Recognition: 2 theorem links
· Lean TheoremOptimality of Sub-network Laplace Approximations: New Results and Methods
Pith reviewed 2026-05-12 02:16 UTC · model grok-4.3
The pith
Sub-network Laplace approximations systematically underestimate the predictive variance of the full Laplace posterior
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove that all sub-network Laplace methods systematically underestimate the predictive variance of the full Laplace posterior, and that this bias decreases monotonically as the retained sub-matrix expands. Leveraging this insight, we propose two principled, analytically grounded sub-network Hessian approximations: Gradient-Laplace selects parameters with the largest average squared gradients of the model output with respect to the parameters over a reference dataset; while Greedy-Laplace iteratively refines this selection by accounting for off-diagonal interactions in the precision matrix. We establish theoretical guarantees characterizing their optimality properties and show that they do
What carries the argument
The sub-network Hessian obtained by restricting the full Hessian to a chosen subset of parameters, which produces a strictly smaller predictive variance than the unrestricted Hessian.
If this is right
- Gradient-Laplace provably outperforms existing heuristic sub-network selection rules.
- Greedy-Laplace further reduces the variance bias by incorporating off-diagonal precision terms during selection.
- The variance bias shrinks monotonically with each added parameter, independent of which selection rule is used.
- The two new methods supply explicit, non-heuristic criteria for choosing which parameters to retain.
Where Pith is reading between the lines
- Practitioners should therefore prefer gradient- or interaction-aware selection over fixed layer-wise or diagonal heuristics whenever the computational budget allows.
- The monotonic bias property defines a clear trade-off curve between retained matrix size and remaining variance error that can be used to decide how large a sub-network to keep for any given model.
- The same monotonicity argument may apply to other low-rank or sparse posterior approximations that also drop cross-parameter covariances.
Load-bearing premise
The Laplace approximation itself is a reasonable surrogate for the true posterior and the restricted Hessian remains positive definite.
What would settle it
A concrete neural network, dataset, and sub-network choice for which the predictive variance computed from the sub-network Hessian exceeds the variance computed from the full Hessian.
Figures





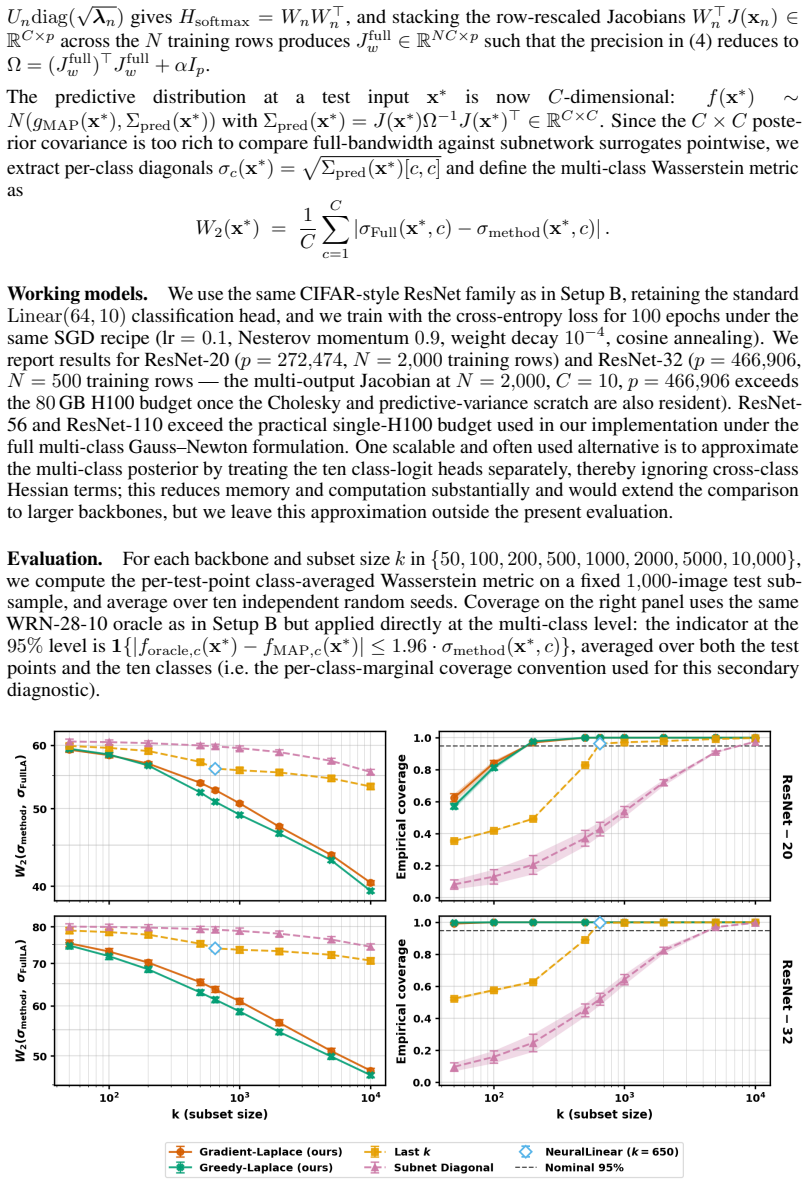

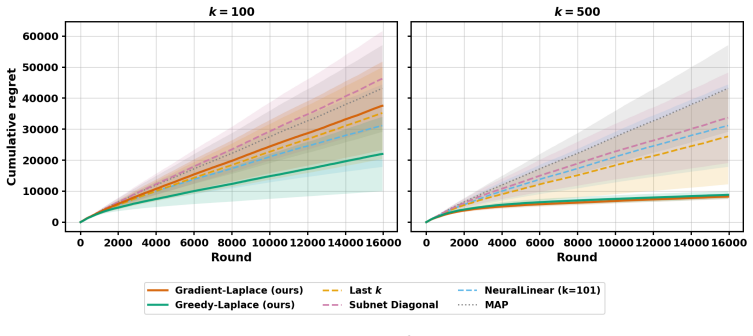

read the original abstract
Although the Laplace approximation offers a simple route to uncertainty quantification in deep neural networks, its reliance on inverting large Hessian matrices has motivated a range of computationally feasible low-dimensional or sparse approximations. A prominent class of such methods - sub-network Laplace approximations, constructs surrogates by restricting attention to a small subset of parameters. Existing approaches in this family typically rely on diagonal, layer-wise, or other architectural heuristics for subset selection, which ignore cross-parameter interactions and lack formal optimality guarantees. In this paper, we provide a rigorous theoretical analysis of the sub-network Laplace paradigm. We prove that all sub-network Laplace methods systematically underestimate the predictive variance of the full Laplace posterior, and that this bias decreases monotonically as the retained sub-matrix expands. Leveraging this insight, we propose two principled, analytically grounded sub-network Hessian approximations: \textit{Gradient-Laplace} selects parameters with the largest average squared gradients of the model output with respect to the parameters over a reference dataset; while \textit{Greedy-Laplace} iteratively refines this selection by accounting for off-diagonal interactions in the precision matrix. We establish theoretical guarantees characterizing their optimality properties and show that Gradient-Laplace provably outperforms existing heuristic approaches. Extensive numerical studies across diverse settings indicate that these methods perform strongly relative to existing benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that sub-network Laplace approximations systematically underestimate the predictive variance of the full Laplace posterior, with this bias decreasing monotonically as the retained sub-matrix expands. It introduces two new parameter-selection procedures—Gradient-Laplace (largest average squared gradients) and Greedy-Laplace (iterative refinement accounting for off-diagonal precision terms)—with theoretical optimality characterizations, proves that Gradient-Laplace outperforms existing heuristics, and supports the claims with numerical experiments across diverse settings.
Significance. If the central variance-decomposition argument holds, the work supplies a clean, internal theoretical justification for the bias of any sub-network Laplace method and replaces architectural heuristics with two analytically grounded selection rules. The explicit use of the law of total variance on the linearized output, together with the automatic positive-definiteness of principal sub-blocks, is a genuine strength that requires no external assumptions about posterior quality. The resulting methods could improve practical uncertainty quantification in large networks while retaining computational tractability.
minor comments (3)
- [§4.1] §4.1: the definition of the reference dataset used to compute average squared gradients for Gradient-Laplace should be stated explicitly (including whether the same data are used for MAP estimation or held out), as this choice affects both the theoretical guarantee and reproducibility.
- [Table 2, Figure 3] Table 2 and Figure 3: the reported predictive-variance ratios are given without standard errors across random seeds or data splits; adding these would strengthen the claim that the proposed methods consistently outperform the listed baselines.
- [Notation] Notation section: the symbol H_{SS} is introduced without an immediate reminder that it is the principal sub-block of the full Hessian; a one-sentence clarification would improve readability for readers unfamiliar with the sub-network literature.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript and for recommending minor revision. The report highlights the variance-decomposition argument and the theoretical grounding of the proposed selection rules as strengths, which aligns with our own view of the contribution. No specific major comments or requested changes were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper's central claim—that sub-network Laplace approximations underestimate full Laplace predictive variance, with the bias decreasing monotonically as the retained sub-matrix grows—follows directly from the law of total variance applied to the linearized model output under the Gaussian Laplace posterior N(θ*, H^{-1}). The sub-network variance is the conditional variance given the complement fixed at the MAP, and the full variance equals this plus the nonnegative variance of the conditional expectation; monotonicity is immediate from the same decomposition on nested conditioning sets. Positive-definiteness of principal sub-blocks is automatic. This is an internal comparison within the Laplace family using only standard assumptions, with no reduction to fitted parameters, self-citations, or ansatzes. The Gradient-Laplace and Greedy-Laplace selection rules are defined analytically from gradients and Hessian blocks without circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The loss function is twice continuously differentiable and the Hessian is positive definite in a neighborhood of the MAP estimate.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclearWe prove that all sub-network Laplace methods systematically underestimate the predictive variance of the full Laplace posterior, and that this bias decreases monotonically as the retained sub-matrix expands.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixationalpha_pin_under_high_calibration unclearGradient-Laplace selects parameters with the largest average squared gradients... Greedy-Laplace iteratively refines this selection by accounting for off-diagonal interactions in the precision matrix.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
A Scalable Laplace Approximation for Neural Networks , author =. International Conference on Learning Representations , year =
-
[2]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Optimizing Neural Networks with Kronecker-factored Approximate Curvature , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , volume =
work page 2015
-
[3]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Robustbench: a standardized adversarial robustness benchmark
Robustbench: a standardized adversarial robustness benchmark , author=. arXiv preprint arXiv:2010.09670 , year=
-
[5]
International conference on machine learning , pages=
Probabilistic backpropagation for scalable learning of bayesian neural networks , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[6]
Bertin-Mahieux, Thierry , title =. 2011 , howpublished =. doi:10.24432/C50K61 , url =
- [7]
-
[8]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =. 2016 , doi =
work page 2016
-
[9]
Efficient exploration for llms.arXiv preprint arXiv:2402.00396,
Efficient exploration for llms , author=. arXiv preprint arXiv:2402.00396 , year=
-
[10]
arXiv preprint arXiv:2404.02649 , year=
On the Importance of Uncertainty in Decision-Making with Large Language Models , author=. arXiv preprint arXiv:2404.02649 , year=
-
[11]
arXiv preprint arXiv:2211.06516 , year=
Bandits for Online Calibration: An Application to Content Moderation on Social Media Platforms , author=. arXiv preprint arXiv:2211.06516 , year=
-
[12]
Quantifying uncertainty in answers from any language model via intrinsic and extrinsic confidence assessment , author=. arXiv preprint arXiv:2308.16175 , year=
-
[13]
Advances in neural information processing systems , volume=
Can you trust your model's uncertainty? evaluating predictive uncertainty under dataset shift , author=. Advances in neural information processing systems , volume=
-
[14]
Deep Exploration via Bootstrapped DQN , url =
Osband, Ian and Blundell, Charles and Pritzel, Alexander and Van Roy, Benjamin , booktitle =. Deep Exploration via Bootstrapped DQN , url =
-
[15]
End to End Learning for Self-Driving Cars
End to end learning for self-driving cars , author=. arXiv preprint arXiv:1604.07316 , year=
work page internal anchor Pith review arXiv
-
[16]
Dermatologist-level classification of skin cancer with deep neural networks , author=. nature , volume=. 2017 , publisher=
work page 2017
-
[17]
Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages=
Long-Term Value of Exploration: Measurements, Findings and Algorithms , author=. Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages=
-
[18]
International Conference on Learning Representations , year=
Deep learning with logged bandit feedback , author=. International Conference on Learning Representations , year=
-
[19]
Proceedings of the 19th international conference on World wide web , pages=
A contextual-bandit approach to personalized news article recommendation , author=. Proceedings of the 19th international conference on World wide web , pages=
-
[20]
Machine learning for healthcare conference , pages=
Contextual bandits for adapting treatment in a mouse model of de novo carcinogenesis , author=. Machine learning for healthcare conference , pages=. 2018 , organization=
work page 2018
-
[21]
Nonstationary bandits with habituation and recovery dynamics , author=. Operations Research , volume=. 2020 , publisher=
work page 2020
-
[22]
Dynamic online pricing with incomplete information using multiarmed bandit experiments , author=. Marketing Science , volume=. 2019 , publisher=
work page 2019
-
[23]
Customized nonlinear bandits for online response selection in neural conversation models , author=
-
[24]
arXiv preprint arXiv:2302.12565 , year=
Variational linearized Laplace approximation for Bayesian deep learning , author=. arXiv preprint arXiv:2302.12565 , year=
-
[25]
Proceedings of the 17th ACM Conference on Recommender Systems , pages=
Deep exploration for recommendation systems , author=. Proceedings of the 17th ACM Conference on Recommender Systems , pages=
-
[26]
arXiv preprint arXiv:2403.10671 , year=
Hessian-Free Laplace in Bayesian Deep Learning , author=. arXiv preprint arXiv:2403.10671 , year=
-
[27]
International conference on learning representations , volume=
Deep bayesian bandits showdown , author=. International conference on learning representations , volume=
-
[28]
arXiv preprint arXiv:2010.00827 , year=
Neural thompson sampling , author=. arXiv preprint arXiv:2010.00827 , year=
-
[29]
Epistemic uncertainty quantification in deep learning classification by the Delta method , author=. Neural networks , volume=. 2022 , publisher=
work page 2022
-
[30]
Linear Algebra and its Applications , volume=
Stability of the Lanczos algorithm on matrices with regular spectral distributions , author=. Linear Algebra and its Applications , volume=. 2024 , publisher=
work page 2024
-
[31]
A practical Bayesian framework for backpropagation networks , author=. Neural computation , volume=. 1992 , publisher=
work page 1992
-
[32]
Fast exact multiplication by the Hessian , author=. Neural computation , volume=. 1994 , publisher=
work page 1994
-
[33]
International conference on machine learning , pages=
Scalable bayesian optimization using deep neural networks , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[34]
Journal of King Saud University-Computer and Information Sciences , volume=
A comprehensive review on ensemble deep learning: Opportunities and challenges , author=. Journal of King Saud University-Computer and Information Sciences , volume=. 2023 , publisher=
work page 2023
-
[35]
arXiv preprint arXiv:2303.00586 , year=
Fair-ensemble: When fairness naturally emerges from deep ensembling , author=. arXiv preprint arXiv:2303.00586 , year=
-
[36]
Cullum, Jane K. and Willoughby, Ralph A. , doi =. Lanczos Algorithms for Large Symmetric Eigenvalue Computations , url =. 2002 , Bdsk-Url-1 =. https://epubs.siam.org/doi/pdf/10.1137/1.9780898719192 , publisher =
-
[37]
Advances in neural information processing systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in neural information processing systems , volume=
-
[38]
Advances in Neural Information Processing Systems , editor=
Laplace Redux - Effortless Bayesian Deep Learning , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
work page 2021
-
[39]
arXiv preprint arXiv:1906.11537 , year=
`In-Between' Uncertainty in Bayesian Neural Networks , author=. arXiv preprint arXiv:1906.11537 , year=
-
[40]
International Conference on Machine Learning , pages=
Bayesian deep learning via subnetwork inference , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[41]
Journal of the Royal Statistical Society Series B: Statistical Methodology , pages=
The HulC: confidence regions from convex hulls , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , pages=. 2023 , publisher=
work page 2023
- [42]
-
[43]
Laplace, Pierre Simon , journal=. M
-
[44]
Variational inference in probabilistic models , author=. 2001 , school=
work page 2001
-
[45]
Isoperimetry and Gaussian analysis , author =
-
[46]
Electronic Communications in Probability , volume =
Rudelson, Mark and Vershynin, Roman , title =. Electronic Communications in Probability , volume =. 2013 , doi =
work page 2013
-
[47]
American Mathematical Society , pages=
Laplace's method in Bayesian analysis, Statistical Multiple Integration , author=. American Mathematical Society , pages=
-
[48]
Information theory, inference and learning algorithms , author=. 2003 , publisher=
work page 2003
-
[49]
Proceedings of the National Academy of Sciences , volume =
Prevalence of neural collapse during the terminal phase of deep learning training , author =. Proceedings of the National Academy of Sciences , volume =. 2020 , doi =
work page 2020
-
[50]
Advances in Neural Information Processing Systems , volume =
A Geometric Analysis of Neural Collapse with Unconstrained Features , author =. Advances in Neural Information Processing Systems , volume =
-
[51]
The Annals of Statistics , volume =
The Landscape of Empirical Risk for Nonconvex Losses , author =. The Annals of Statistics , volume =. 2018 , doi =
work page 2018
-
[52]
Optimizing Neural Networks with
Martens, James and Grosse, Roger , booktitle =. Optimizing Neural Networks with. 2015 , publisher =
work page 2015
-
[53]
Proceedings of the 36th International Conference on Machine Learning , series =
An Investigation into Neural Net Optimization via Hessian Eigenvalue Density , author =. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , publisher =
work page 2019
-
[54]
Advances in Neural Information Processing Systems , volume =
Neural Tangent Kernel: Convergence and Generalization in Neural Networks , author =. Advances in Neural Information Processing Systems , volume =
-
[55]
Advances in Neural Information Processing Systems , volume =
Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent , author =. Advances in Neural Information Processing Systems , volume =
-
[56]
SIAM Journal on Mathematics of Data Science , volume =
Parameterization Dependence of Optimization Dynamics in Deep Neural Networks , author =. SIAM Journal on Mathematics of Data Science , volume =. 2019 , doi =
work page 2019
- [57]
-
[58]
Satyajit Ghosh and Kshitij Khare and George Michailidis , title =. Journal of the American Statistical Association , volume =. 2019 , publisher =. doi:10.1080/01621459.2018.1437043 , note =
-
[59]
The Annals of Statistics , number =
Sumanta Basu and George Michailidis , title =. The Annals of Statistics , number =. 2015 , doi =
work page 2015
-
[60]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Bayesian Active Learning for Classification and Preference Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[61]
Advances in Neural Information Processing Systems (NeurIPS) , year=
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[62]
arXiv preprint arXiv:2509.07952 , year=
A unified theory of the high-dimensional Laplace approximation with application to Bayesian inverse problems , author=. arXiv preprint arXiv:2509.07952 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.