Recognition: no theorem link
Re²Math: Benchmarking Theorem Retrieval in Research-Level Mathematics
Pith reviewed 2026-05-12 02:02 UTC · model grok-4.3
The pith
A new benchmark shows current AI systems retrieve valid math statements yet succeed at confirming their fit to the local proof step in only 7 percent of cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Re²Math constructs benchmark instances from candidate instrumental citations that appear inside the proofs of main theorems. Each instance supplies hierarchical context for the proof step together with an optional leakage-controlled anchor hint. The task is source-grounded yet citation-agnostic, so any admissible theorem that suffices for the transition is accepted. Evaluation runs against a release-frozen retrieval artifact to guarantee reproducibility, and the benchmark is designed for automatic continual expansion. On the current test set the highest fixed-judge ToolAcc is 7.0 percent, while source-grounding rates are substantially higher; this shows that systems frequently retrieve valid
What carries the argument
The Re²Math benchmark instance, built from an instrumental citation inside a real proof and equipped with hierarchical context, that evaluates ToolAcc as success at retrieving a theorem sufficient for the immediate proof transition.
If this is right
- Systems will need explicit mechanisms to verify local applicability rather than depending on general retrieval quality alone.
- The benchmark can expand automatically as new published proofs supply fresh instrumental citations.
- Decoupling citation recall, grounding, and sufficiency supplies clearer diagnostic signals for improving mathematical assistants.
- Low applicability rates despite better grounding indicate that tighter coupling between literature search and step-by-step reasoning is required.
Where Pith is reading between the lines
- The same construction technique could be applied to benchmarks in physics or computer science where proofs rely on external lemmas.
- Training with explicit rewards for applicability verification might raise ToolAcc without altering the underlying retriever.
- The identified gap suggests that simply scaling retrieval models will not close the distance to useful research assistance.
- Comparing ToolAcc on this benchmark with closed-world math performance would quantify the extra cost of literature grounding.
Load-bearing premise
Instances built from candidate instrumental citations in real proofs, supplied with hierarchical context and leakage-controlled hints, form a faithful representation of the theorem-retrieval challenges that arise in actual research-level mathematics.
What would settle it
A retrieval system that achieves ToolAcc substantially above 7 percent on the current test set while keeping high source-grounding rates, or a new collection of proof steps whose distribution of retrieval difficulty differs markedly from the benchmark instances.
Figures


read the original abstract
Large language models are increasingly capable at closed-world mathematical reasoning, but research assistance also requires source-grounded use of the literature. When a proof reaches a non-trivial step, a useful assistant should determine whether the needed tool (e.g., a lemma) already exists, identify a suitable scholarly source, and verify that its assumptions align with the current proof context. To rigorously evaluate such capabilities, we introduce Re$^2$Math, a benchmark for tool-grounded retrieval from partial mathematical proofs. Each instance is built from a candidate instrumental citation in the proof of a main theorem, with hierarchical context and an optional leakage-controlled anchor hint. We also make the task source-grounded yet citation-agnostic in that any admissible theorem sufficient for the proof transition is accepted. Evaluation uses a release-frozen retrieval artifact, ensuring reproducibility, while the benchmark itself supports automatic, continual expansion with newly constructed instances. On the current benchmark test set, the best fixed-judge ToolAcc reaches 7.0%, despite substantially higher rates of source grounding, indicating that current systems often retrieve valid statements but fail to establish their applicability to the local proof step. By decoupling citation recall, grounding, and proof-gap sufficiency, Re$^2$Math transforms literature-grounded mathematical tool use into a controlled diagnostic task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Re²Math, a benchmark for tool-grounded theorem retrieval from partial research-level mathematical proofs. Instances are constructed from candidate instrumental citations appearing in proofs of main theorems, supplied with hierarchical context and optional leakage-controlled hints. The task is source-grounded yet citation-agnostic, accepting any admissible theorem sufficient for the local proof step. Evaluation employs a release-frozen retrieval artifact for reproducibility, and the benchmark supports automatic expansion. On the current test set the best reported fixed-judge ToolAcc is 7.0 %, substantially below source-grounding rates, which the authors interpret as evidence that current systems retrieve valid statements but fail to verify applicability to the local context.
Significance. If the benchmark construction is shown to be faithful and unbiased, the work supplies a controlled diagnostic for a practically important limitation in literature-grounded mathematical reasoning. By separating citation recall, source grounding, and proof-gap sufficiency, Re²Math could guide targeted improvements in research-assistant systems. The release-frozen artifact and continual-expansion design are concrete strengths that support reproducibility and long-term utility.
major comments (1)
- [Abstract] Abstract: the central performance claim (best ToolAcc of 7.0 % indicating failure to establish applicability) rests on the assumption that the constructed instances faithfully represent research-level retrieval challenges. However, the abstract provides no information on instance validation procedures, mitigation of selection biases during proof and citation extraction, or the precise criteria used to judge sufficiency of alternative theorems. These details are load-bearing for interpreting the metric and the stated conclusions.
minor comments (1)
- [Abstract] The abstract refers to a 'fixed-judge ToolAcc' without a brief definition or pointer to the metric's formal definition; a one-sentence clarification would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying a point that can strengthen the presentation of our work. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (best ToolAcc of 7.0 % indicating failure to establish applicability) rests on the assumption that the constructed instances faithfully represent research-level retrieval challenges. However, the abstract provides no information on instance validation procedures, mitigation of selection biases during proof and citation extraction, or the precise criteria used to judge sufficiency of alternative theorems. These details are load-bearing for interpreting the metric and the stated conclusions.
Authors: We agree that the abstract's brevity leaves these supporting details implicit. The full manuscript (Section 3) specifies the construction pipeline: instances are extracted from instrumental citations in proofs of main theorems drawn from recent arXiv papers; each instance undergoes expert validation by mathematicians to confirm it poses a genuine research-level retrieval challenge; selection bias is mitigated by systematic sampling across subfields with explicit diversity controls and leakage safeguards; and sufficiency is defined as any theorem whose assumptions are compatible with the local context and whose application advances the partial proof (verified by the same expert annotators). The citation-agnostic acceptance of any admissible theorem is already stated. To make these elements more visible without lengthening the abstract excessively, we will revise the abstract to include a concise clause referencing the validation and sufficiency criteria. This change supports rather than alters the reported results and conclusions. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces and evaluates a new benchmark (Re²Math) for theorem retrieval rather than deriving a fitted result, prediction, or theorem from prior inputs. Instance construction from candidate citations in real proofs, hierarchical context, leakage-controlled hints, and metrics such as ToolAcc and source grounding are defined directly from the task specification without self-referential reduction. The reported 7.0% ToolAcc on the test set follows from straightforward evaluation on the constructed instances; no equation, claim, or central premise reduces by construction to a fit, self-citation chain, or renamed input. The work is self-contained as an empirical benchmark release.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mathematical proofs contain instrumental citations that can be isolated to form benchmark instances while preserving hierarchical context.
Reference graph
Works this paper leans on
-
[1]
Deepmath-deep sequence models for premise selection.arXiv preprint arXiv:1606.04442,
Alex A Alemi, François Chollet, Niklas Een, Geoffrey Irving, Christian Szegedy, and Josef Urban. Deepmath-deep sequence models for premise selection.arXiv preprint arXiv:1606.04442,
-
[2]
URL https://arxiv.or g/abs/2411.14199. Zhangir Azerbayev, Bartosz Piotrowski, Hailey Schoelkopf, Edward W Ayers, Dragomir Radev, and Jeremy Avigad. Proofnet: Autoformalizing and formally proving undergraduate-level mathematics. arXiv preprint arXiv:2302.12433,
-
[3]
arXiv preprint arXiv:2305.12524 , year=
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. Theoremqa: A theorem-driven question answering dataset.arXiv preprint arXiv:2305.12524,
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URL https://arxiv. org/abs/2004.07180. FutureSearch, :, Nikos I. Bosse, Jon Evans, Robert G. Gambee, Daniel Hnyk, Peter Mühlbacher, Lawrence Phillips, Dan Schwarz, and Jack Wildman. Deep research bench: Evaluating ai web research agents,
-
[6]
Deep research bench: Evaluating ai web research agents, arXiv preprint arXiv:2506.06287, 2025
URLhttps://arxiv.org/abs/2506.06287. Michael Färber and Adam Jatowt. Citation recommendation: approaches and datasets.International Journal on Digital Libraries, 21(4):375–405, August
-
[7]
doi: 10.1007/s007 99-020-00288-2
ISSN 1432-1300. doi: 10.1007/s007 99-020-00288-2. URLhttp://dx.doi.org/10.1007/s00799-020-00288-2. Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, et al. Omni-math: A universal olympiad level mathematic benchmark for large language models.arXiv preprint arXiv:2410.07985, 2024a. Guoxiong Gao...
-
[8]
arXiv preprint arXiv:2305.14627 , year=
URLhttps://arxiv.org/abs/2305.14627. Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falk- man Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, et al. Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai.arXiv preprint arXiv:2411.04872,
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
10 Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
doi: 10.1145/1772690.1772734. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
-
[11]
Cezary Kaliszyk, François Chollet, and Christian Szegedy. Holstep: A machine learning dataset for higher-order logic theorem proving.arXiv preprint arXiv:1703.00426,
-
[12]
Jakub Lála, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G
URL https://arxiv.org/abs/2508.15804. Jakub Lála, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G. Rodriques, and Andrew D. White. Paperqa: Retrieval-augmented generative agent for scientific research,
-
[13]
URLhttps://arxiv.org/abs/2312.07559. Sadegh Mahdavi, Muchen Li, Kaiwen Liu, Christos Thrampoulidis, Leonid Sigal, and Renjie Liao. Leveraging online olympiad-level math problems for llms training and contamination-resistant evaluation.arXiv preprint arXiv:2501.14275,
-
[14]
Magnushammer: A transformer-based approach to premise selection.arXiv preprint arXiv:2303.04488,
Maciej Mikuła, Szymon Tworkowski, Szymon Antoniak, Bartosz Piotrowski, Albert Qiaochu Jiang, Jin Peng Zhou, Christian Szegedy, Łukasz Kuci´nski, Piotr Miło´s, and Yuhuai Wu. Magnushammer: A transformer-based approach to premise selection.arXiv preprint arXiv:2303.04488,
-
[15]
URL https://arxiv.org/abs/2009.02252. Mark Sanderson. Test collection based evaluation of information retrieval systems.Foundations and Trends in Information Retrieval, 4(4):247–375,
-
[16]
Amanpreet Singh, Mike D’Arcy, Arman Cohan, Doug Downey, and Sergey Feldman
doi: 10.1561/1500000009. Amanpreet Singh, Mike D’Arcy, Arman Cohan, Doug Downey, and Sergey Feldman. Scirepeval: A multi-format benchmark for scientific document representations,
-
[17]
URL https://arxiv.or g/abs/2211.13308. Haoxiang Sun, Yingqian Min, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, Zheng Liu, Zhongyuan Wang, and Ji-Rong Wen. Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models.arXiv preprint arXiv:2503.21380,
-
[18]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
URL https://arxiv.org/abs/2104.08663. 11 George Tsoukalas, Jasper Lee, John Jennings, Jimmy Xin, Michelle Ding, Michael Jennings, Ami- tayush Thakur, and Swarat Chaudhuri. Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition.Advances in Neural Information Processing Systems, 37: 11545–11569,
work page internal anchor Pith review arXiv
-
[19]
Fact or fiction: Verifying scientific claims.ArXiv, abs/2004.14974,
URL https: //arxiv.org/abs/2004.14974. David Wadden, Kyle Lo, Bailey Kuehl, Arman Cohan, Iz Beltagy, Lucy Lu Wang, and Hannaneh Hajishirzi. Scifact-open: Towards open-domain scientific claim verification,
-
[20]
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui
URL https: //arxiv.org/abs/2210.13777. Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439,
-
[21]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdh- ery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Naturalproofs: Mathematical theorem proving in natural language.arXiv preprint arXiv:2104.01112,
Sean Welleck, Jiacheng Liu, Ronan Le Bras, Hannaneh Hajishirzi, Yejin Choi, and Kyunghyun Cho. Naturalproofs: Mathematical theorem proving in natural language.arXiv preprint arXiv:2104.01112,
-
[23]
Livebench: A challenging, contamination-free llm benchmark,
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz- Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, et al. Livebench: A challenging, contamination- free llm benchmark.arXiv preprint arXiv:2406.19314, 4,
-
[24]
Huajian Xin, ZZ Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, et al. Deepseek-prover-v1. 5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search.arXiv preprint arXiv:2408.08152,
-
[25]
Harp: A challenging human-annotated math reasoning benchmark.arXiv preprint arXiv:2412.08819,
Albert S Yue, Lovish Madaan, Ted Moskovitz, DJ Strouse, and Aaditya K Singh. Harp: A challenging human-annotated math reasoning benchmark.arXiv preprint arXiv:2412.08819,
-
[26]
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. Minif2f: a cross-system benchmark for formal olympiad-level mathematics.arXiv preprint arXiv:2109.00110,
-
[27]
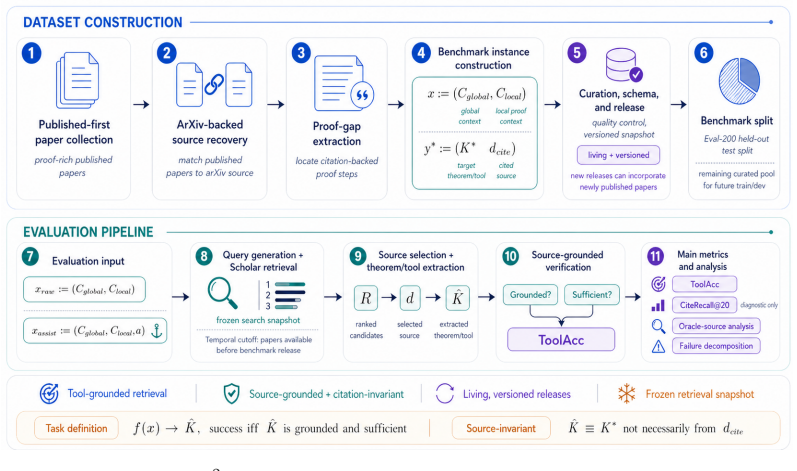
context and (optional) anchor, through query formulation and retrieval, to source selection and tool extraction—and highlights the validity criterion based on grounding and proof-gap sufficiency. This diagram is intended for intuition only and does not replace the formal task definition in Section 3, which specifies the precise inputs, outputs, and evalua...
-
[28]
Each case first presents the proof situation and reference witness, then reports the observed model behavior, and finally explains which interface breaks: proof need → search-effective language, retrieved source → theorem-bearing passage, or sourced statement→assumption-checked proof tool. Legend.Y/N indicate positive/negative labels, and ⊥ indicates no e...
-
[29]
Model behavior. Model Query Plan Query Cite@20 Ground Suff Tool Selected source GPT-5.2 positive definite polynomial sphere N Y Y⊥ ⊥ ⊥ Strictly positive definite functions on spheres Gemini 3.1 Pro positive definite function coefficients one N Y Y N N N Metric spaces and positive definite functions Claude Opus 4.5 positive definite functions spheres Gegen...
-
[30]
Model behavior. Model Query Plan Query Cite@20 Ground Suff Tool Selected source GPT-5.2 tropical circuit boolean reduction N N N Y Y Y Approximation Limitations of Pure Dy- namic Programming Gemini 3.1 Pro Jerrum Snir monotone perfect matchingN N N⊥ ⊥ ⊥none Claude Opus 4.5 tropical circuit monotone boolean simu- lation Y Y N N N N Reciprocal inputs in ari...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.