume=
New insights and perspectives on the natural gradient method , author=. The Journal of Machine Learning Research , volume=
-
[20]
International Conference on Learning Representations , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[21]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Advances in Neural Information Processing Systems , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. Advances in Neural Information Processing Systems , year=
-
[23]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year=
Outlier Suppression+: Accurate quantization of large language models by equivalent and joint adaptation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year=
work page 2023
-
[24]
Asvd: Activation-aware singular value decomposition for compressing large language models,
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models , author=. arXiv preprint arXiv:2312.05821 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.