Recognition: 2 theorem links
· Lean TheoremDependency-Aware Discrete Diffusion for Scene Graph Generation
Pith reviewed 2026-05-12 02:00 UTC · model grok-4.3
The pith
A dependency-aware discrete diffusion model generates scene graphs from text by decoupling structure from semantics in the diffusion steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
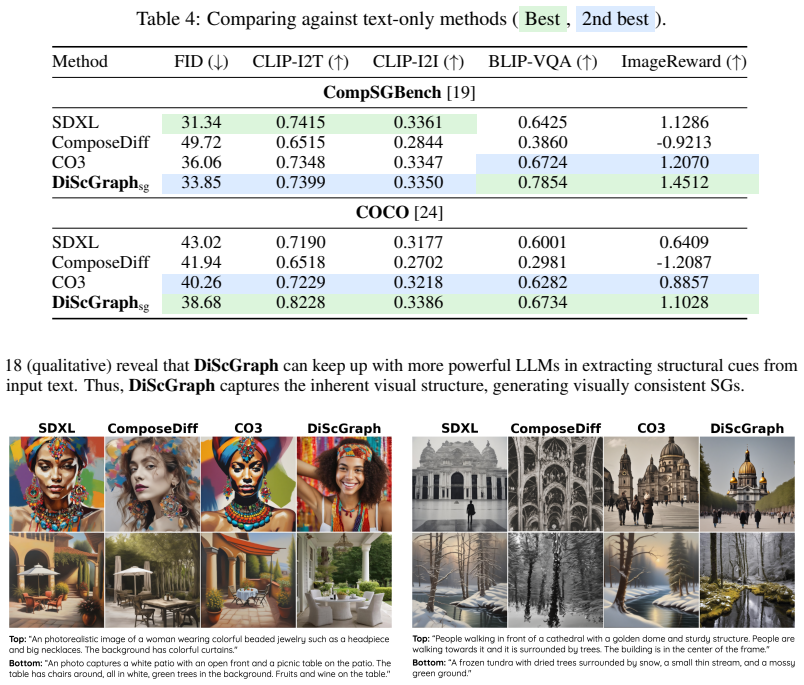
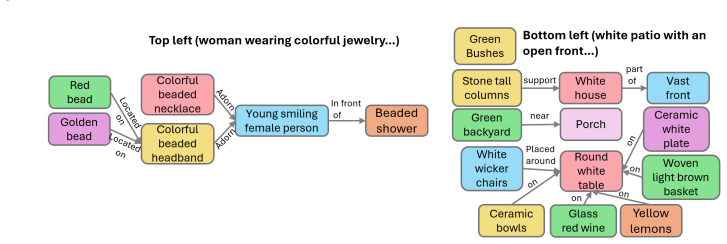
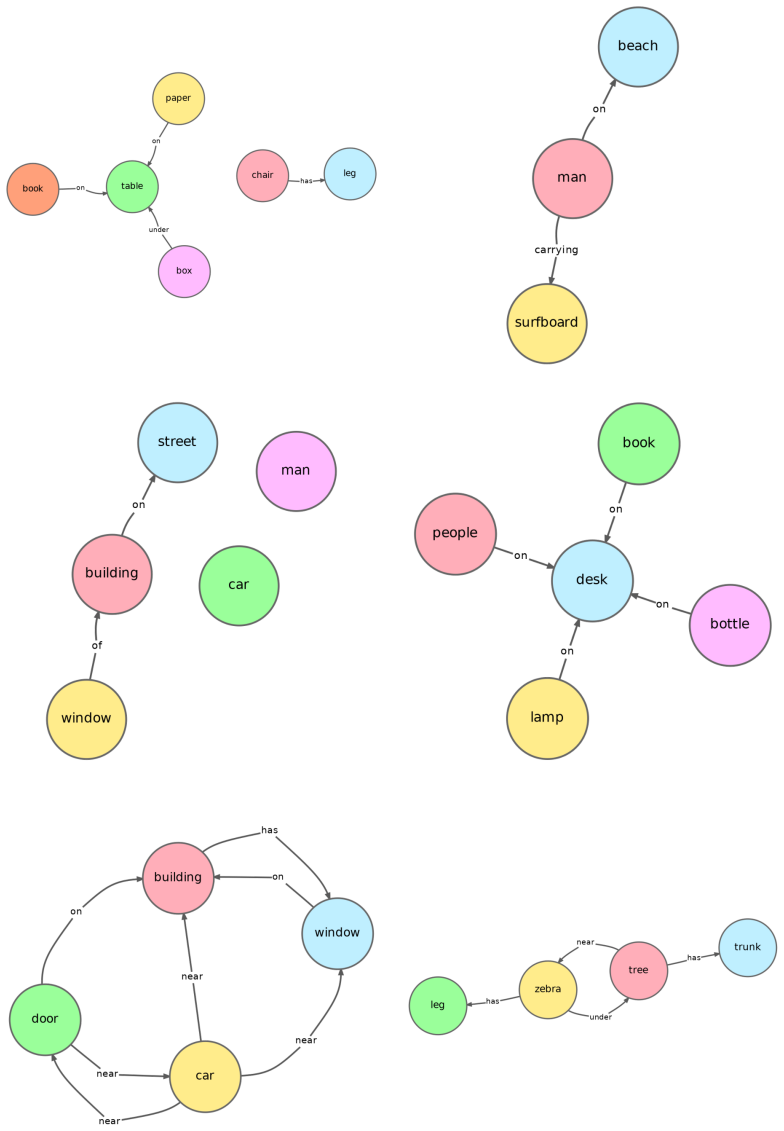
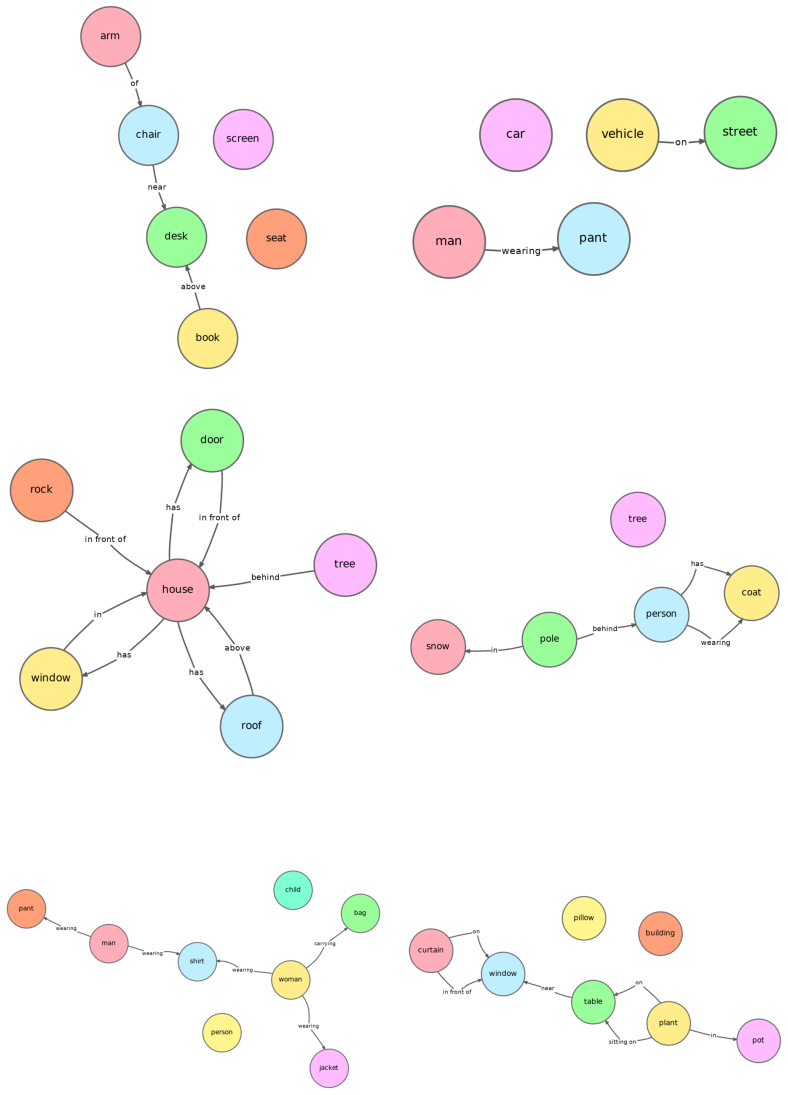
Prior discrete diffusion approaches for graph generation do not account for the hierarchical structure and strong dependencies between objects, edges, and relations that are characteristic of scene graphs. The proposed dependency-aware, hierarchically constrained discrete diffusion model decouples structure and semantics across the forward and reverse processes to capture these conditional dependencies. At inference, training-free conditioning is used to sample scene graphs aligned with natural language input. This yields improvements over both continuous and discrete graph generation baselines on graph and layout metrics, and produces better compositional alignment when the graphs are used
What carries the argument
Dependency-aware hierarchically constrained discrete diffusion model that decouples structure and semantics across forward and reverse processes to enforce conditional dependencies in scene graphs.
If this is right
- Outperforms continuous and discrete graph generation baselines on standard scene graph benchmarks across graph and layout metrics.
- Produces scene graphs that improve compositional alignment in downstream image generation, especially in multi-object cases.
- Supports sampling of text-aligned scene graphs through training-free conditioning at inference time.
- Captures conditional dependencies in scene graphs without requiring task-specific training for the conditioning step.
Where Pith is reading between the lines
- The decoupling technique could transfer to other hierarchical structured outputs such as 3D scene descriptions or action plans from language.
- If the separation holds, it may lower the amount of paired text-graph data needed for training vision-language systems.
- The method suggests a path to embed scene graph generation directly inside text-to-image pipelines while keeping the diffusion steps general.
Load-bearing premise
Decoupling structure and semantics across forward and reverse diffusion processes will capture the hierarchical dependencies between objects, edges, and relations without introducing new inconsistencies.
What would settle it
Running the model on standard scene graph benchmarks and finding no measurable gain in hierarchical consistency or relation accuracy metrics compared with existing discrete diffusion baselines.
Figures










read the original abstract
Scene graphs (SGs) represent objects and their relationships as structured graphs, enabling applications in image generation, robotics, and 3D understanding. Recent work suggests that conditioning image generation on scene graphs improves compositional fidelity compared to text-only prompting. However, since users typically provide text rather than structured graphs, a key challenge is to generate scene graphs from natural language. Prior work on discrete diffusion has demonstrated success in generating generic graphs such as molecules and circuits, but fails to account for the hierarchical structure and strong dependencies between objects, edges, and relations in scene graphs. We address this limitation by introducing a dependency-aware, hierarchically constrained discrete diffusion model for scene graph generation. Our approach decouples structure and semantics across the forward and reverse processes, enabling the model to capture conditional dependencies. At inference time, we perform training-free conditioning to sample text-aligned scene graphs. We evaluate our method on standard SG benchmarks and demonstrate improvements over both continuous and discrete graph generation baselines across graph and layout metrics. When fed to downstream image generation, our approach yields improved compositional alignment compared to text-to-image models, particularly in multi-object scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prior discrete diffusion models for graphs fail to capture the hierarchical dependencies between objects, edges, and relations in scene graphs. It introduces a dependency-aware, hierarchically constrained discrete diffusion model that decouples structure and semantics across the forward and reverse processes. At inference, training-free conditioning is applied to sample text-aligned scene graphs from natural language, yielding improvements over continuous and discrete baselines on standard SG benchmarks (graph and layout metrics) and better compositional alignment when used for downstream image generation.
Significance. If the central claims hold, the decoupling of structure and semantics plus training-free conditioning could offer a useful architectural advance for structured discrete generation tasks in vision-language settings. The idea of hierarchically constrained diffusion is potentially extensible, but the absence of any quantitative results, ablations, or exact baseline numbers in the abstract makes it impossible to gauge the magnitude or reliability of the reported gains.
major comments (2)
- [Methods / Inference-time conditioning] The manuscript provides only a high-level description of the training-free conditioning mechanism and does not include a derivation, algorithm, or pseudocode showing how the text embedding is injected into the decoupled structure and semantics reverse processes. This detail is load-bearing for the claim that the generated graphs remain both text-aligned and hierarchically valid (see skeptic note on object-relation mismatches).
- [Abstract / Experiments] The abstract asserts improvements 'across graph and layout metrics' and 'particularly in multi-object scenarios' for downstream image generation, yet supplies no numerical values, error bars, exact baseline comparisons, or ablation results. Without these, the central empirical claim cannot be evaluated for soundness.
minor comments (2)
- [Introduction / Model] Define 'dependency-aware' and 'hierarchically constrained' formally (e.g., via explicit constraints or loss terms) rather than descriptively, to allow readers to verify how the decoupling avoids new inconsistencies.
- [Model description] Clarify whether the forward process also respects the hierarchical constraints or whether they are enforced only in the reverse process; the current wording leaves this ambiguous.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive suggestions. Below we provide point-by-point responses to the major comments and indicate the changes we will implement in the revised manuscript.
read point-by-point responses
-
Referee: [Methods / Inference-time conditioning] The manuscript provides only a high-level description of the training-free conditioning mechanism and does not include a derivation, algorithm, or pseudocode showing how the text embedding is injected into the decoupled structure and semantics reverse processes. This detail is load-bearing for the claim that the generated graphs remain both text-aligned and hierarchically valid (see skeptic note on object-relation mismatches).
Authors: We acknowledge that the current description of the training-free conditioning is high-level and agree that additional detail is required for clarity and reproducibility. In the revised manuscript we will add a mathematical derivation of the conditioning process, an algorithm box, and pseudocode that explicitly shows how the text embedding is injected into the decoupled structure and semantics reverse processes. These additions will demonstrate how hierarchical constraints are preserved while achieving text alignment. revision: yes
-
Referee: [Abstract / Experiments] The abstract asserts improvements 'across graph and layout metrics' and 'particularly in multi-object scenarios' for downstream image generation, yet supplies no numerical values, error bars, exact baseline comparisons, or ablation results. Without these, the central empirical claim cannot be evaluated for soundness.
Authors: We agree that the abstract would benefit from specific quantitative highlights. Although the full experiments section already contains the requested numerical results, error bars, baseline comparisons, and ablations, we will revise the abstract to include key metric gains (e.g., improvements in recall@50 and layout metrics) and a concise statement on downstream image-generation improvements in multi-object cases, while remaining within length constraints. revision: yes
Circularity Check
No significant circularity; architectural claims rest on independent decoupling and conditioning rather than self-referential definitions or fits.
full rationale
The manuscript introduces a dependency-aware discrete diffusion model that explicitly decouples structure and semantics across forward/reverse processes and applies training-free conditioning at inference. No equations, fitted parameters, or self-citations are shown that would reduce the claimed text-aligned scene graphs or benchmark improvements to quantities defined by construction from the inputs. Evaluations compare against external continuous and discrete baselines on standard SG benchmarks, confirming the derivation chain remains self-contained and non-tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scene graphs exhibit hierarchical structure and strong conditional dependencies between objects, edges, and relations that prior discrete diffusion models fail to model.
invented entities (1)
-
dependency-aware hierarchically constrained discrete diffusion
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach decouples structure and semantics across the forward and reverse processes... pθ(ˆV0,ˆE0,ˆR0|xt)=pθ(ˆV0|xt)pθ(ˆE0|ˆV0,xt)pθ(ˆR0|ˆE0,ˆV0,xt)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
edge-gated forward noising process... qR(rij,t|rij,t−1,eij,t)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces, 2023
work page 2023
-
[2]
Split gibbs discrete diffusion posterior sampling
Wenda Chu, Zihui Wu, Yifan Chen, Yang Song, and Yisong Yue. Split gibbs discrete diffusion posterior sampling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[3]
Nicola De Cao and Thomas Kipf. Molgan: An implicit generative model for small molecular graphs.arXiv preprint arXiv:1805.11973, 2018
-
[4]
Steer away from mode collisions: Improving composition in diffusion models, 2026
Debottam Dutta, Jianchong Chen, Rajalaxmi Rajagopalan, Yu-Lin Wei, and Romit Roy Choudhury. Steer away from mode collisions: Improving composition in diffusion models, 2026
work page 2026
-
[5]
A generalization of transformer networks to graphs, 2021
Vijay Prakash Dwivedi and Xavier Bresson. A generalization of transformer networks to graphs, 2021
work page 2021
-
[6]
Scenegenie: Scene graph guided diffusion models for image synthesis
Azade Farshad, Yousef Yeganeh, Yu Chi, Chengzhi Shen, Björn Ommer, and Nassir Navab. Scenegenie: Scene graph guided diffusion models for image synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2023
work page 2023
-
[7]
Unconditional scene graph generation
Sarthak Garg, Helisa Dhamo, Azade Farshad, Sabrina Musatian, Nassir Navab, and Federico Tombari. Unconditional scene graph generation. InICCV, 2021
work page 2021
-
[8]
Equivariant diffusion for molecule generation in 3d
Emiel Hoogeboom, Victor Garcia Satorras, Clément Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3d. InICML, 2022
work page 2022
-
[9]
Graphgdp: Generative diffusion processes for permutation invariant graph generation
Han Huang, Leilei Sun, Bowen Du, Yanjie Fu, and Weifeng Lv. Graphgdp: Generative diffusion processes for permutation invariant graph generation. InICDM, 2022
work page 2022
-
[10]
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
work page 2023
-
[11]
Garg, Regina Barzilay, and Tommi Jaakkola
John Ingraham, Vikas K. Garg, Regina Barzilay, and Tommi Jaakkola. Generative models for graph-based protein design. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[12]
Layoutdm: Discrete diffusion model for graph-based layout generation
Naoto Inoue, Kotaro Kikuchi, Mayu Yamaguchi, and Ryosuke Otani. Layoutdm: Discrete diffusion model for graph-based layout generation. InCVPR, 2023
work page 2023
-
[13]
Score-based generative modeling of graphs via stochastic differential equations
Jaehyeong Jo, Seul Lee, and Sung Ju Hwang. Score-based generative modeling of graphs via stochastic differential equations. InICML, 2022
work page 2022
-
[14]
Image generation from scene graphs
Justin Johnson, Agrim Gupta, and Li Fei-Fei. Image generation from scene graphs. InCVPR, 2018
work page 2018
-
[15]
Test-time alignment of diffusion models without reward over-optimization, 2025
Sunwoo Kim, Minkyu Kim, and Dongmin Park. Test-time alignment of diffusion models without reward over-optimization.arXiv preprint arXiv:2501.05803, 2025
-
[16]
Blt: Bidirectional layout transformer for controllable layout generation
Xiang Kong, Lu Jiang, Huiwen Chang, Han Zhang, Yuan Hao, Haifeng Gong, and Irfan Essa. Blt: Bidirectional layout transformer for controllable layout generation. InECCV, 2022
work page 2022
-
[17]
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Fei-Fei Li. Visual genome: Connecting language and vision using crowdsourced dense image annotations, 2016. 10
work page 2016
-
[18]
Factorizable net: An efficient subgraph-based framework for scene graph generation
Yikang Li, Wanli Ouyang, Bolei Zhou, Jianping Shi, Chao Zhang, and Xiaogang Wang. Factorizable net: An efficient subgraph-based framework for scene graph generation. InEuropean Conference on Computer Vision (ECCV), 2018
work page 2018
-
[19]
Gligen: Open-set grounded text-to-image generation, 2023
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation, 2023
work page 2023
-
[20]
Learning deep generative models of graphs.arXiv preprint arXiv:1803.03324, 2018
Yujia Li, Oriol Vinyals, Chris Dyer, Razvan Pascanu, and Peter Battaglia. Learning deep generative models of graphs.arXiv preprint arXiv:1803.03324, 2018
-
[21]
Zejian Li, Chenye Meng, Yize Li, Ling Yang, Shengyuan Zhang, Jiarui Ma, Jiayi Li, Guang Yang, Changyuan Yang, Zhiyuan Yang, Jinxiong Chang, and Lingyun Sun. Laion-sg: An enhanced large-scale dataset for training complex image-text models with structural annotations, 2024
work page 2024
-
[22]
Long Lian, Boyi Li, Adam Yala, and Trevor Darrell. Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models, 2024
work page 2024
-
[23]
Hamilton, David Duvenaud, Raquel Urtasun, and Richard Zemel
Renjie Liao, Yujia Li, Yang Song, Shenlong Wang, Charlie Nash, William L. Hamilton, David Duvenaud, Raquel Urtasun, and Richard Zemel. Efficient graph generation with graph recurrent attention networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[24]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015
work page 2015
- [25]
-
[26]
Associative embedding: End-to-end learning for joint detection and grouping
Alejandro Newell and Jia Deng. Associative embedding: End-to-end learning for joint detection and grouping. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[27]
Permutation invariant graph generation via score-based generative modeling, 2020
Chenhao Niu, Yang Song, Jiaming Song, Shengjia Zhao, Aditya Grover, and Stefano Ermon. Permutation invariant graph generation via score-based generative modeling, 2020
work page 2020
-
[28]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Leigang Qu, Shengqiong Wu, Hao Fei, Liqiang Nie, and Tat-Seng Chua. Layoutllm-t2i: Eliciting layout guidance from llm for text-to-image generation.arXiv preprint arXiv:2308.05095, 2023
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763. PMLR, 2021
work page 2021
-
[31]
Nevae: A deep generative model for molecular graphs
Bidisha Samanta, Abir De, Gourhari Jana, Pratim Kumar Chattaraj, Niloy Ganguly, and Manuel Gomez Rodriguez. Nevae: A deep generative model for molecular graphs. InAAAI Conference on Artificial Intelligence, 2019
work page 2019
-
[32]
Sg-adapter: Enhancing text-to-image generation with scene graph guidance, 2024
Guibao Shen, Luozhou Wang, Jiantao Lin, Wenhang Ge, Chaozhe Zhang, Xin Tao, Yuan Zhang, Pengfei Wan, Zhongyuan Wang, Guangyong Chen, Yijun Li, and Ying-Cong Chen. Sg-adapter: Enhancing text-to-image generation with scene graph guidance, 2024
work page 2024
-
[33]
Jiantao Shen and others Lin. Scene graph guided generation: Enable accurate relations generation in text-to-image models via textural rectification. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[34]
Martin Simonovsky and Nikos Komodakis. Graphvae: Towards generation of small graphs using variational autoencoders.arXiv preprint arXiv:1802.03480, 2018
-
[35]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In Francis Bach and David Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 2256–2265, Lille, France, 07–09 Jul 2015. PMLR
work page 2015
-
[36]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021. 11
work page 2021
-
[37]
Autoregressive image generation guided by scene graphs.arXiv preprint arXiv:2508.14502, 2025
V o Thanh-Nhan, Nguyen Trong-Thuan, Nguyen Tam V ., and Tran Minh-Triet. Autoregressive image generation guided by scene graphs.arXiv preprint arXiv:2508.14502, 2025
-
[38]
Trippe, Jason Yim, Doug Tischer, Tamara Broderick, David Baker, Regina Barzilay, and Tommi Jaakkola
Brian L. Trippe, Jason Yim, Doug Tischer, Tamara Broderick, David Baker, Regina Barzilay, and Tommi Jaakkola. Diffusion probabilistic modeling of protein backbones. InICLR, 2023
work page 2023
-
[39]
Varscene: A deep generative model for realistic scene graph synthesis
Tathagat Verma, Abir De, Yateesh Agrawal, Vishwa Vinay, and Soumen Chakrabarti. Varscene: A deep generative model for realistic scene graph synthesis. InICML, 2022
work page 2022
-
[40]
Digress: Discrete denoising diffusion for graph generation
Clement Vignac, Igor Krawczuk, Victor Garcia Satorras, Pascal Frossard, Sviatoslav V oloshynovskiy, and Max Welling. Digress: Discrete denoising diffusion for graph generation. InICLR, 2023
work page 2023
-
[41]
Maxime V ono, Nicolas Dobigeon, and Pierre Chainais. Split-and-augmented gibbs sampler—application to large-scale inference problems.IEEE Transactions on Signal Processing, 67(6):1648–1661, March 2019
work page 2019
-
[42]
Stephen J. Wright. Coordinate descent algorithms, 2015
work page 2015
-
[43]
Fang Wu and Stan Z. Li. Diffmd: A geometric diffusion model for molecular dynamics simulations, 2023
work page 2023
-
[44]
Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion
Jinheng Xie, Yuexiang Li, Yawen Huang, Haozhe Liu, Wentian Zhang, Yefeng Zheng, and Mike Zheng Shou. Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[45]
Bicheng Xu, Qi Yan, Renjie Liao, Lele Wang, and Leonid Sigal. Joint generative modeling of grounded scene graphs and images via diffusion models.Transactions on Machine Learning Research, 2024
work page 2024
-
[46]
Danfei Xu, Yuke Zhu, Christopher B. Choy, and Li Fei-Fei. Scene graph generation by iterative message passing. InCVPR, 2017
work page 2017
-
[47]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. InProceedings of the 37th International Conference on Neural Information Processing Systems, pages 15903–15935, 2023
work page 2023
-
[48]
Graph r-cnn for scene graph generation
Jianwei Yang, Jiasen Lu, Stefan Lee, Dhruv Batra, and Devi Parikh. Graph r-cnn for scene graph generation. InECCV, 2018
work page 2018
-
[49]
Diffusion-based scene graph to image generation with masked contrastive pre-training, 2022
Ling Yang, Zhilin Huang, Yang Song, Shenda Hong, Guohao Li, Wentao Zhang, Bin Cui, Bernard Ghanem, and Ming-Hsuan Yang. Diffusion-based scene graph to image generation with masked contrastive pre-training, 2022
work page 2022
-
[50]
Training-free diffusion model alignment with sampling demons.arXiv preprint arXiv:2410.05760, 2024
Po-Hung Yeh, Kuang-Huei Lee, and Jun-Cheng Chen. Training-free diffusion model alignment with sampling demons.arXiv preprint arXiv:2410.05760, 2024
-
[51]
Jiaxuan You, Rex Ying, Xiang Ren, William L. Hamilton, and Jure Leskovec. Graphrnn: Generating realistic graphs with deep auto-regressive models. InProceedings of the 35th International Conference on Machine Learning (ICML), pages 5708–5717, 2018
work page 2018
-
[52]
Seongjun Yun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, and Hyunwoo J. Kim. Graph transformer networks, 2020
work page 2020
-
[53]
Neural motifs: Scene graph parsing with global context
Rowan Zellers, Mark Yatskar, Sam Thomson, and Yejin Choi. Neural motifs: Scene graph parsing with global context. InCVPR, 2018
work page 2018
-
[54]
Adding conditional control to text-to-image diffusion models, 2023
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models, 2023
work page 2023
-
[55]
Sgdiff: Scene graph guided diffusion model for image collaborative segcaptioning, 2025
Xu Zhang, Jin Yuan, Hanwang Zhang, Guojin Zhong, Yongsheng Zang, Jiacheng Lin, and Zhiyong Li. Sgdiff: Scene graph guided diffusion model for image collaborative segcaptioning, 2025
work page 2025
-
[56]
Zhiyuan Zhang, Dongdong Chen, and Jing Liao. Sgedit: Bridging llm with text-to-image models for scene graph-based image editing.ACM Transactions on Graphics, 2024
work page 2024
-
[57]
Layoutdiffusion: Improving graphic layout generation by discrete diffusion probabilistic models
Zhengbin Zhou, Zheng Wang, Yandong Guo, and Ming-Ming Lin. Layoutdiffusion: Improving graphic layout generation by discrete diffusion probabilistic models. InICCV, 2023. 12 A Appendix Appendix Table of Contents A.1 Structure-aware Forward Process – Additional Details . . . . . . . . . . . . . . . . . . . . . 14 A.2 Factorized Reverse Sampler – Additional ...
work page 2023
-
[58]
object identities define the semantic entities in the graph,
-
[59]
directed edge existence determines which object pairs interact,
-
[60]
Thus, relation prediction is conditioned on both object identity and edge existence
relation identities are meaningful only for active directed edges. Thus, relation prediction is conditioned on both object identity and edge existence. Object reverse posterior.For each object variable vi, the model predicts, pθ(vi,0 =c|x t). The reverse posterior is pθ(vi,t−1 =a|v i,t =b, x t) = X c qV (vi,t−1 =a|v i,t =b, v i,0 =c)p θ(vi,0 =c|x t). (79)...
-
[61]
(100) Sample or decode Vt−1 ∼p θ(Vt−1 |x t) (101) using the object posterior
Predict object clean-state probabilities: pθ(V0 |x t). (100) Sample or decode Vt−1 ∼p θ(Vt−1 |x t) (101) using the object posterior
-
[62]
(102) Sample Et−1 ∼p θ(Et−1 |V t−1, xt) (103) using the edge posterior
Predict edge clean-state probabilities conditioned on recovered objects: pθ(E0 |V t−1, xt). (102) Sample Et−1 ∼p θ(Et−1 |V t−1, xt) (103) using the edge posterior
-
[63]
Predict relation clean-state probabilities conditioned on recovered objects and edges: pθ(R0 |V t−1, Et−1, xt). (104) For each pair(i, j): rij,t−1 = 0, e ij,t−1 = 0, sample from active relation posterior, e ij,t−1 = 1, eij,t = 1. sample from relation marginale ij,t−1 = 1, eij,t = 0 (105) Thus, the reverse sampler follows the semantic order Vt−1 →E...
-
[64]
Particle Propagation step: G(d) t−1 ∼p θ(Gt−1 |G (d) t ). (122)
-
[65]
Followed by normalization, ˜w(d) t−1 = w(d) t−1 PD j=1 w(j) t−1
Weight computation step:For each particle, we compute the predicted clean graph and to distribute the reward across timesteps, incremental weights are used,w t = exp β(Rt−1 −R t) , ˆG(d) 0 =ϵ θ(G(d) t−1, t−1), (123) w(d) t−1 = exp β(R( ˆG(d) 0 , T)−R (d) t ) , (124) where R(d) t =R( ˆG(d) 0 (t), T) is the previous reward and T is the text prompt (not to b...
-
[66]
Resampling Step: {G(d) t−1}D d=1 are the propagated particles with normalized weights {˜w(d) t−1}D d=1, wherePD d=1 ˜w(d) t−1 = 1. We perform resampling by drawing particle indices from a categorical distribution based on reward alignment, I(d) ∼Categorical ˜w(1) t−1, . . . ,˜w(D) t−1 , (126) and setting G(d) t−1 ←G (I(d)) t−1 . (127) Equivalently, this s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.