Recognition: no theorem link
Data-driven Circuit Discovery for Interpretability of Language Models
Pith reviewed 2026-05-12 02:16 UTC · model grok-4.3
The pith
Existing methods for discovering circuits in language models recover subgraphs tied to the dataset rather than to the intended task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
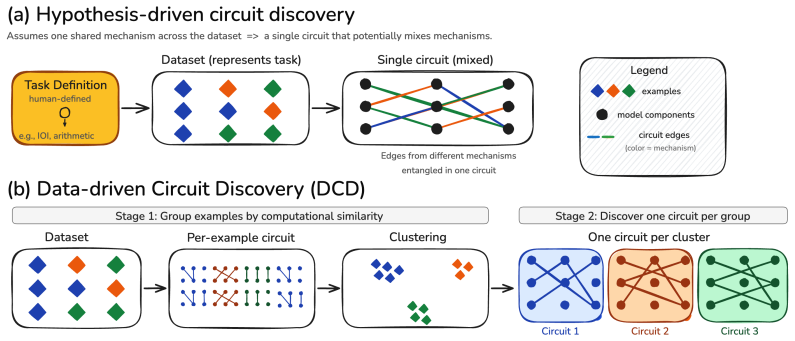
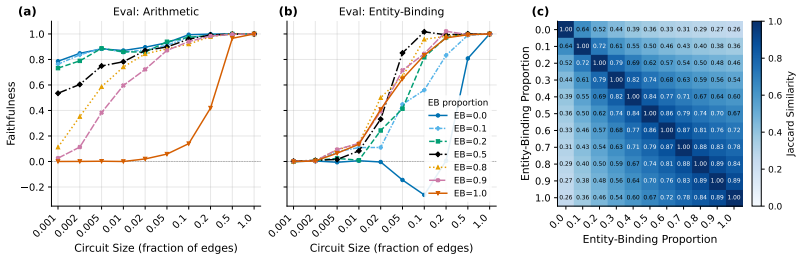
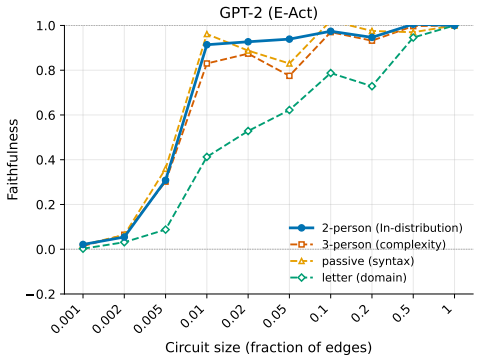
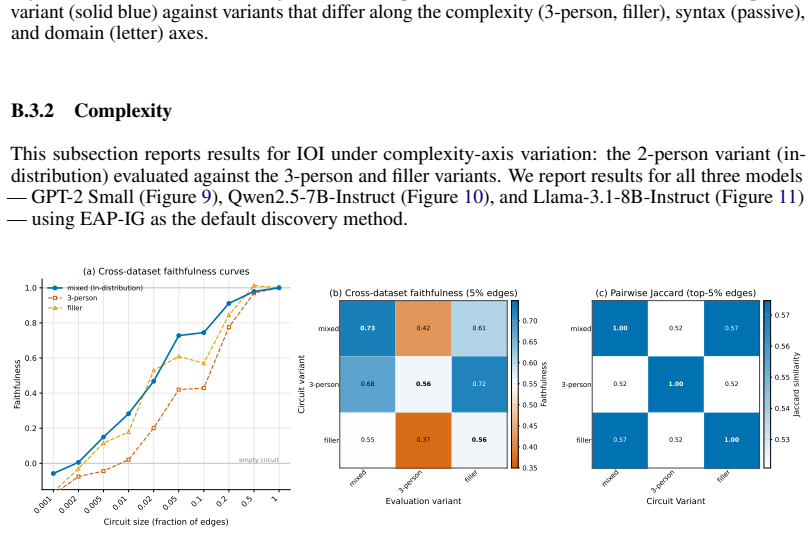
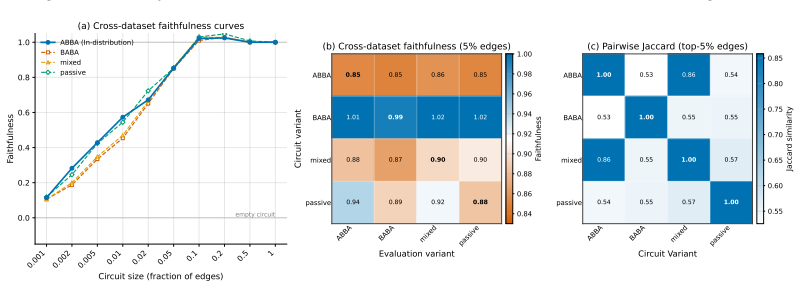
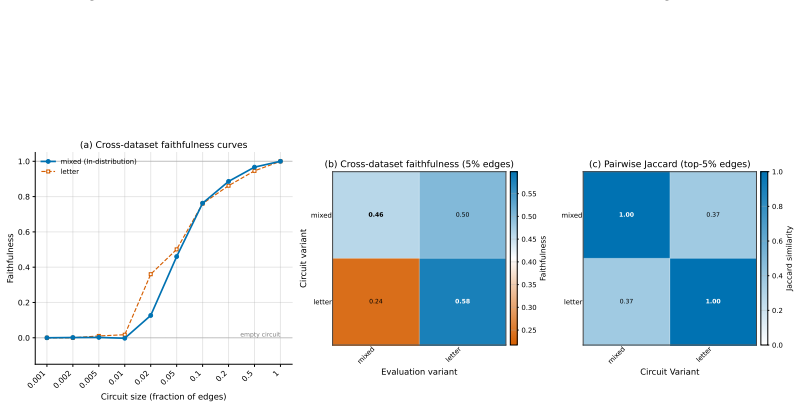
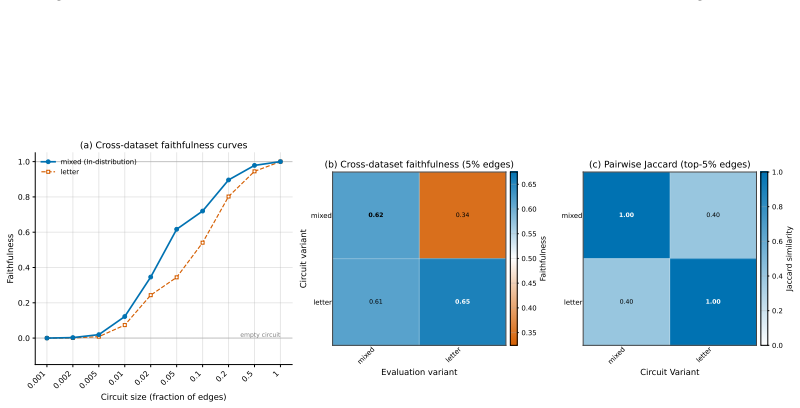
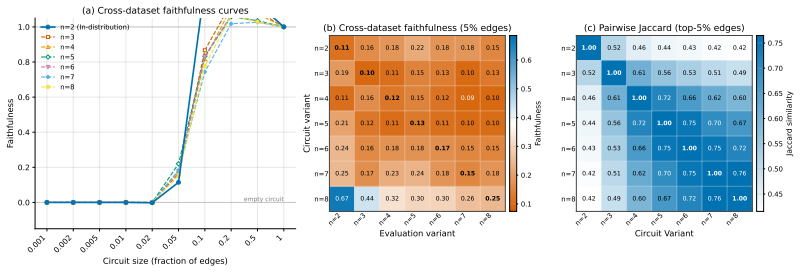
The paper claims that existing circuit discovery methods recover circuits tied to the specific dataset rather than to the general task, as evidenced by low cross-faithfulness between circuits from semantically similar but distinct datasets and by the ability of a single circuit to achieve high faithfulness on mixed-task data. It introduces Data-driven Circuit Discovery, which drops the single-circuit assumption by clustering dataset examples based on the model's internal processing patterns and then extracting a dedicated circuit for each cluster.
What carries the argument
Data-driven Circuit Discovery (DCD), a framework that first clusters examples by similarity of model processing and then locates a separate circuit for each resulting group.
If this is right
- A single human-defined task can be implemented by several distinct circuits within the same model.
- Circuits recovered by existing methods are more faithful to the particular dataset used than to the broader task.
- Grouping examples by processing similarity allows distinct mechanisms to be analyzed separately instead of being merged.
- Each per-group circuit explains model behavior on its examples more accurately than any unified circuit explains the full dataset.
Where Pith is reading between the lines
- Interpretability research may need to shift from assuming one circuit per task to identifying and comparing multiple mechanisms that models actually use.
- The clustering step could be tested on other model families or modalities to check whether similar hidden structure appears outside language models.
- If the clusters correspond to observable behavioral differences, the method might help diagnose when models switch strategies on edge cases within a task.
Load-bearing premise
That clustering examples according to how the model processes them will isolate genuinely distinct computational mechanisms rather than arbitrary or spurious groupings.
What would settle it
Run DCD on a mixed dataset of two tasks whose separate circuits already show near-zero cross-faithfulness; if the resulting per-cluster circuits do not each achieve higher faithfulness on their own group than a single circuit achieves on the whole mixed set, the core claim would be refuted.
Figures





















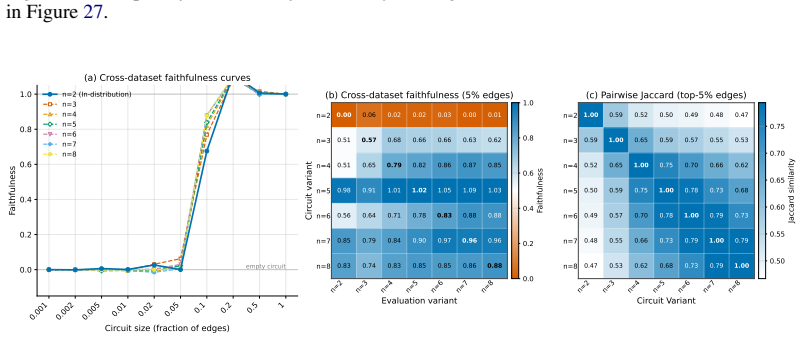
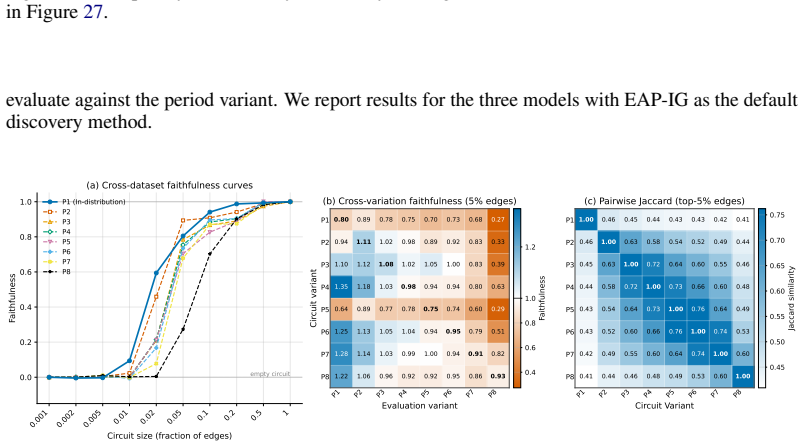


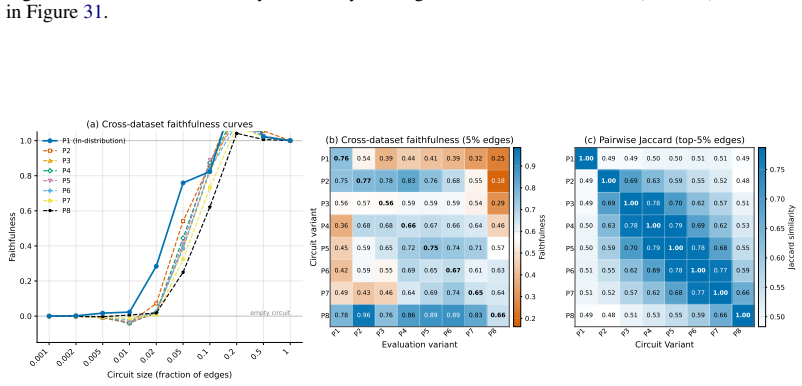



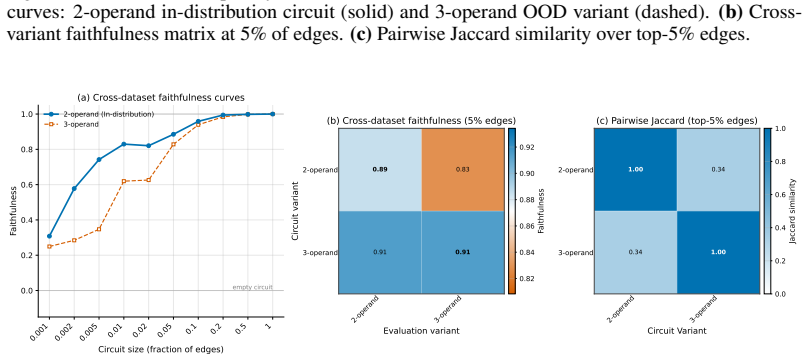



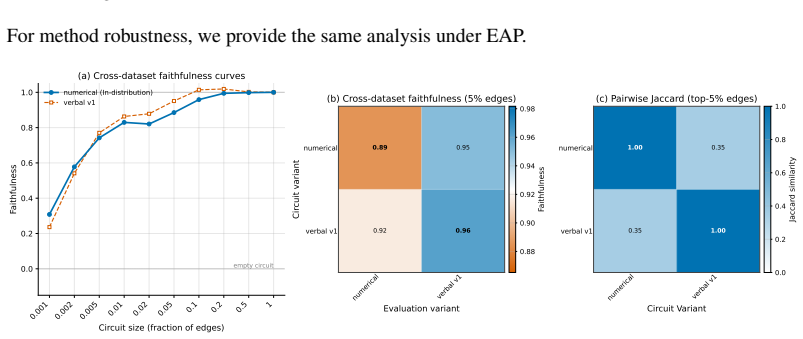






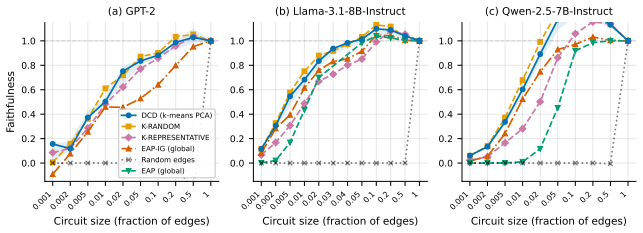


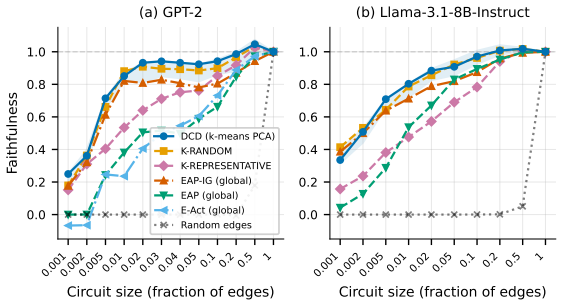
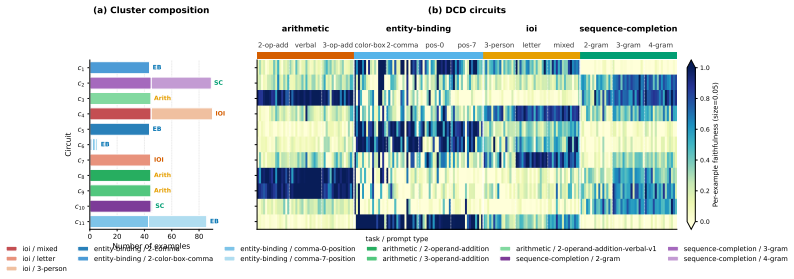

read the original abstract
Circuit discovery aims to explain how language models (LMs) implement a specific task by localizing and interpreting a circuit, a computational subgraph responsible for the LM's behavior. Existing circuit discovery methods are hypothesis-driven; they first informally define a task with a dataset, and then apply a circuit discovery algorithm over that dataset to obtain a single circuit. This imposes two strong assumptions: that the LM implements the task with a single circuit, and that the dataset adequately represents the task as humans understand it. We systematically test these assumptions across four previously studied tasks and find that even minor dataset variations that preserve task semantics can produce circuits with low edge overlap and cross-dataset faithfulness. More strikingly, when applied to a mixed dataset with two distinct tasks whose separately discovered circuits have near-zero cross-faithfulness, existing methods still return a single circuit with high faithfulness across both tasks. This indicates that current methods discover dataset-specific circuits, rather than general task circuits. We propose Data-driven Circuit Discovery (DCD), a new discovery framework that drops both assumptions: instead of returning a single circuit for a dataset, DCD first clusters examples in the dataset by how similarly the model processes them and discovers a separate circuit for each group. This allows distinct mechanisms to appear separately rather than merged into a single circuit; each circuit explains its group, not the full task. Experiments show that DCD discovers multiple circuits per dataset, each more faithful to its group than a single circuit discovered by existing methods. Broadly, DCD lets the data reveal mechanistic structure within LMs, rather than relying on human-defined task boundaries that may not align with how models organize their computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that existing circuit discovery methods for language models rest on two assumptions—that a task is implemented by a single circuit and that a given dataset adequately represents the task—and tests these by showing low edge overlap and cross-faithfulness even for minor dataset variations that preserve semantics. On mixed datasets combining two tasks whose separate circuits have near-zero cross-faithfulness, standard methods still recover a single high-faithfulness circuit, suggesting they capture dataset-specific rather than task-general structure. The authors introduce Data-driven Circuit Discovery (DCD), which clusters examples by similarity of model processing and extracts a separate circuit per cluster; experiments indicate each such circuit is more faithful to its subgroup than a single circuit found by prior methods.
Significance. If the clustering step reliably isolates distinct computational mechanisms rather than surface-feature correlations, DCD would represent a meaningful shift from hypothesis-driven to data-driven interpretability, allowing mechanistic structure to emerge from the data instead of human task definitions. The mixed-dataset experiment provides a concrete demonstration that current methods can merge distinct circuits, and the per-group faithfulness gains are a falsifiable, quantitative claim. The work also supplies a practical framework that could be applied to other interpretability pipelines.
major comments (3)
- [Methods] Clustering procedure (Methods section): the claim that DCD isolates distinct mechanisms rests on the unstated similarity metric used to cluster examples 'by how similarly the model processes them.' Without an explicit definition (e.g., cosine similarity on which layer activations, gradient alignment, or logit differences) and controls for confounds such as sequence length or token overlap, it is possible that clusters reflect spurious correlations rather than shared computational pathways; this directly affects whether the reported per-group faithfulness improvement is mechanistic or an artifact of reduced variance in smaller subproblems.
- [Experiments] Mixed-dataset experiment (Experiments section): the central empirical result—that existing methods return a single circuit with high faithfulness on a mixture whose separately discovered circuits have near-zero cross-faithfulness—requires the exact faithfulness values, the models and datasets used, and any statistical controls or ablation studies. The abstract states the qualitative outcome but does not report quantitative thresholds or variance estimates, making it difficult to assess whether the 'high faithfulness' is robust or merely consistent with a merged but still dataset-specific circuit.
- [Experiments] Faithfulness evaluation on subgroups (Experiments section): when faithfulness is measured on the derived clusters rather than the original task distribution, it is necessary to verify that the metric remains well-calibrated (e.g., via comparison to random or size-matched baselines). If the per-group circuits simply solve easier subproblems, the reported improvement over a single circuit could be expected by construction rather than evidence of better mechanistic discovery.
minor comments (2)
- Notation for circuits and edges should be standardized across figures and text; currently the abstract refers to 'edge overlap' without defining the precise edge representation used in the overlap calculation.
- The paper would benefit from an explicit statement of the four previously studied tasks and the models (e.g., GPT-2, Llama) on which all experiments were run, preferably in a table in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods] Clustering procedure (Methods section): the claim that DCD isolates distinct mechanisms rests on the unstated similarity metric used to cluster examples 'by how similarly the model processes them.' Without an explicit definition (e.g., cosine similarity on which layer activations, gradient alignment, or logit differences) and controls for confounds such as sequence length or token overlap, it is possible that clusters reflect spurious correlations rather than shared computational pathways; this directly affects whether the reported per-group faithfulness improvement is mechanistic or an artifact of reduced variance in smaller subproblems.
Authors: We agree that an explicit definition of the similarity metric and controls for confounds are required for the claim to be fully substantiated. The current Methods section describes clustering by similarity of model processing but does not provide the precise implementation details or confound controls. In the revised manuscript we will add a complete specification of the metric (cosine similarity on selected layer activations), the clustering algorithm, and ablation experiments that control for sequence length and token overlap. These additions will allow readers to evaluate whether the clusters reflect shared computational pathways. revision: yes
-
Referee: [Experiments] Mixed-dataset experiment (Experiments section): the central empirical result—that existing methods return a single circuit with high faithfulness on a mixture whose separately discovered circuits have near-zero cross-faithfulness—requires the exact faithfulness values, the models and datasets used, and any statistical controls or ablation studies. The abstract states the qualitative outcome but does not report quantitative thresholds or variance estimates, making it difficult to assess whether the 'high faithfulness' is robust or merely consistent with a merged but still dataset-specific circuit.
Authors: We acknowledge that the abstract presents only a qualitative summary. The Experiments section already specifies the models, datasets, and reports faithfulness values together with variance across random seeds and statistical controls. We will revise the abstract to include the key quantitative thresholds and will add any missing ablation details to the main text so that the robustness of the mixed-dataset result is fully documented. revision: yes
-
Referee: [Experiments] Faithfulness evaluation on subgroups (Experiments section): when faithfulness is measured on the derived clusters rather than the original task distribution, it is necessary to verify that the metric remains well-calibrated (e.g., via comparison to random or size-matched baselines). If the per-group circuits simply solve easier subproblems, the reported improvement over a single circuit could be expected by construction rather than evidence of better mechanistic discovery.
Authors: We agree that calibration of the faithfulness metric on the derived subgroups must be demonstrated. In the revised manuscript we will include additional baselines: random circuits of comparable size and single circuits discovered on size-matched random subsets of the same clusters. These comparisons will show whether the observed faithfulness gains exceed what would be expected from reduced problem variance alone. revision: yes
Circularity Check
No circularity: DCD defined and evaluated independently
full rationale
The paper defines DCD as an independent procedure—cluster dataset examples by model processing similarity, then run circuit discovery per cluster—followed by separate faithfulness evaluation on the resulting groups. No step reduces by construction to its own inputs, fitted parameters, or self-citations; the clustering metric and faithfulness scores are distinct from the circuit outputs, and the central claim (multiple circuits outperforming a single merged one) is tested empirically rather than assumed. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models implement tasks via localized computational subgraphs called circuits
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2404.14082 (2024)
L. Bereska and E. Gavves. Mechanistic interpretability for ai safety–a review.arXiv preprint arXiv:2404.14082, 2024
-
[2]
B. Chughtai, A. Cooney, and N. Nanda. Summing up the facts: Additive mechanisms behind factual recall in llms.arXiv preprint arXiv:2402.07321, 2024
-
[3]
A. Conmy, A. Mavor-Parker, A. Lynch, S. Heimersheim, and A. Garriga-Alonso. To- wards automated circuit discovery for mechanistic interpretability. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 16318–16352. Curran Associates, Inc., 2023. URL https://p...
work page 2023
- [4]
- [5]
-
[6]
N. Elhage, N. Nanda, C. Olsson, T. Henighan, N. Joseph, B. Mann, A. Askell, Y . Bai, A. Chen, T. Conerly, N. DasSarma, D. Drain, D. Ganguli, Z. Hatfield-Dodds, D. Hernandez, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCandlish, and C. Olah. A mathematical framework for transformer circuits.Transformer Circui...
-
[7]
https://transformer-circuits.pub/2021/framework/index.html
work page 2021
-
[8]
J. Feng and J. Steinhardt. How do language models bind entities in context? InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=zb3b6oKO77
work page 2024
-
[9]
J. Ferrando and E. V oita. Information flow routes: Automatically interpreting language models at scale. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17432–17445, 2024
work page 2024
-
[10]
J. Ferrando, G. Sarti, A. Bisazza, and M. R. Costa-Jussà. A primer on the inner workings of transformer-based language models.arXiv preprint arXiv:2405.00208, 2024
-
[11]
G. Franco, L. M. Tassis, A. Rohr, and M. Crovella. Finding highly interpretable prompt-specific circuits in language models.arXiv preprint arXiv:2602.13483, 2026
work page internal anchor Pith review arXiv 2026
-
[12]
arXiv preprint arXiv:2510.06182 , year=
Y . Gur-Arieh, M. Geva, and A. Geiger. Mixing mechanisms: How language models retrieve bound entities in-context.arXiv preprint arXiv:2510.06182, 2025. 10
- [13]
- [14]
-
[15]
S. Mamidanna, D. Rai, Z. Yao, and Y . Zhou. All for one: Llms solve mental math at the last token with information transferred from other tokens. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30735–30748, 2025
work page 2025
-
[16]
S. Marks, C. Rager, E. J. Michaud, Y . Belinkov, D. Bau, and A. Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=I4e82CIDxv
work page 2025
-
[17]
A. Mueller, A. Geiger, S. Wiegreffe, D. Arad, I. Arcuschin, A. Belfki, Y . S. Chan, J. F. Fiotto- Kaufman, T. Haklay, M. Hanna, J. Huang, R. Gupta, Y . Nikankin, H. Orgad, N. Prakash, A. Reusch, A. Sankaranarayanan, S. Shao, A. Stolfo, M. Tutek, A. Zur, D. Bau, and Y . Belinkov. MIB: A mechanistic interpretability benchmark. InForty-second International C...
work page 2025
-
[18]
Y . Nikankin, D. Arad, Y . Gandelsman, and Y . Belinkov. Same task, different circuits: Disen- tangling modality-specific mechanisms in vlms. InMechanistic Interpretability Workshop at NeurIPS 2025, 2025
work page 2025
-
[19]
Y . Nikankin, A. Reusch, A. Mueller, and Y . Belinkov. Arithmetic without algorithms: Language models solve math with a bag of heuristics. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=O9YTt26r2P
work page 2025
-
[20]
C. Olah, N. Cammarata, L. Schubert, G. Goh, M. Petrov, and S. Carter. Zoom in: An introduction to circuits.Distill, 2020. doi: 10.23915/distill.00024.001. https://distill.pub/2020/circuits/zoom- in
-
[21]
C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. DasSarma, T. Henighan, B. Mann, A. Askell, Y . Bai, A. Chen, T. Conerly, D. Drain, D. Ganguli, Z. Hatfield-Dodds, D. Hernandez, S. Johnston, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCan- dlish, and C. Olah. In-context learning and induction heads.Transformer C...
work page 2022
-
[22]
N. Prakash, T. R. Shaham, T. Haklay, Y . Belinkov, and D. Bau. Fine-tuning enhances existing mechanisms: A case study on entity tracking. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=8sKcAWOf2D
work page 2024
-
[23]
A. Y . Qwen, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, et al. Qwen2. 5 technical report.arXiv preprint, 2024
work page 2024
-
[24]
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
- [25]
-
[26]
D. Rai, S. Miller, K. Moran, and Z. Yao. Failure by interference: Language models make balanced parentheses errors when faulty mechanisms overshadow sound ones. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=1t4hR9JCcS
work page 2025
- [27]
-
[28]
A. Syed, C. Rager, and A. Conmy. Attribution patching outperforms automated circuit discovery. InProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 407–416, 2024
work page 2024
-
[29]
R. Tibshirani, G. Walther, and T. Hastie. Estimating the number of clusters in a data set via the gap statistic.Journal of the royal statistical society: series b (statistical methodology), 63(2): 411–423, 2001
work page 2001
-
[30]
K. R. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=NpsVSN6o4ul
work page 2023
-
[31]
F. Zhang and N. Nanda. Towards best practices of activation patching in language models: Metrics and methods.arXiv preprint arXiv:2309.16042, 2023. A Dataset construction In this section, we provide details on the dataset construction across all four tasks, representative example prompts (section A.4), and the accuracy of each model on each variant (secti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.